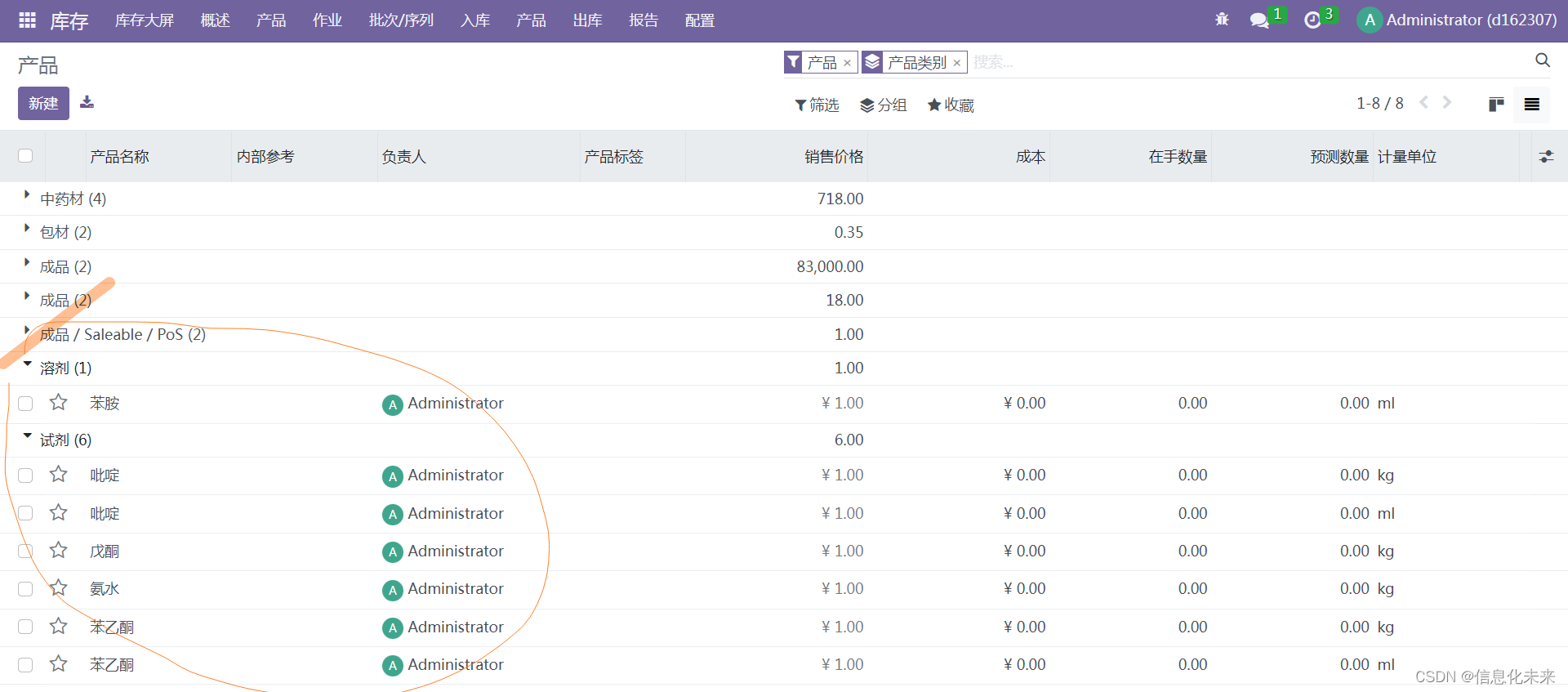
Understanding LSTM Networks
- 前言
- Recurrent Neural Networks
- The Problem of Long-Term Dependencies
- LSTM Networks
- The Core Idea Behind LSTMs
- Step-by-Step LSTM Walk Through
- Forget Gate Layer
- Input Gate Layer
- Output Gate Layer
- Variants on Long Short Term Memory
- Conclusion
前言
最近在整理LSTM相关的工作,看到了一篇非常经典的博客,遂沿着该博客的思路过了一遍LSTM,收获颇丰,故写下此篇笔记以帮助NLP初学者理解LSTM这个经典的模型,当然要想深入学习,还是看英文原版博客更合适。
