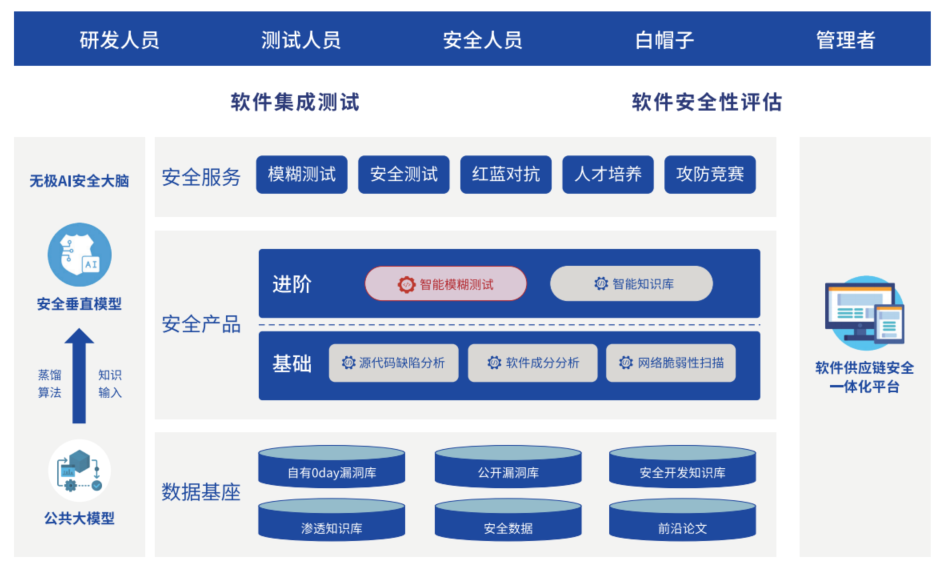
YOLO的核心原理预览

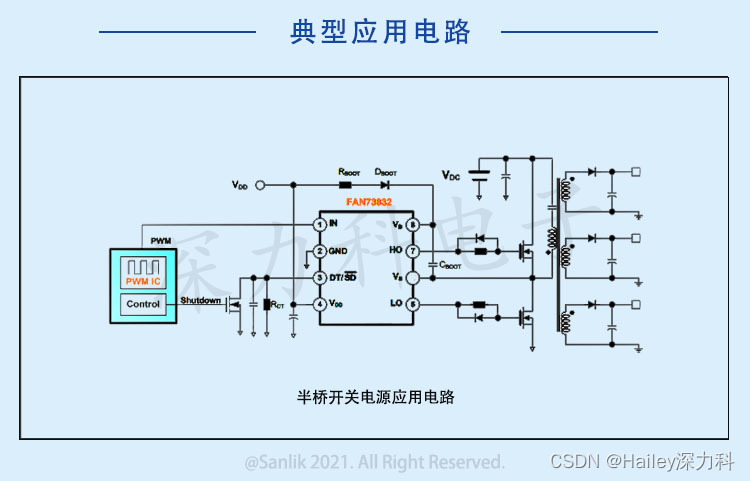
- YOLO将输入的图片resize成448 x 448,并且为 S x S(S = 7)个grid,如果物体的中心落入该grid中,那么该grid就需要负责检测该物体。
- 一次性输出所检测到的目标信息,包括类别和位置。

-
对于每一个网格(grid),都会预测出B个bounding boxes(B=2),这个bounding boxes有5个量,分别是物体的中心位置(x,y)和它的高(h)和宽(w),以及这次预测的置信度(confidence score)。
-
Bounding Box指矩形框的中心 (x,y),矩形框的宽高(w,h)以及置信度c,这5个值的范围在0和1之间,通过Sigmoid函数来实现。
