目录
一、归并排序
1、主函数
2、递归实现
3、优化递归
4、非递归实现
5、特性总结:
二、计数排序
1、代码:
2、特性总结:
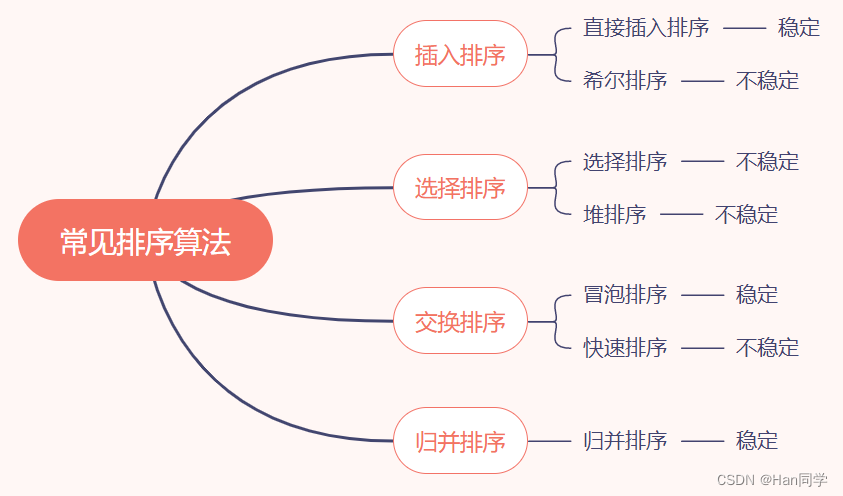
三、各种排序稳定性总结
一、归并排序
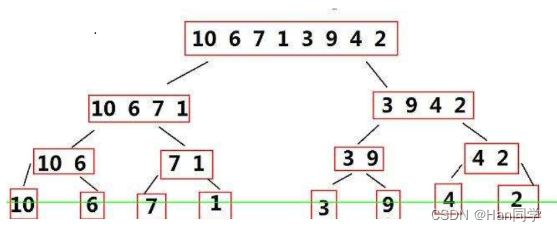
基本思想: 归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
偶数个元素的归并逻辑图:
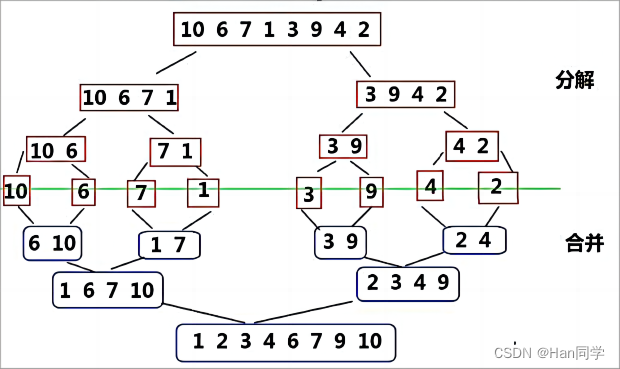
奇数个元素的归并动图: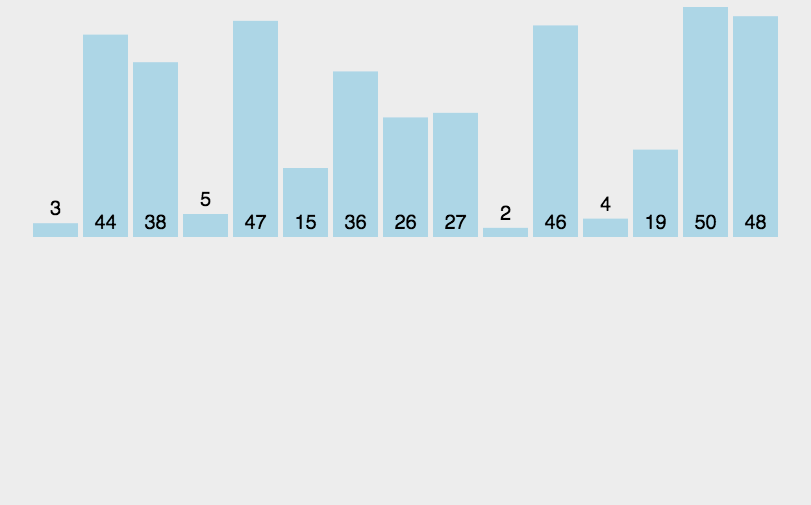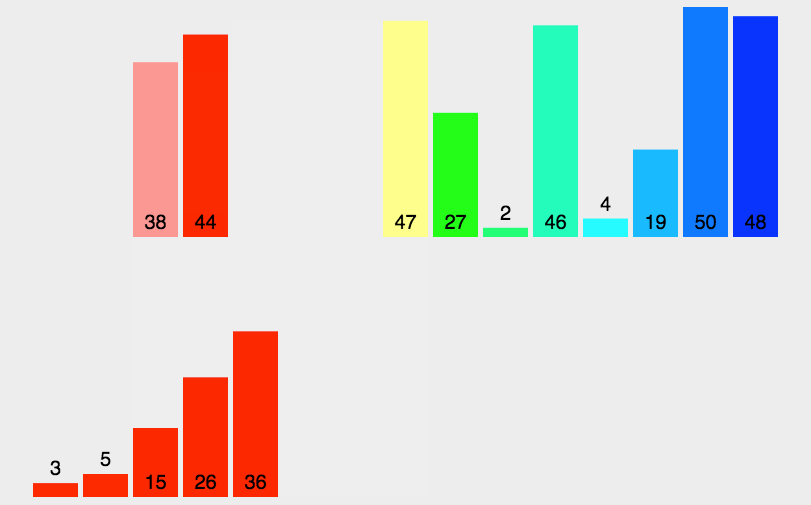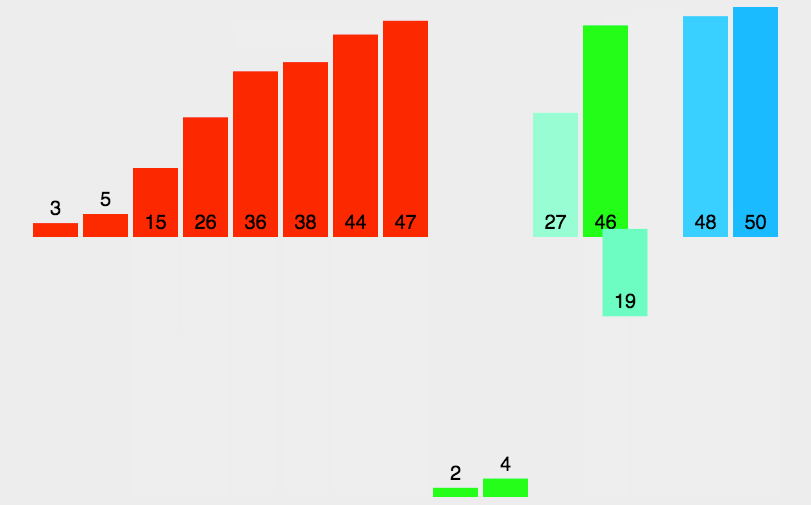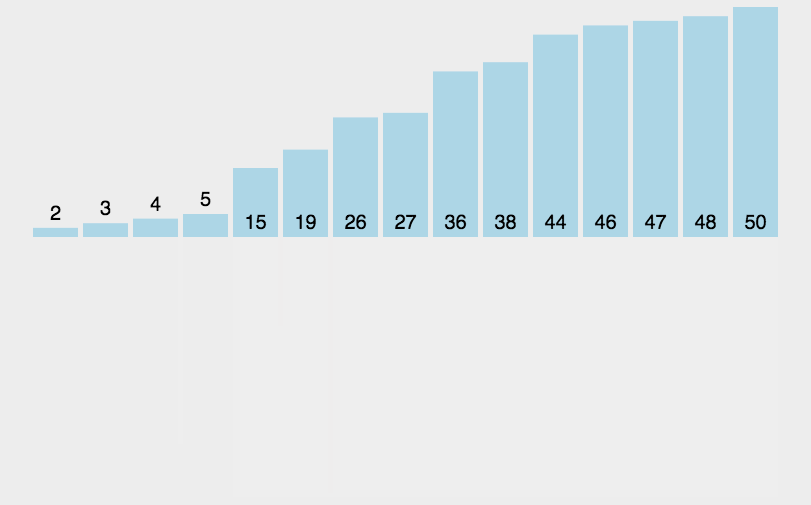
这里谈到元素的偶数奇数个数,我们在代码中会讲解如何处理。
我们先从偶数个元素的数组讲解 :
1、主函数
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