| Paper | https://colah.github.io/posts/2015-08-Understanding-LSTMs |
|---|---|
| Code | https://github.com/nicodjimenez/lstm |
| From | colah’s blog |
Recurrent Neural Networks
人类总是依赖上下文进行思考的,因为你的思想存在延续性,但是传统的神经网络做不到这一点,它无法将先验知识添加进来帮助模型理解当前的场景。因此RNN应运而生,RNN作为特殊的神经网络,保留了之前学习到的内容,引入了隐状态的概念,它可以对序列信息抽取特征,作为先验信息传递下去。

上图就是一块RNN模块,输入
X
t
X_t
Xt到模块中,输出
h
t
h_t
ht,同时模块中的loop允许信息从该模块传递下去。从这个角度来看,RNN又更像神经网络了。
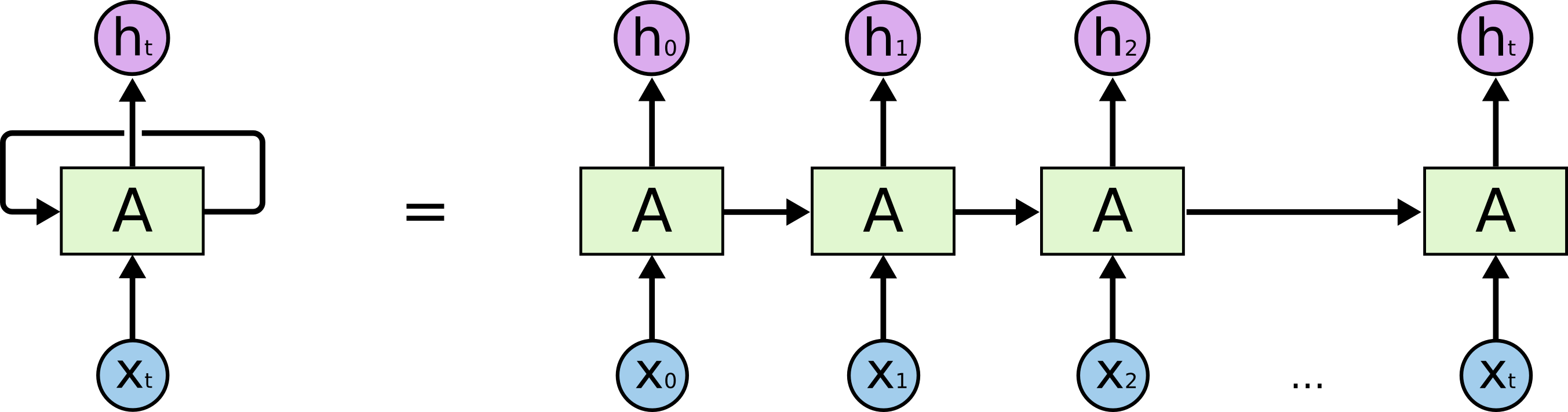