矩形框中心 (x,y)的含义:每个Bounding Box相对于grid cell的偏移值,范围0~1
矩形框的宽高 (w,h)的含义: 每个Bounding Box的宽高相对于整个图像的大小,范围0~1
-
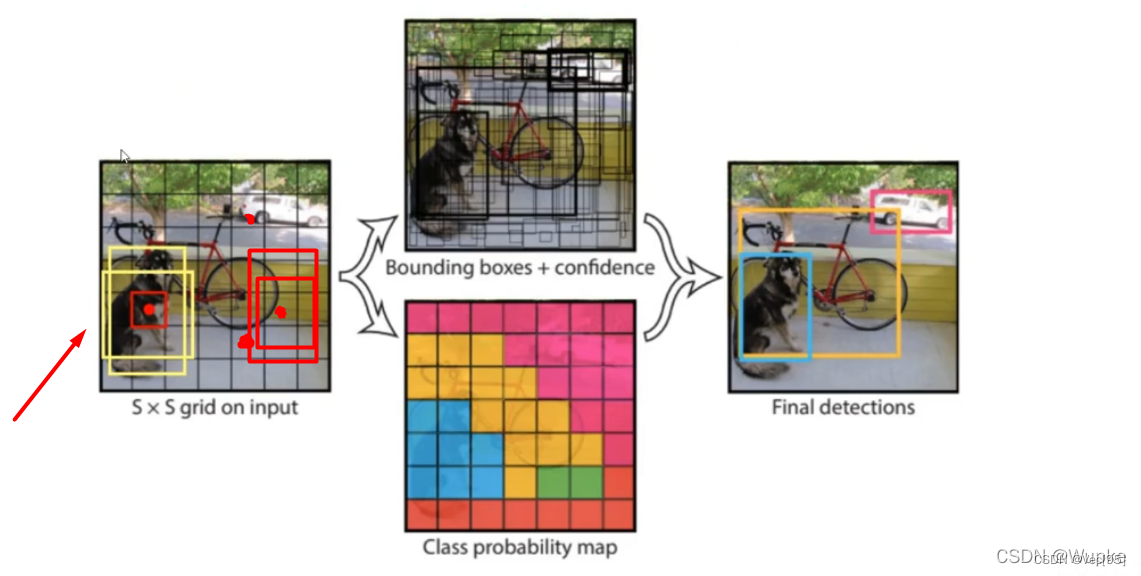
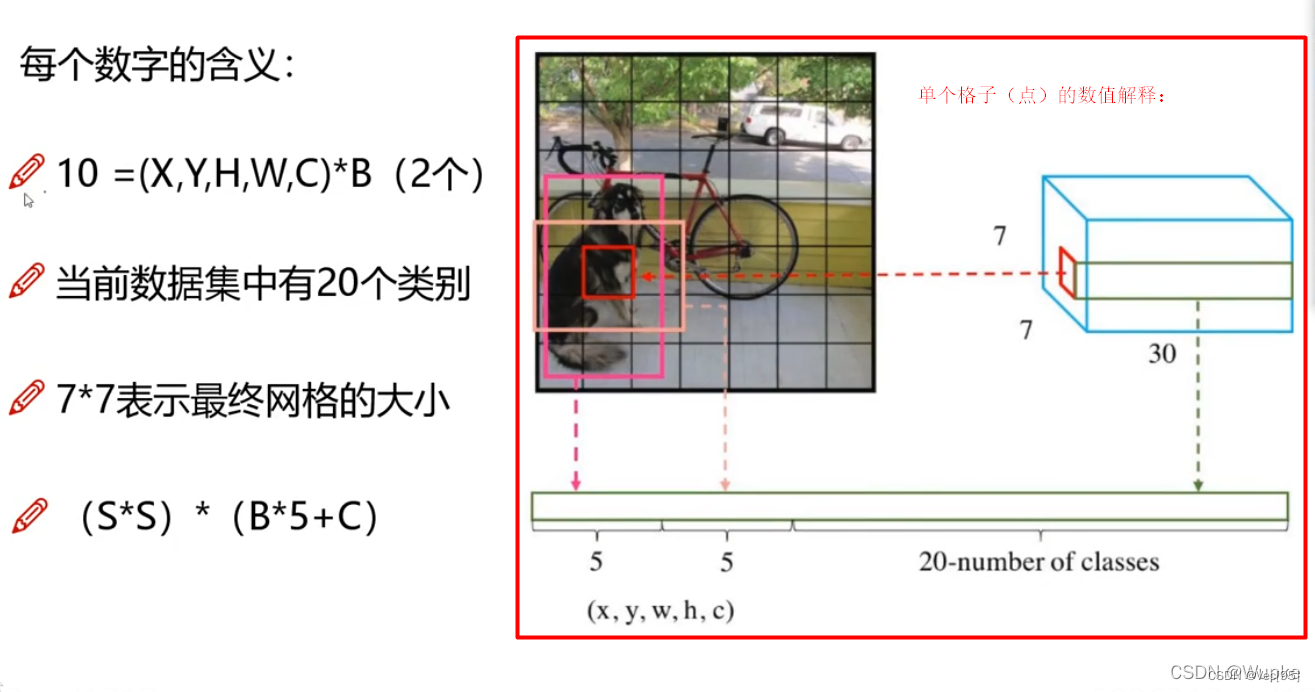
要注意:每个grid产生两个bounding boxs,如下左图中狗的中心点对应两个黄色框,以及自行车后轮外面的图像中心点对应的两个红色框,其中狗的中心点对应的两个bounding boxs(黄色),相对于自行车后轮外面的图像中心点对应的两个bounding boxs(红色)尺寸是不一样的,也说明bounding boxs的尺寸是根据目标自适应的:
-
每个框还要负责预测这个框中的物体是什么类别的,共预测C个类。

-
