目录
- 通信机制
- 同步Synchronous
- 异步Asynchronous
- 半同步/延时同步
- 通信的拓扑结构
- 基于迭代式MapReduce的通信(同步模式)
- 基于MPI之AllReduce的通信(同步模式)
- AllReduce有很多变种
- 基于参数服务器的通信(多为异步)
- 去中心化算法
- D-PSGD
- 通信频率及通信量
- 降低通信频率
- 降低通信时间-通信隐藏
- 减少通信数据量:梯度压缩
- 梯度稀疏化
- 模型低秩化处理
- 梯度量化
- 总结
通信机制
同步Synchronous
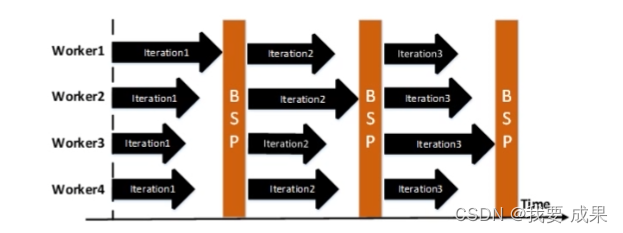
基于同步障
步调一致,收敛性有保证
等待严重,延迟大
Bulk Synchronous Parallel
异步Asynchronous
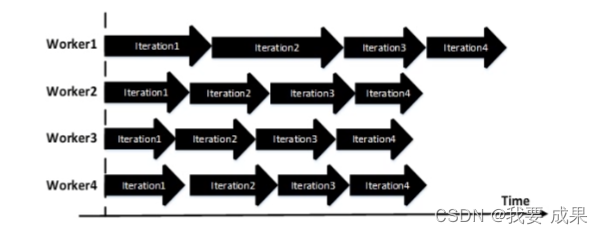
基于参数服务器(或者锁)
自主步调,等待少
收敛性差
半同步/延时同步
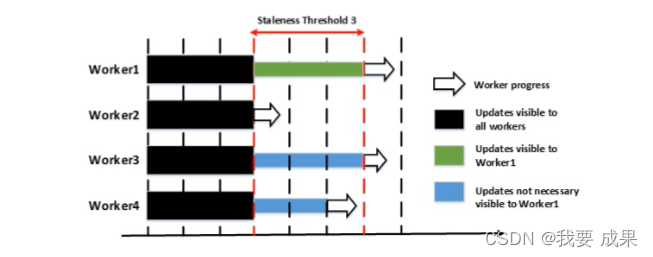
Stale Synchronous
这衷平衡
通信的拓扑结构
基于迭代式MapReduce的通信(同步模式)
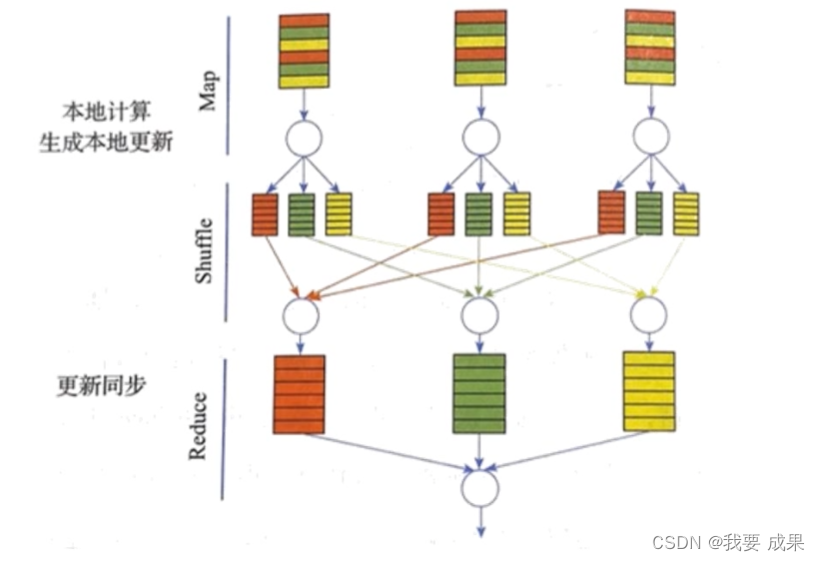
基于MPI之AllReduce的通信(同步模式)
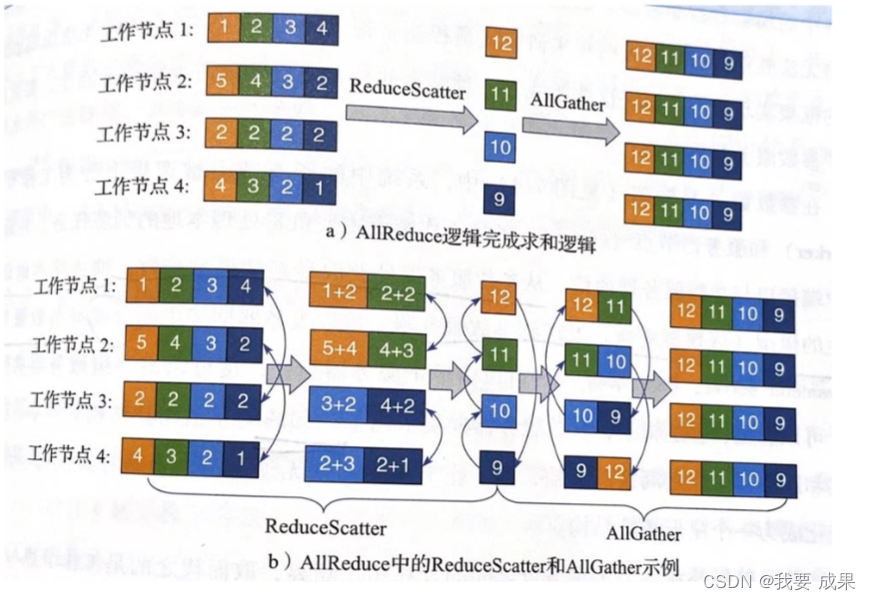
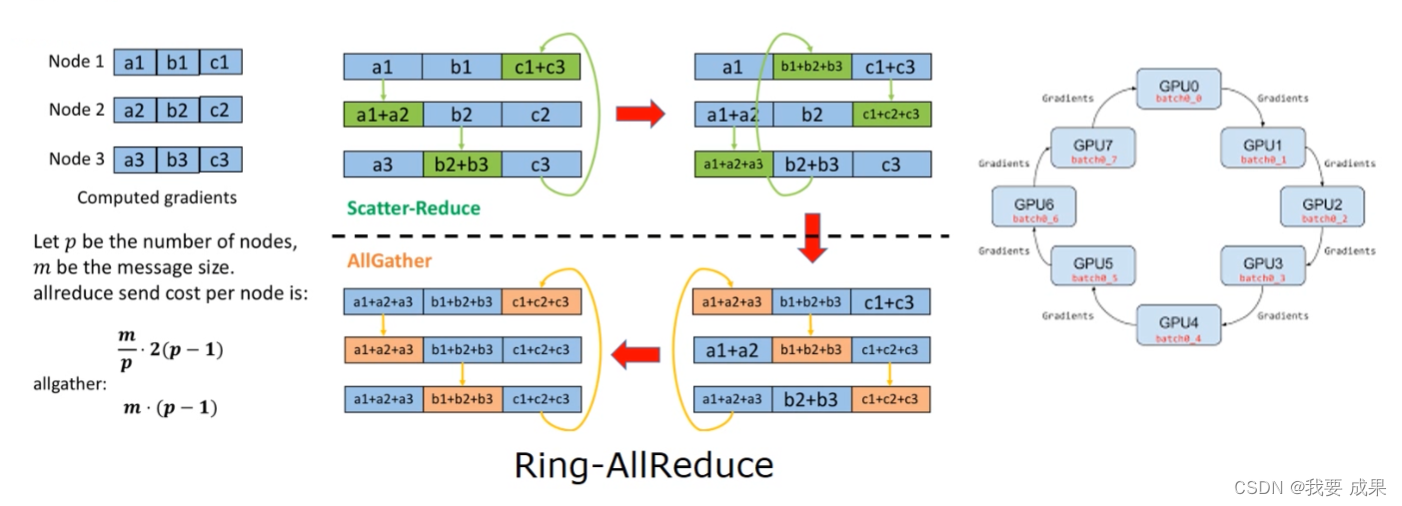
AllReduce有很多变种
星形拓扑、树形拓扑、蝶形拓扑、环形拓扑
pytorch、TensorFlow和caffe2等框架都实现AllReduce/Ring-AllReduce
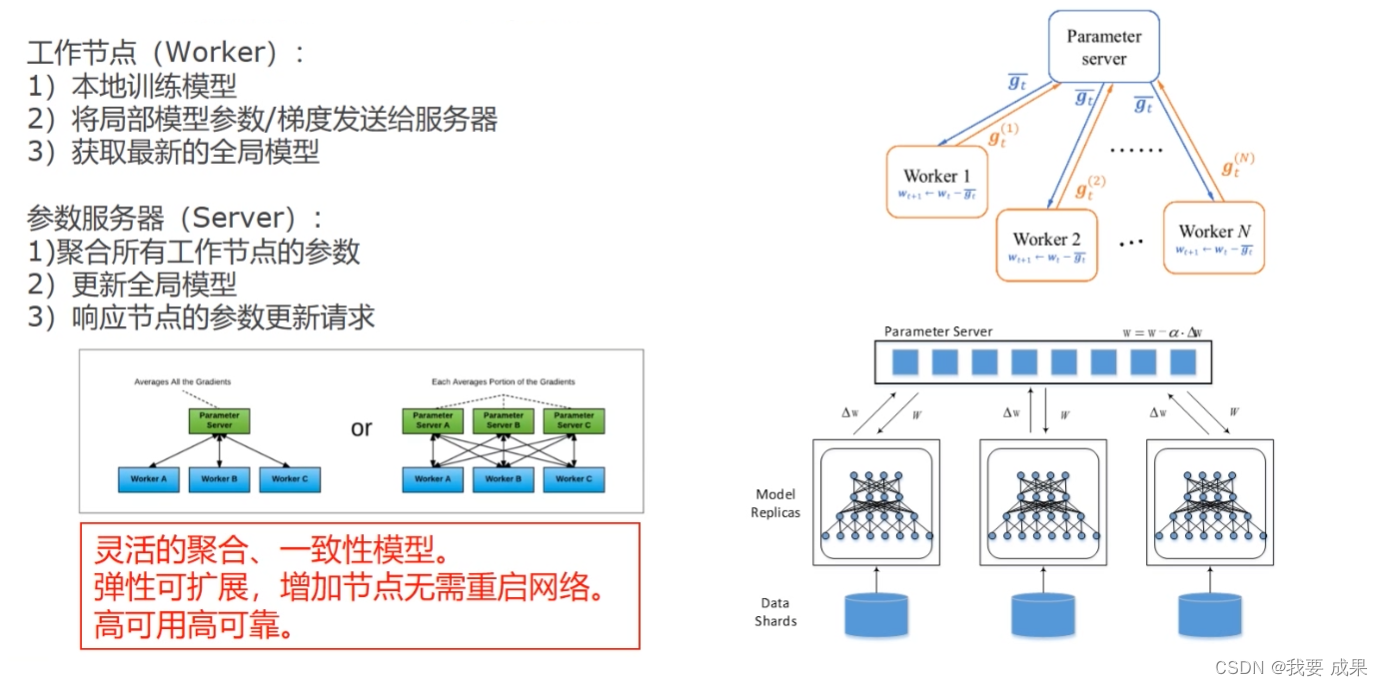
基于参数服务器的通信(多为异步)
去中心化算法
D-PSGD

通信频率及通信量
如何减少通信开销?
- 降低通信频率:Batch训练
- 降低通信时间:通信隐藏
- 减少通信数据量:梯度压缩(过滤、量化)
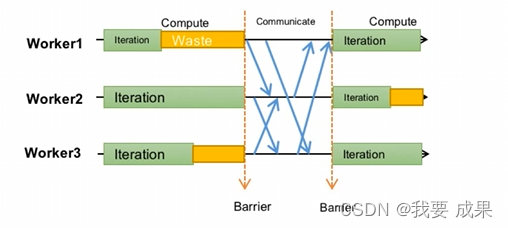
降低通信频率
由于通信间隔会导致各个机器间存在一定的不一致,对优化带来一定影响。
该方法在凸优化问题下有理论保证,但在处理神经网络等非凸模型时缺乏理论证明,往往需要超参数的设置来取得较好的训练效果。
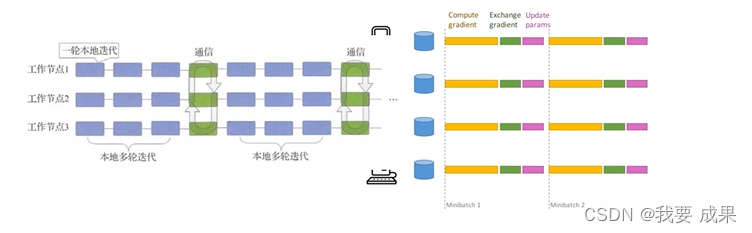