具体来说,RNN模块以链式结构连接在一起,如上图所示,这种链式的结构将上游的信息传递下去,从而使得模型能够将先验知识利用起来。RNN在语音识别、语言建模、翻译和图像识别等领域都取得了巨大的成功,不过其中最大的功臣还是LSTM,下面将讲述普通的RNN所遇到的瓶颈。
The Problem of Long-Term Dependencies
理论上,RNN利用上之前的信息可以解决当前的问题,但是这取决于序列的长短。当序列很短时,比如一句话“the clouds are in the”,模型很容易知道下一个要输出的单词是“sky”。
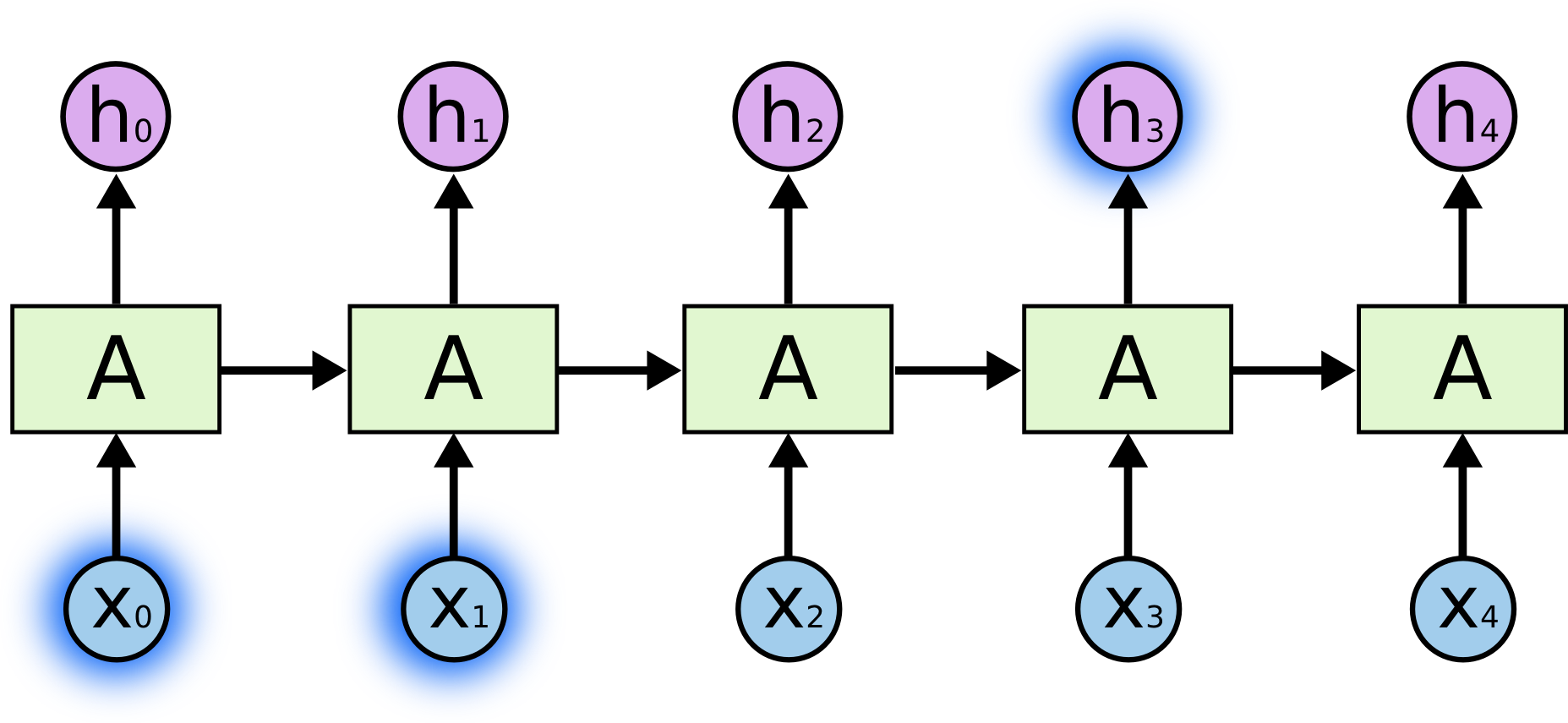
可是当序列很长时,比如一段文本“I grew up in France… I speak fluent _”,中间省略的部分包含大量的文本内容,对于人来说,由于一开始提及了France,如果多加注意,那么这里大概率会填写“French”,但是对于普通的RNN模型来说,很难将这二者关联起来。这就是长程依赖问题。
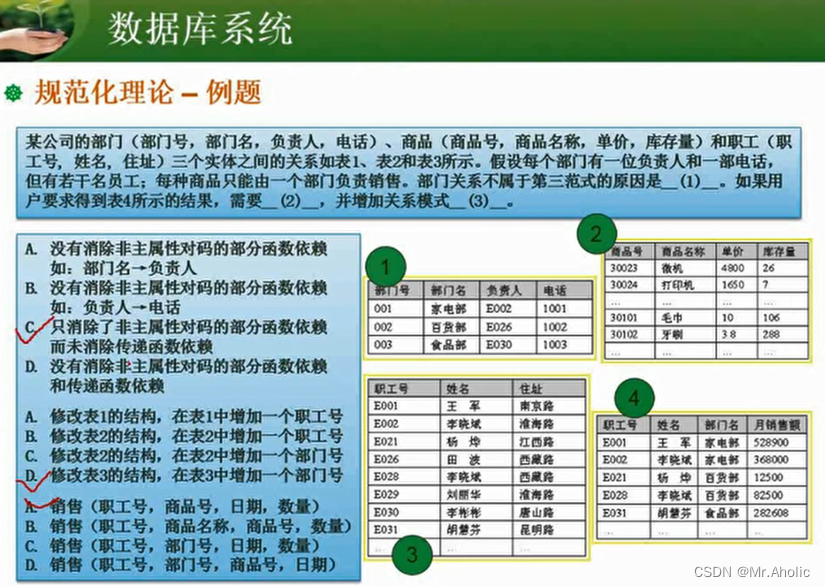
总结一下, RNN具有如下的局限性:
