【C++笔记】二叉搜索树的模拟实现
- 一、二叉搜索树的概念
- 二、二叉搜索树的模拟实现
- 2.0、定义二叉树节点
- 2.1、非递归接口实现
- 2.1.1、插入
- 2.1.2、查找
- 2.1.3、删除
- 2.2、递归接口实现
- 2.2.1、插入
- 2.2.2、查找
- 2.2.3、删除
- 三、升级为K-V模型
一、二叉搜索树的概念
二叉搜索树的概念:
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
它的左右子树也分别为二叉搜索树
就比如下面这一棵树就是一颗二叉搜索树:
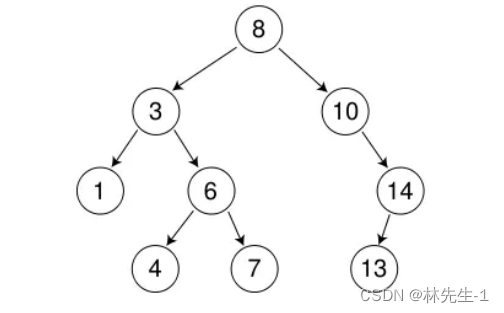
学习二叉搜索树其实也是为了后面学习AVL树和红黑树打下基础,因为AVL树和红黑树都是有二叉搜索树延伸出来的。
基于二叉搜索树的的特性,如果要在二叉搜索树中查找某一个数,最多只需要查找到最底层(如果比根大就去右子树去查找,如果比根小就去左子树中查找),很容易得出查找的时间复杂度为logn。所以在应用中二叉搜索树也常常用于查找。
但是二叉搜索树查找的时间复杂度也并非一直稳定在logn,如果是一些比较特殊的树,时间复杂度可能会升到n,就比如下面这棵树:
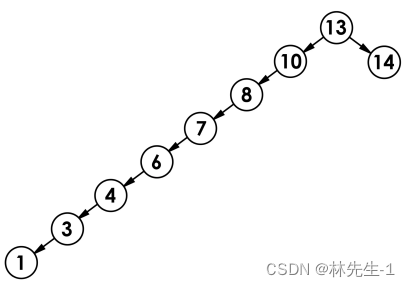
所以AVL树和红黑树就是为了解决二叉搜索树的这个缺陷而设计出来的。
而且我们后面要学到的set和map就是用红黑树封装出来的,所以学好二叉搜索树也就变成了基础中的基础。
二、二叉搜索树的模拟实现
2.0、定义二叉树节点
搜索二叉树的节点其实也和传统的二叉树节点一样,只是我们处理这些节点的规则变了而已:
// 搜索二叉树节点
template <class K>
struct BSTreeNode {
BSTreeNode<K>* _left;
BSTreeNode<K>* _right;
K _val;
BSTreeNode(const K& val)
:_left(nullptr)
, _right(nullptr)
, _val(val)
{}
};
然后我们在搜索二叉树的类中就只需要封装一个根节点的指针即可:
template <class K>
class BSTree {
public :
typedef BSTreeNode<K> Node;
// ……
private :
Node* _root = nullptr;
};
2.1、非递归接口实现
因为搜索二叉树可以说是为了应用而产生的,所以它主要的接口不多,只需要实现三个:插入、查找、删除即可。其他的一些接口和普通二叉树是一样的。
2.1.1、插入
根据二叉搜索输的规则,我们很容易就能想出插入该怎么写:
我们只需要从根节点出发,一直遍历,如果要插入的节点比当前节点小那我们就往左子树走,如果如果比当前节点大就往右子树走,知道当前节点cur走到空就确定了要插入的位置:
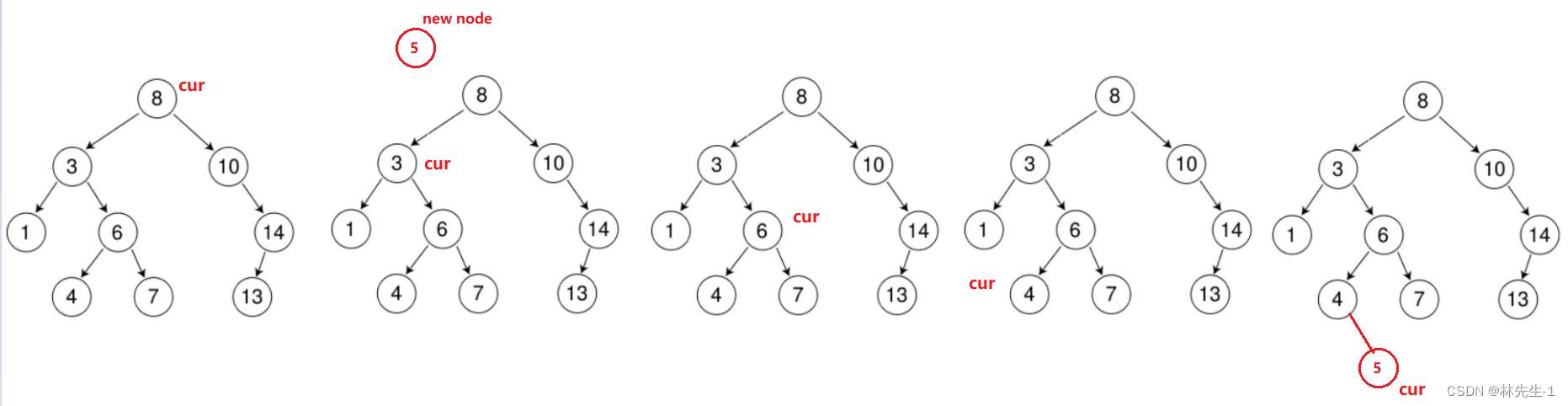
但是这样子,只是cur走到了空,我们并不是道cur是最有一个节点的做孩子还是右孩子,所以我们还需要一个parent指针一路记录cur的父亲,这样到cur走到空的时候就能判断是插入在左边还是右边了:
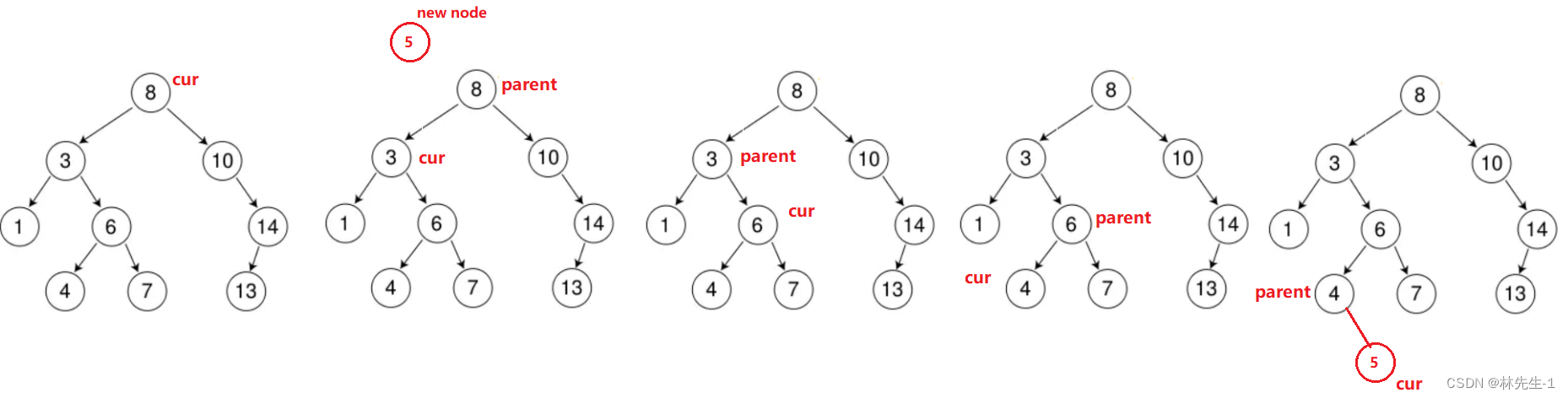
注意: 搜索二叉树是不能插入相同节点的。
代码实现:
// 非递归插入
bool insert(const K& val) {
if (nullptr == _root) {
_root = new Node(val);
return true;
}
Node* cur = _root;
Node* parent = _root;
while (cur) {
parent = cur;
if (val < cur->_val) {
cur = cur->_left;
}
else if (val > cur->_val) {
cur = cur->_right;
}
else { // 不能插入相同节点,如果相同直接返回false
return false;
}
}
// 判断插入在左还是在右
if (val < parent->_val) {
parent->_left = new Node(val);
}
else {
parent->_right = new Node(val);
}