降低通信时间-通信隐藏
非对称的推送和获取,异步推送
在参数服务器架构下,推送模型更新和获取最新的全局模型两种操作采取不同的频率
谷歌提出的第一代分布式机器学习系统DistBelief [Dean J; NIPS2012]则采用了这种方法
与增加通信间隔类似,调整推送和获取的间隔时间也会给模型训练带来一定的精度损失
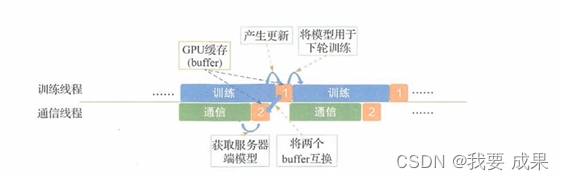
计算和传输流水线
模型的训练和网络通信构成流水线
减少整体的训练时间开销
模型更新的延迟稍有所增加
减少通信数据量:梯度压缩
梯度稀疏化:设置闻值,过滤掉不重要的梯度更新
模型低秩化:矩阵低秩分解,不重要的参数不通信
梯度量化: 对梯度值进行量化减少bit数
梯度稀疏化
-
梯度稀疏化是对模型梯度进行过滤
-
在每次迭代只发送部分参数:
- 固定闽值稀疏化 [Strom N.ISCA 2015]
- TopK稀疏化[Aji A F,et al. arXiv:1704.05021]
- Deep Gradient Compression [Lin Y, et al.arXiv:1712.01887 ]
- GTopk稀疏化[Shaohuai Shi,et al.ICDCS 2019]