- 梯度消失。随着模型网络层次加深,小于1的梯度传递下去会越来越小,造成梯度消失,因此RNN只具有短时记忆。
- 梯度爆炸。本质上也是和模型深度有关,大于1的梯度会随着模型加深而爆炸式增大。
LSTM Networks
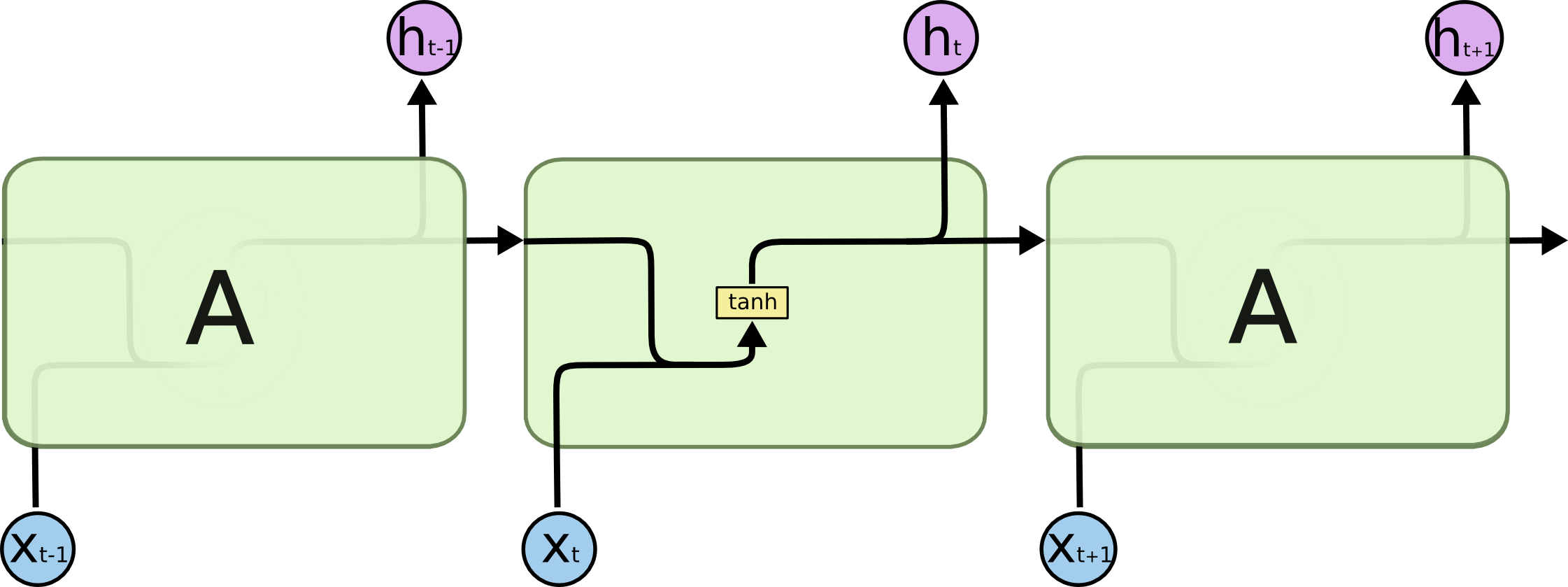
LSTM,即长短期记忆网络,是RNN的一个特例,它可以学习长程依赖,并被广泛使用。一个普通的RNN模型可以由下面的结构图表示:
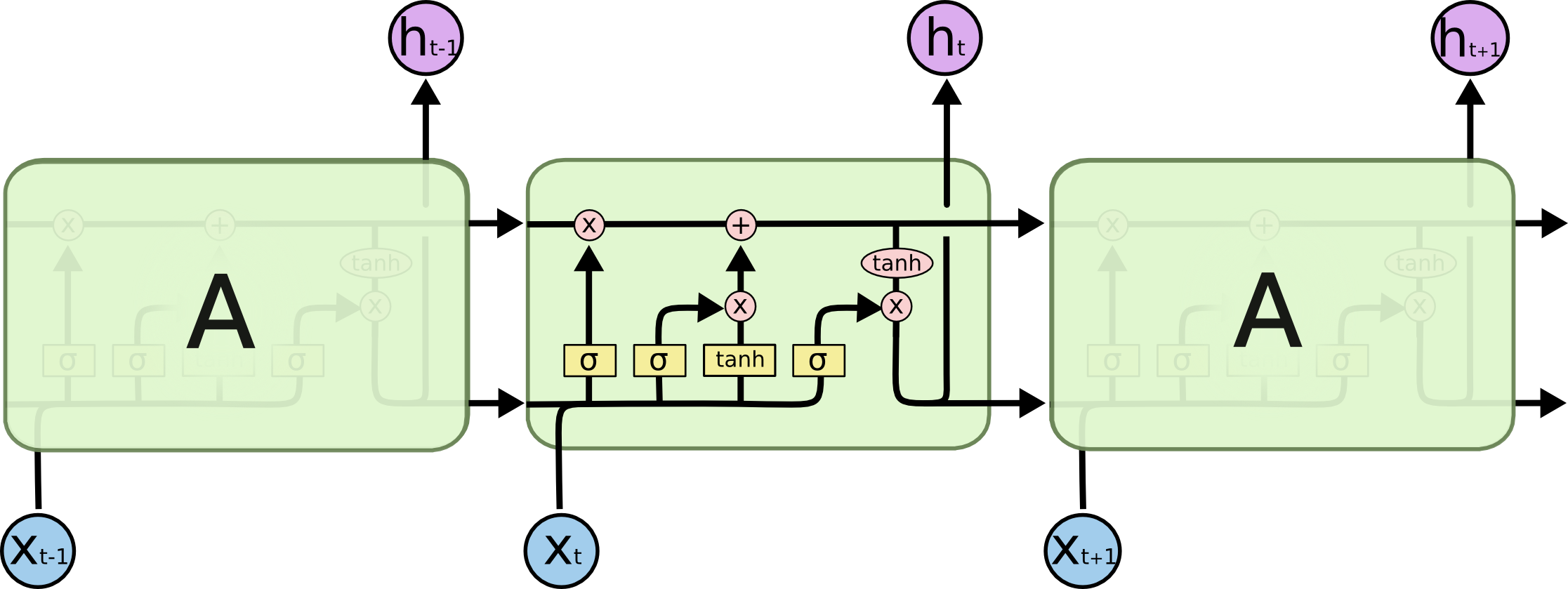
LSTM在此链式结构基础上添加了三道门控机制,使得之前单一的网络变为了四层相互作用的网络,如下图所示:
为了详细分析LSTM模型的结构,这里将介绍常用的符号及其表示:

在上面的图表中,每条线都传递着一个向量,从一个节点输出,再输入到另一个节点中;粉色的圆圈表示逐点操作,如点乘或者点加;合并的箭头表示将两个向量进行拼接(concatenation),分开的箭头表示将一个向量进行复制,然后输入到不同的节点中。