}我们的思路是取出数组元素,排序后插入创建的 tmp数组中,全部有序后将tmp数组拷贝给原数组。
- 主函数接受两个参数,一个整数数组
a和一个整数n,n 表示数组的长度。 - MergeSort 函数首先为tmp数组开辟待空间。
- 调用_MergeSort函数进行排序。
- 释放tmp的空间。
2、递归实现
void _MergeSort(int* a, int begin, int end, int* tmp)
{
if (begin == end)
return;
int mid = (begin + end) / 2;
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}我们先看函数是如何比较每部分的:
- 首先计算中间位置
mid,并递归地对数组的两部分进行排序。这是分治的思想,将大问题分解成小问题,使用四个指针begin1和begin2、end1和end2,分别指向两个部分的开始位置和结束位置,- 然后看三个while循环的比较插入过程,每次分割后两部分分别从头开始比较,把较小的插入tmp数组,某一部分的数全部插入数组后,结束第一个while循环。继续检查哪个数组还有剩余元素,剩下的都是较大的,直接插入tmp数组中。
下面以数组{1,6,7,10,2,3,4,9}进行比较插入:
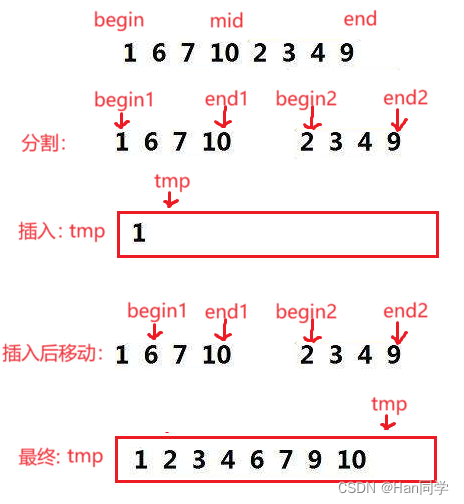
递归思路 :
接下来,我们需要从最小的子序列到最大依次往上进行排序插入,所以这里引用递归的思想完成排序:
- 在函数_MergeSort中,首先判断begin是否等于end,如果相等,则当前子序列只有一个元素,不需要排序,直接返回。
- 如果不相等,则计算中间位置mid,然后递归调用_MergeSort函数对左半部分和右半部分进行排序。在排序完成后,将左半部分和右半部分合并成一个有序数组tmp。
if (begin == end)
return;
int mid = (begin + end) / 2;
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);每层递归排序后,使用memcpy函数将临时数组tmp中的元素复制回原数组a中。
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
3、优化递归
先观察一下哪里做了优化 ?
