目录
0.hadoop hive的文档
1.一级分区表
2.一级分区表练习2
3.创建多级分区表
4.分区表操作
5.分桶表
6. 分桶表进行排序
7.分桶的原理
8.hive的复杂类型
9.array类型: 又叫数组类型,存储同类型的单数据的集合
10.struct类型: 又叫结构类型,可以存储不同类型单数据的集合
11.map类型: 又叫映射类型,存储键值对数据的映射(根据key找value)
0.hadoop hive的文档
hive文档: https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
hdfs文档: https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
yarn文档: https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
mr文档: https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
1.一级分区表
创建分区表: create [external] table [if not exists] 表名(字段名 字段类型 , 字段名 字段类型 , ... )partitioned by (分区字段名 分区字段类型)... ;
自动生成分区目录并插入数据: load data [local] inpath '文件路径' into table 分区表名 partition (分区字段名='值');
注意: 如果加local后面文件路径应该是linux本地路径,如果没有加那么就是hdfs文件路径
建表
create database hive3; use hive3; --练习1 创建一级分区表 -- 创建分区表: create [external] table [if not exists] -- 表名(字段名 字段类型 , 字段名 字段类型 , ... ) -- partitioned by (分区字段名 分区字段类型) ; -- 自动生成分区目录并插入数据: load data [local] inpath -- '文件路径' into table 分区表名 partition (分区字段名='值'); --建表 create table if not exists score (name string,subject string,grade int) partitioned by (dt string) row format delimited fields terminated by '\t' ;
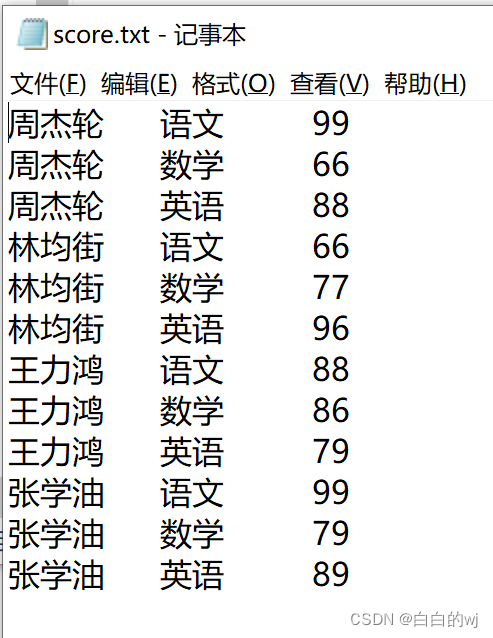
此为score.txt文件
--在hdfs的网页中手动上传score.txt到目录,下面每一次load data都会把这个文件移动 -- 加载数据 load data inpath '/score.txt' into table score partition (dt='2022'); load data inpath '/score.txt' into table score partition (dt='2023'); load data inpath '/score.txt' into table score partition (dt='2024');
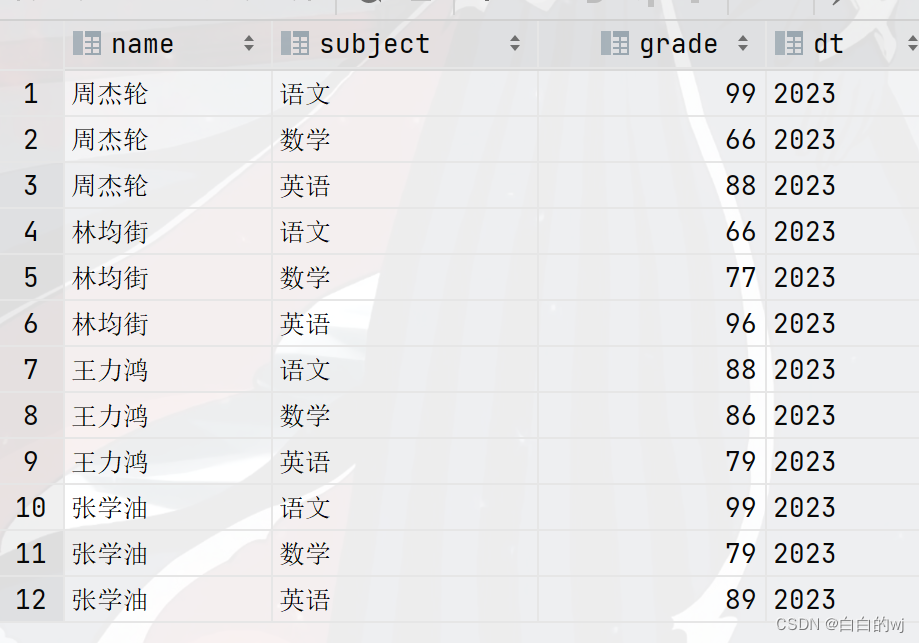