The Core Idea Behind LSTMs
LSTMs的关键在于cell的状态,即下图中加粗的水平横线。
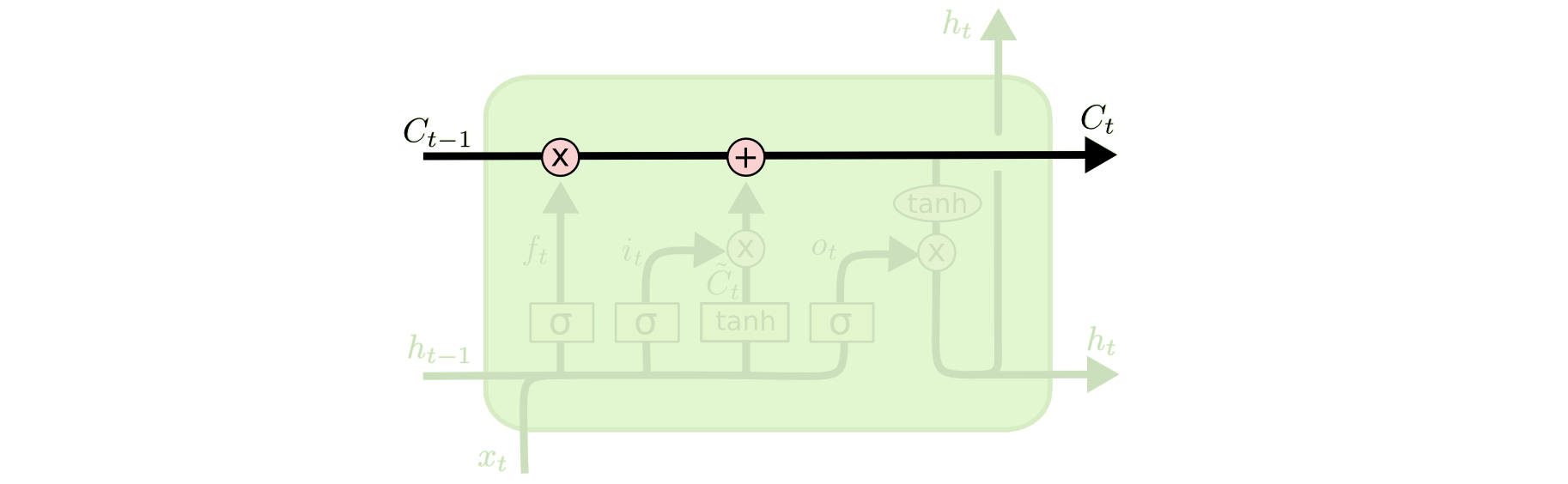
cell的状态类似一种传输带,它横穿整个链,只做了少量的线性操作。这种结构可以轻松实现信息不变传递。当然,LSTM也具有向cell移出、添加信息的能力,由门的结构来实现。
门让信息可选通过,它通过sigmod激活函数和点乘操作实现。
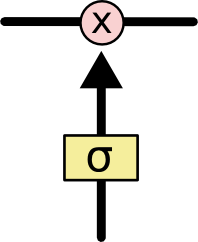
sigmoid激活函数让输入的信息的值限定在0到1的范围,决定了允许多少比例的信息流出,0即不允许信息流出,1即让所有信息传递下去。一个LSTM具有三种不同结构的门,分别是遗忘门、 输入门和输出门,用于保护和控制cell的状态。
Step-by-Step LSTM Walk Through
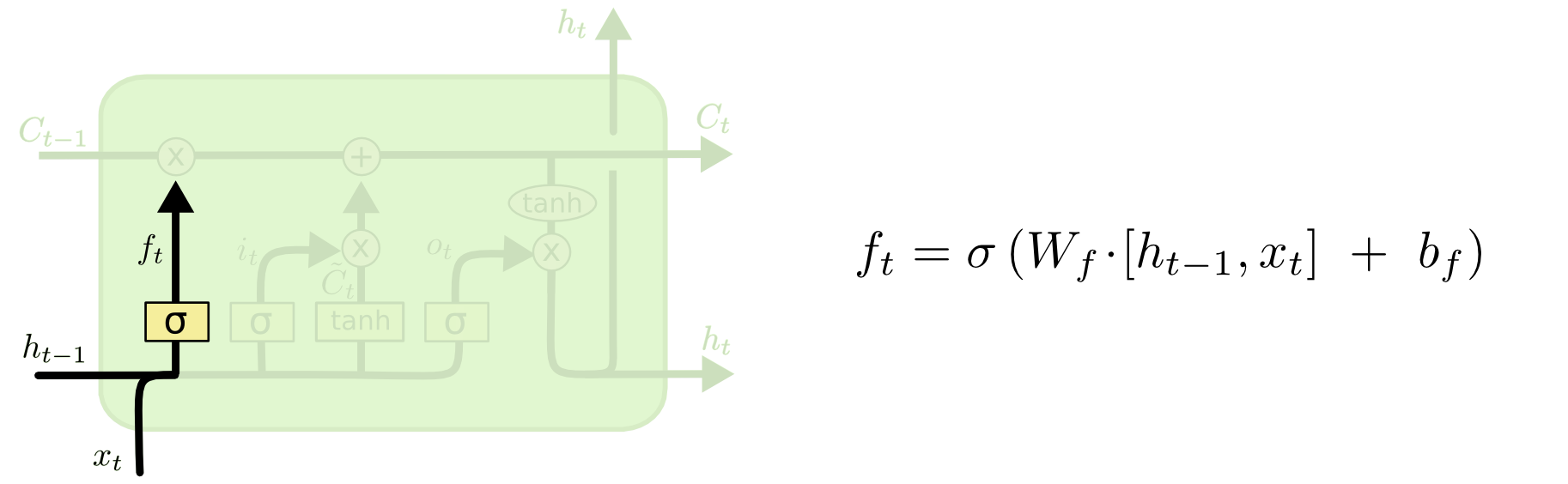
Forget Gate Layer