综上,S×S 个网格,每个网格要预测 B个bounding box ,还要预测 C 个类。网络输出就是一个 S × S × (5×B+C)。(S x S个网格,每个网格都有B个预测框,每个框又有5个参数(矩形框的中心 (x,y),矩形框的宽高(w,h)以及置信度c,这5个值的范围在0和1之间),再加上每个网格都有C个预测类,默认C=20,即可以将物体检测为20个类别)
-
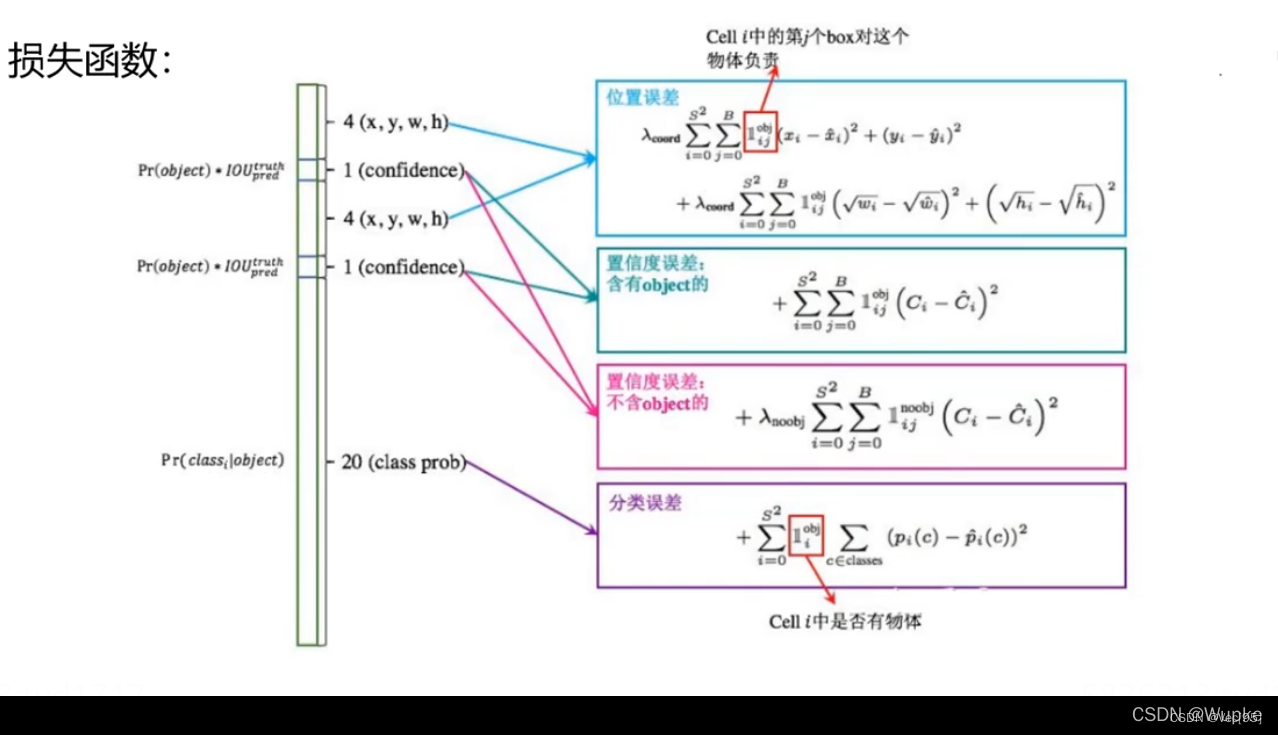
图像中包含物体对象的Bounding Box数量远远小于不包含物体的Bounding Box数量,因此若两者的权重相等,那么计算的损失函数会偏向于给出背景的结果。Yolo1算法论文设置包含物体的Bounding Box的权重为5,不包含的Bounding Box的权重为0。
包含物体和不包含物体的权重分别记为:
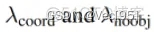