return true;
}
2.1.2、查找
查找我想应该是最简单的了,我们按规矩走一遍就行了,如果找到就返回true,走到空就表示找不到,返回false即可:
// 非递归查找
bool Find(const K& val) {
Node* cur = _root;
while (cur) {
if (val < cur->_val) {
cur = cur->_left;
}
else if (val > cur->_val) {
cur = cur->_right;
}
else {
return true;
}
}
return false;
}
2.1.3、删除
但删除就没有这么简单了,因为这得涉及到对这棵树局部的重新调整。
可能大家也能想到,删除叶子结点一定是最简单的,删除左右都不为空的节点一定是最难的。
但是叶子结点是左右都为空,我们其实可以将它分类到左为空或者右为空中,因为它两个条件都满足嘛。
左为空:
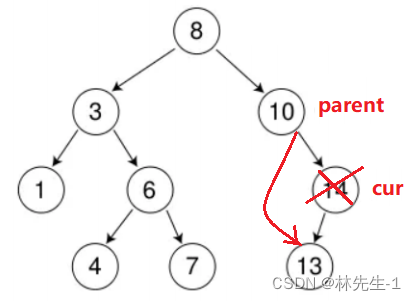
比如在下面这棵树中我们要删除10这个节点:
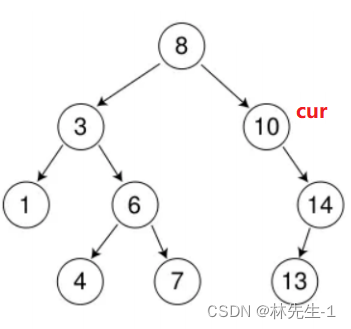
根据搜索二叉树的规则,我们会发现对于一个根节点,其左子树的所有节点都是小于它的,右子树的所有节点都是大于它的。
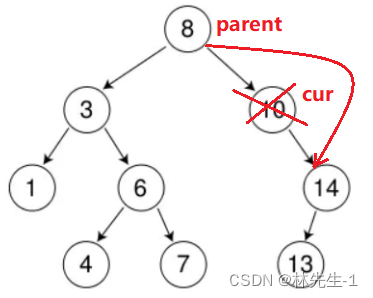
所以对于当前的情况,我们只需要将当前cur节点删除,然后让其父亲的左指针或右指针指向cur的右孩子即可:
右为空:
同理,右为空的处理和左为空类似:
左右都不为空:
左右都不为空的情况就有点儿复杂了,因为这种情况cur牵扯到的节点一定是最多的,有可能cur的做右子树都是很大的树,可想要做的调整应该是很大的!?
但其实我们并需要做多大的调整,调整这种情况我们只需要把注意力放在搜索二叉树的“规则”上。
即对于每一棵子树,它的左孩子一定比它小,有孩子一定比它大。
而从这个规律中我们也能得到另个一规律,就是对于一个根而言,它的左子树的所有节点都一定比它小,它的右子树的所有节点都一定比它大。
我们从第二个规律入手就可以很好的解决了,那怎样做到调整之后保持这个规律呢?
先给出结论:
找出左/右字数中最大/小的节点,然后与cur交换,然后那个最小的节点(值已经交换,所以也就达到了删除cur的目的)。
以找到右子树的最小节点为例,我们来解释一下,这样做为什么行,比如在下面这棵树中,我们要上出节点3:
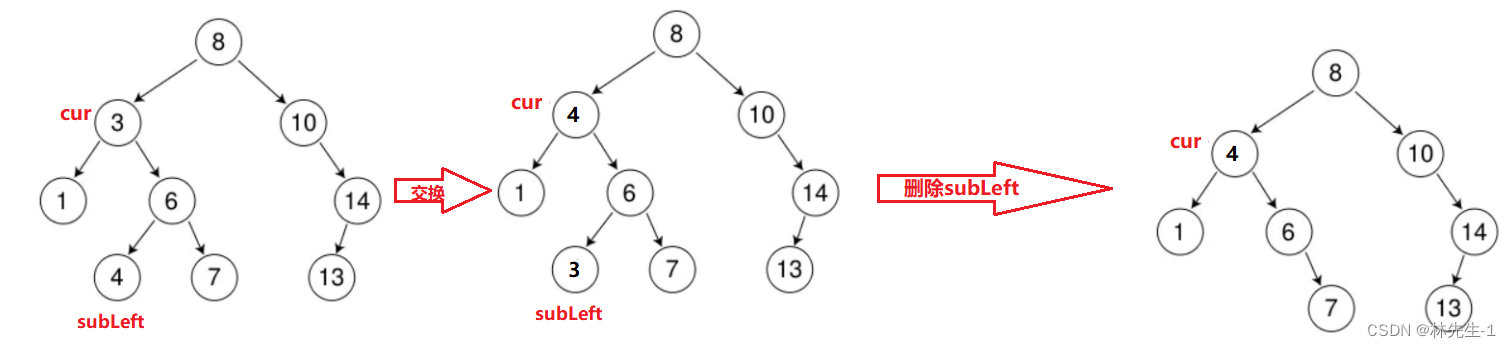
我们这里用subLeft来表示右子树的最小节点,cur表示当前要删除的节点。
由搜索二叉树的规律我们可知,一个树的最小节点一定是这棵树的最左节点,所以它一定是个叶子结点,所以删除subLeft就可以转化成和上面左/右为空的情况。
而一棵树的最小节点一定比这棵树中的所有节点都要小,又由上面的第二个结论,**我们可知subLeft一定是大于cur左子树中任意的节点的。**所以交换cur和subleft后的整棵子树依旧符合搜索二叉树的定义。
同理,选择右子树的最大节点也是同样的证明。
代码实现:
// 非递归删除
bool Erase(const K& val) {
Node* cur = _root;
Node* parent = _root;
// 先找到要删除的节点
while (cur) {
if (val < cur->_val) {
parent = cur;
cur = cur->_left;
}
else if (val > cur->_val) {
parent = cur;
cur = cur->_right;
}
else {
// 开始删除
if (nullptr == cur->_left) { // 左为空
if (cur == _root) { // 如果cur等于_root
_root = _root->_right;
}
else {
if (cur == parent->_left) {
parent->_left = cur->_right;
}
else {
parent->_right = cur->_right;
}
}
delete cur;
}
else if (nullptr == cur->_right) { // 右为空
if (cur == _root) {
_root = _root->_left;
}
else {
if (cur == parent->_left) {
parent->_left = cur->_left;
}
else {
parent->_right = cur->_left;
}
}
delete cur;
}
else { // 左右都不为空
Node* parent = cur;
Node* subLeft = cur->_right; // 记录右子树中最小的节点
// 找到右子树最小的节点(右子树中最左边的节点)
while (subLeft->_left) {
parent = subLeft;
subLeft = subLeft->_left;
}
// 交换
swap(subLeft->_val, cur->_val);
// 转化成去删除subLeft
if (subLeft == parent->_left) {
parent->_left = subLeft->_right;
}
else {
parent->_right = subLeft->_right;
}
delete subLeft;
}
return true;
}
}
return false;
}
2.2、递归接口实现
我们以前的二叉树都是用递归实现的,二搜索二叉树也是二叉树,当然也可以使用递归实现。
2.2.1、插入
插入的递归实现其实很好写,如果要插入的节点比当前的节点小就转化成在左子树插入,如果要插入的节点把当前的节点大就转化成在右子树插入,如果相等就返回false即可。
用递归实现还有一个好处就是,我们没必要记录遍历到的每个节点的parent了,因为递归用传参的方式就很好的帮我们解决了。
先看代码实现:
// 递归版insert
bool insertR(const K& val) {
return _insertR(_root, val); // 因为_root在类里面是私有的,在类外部不好传参,所以在这里设计了一个子函数
}
bool _insertR(Node *& root, const K & val) {
if (nullptr == root) {
root = new Node(val);
}
if (val < root->_val) {
return _insertR(root->_left, val);
}
else if (val > root->_val) {
return _insertR(root->_right, val);
}
return false;
}
不知道大家有没有注意到,我的_insertR子函数里的root指针给的是一个引用,为什么要给引用呢?如果不给引用的话会有什么问题呢?
先给出回答:这里的root必须给引用,如果不给引用的话新插入的节点和之前的节点就连接不上了。
为什么:
虽说现在已经是C++了,但是有时候解决一些问题还是需要用到C语言的知识的。
这里其实涉及到了C语言中变量的“左值”和“右值”的知识。
如下图:
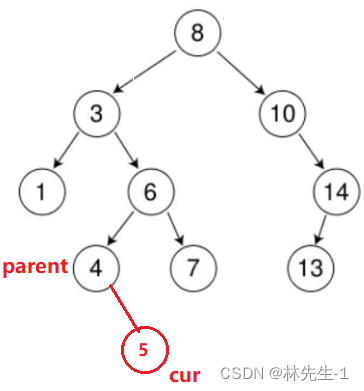
如果我们想要将新的节点连接上parent,要执行parent->_right = cur,这其实是将cur放到parent->_right指向的 “空间”,也就是要用到parent->_right的 “左值”(“左值”表示空间,“右值”表示数据)。
而如果我们不适用引用传参,则我们传过来的值是一个局部变量,是是实参的拷贝:
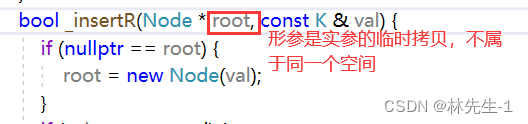
也就是说只传指针的话,我们只是将新节点放到了局部变量的空间中,所以就没有连接上。
如果想要连接成功,也可以像C语言一样使用二级指针,但是现在有C++的引用可以用,谁还用二级指针啊,二级指针多恶心啊!
所以我们这里就需要使用引用传参,引用是对象的别名,所以用的还是一样的左值,一样的空间。
2.2.2、查找
查找也是很简单的,几乎和循环一样。
如果要查找的节点比当前节点小,就递归到左子树查找,如果要查找的节点比当前节点大,就递归到右子树查找,如果递归到空节点,则说明找不到,返回false即可:
// 递归版查找
bool FindR(const K& val) {
return _FindR(_root, val);
}
bool _FindR(Node* root, const K& val) {
if (nullptr == root) {
return false;
}
if (val < root->_val) {
return _FindR(root->_left, val);
}
else if (val > root->_val) {
return _FindR(root->_right, val);
}
return true;
}
2.2.3、删除
递归删除也是先要找到节点才行,这个不多说。
递归删除虽说是递归,但是我们只是借助递归帮我们查找节点而已,删除操作其实是和迭代的方式一样的,唯一不同的是,当删除到左右都不为空的节点时,我们交换后可以利用递归转化成在左子树或右子树中删除同样值:
// 递归版删除
bool EraseR(const K& val) {
return _EraseR(_root, val);
}
bool _EraseR(Node*& root, const K& val) {
if (root == nullptr) {
return false;
}
if (val < root->_val) {
return _EraseR(root->_left, val);
}
else if (val > root->_val) {
return _EraseR(root->_right, val);
}
else {
if (nullptr == root->_left) {
// 开始删除(和迭代的方式一样)
Node* del = root;
root = root->_right;
delete del;
return true;
}
else if (nullptr == root->_right) {
Node* del = root;
root = root->_left;
delete del;
return true;
}
else {
Node* subLeft = root->_right;
// 找到右子树最小的节点(右子树中最左边的节点)
while (subLeft->_left) {
subLeft = subLeft->_left;
}
// 交换
swap(subLeft->_val, root->_val);
}
// 转化成在右子树删除同样的值
return _EraseR(root->_right, val);
}
}
三、升级为K-V模型
我们上面所实现的其实可以称作是K模型的二叉搜索树,但二叉搜索树最多的应用其实是K-V模型。
K-V模型其实就是一个键对应一个值,比如英汉字典就是典型的K-V模型,中文是键,英文是值,在查找的时候只需要找到中文就可以得到对应的英文了。
搜索二叉树的K-V模型也是一样,在查找的时候我们只需要给出对应的key,就能找到对应的value。
想要将我们上面写的二叉搜索树改成K-V模型其实很简单,只需要多加一个模板参数,然后将对应的接口修改一下即可:
修改节点:
// 搜索二叉树节点
template <class K, class V>
struct BSTreeNode {
BSTreeNode<K>* _left;
BSTreeNode<K>* _right;
K _key;
V _val;
BSTreeNode(const K& keyl, const V& val)
:_left(nullptr)
, _right(nullptr)
, _key(key)
,_val(val)
{}
};
修改插入(非递归):
// 非递归插入
bool insert(const K& key, const V& val) {
if (nullptr == _root) {
_root = new Node(key, val);
return true;
}
Node* cur = _root;
Node* parent = _root;
while (cur) {
parent = cur;
if (keyl < cur->_key) {
cur = cur->_left;
}
else if (key > cur->_key) {
cur = cur->_right;
}
else {
return false;
}
}
if (key < parent->_key) {
parent->_left = new Node(key, val);
}
else {
parent->_right = new Node(key, val);
}
return true;
}
因为K-V模型只是通过key找到val,所以比较的时候置于key有关。
因为我们的插入和删除都是依照key来判断的,而删除并不涉及到修改,所以也就与val无关,所以删除的逻辑是一样的,不用修改。
修改查找:
因为我们这里改成了K-V模型,查找的话最好是能查找出一个键值对这样的效果更好,所以我们查找成功的话就直接返回节点的指针即可:
// 非递归查找
Node* Find(const K& keyl) {
Node* cur = _root;
while (cur) {
if (keyl < cur->_key) {
cur = cur->_left;
}
else if (keyl > cur->_key) {
cur = cur->_right;
}
else {
return cur;
}
}
return nullptr;
}
修改完后我们可以浅浅的来测试一下,实现一个简易的单词查找功能:
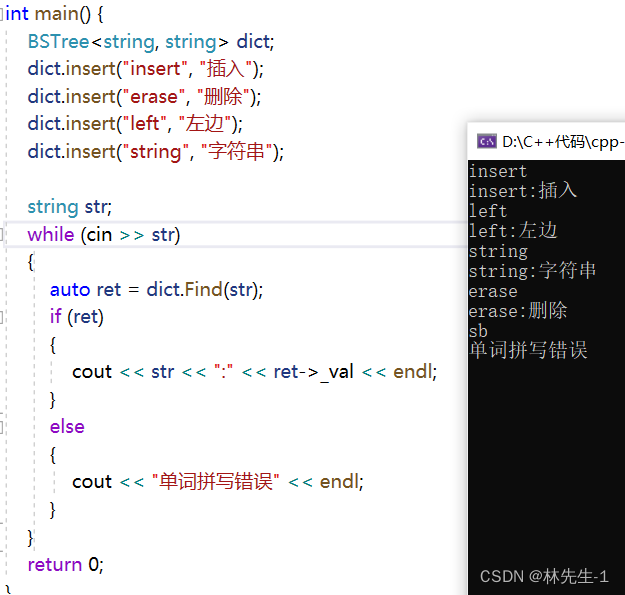
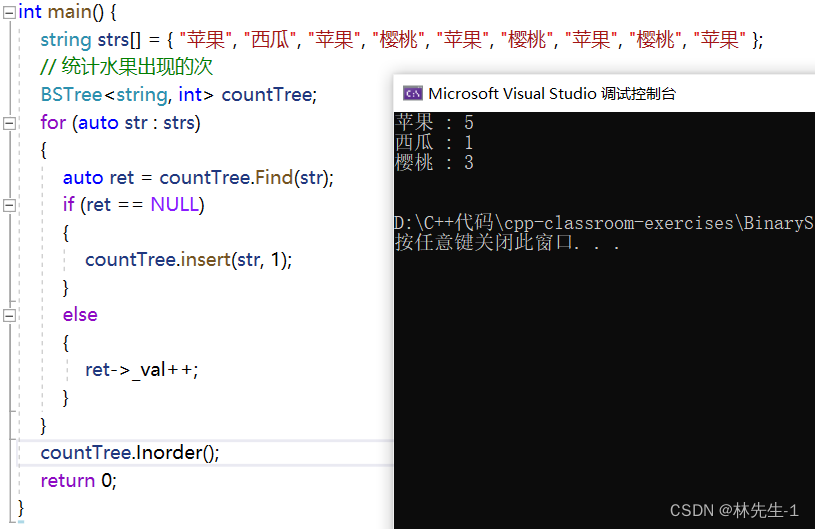
还有一个简易的统计频数的功能:





![[直播自学]-[汇川easy320]搞起来(4)看文档 查找设备(续)](https://img-blog.csdnimg.cn/16455f77f298415690b464ecb01c07c9.png)