第一个门是遗忘门,决定多少信息可以继续通过这个cell,输入是
x
t
x_t
xt和
h
t
−
1
h_{t-1}
ht−1,输出是每个数值都在0-1范围的向量,其长度和cell状态
C
t
−
1
C_{t-1}
Ct−1一致,表示让多少上游信息继续传递下去。
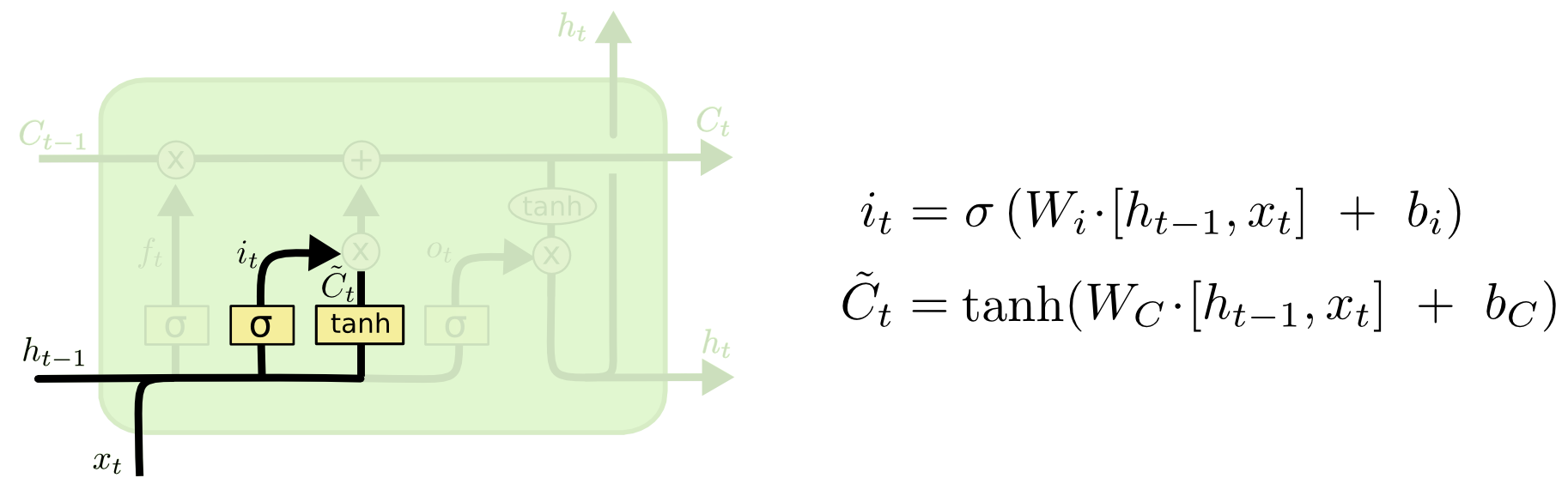
Input Gate Layer
接着下一步,对于当前的新信息,决定有哪些需要存储到cell状态中。它分为两个部分:
- 输入门的sigmoid层决定哪些信息需要更新
- 输入门的tanh层创建候选向量 C ~ t \tilde{C}_{t} C~t,用于作为新信息加入到cell状态中。
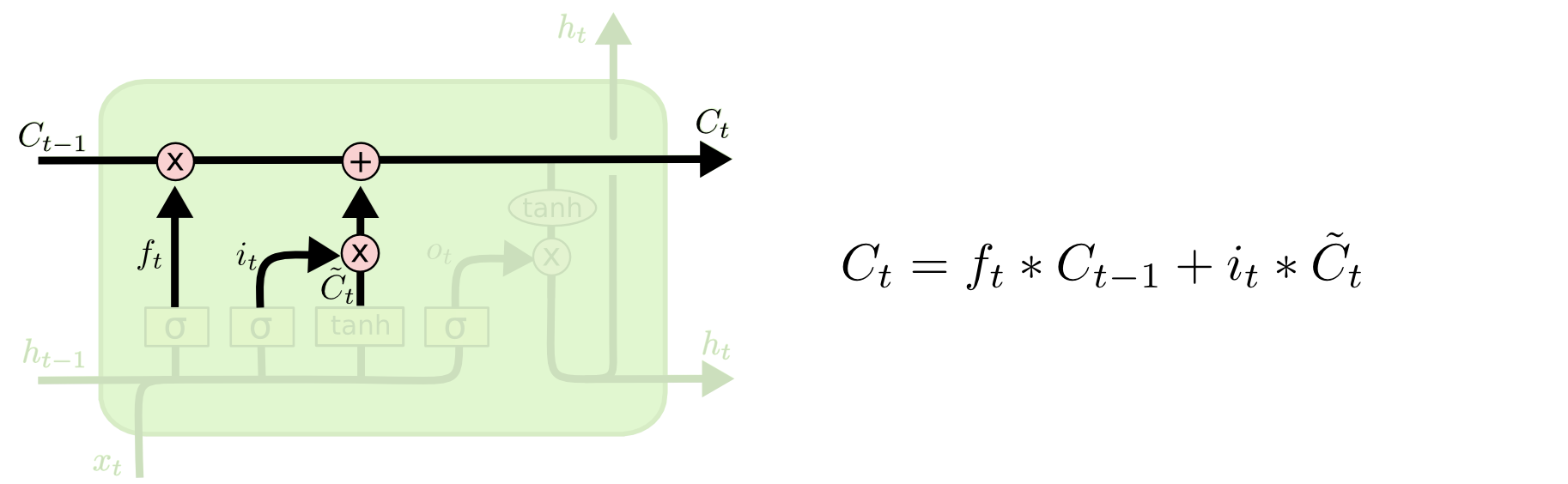
上面两层输出相乘即得到需要更新到状态的信息。旧状态
C
t
−
1
C_{t-1}
Ct−1与
f
t
f_{t}
ft相乘再和需要更新的新状态想相加,就得到了更新后当前cell的状态。如下图所示:
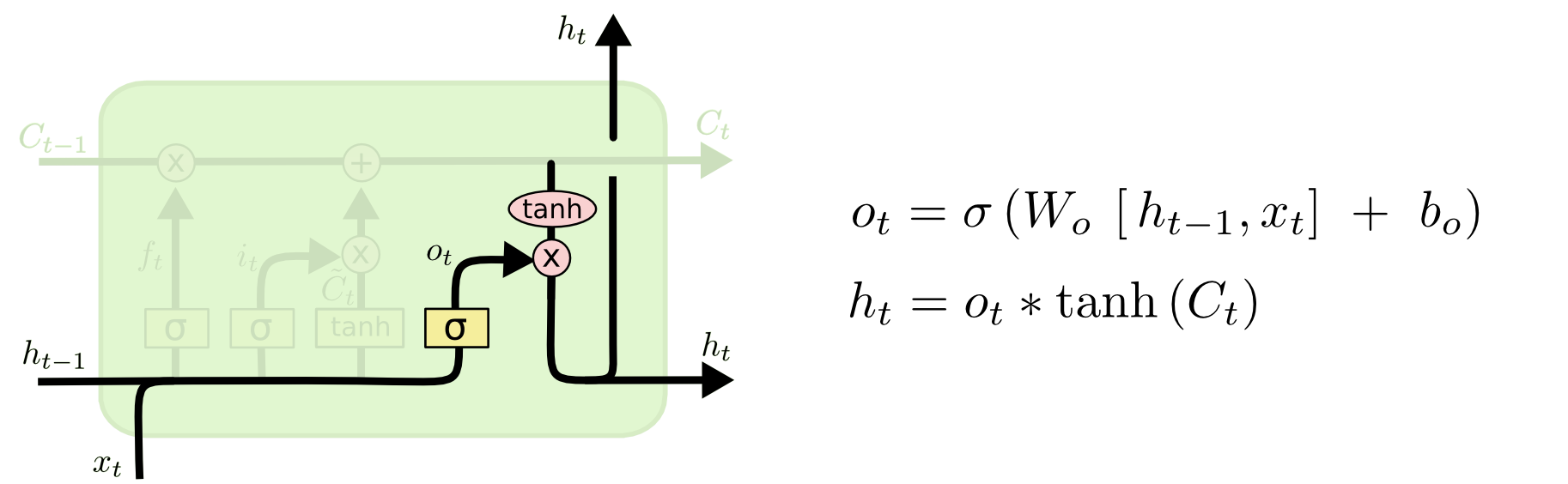
Output Gate Layer
最后,对于当前的模块,我们需要决定输出什么样的值。这个输出主要依赖于cell的状态
C
t
C_{t}
Ct。首先需要一个sigmoid层来决定
C
t
C_{t}
Ct中的哪些信息会被输出,接着把
C
t
C_{t}
Ct通过一个Tanh层,将该层的输出与sigmoid层的权重相乘,得到了最后的输出结果。
Variants on Long Short Term Memory
在LSTM出现之后,又涌现出很多LSTM的变体。一个变体来自Gers & Schmidhuber (2000),它加入了“peephole connections”层,意思是让所有的门层都看向cell状态。
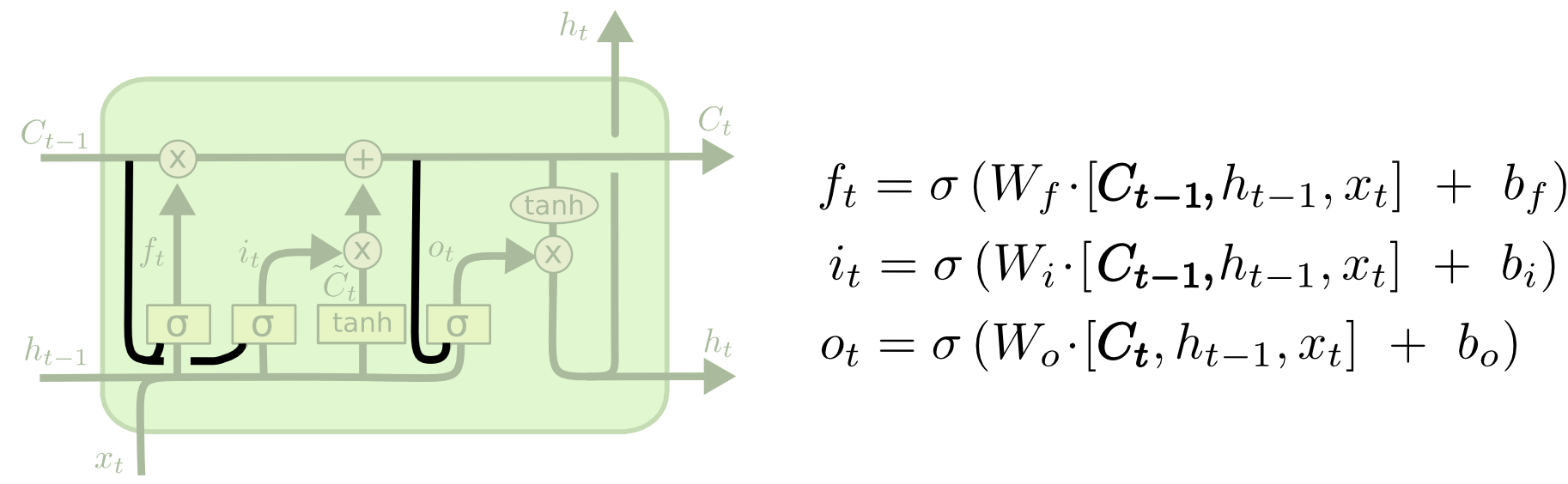
另一个变体将遗忘门和输入门连接起来,当需要遗忘和输入新信息时,同时做出决定。这比较符合人类的认知,当我们输入新的东西时我们才会遗忘,当我们遗忘旧的知识时,就需要新的知识来补充。