Yolo算法把定位和检测目标看成是一个回归问题,因此对于所有的输出变量,我们都使用和平方误差表示损失函数。
每个grid cell包含了2个Bounding Box和1个条件类概率,grid cell结构和损失函数如下图:
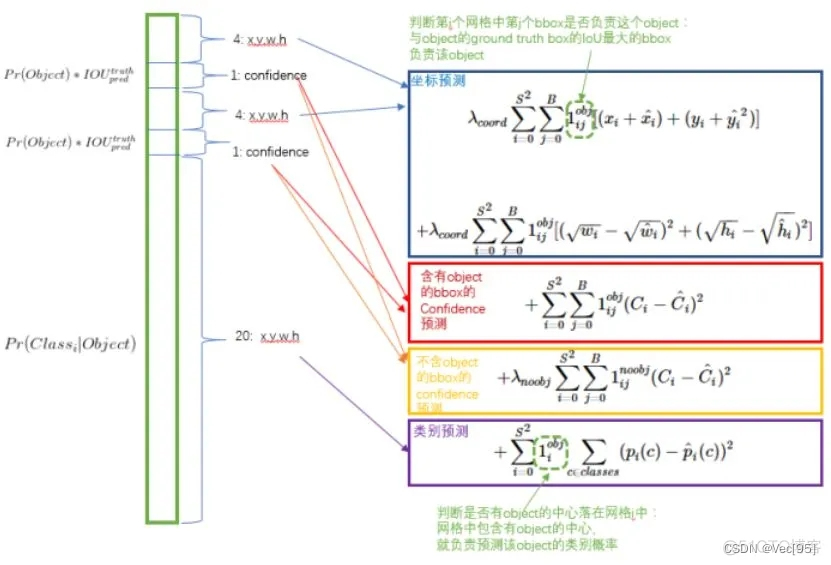
其中:
![]() 表示第i个grid cell的第j个Bounding Box是否包含物体对象,若包含,则
表示第i个grid cell的第j个Bounding Box是否包含物体对象,若包含,则![]() 等于1;若不包含,则
等于1;若不包含,则![]() 等于0。
等于0。
![]() 表示第i个grid cell是否包含物体对象,若包含,则
表示第i个grid cell是否包含物体对象,若包含,则![]() 等于1;若不包含,则
等于1;若不包含,则![]() 等于0。
等于0。