--查询数据 select * from score;--此时dt的三个年份都存在了这个表里 --如,查询2023年的数据,效率提升 select * from score where dt = '2023'; select * from score where dt = '2022'; select * from score where dt = '2024';
可以直接根据年份作为条件来查询表的内容,结果如下
2.一级分区表练习2
1.建表
--练习2建一个新表,-- 创建分区表: create [external] table [if not exists]
-- 表名(字段名 字段类型 , 字段名 字段类型 , ... )
-- partitioned by (分区字段名 分区字段类型) ;
--建表
create table one_part_order(
oid string,
name string,
price double,
num int
)partitioned by (year string)
row format delimited
fields terminated by ' ';2.加载数据
四个order.txt文件如下
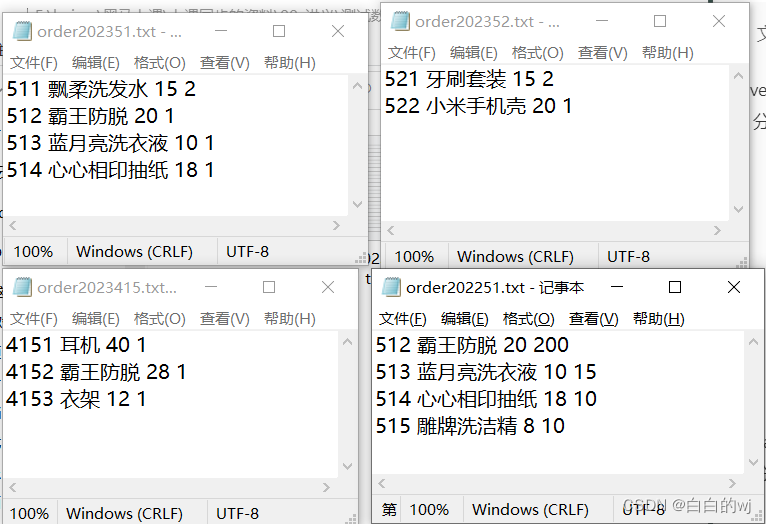
--加载数据,现在hdfs中准备好文件,再使用load加载数据到分区表中
load data inpath '/itcast/order202251.txt'
into table one_part_order partition (year='2022');
load data inpath '/itcast/order2023415.txt'
into table one_part_order partition (year='2023');
load data inpath '/itcast/order202351.txt'
into table one_part_order partition (year='2023');
load data inpath '/itcast/order202352.txt'
into table one_part_order partition (year='2023');3.验证数据
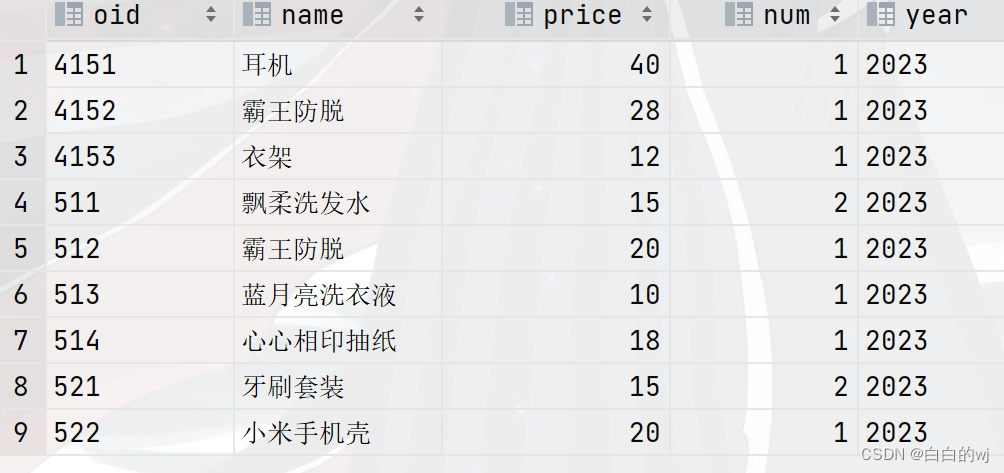
select * from one_part_order ;
select * from one_part_order where year = '2023';
3.创建多级分区表
创建分区表: create [external] table [if not exists] 表名(字段名 字段类型 , 字段名 字段类型 , ... )partitioned by (一级分区字段名 分区字段类型, 二级分区字段名 分区字段类型 , ...) ; 自动生成分区目录并插入数据: load data [local] inpath '文件路径' into table 分区表名 partition (一级分区字段名='值',二级分区字段名='值' , ...); 注意: 如果加local后面文件路径应该是linux本地路径,如果没有加那么就是hdfs文件路径
1.建表
--删表
drop table more_part_order;
truncate table multi_part_order;
--建表
create table multi_part_order(
oid string,
pname string,
price double,
num int)partitioned by (year string,month string,day string)