void _MergeSort(int* a, int begin, int end, int* tmp)
{
if (begin == end)
return;
if (end - begin + 1 < 10)
{
InsertSort(a+begin, end - begin + 1);
return;
}
int mid = (begin + end) / 2;
// [begin, mid] [mid+1, end]
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid+1, end, tmp);
int begin1 = begin, end1 = mid;
int begin2 = mid+1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a+begin, tmp+begin, sizeof(int) * (end - begin + 1));
}通过观察发现,这个递归实现与刚才的多了一个“插入排序”实现小区间优化,我们来看看它有什么用处:
// 小区间优化
if (end - begin + 1 < 10)
{
InsertSort(a+begin, end - begin + 1);
return;
}我们借助例子进行分析:
假如我们有10000个待排序的数据,每次通过递归依次往下调用 ,这样会调用很多次函数。
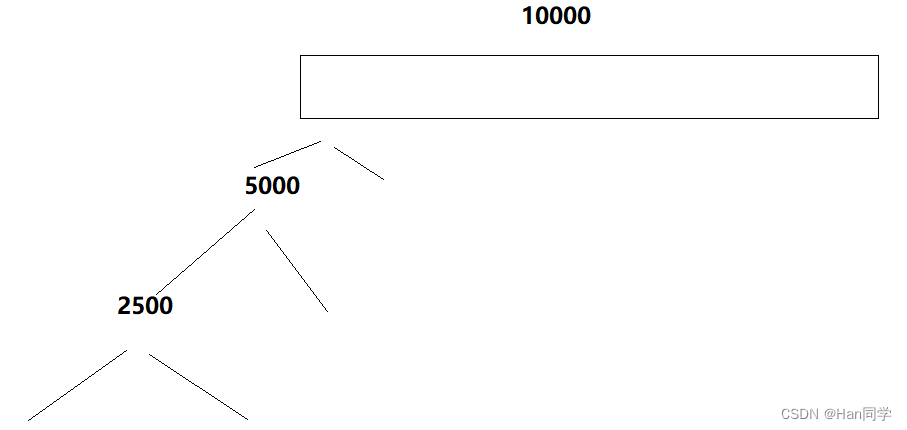
我们可以将分割到数据总数较小时,调用插入排序进行辅助处理,不再递归处理,下面来一一解释 :
当数组元素总数为10时,会向下递归调用三层。
通过二叉树的学习,我们可以借助二叉树知识来理解如何提高效率:
用插入排序处理元素总数为10的情况,就是处理递归的倒数三层,通过二叉树的节点数计算可以得知函数调用次数,由图可知:最后三层占据87.5%的调用次数,我们解决这三层实现了递归的优化,即对元素总数为10的情况插入排序。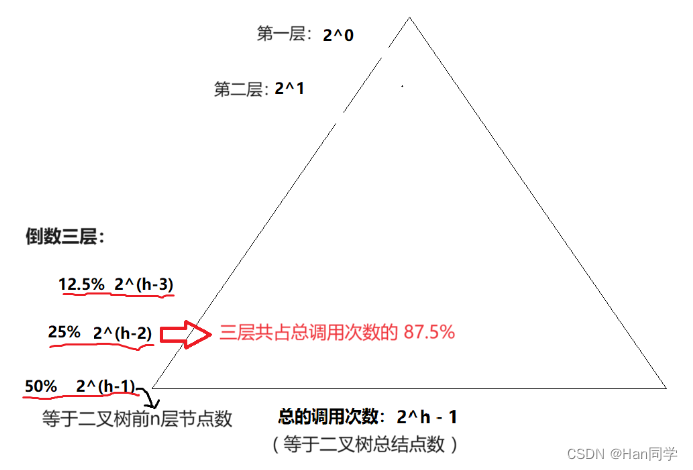
4、非递归实现
通过gap控制归并的子数组大小实现非递归的归并排序
我们可以先将gap初始化为1,然后每次将gap乘以2,直到gap大于等于数组的长度为止。在每次循环中,我们将数组分成若干个大小为gap的子数组,然后对每个子数组进行排序和合并。这样,我们就可以通过循环来实现归并排序,而不需要使用递归。
在非递归中有些尾部的特殊情况,代码的修正部分进行了处理,现在让我们进入代码的讲解:
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
// 1 2 4 ....