- 基于熵的梯度稀疏化 [Di Kuang,et al.HPCC 2019]
-
通常梯度稀疏化需要压缩率较大,需要配合相应的优化算法实现模型精度与通信效率的平衡。

模型低秩化处理
- 模型低秩化处理通过低秩分解压缩参数来减少通信量。
- 探索参数中的低秩结构: 矩阵低秩分解,将原来比较大的参数矩阵分解成几个较小的矩阵的乘积

- 精度损失、压缩与解压缩开销
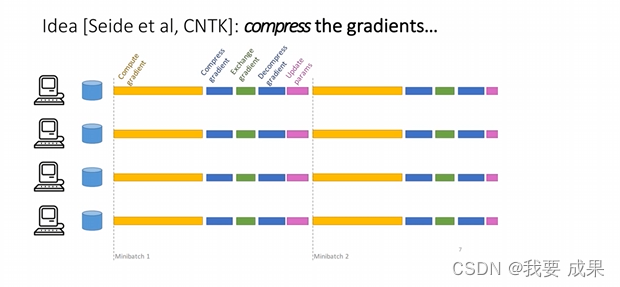
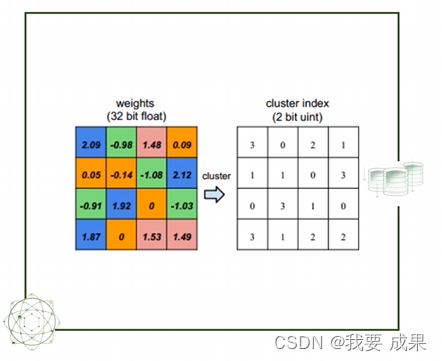
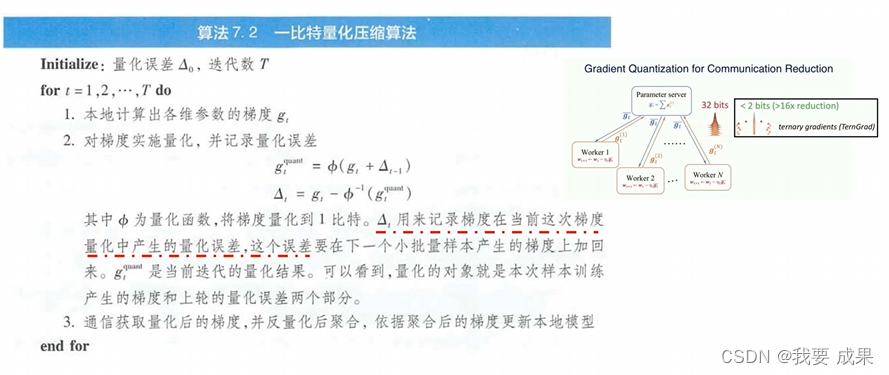
梯度量化
- 对梯度值进行量化减少bit数
- 降低精度,显著降低通信量
- 主要方法
- 1bit量化[Seide F,et al.2014]
- QSGD [Alistarh D, et al. NIPS 2017]
- TernGrad [Wen W, et al. NIPS 2017]
总结







![[直播自学]-[汇川easy320]搞起来(4)看文档 查找设备(续)](https://img-blog.csdnimg.cn/16455f77f298415690b464ecb01c07c9.png)