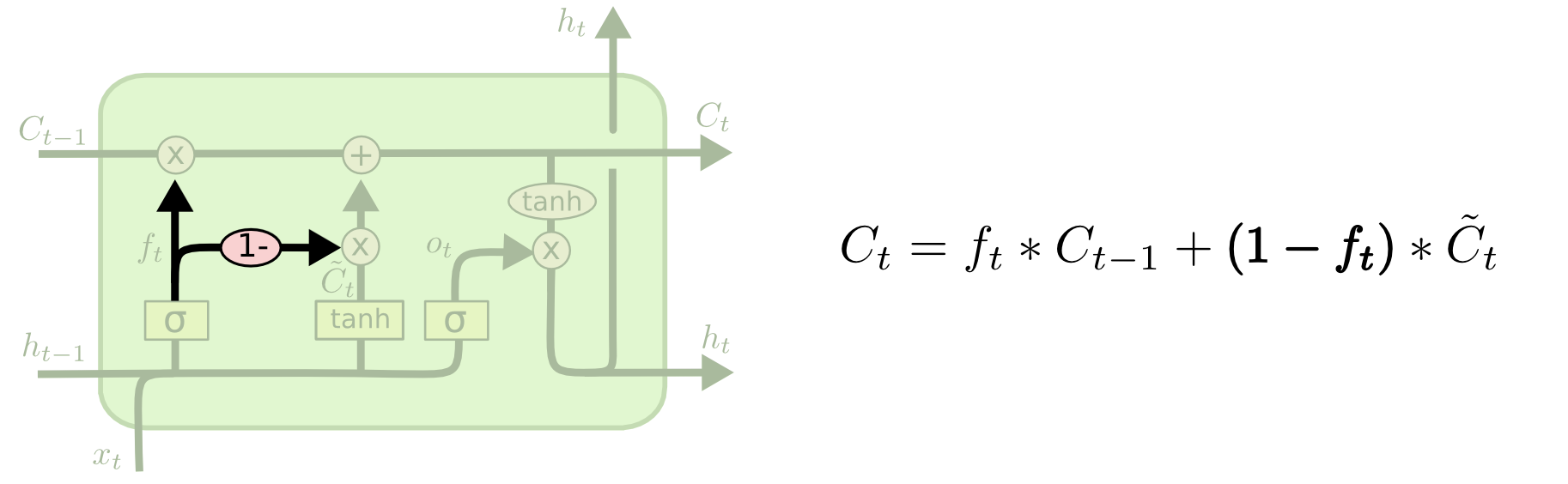
最经典的变体当然还是GRU,它只有两个门:重置门和更新门,重置门即
r
t
r_{t}
rt,它决定是否重置上一时刻信息,更新门
z
t
z_{t}
zt相当于将LSTM的遗忘门和输入门合并到了一起,它将当前的信息和上一时刻的信息进行合并。

GRU与LSTM有如下的对比:
- GRU少一个门,同时少了cell状态。
- LSTM通过遗忘门和输入门来控制信息的传输,而GRU通过重置门来决定是否保留原来的隐藏状态。
Conclusion
LSTM在许多任务上都取得了显著的成功,但是注意力机制的出现进一步吸引科研人员的目光,它可以对更长的序列进行建模,并且支持并行计算,大大提高了模型的效率,这也就是后来的基于Transformer的一系列模型,如今Transformer的影响已经涉及到AI的各个领域,LLM的出现又进一步推动了AIGC的发展。正所谓星星之火可以燎原,谁能想到,当年RNN的一小步,竟然造就了AI如此辉煌的今天!