int gap = 1;
while (gap < n)
{
int j = 0;
for (int i = 0; i < n; i += 2 * gap)
{
// 每组的合并数据
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//修正
if (end1 >= n || begin2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
// 归并一组,拷贝一组
memcpy(a+i, tmp+i, sizeof(int)*(end2-i+1));
}
gap *= 2;
}
free(tmp);
}
- 首先,代码中定义了一个临时数组 tmp,用于存储归并排序中的中间结果。然后,通过一个 while 循环,不断增加 gap 的值,每次将数组分成若干个长度为 gap 的子数组,对每个子数组进行归并排序。
- 然后解决数组越界问题:
- 第一种方法:每个合并段进行局部复制,
- 第一种情况一组的第二部分全部越界,第一部分部分越界,则不进行排序归并,有效的元素留到恰当的gap分组进行归并排序,也就是当 end1 或 begin2 超出数组 a 的范围时,需要退出循环;
- 第二种情况一组部分未越界,另一部分部分越界,则将未越界部分,也就是当 end2 越界而 begin2 未越界时,需要将 end2 修正为 n-1。
- 在每个子数组中,通过一个 for 循环,将子数组分成两个部分,分别为 [begin1, end1] 和 [begin2, end2]。然后,通过两个 while 循环,将这两个部分中的元素按照从小到大的顺序合并到 tmp 数组中。
- 内层三个while循环结束后,通过 memcpy 函数将 tmp 数组中当前合并完成的元素拷贝回原数组 a 中,防止覆盖原数组丢失数据,因为tmp数组还有不符合归并要求的数据位置。
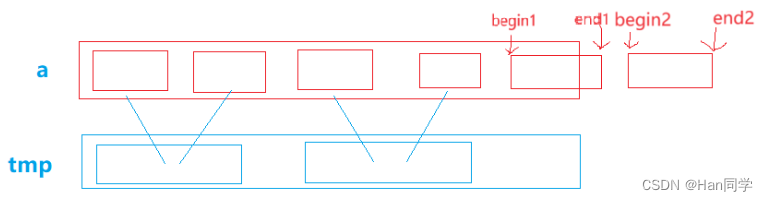
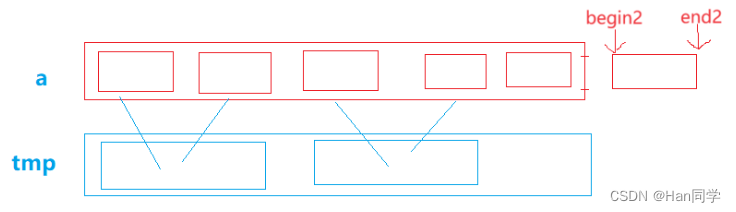
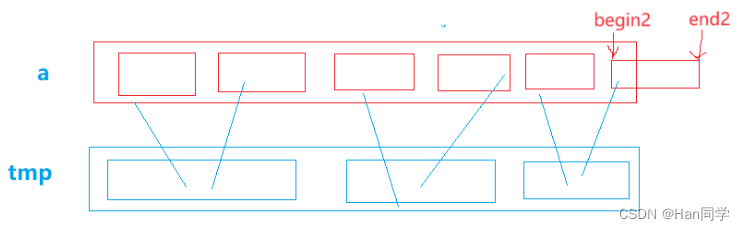
除了上诉讲解中的处理数组越界的方法,还有第二种方法
第二种: 每轮合并后进行全局复制
if (end1 >= n)
{
end1 = n - 1;
// 不存在区间
begin2 = n;
end2 = n - 1;
}
else if (begin2 >= n)
{
// 不存在区间
begin2 = n;
end2 = n - 1;
}
else if(end2 >= n)
{
end2 = n - 1;
}
- end1 begin2 end2越界,则将第一部分中未越界的元素参与排序归并,即 end1 修正为 n-1,对于第二部分越界的,我们不需要处理,所以将begin2赋值为 n ,end2 赋值为 n-1,这样这部分为不存在的区间,不满足排序要求,不会进行处理。
- begin2 end2越界,只需将第二部分越界的begin2赋值为 n ,end2 赋值为 n-1,这样这部分为不存在的区间,不满足排序要求,不会进行处理。
- 当 end2 越界而 begin2 未越界时,需要将 end2 修正为 n-1。
- 最后注意将 memcpy 函数放在 for 循环结束后。
memcpy(a, tmp, sizeof(int) * n);
5、特性总结:
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题,思路:外存大数据排序通常需要将数据分成多个小块,每个小块可以在内存中进行排序,然后将排序好的小块写入外存中。接着,我们可以将多个排序好的小块进行归并排序,得到最终的有序序列。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
二、计数排序
计数排序是一种常见的排序算法,也被称为鸽巢原理。它是对哈希直接定址法的变形应用。
该算法的操作步骤如下:
- 统计相同元素出现的次数,将其存储在一个计数数组中。
- 根据计数数组中的统计结果,将序列中的元素回收到原来的序列中。
计数排序的优点是速度快,适用于数据范围比较小的情况。同时,该算法不需要比较元素的大小,因此在某些情况下比其他排序算法更加高效。如果需要对大量数据进行排序,可以考虑使用其他更加高效的排序算法。

1、代码:
void CountSort(int* a, int n)
{
int min = a[0], max = a[0];
for (int i = 0; i < n; i++)
{
if (a[i] < min)
{
min = a[i];
}
if (a[i] > max)
{
max = a[i];
}
}
int range = max - min + 1;
int* countA = (int*)malloc(sizeof(int) * range);
memset(countA, 0, sizeof(int) * range);
// 统计次数
for (int i = 0; i < n; i++)
{
countA[a[i] - min]++;
}
// 排序
int k = 0;
for (int j = 0; j < range; j++)
{
while (countA[j]--)
{
a[k++] = j + min;
}
}
}- 首先,代码中通过遍历数组找到了数组中的最小值和最大值,以便后面确定计数数组的大小和范围。
- 接着,代码中动态分配了一个大小为 range 的计数数组 countA,并将其初始化为 0。
- 然后,代码中遍历原始数组 a,统计每个元素出现的次数,并将其存储在计数数组 countA 中。
- 最后,代码中遍历计数数组 countA,将排序后的元素重新存储回原始数组 a 中。
- 具体来说,从计数数组的第一个元素开始遍历,如果该元素的计数值不为 0,则将其对应的元素值(即 j + min)存储到原始数组 a 的第 k 个位置上,并将 k 向后移动一位。这样,就可以将所有元素按照从小到大的顺序重新存储到原始数组 a 中,从而完成了排序。
需要注意的是,该算法的时间复杂度为 O(n + range),其中 range 表示计数数组的大小,因此当 range 比较大时,该算法的效率会变得比较低。此外,该算法只适用于元素值范围比较小的情况,如果元素值范围很大,推荐使用其他排序算法。
2、特性总结:
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(MAX(N,range))
- 空间复杂度:O(range)
三、各种排序稳定性总结
稳定性: 假定在待排序的记录列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i] = r[j],且 r[i] 在 r[j] 之前,而在排序后的序列中,r[i] 仍在 r[j] 之前,则称这种排序算法是稳定的:否则称为不稳定的。
 比如上面的情况,如果排序结束后,保证 5 在 5 前面,那这个排序就是稳定的,否则就是不稳定的。
比如上面的情况,如果排序结束后,保证 5 在 5 前面,那这个排序就是稳定的,否则就是不稳定的。




![[Go语言]SSTI从0到1](https://img-blog.csdnimg.cn/45d6d559468b42c8981b89e9fdd86548.png)

![[工业自动化-16]:西门子S7-15xxx编程 - 软件编程 - 西门子仿真软件PLCSIM](https://img-blog.csdnimg.cn/a8ac233c67454499b45cc926a8239f59.png)