row format delimited
fields terminated by ' ';或者
--建表
create table multi_part1_order(
oid string,
pname string,
price double,
num int)partitioned by (year string,month string,day string)
row format delimited
fields terminated by ' ';
2.加载数据
--加载数据
load data inpath '/itcast/order202251.txt' into table
multi_part_order partition (year='2022',month='05',day='01');
load data inpath '/itcast/order2023415.txt' into table
multi_part_order partition (year='2023',month='04',day='15');
load data inpath '/itcast/order202351.txt' into table
multi_part_order partition (year='2023',month='05',day='01');
load data inpath '/itcast/order202352.txt' into table
multi_part_order partition (year='2023',month='05',day='02');或者
--加载数据
load data inpath '/itcast/order202251.txt' into table
multi_part1_order partition (year='2022',month='2022-05',day='2022-05-01');
load data inpath '/itcast/order2023415.txt' into table
multi_part1_order partition (year='2023',month='2023-04',day='2023-04-15');
load data inpath '/itcast/order202351.txt' into table
multi_part1_order partition (year='2023',month='2023-05',day='2023-05-01');
load data inpath '/itcast/order202352.txt' into table
multi_part1_order partition (year='2023',month='2023-05',day='2023-05-02');
3.验证数据
--验证数据
select * from multi_part1_order;
select * from multi_part1_order where day = '2023-05-01'; 需求1:查询日期为2023年5月1日的商品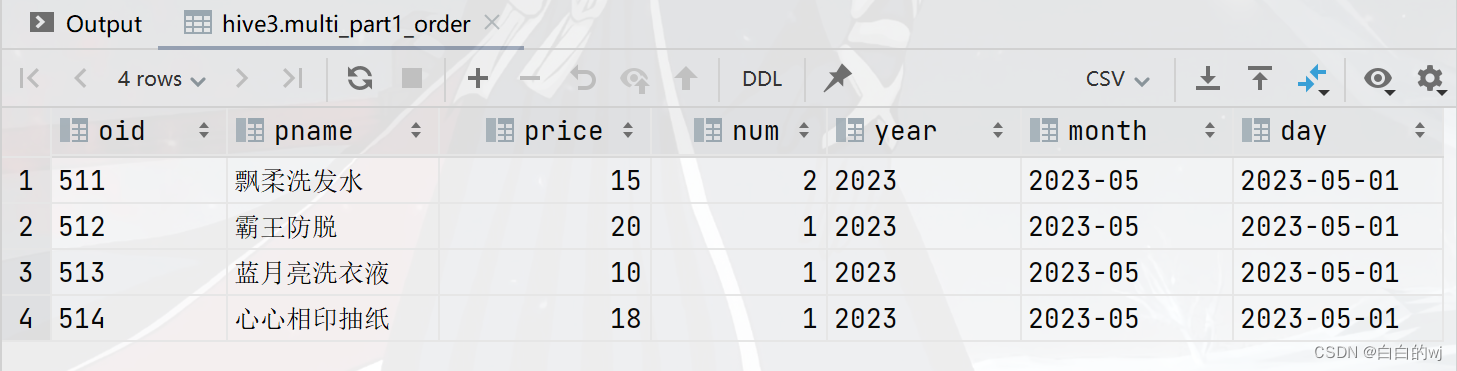
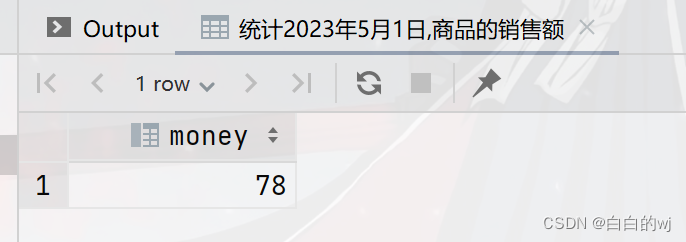
需求2:统计日期2023年5月1日的商品销售额
--统计2023年5月1日,商品的销售额
select sum(price*num) as money from multi_part_order
where year='2023'and month='05'and day='01';
4.分区表操作
添加,删除
--------------------------------分区表操作------------------------------
--添加分区:alter table 分区表名 add partition (分区字段名='值',....);
select * from multi_part1_order;
alter table multi_part1_order add partition (year='2024',month='5',day='01');
--删除分区:alter table 分区表名 drop partition(分区字段名='值',....);
alter table multi_part1_order drop partition (year='2024');
alter table multi_part1_order drop partition (year='2024',month='5',day='01');
alter table multi_part1_order drop partition (year='2024',month='5');修改
--修改分区:alter table 分区表名 partition (分区字段名='旧值' , ...)rename to partition (分区字段名='新值' , ...);
alter table multi_part1_order partition (year='2024',month='5',day='01')
rename to partition (year='2030',month='5',day='01');
--本质上是改了原本day01,被移动.并新增了year=2024的目录查看
-- 查看所有分区: show partitons 分区表名;
show partitions multi_part1_order;
-- 同步/修复分区: msck repair table 分区表名;
msck repair table multi_part1_order;5.分桶表
创建基础分桶表:
create [external] table [if not exists] 表名(字段名 字段类型 )clustered by (分桶字段名)
into 桶数量 buckets ;
1.建表
- 创建基础分桶表:
-- create [external] table [if not exists] 表名(字段名 字段类型)clustered by (分桶字段名)into 桶数量 buckets ;
--建表
create table course_base(
cid int,
cname string,
sname string
)clustered by (cid) into 3 buckets
row format delimited fields terminated by '\t';2.加载数据
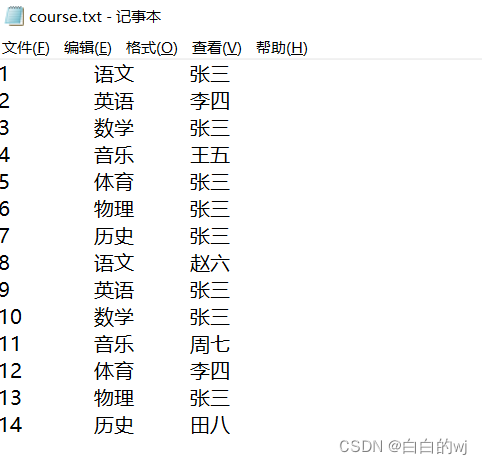
--加载数据 load data inpath '/itcast/course.txt'into table course_base;
3.验证数据
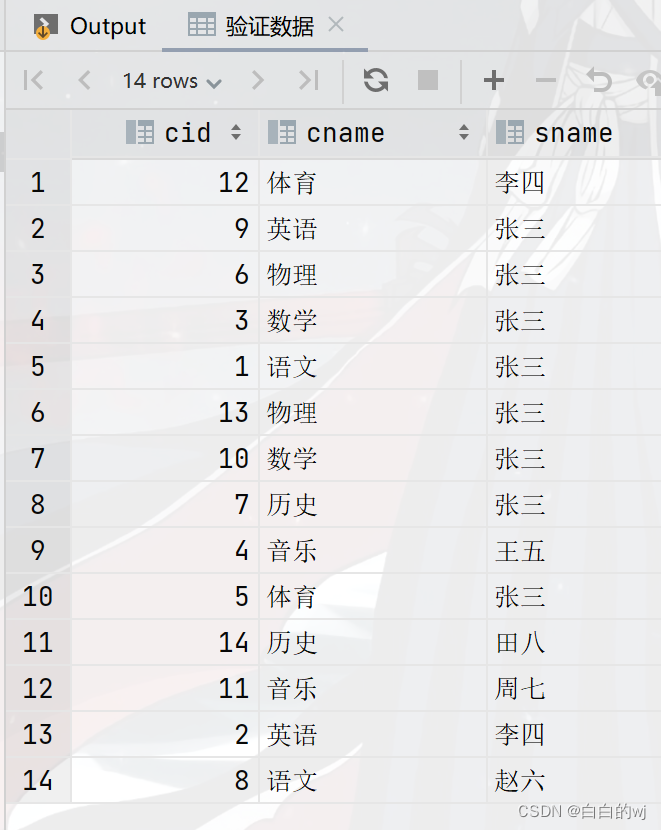
--验证数据
select * from course_base;
--取余数:12/3余0, 9/3余0 , 6/3余0 , 3/3余0 ,1/3余1 ,13/3余1....
6. 分桶表进行排序
--创建基础分桶表,要求分3个桶,桶内根据cid排序 -- 创建基础分桶表,然后桶内排序: -- create [external] table [if not exists] 表名(字段名 字段类型) -- clustered by (分桶字段名)sorted by(排序字段名 asc|desc) # 注意:asc升序(默认) desc降序 -- into 桶数量 buckets ;
1.创建表
--创建分桶表
truncate table course_sort;
create table course_sort(
cid int,
cname string,
sname string
)clustered by (cid) sorted by (cid desc )into 3 buckets
row format delimited fields terminated by '\t';2.加载数据
--加载数据
load data inpath '/input/course.txt'into table course_sort;3. 验证数据
--验证数据
select * from course_sort ;
--生成的三个文件,000000_0 , 000001_0, 000002_0
--验证余数:12/3=0 9/3=0 6/3=0 3/3=0
-- 13/3=1 10/3=1 7/3=1 4/3=1 1/3的结果是0,余1
-- 14/3=2 11/3=2 8/3=2 5/3=2

7.分桶的原理
分桶原理:
如果是数值类型分桶字段: 直接使用数值对桶数量取模
如果是字符串类型分桶字段: 底层会使用hash算法计算出一个数字然后再对桶数量取模
Hash: Hash是一种数据加密算法,其原理我们不去详细讨论,我们只需要知道其主要特征:同样的值被Hash加密后的结果是一致的
举例: 字符串“binzi”被Hash后的结果是93742710(仅作为示意),那么无论计算多少次,字符串“binzi”的结果都会是93742710。
计算余数: hash('binzi')%3==0
注意: 同样的数据得到的结果一致,如’binzi’ hash取模结果是0,无论计算多少次,它的取模结果都是0
8.hive的复杂类型

---------------------------复杂类型建表格式------------------------ -- 复杂类型建表格式: [row format delimited] # hive的serde机制 [fields terminated by '字段分隔符'] # 自定义字段分隔符固定格式 [collection ITEMS terminated by '集合分隔符'] # 自定义array同类型集合和struct不同类型集合 [map KEYS terminated by '键值对分隔符'] # 自定义map映射kv类型 [lines terminated by '\n'] # # 默认即可 hive复杂类型: array struct map
9.array类型: 又叫数组类型,存储同类型的单数据的集合
-- array类型: 又叫数组类型,存储同类型的单数据的集合 -- 建表指定类型: array<数据类型> -- 取值: 字段名[索引] 注意: 索引从0开始 -- 获取长度: size(字段名) -- 判断是否包含某个数据: array_contains(字段名,某数据)
需求: 已知data_for_array_type.txt文件,存储了学生以及居住过的城市信息,要求建hive表把对应的数据存储起
1.创建表
----建表,
create table test_array_1(
name string,
location array<string>
)row format delimited
fields terminated by '\t'
collection items terminated by ',';2.加载数据

--加载数据
load data inpath '/itcast/data_for_array_type.txt' into table test_array_1;3.验证数据
--验证数据
select * from test_array_1;
--zhangsan,"[""beijing"",""shanghai"",""tianjin"",""hangzhou""]"
--wangwu,"[""changchun"",""chengdu"",""wuhan"",""beijin""]"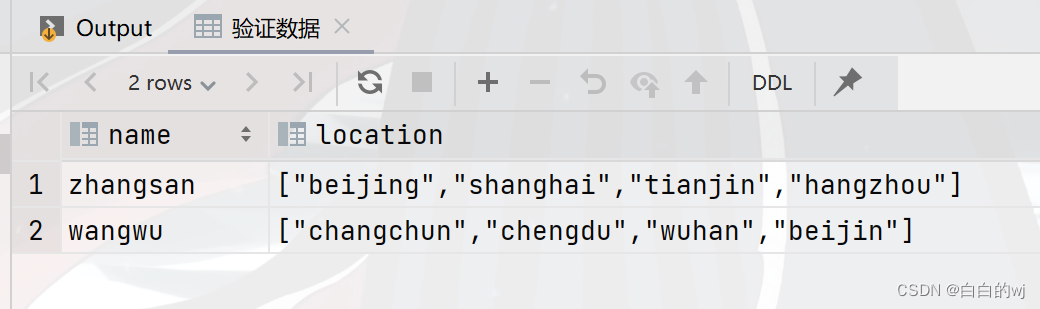
4.需求:查询张三是否在天津住过?
select array_contains(location,'tianjin')from test_array_1 where name = 'zhangsan';
--结果:true5. 需求:查询张三的地址有几个?
select size(location)from test_array_1 where name = 'zhangsan';
--结果:46.需求:查询王五的第二个地址?
select location[1] from test_array_1 where name = 'wangwu';
--结果:chengdu10.struct类型: 又叫结构类型,可以存储不同类型单数据的集合
-- 建表指定类型: struct<子字段名1:数据类型1, 子字段名2:数据类型2 , ...> -- 取值: 字段名.子字段名n
1.建表
-- 建表
create table test_struct_1(
id int,
name_info struct<name:string,age:int>
)row format delimited fields terminated by '#'
collection items terminated by ':';2.加载数据
--加载数据
load data inpath '/itcast/data_for_struct_type.txt' into table test_struct_1;
3.验证数据
--验证数据
select * from test_struct_1;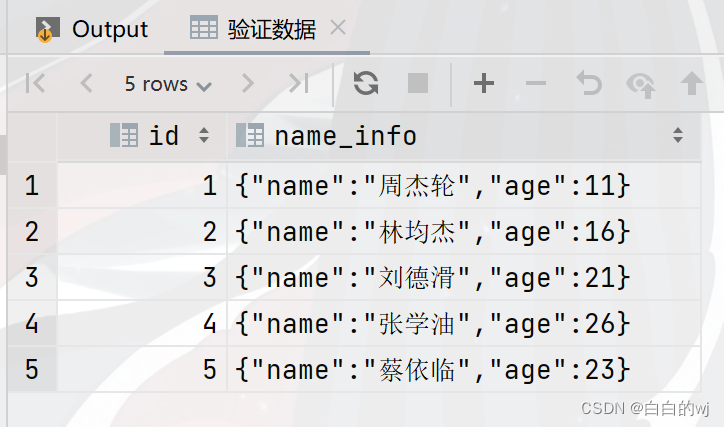
需求1:查询所有用户姓名
select name_info.name from test_struct_1;需求2:查询所有的用户年龄
select name_info.age from test_struct_1;需求3:查询所有用户的平均年龄
11.map类型: 又叫映射类型,存储键值对数据的映射(根据key找value)
-- 建表指定类型: map<key类型,value类型> -- 取值: 字段名[key] -- 获取长度: size(字段名) -- 获取所有key: map_keys() -- 获取所有value: map_values()
1.创建表
--创建表
create table test_map_1(
id int,
name string,
members map<string,string>,
age int
)row format delimited
fields terminated by ','
collection items terminated by '#'
map keys terminated by ':';2.加载数据
-- 加载数据
load data inpath '/itcast/data_for_map_type.txt'into table test_map_1;
3.验证数据
--验证数据
select * from test_map_1;
-- 1,林杰均,"{""father"":""林大明"",""mother"":""小甜甜"",""brother"":""小甜""}",28
-- 2,周杰伦,"{""father"":""马小云"",""mother"":""黄大奕"",""brother"":""小天""}",22
-- 3,王葱,"{""father"":""王林"",""mother"":""如花"",""sister"":""潇潇""}",29
-- 4,马大云,"{""father"":""周街轮"",""mother"":""美美""}",26需求1:查询每个学生的家庭成员关系(就是所有的key)
select name,map_keys(members) from test_map_1;需求2:查询每个学生的家庭成员姓名(就是所有的value)
select name ,map_values(members) from test_map_1;需求3:查询每个学生和对应的父亲名字
select name,members['father'] as father from test_map_1;需求4:查询马大云是否有兄弟
select name,array_contains(map_keys(members),'brother') from test_map_1 where name ='马大云';
-- 需求5:查询每个学生的对应brother姓名,没有brother的学生null补全 -- 需求6:查询每个学生的对应brother姓名,没有brother的学生直接不显示