对于不同大小的Bounding Box,小的Bounding Box对于偏差的容忍度更低,比如千万富翁丢失1000块钱与普通家庭丢失1000块钱的意义不一样。为了缓和这个问题,我们对Bounding Box的宽和高取平方根。如下图:

YOLO-V1的网络架构:
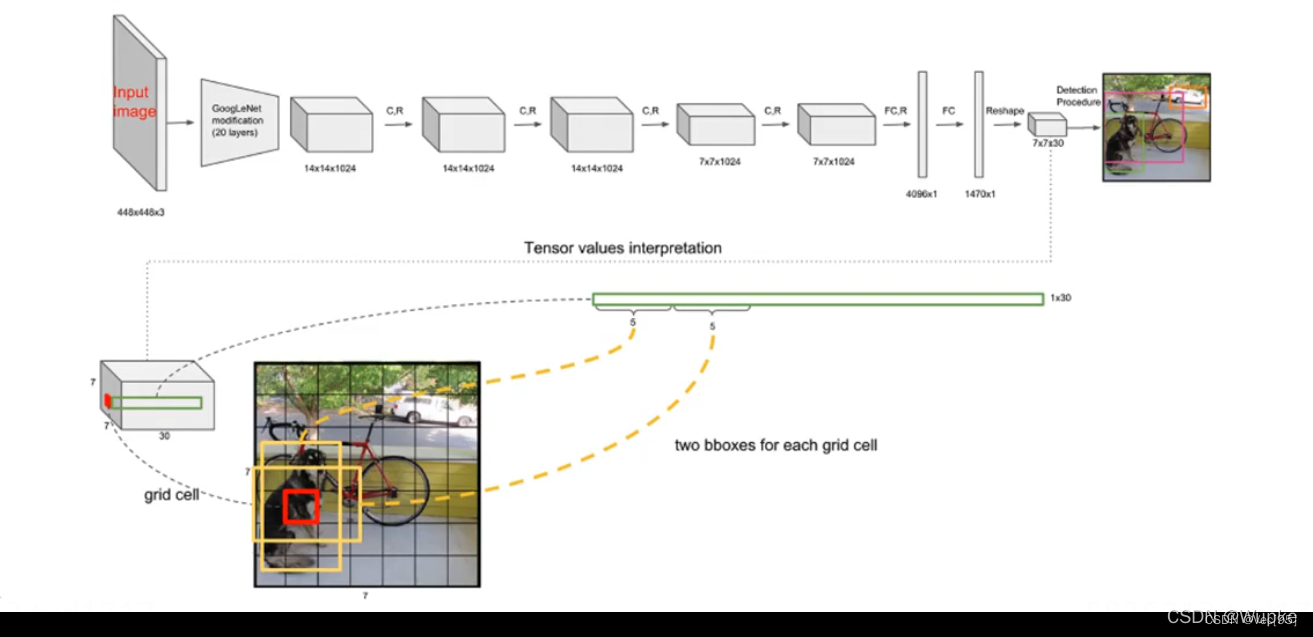
输入图像大小: 448×448×3
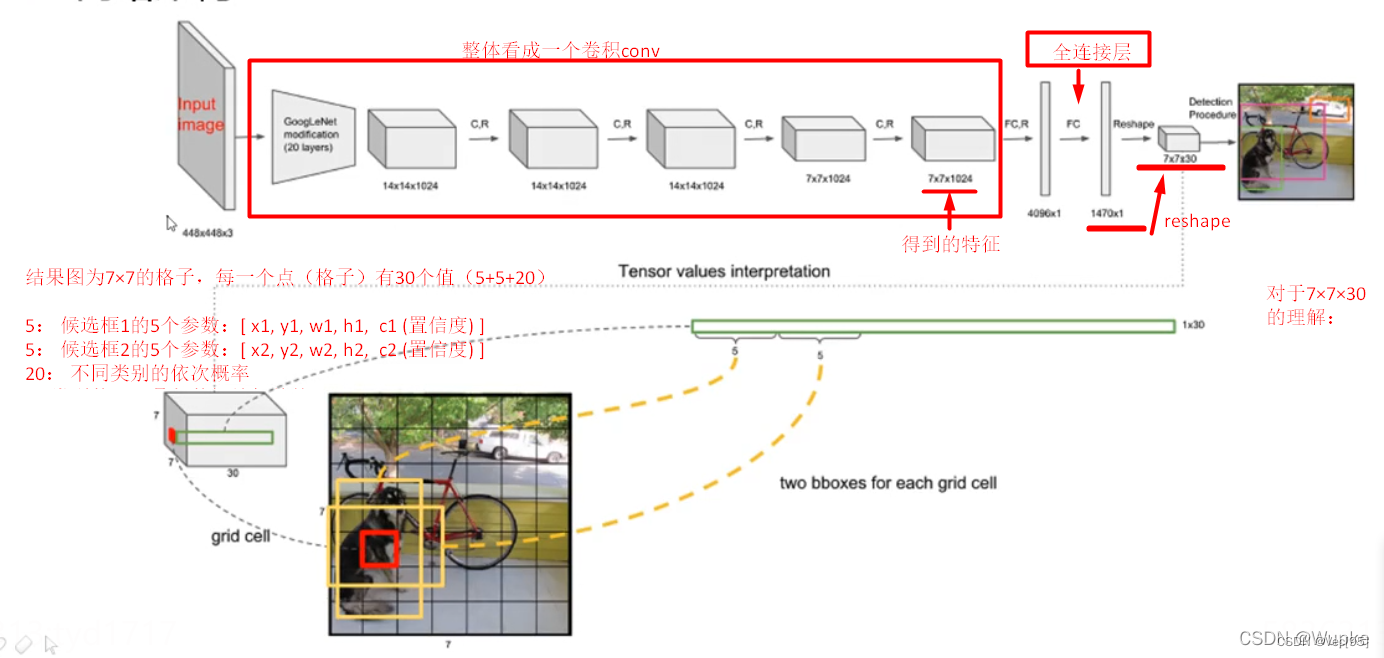
过程中的参数含义:
损失函数:
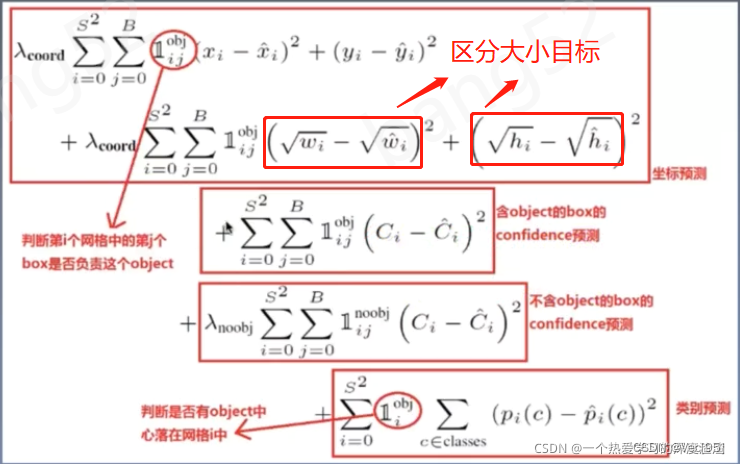
①涉及的预测的位置参数值与对应的损失函数描述:
x, y, w, h :
对应的损失函数要尽量减小预测值与真实值之间的差距。
函数公式中 x, y 是使用 平方差值 来描述,而对于 w, h 使用了根号,是为了检测小物体时候,减小偏移量小的时候对于小物体的的敏感度。

损失函数中的系数,是相应的权重。
②关于置信度的损失函数(与类别有关):
平方置信度与真实值之间的差异(分为不同的情况讨论:前景(要检测的物体)、背景(无目标处))
③分类相关的损失函数:交叉熵损失函数
非极大值抑制:

只取出保留 IOU 数值最大的框。
YOLO-V1小结
YOLO-V1 整体网络架构简单,检测速度快。
网络中,每个 cell 只预测一个类别,若物体的位置重合时,检测困难。
每个点只有两个候选框,小物体考虑的少。
如何定位目标物体的grid cell和Bounding Box
我们知道了损失函数如何计算,yolo算法预测每个grid cell的Bounding Box?训练阶段,我们需要知道物体的实际grid cell和Bounding Box。
如何定位?若目标物体的中心点在某一个grid cell,则该目标物体属于这一个grid cell,然后以整个图像宽高为尺度,计算该物体所在grid cell的宽高。如下图的红框grid cell标记的狗: