引入MongoDB:
在面对高并发,高效率存储和访问,高扩展性和高可用性等的需求下,我们之前所学习过的关系型数据库(MySql,sql server…)显得有点力不从心,而这些需求在我们的生活中也是随处可见的,例如在社交中,使用它存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人,地点等功能。在游戏中,使用它存储游戏用户信息,用户的装备,积分等直接以内嵌文档的形式存储,方便查询,高效率存储和访问。还有我们熟悉的物流,使用它存储订单信息,订单状态在运送过程中会不断的更新,以内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来等等。这些场景中,数据操作都有共同的特点,数据量大,读写操作频繁,价值较低的数据(对事务性要求不高),对于这样的数据,我们更适合使用MongoDB去实现存储。
如何理解事务性要求不高?
事务性要求不高的意思是指对于一项任务或工作,对其完成的准确性、完整性和一致性的要求相对较低。这意味着即使在一些小的错误或不完美的情况下,任务仍然可以被接受或达到预期的结果。
例如,对于一项事务性要求不高的简单办公任务,如复制粘贴文本或整理文件等,只要大致完成了任务,小的错误或细微的差异通常被容忍。而对于事务性要求高的任务,如财务报表的编制或重要文件的审查,任何错误或不完美都可能导致严重后果,因此对其准确性和完整性的要求较高。
然而,尽管事务性要求不高,仍然需要保持对任务的专注和准确性,以确保任务的合理完成,并避免可能出现的问题或错误。
什么时候选择MongoDB?
是否需要选择它,我们可以考虑以下几个问题:
应用不需要事务及复杂join支持
新应用,需求会变,数据模型无法确定,想快速迭代开发
应用需要2000-3000以上的读写QPS
应用需要TB甚至PB级别数据存储
应用发展迅速,需要能快速水平扩展
应用要求存储的数据不丢失
应用需要99.999%高可用
应用需要大量的地理位置查询,文本查询
如果符合上述中的1个及以上,那么MongoDB是你绝不后悔的选择,一定会有人有这样的疑问,上述的这些问题就不能使用们么之前学习过的关系型数据库解决了吗?当然不是,只是在面对这些问题时,相比于MySQL或者SQL server,MongoDB无论是从开发还是运维都可以以更低的成本解决问题!
什么是MongoDB?
MongoDB是一个开源,高性能,无模式的文档型数据库,当初的设计就是用于简化开发和方便扩展,是NOSQL数据库产品中的一种,是最像关系型数据库(MySQL)的非关系型数据库,它所支持的数据结构非常松散,是一种类似于JSON的格式叫BSON,所以它既可以存储比较复杂的数据类型,又相当的灵活,MongoDB中的记录是一个文档,它是一个由字段和值对组成的数据结构,MongoDB文档类似于JSON对象,即一个文档认为就是一个对象,字段的数据类型是字符型,它的值除了使用基本的一些类型外,还可以包括其他文档,普通数组和文档数组。
注:MongoDB的无模式是指在数据存储过程中不需要事先定义表结构,也不需要强制要求所有文档具有相同的字段。这意味着MongoDB允许在同一个集合中存储不同结构的文档。
而在传统的关系型数据库中,需要定义表结构和字段类型,然后才能存储数据。而在MongoDB中,可以直接将文档插入到集合中,MongoDB会自动为每个文档创建一个唯一的_id字段,并且不限制其他字段的存在和类型。
这种无模式的特性使得MongoDB非常灵活,能够适应数据结构的变化和快速迭代。开发人员可以根据具体需求来设计文档的结构,而不需要事先定义固定的表结构。这使得MongoDB适用于需要频繁更改和扩展数据模型的场景,如大数据、实时分析和快速迭代的应用程序。
然而,尽管MongoDB允许灵活的无模式设计,但在实际使用中也需要谨慎。过于灵活的结构可能导致数据冗余、查询复杂和数据一致性问题。因此,在设计数据库时,仍然需要考虑数据的结构和关系,以保证数据的一致性和查询性能。
关系型数据库与MongoDB对比:
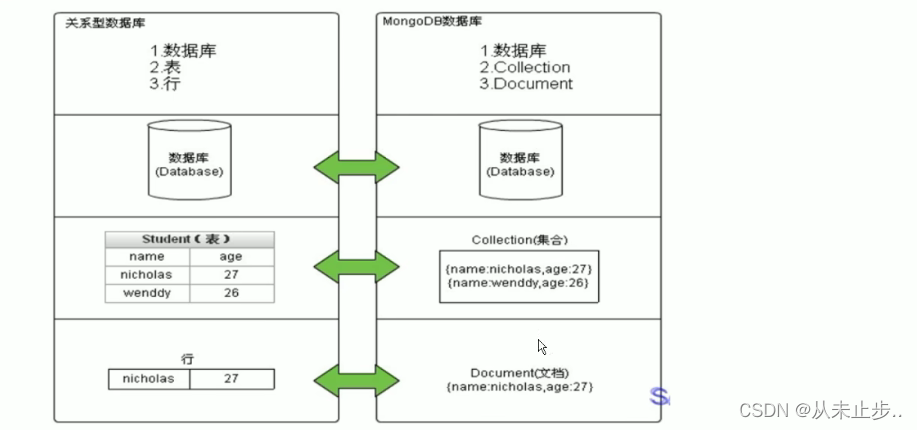
| SQL术语/概念 | MongoDB术语/概念 |
|---|---|
| database 数据库 | database 数据库 |
| table 数据库表 | collection 集合 |
| row 数据记录行 | document 文档 |
| column 数据字段 | filed 域 |
| index 索引 | index 索引 |
| table joins 表连接 | 不支持 |
| 嵌入文档 通过嵌入文档来代替表连接 | |
| primary key 主键 | primary key MongoDB自动将_id字段设置为主键 |
MongoDB中的数据模型:
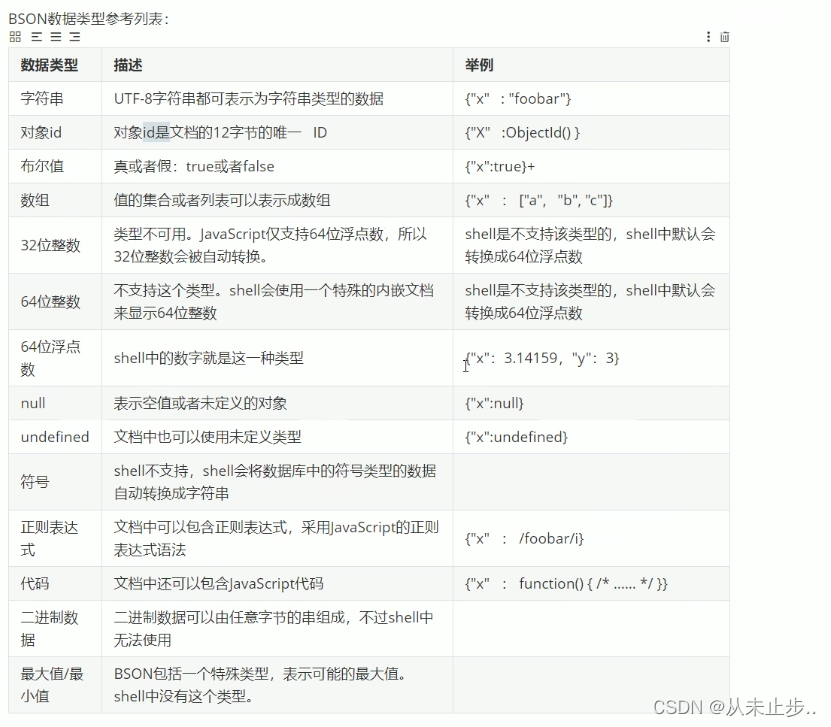
MongoDB的最小存储单位就是文档对象,文档对象对应于关系型数据库的行,数据在MongoDB中以BSON文档的格式存储在磁盘上,BSON是类JSON的一种二进制形式的存储格式,简称Binary JSON,BSON和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型,BSON采用了类似于C语言结构体的名称,对表示方法,支持内嵌的文档对象和数组对象,具有轻量级,可遍历性,高效性三个优点,可以有效描述非结构化数据和结构化数据,这种格式的优点是灵活性高,但它的缺点是空间利用率不是很理想,BSON中,除了基本的JSON类型:string,integer,boolean,double,null,array和object,Mongo还使用了特殊的数据类型,这些类型包括date,object,id,binary,data,regular,expression和code,每一个驱动都以特定语言的方式实现了这些类型。
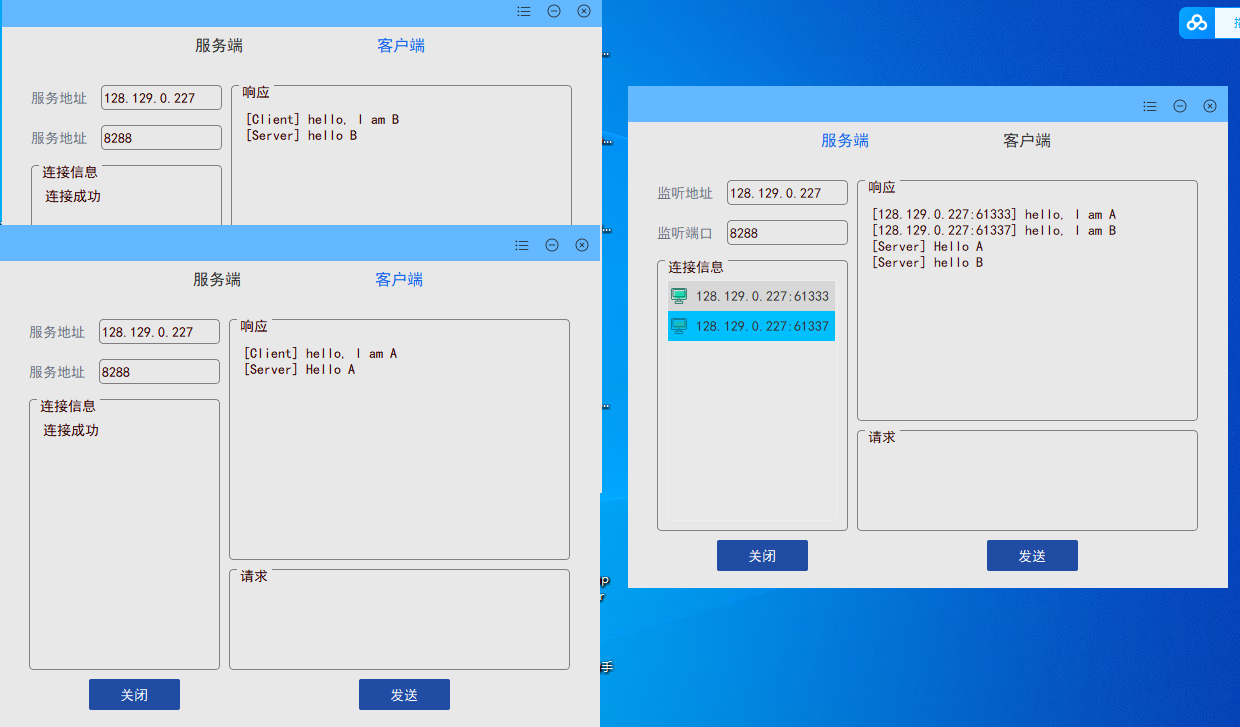
在Windows下启动和部署MongoDB:
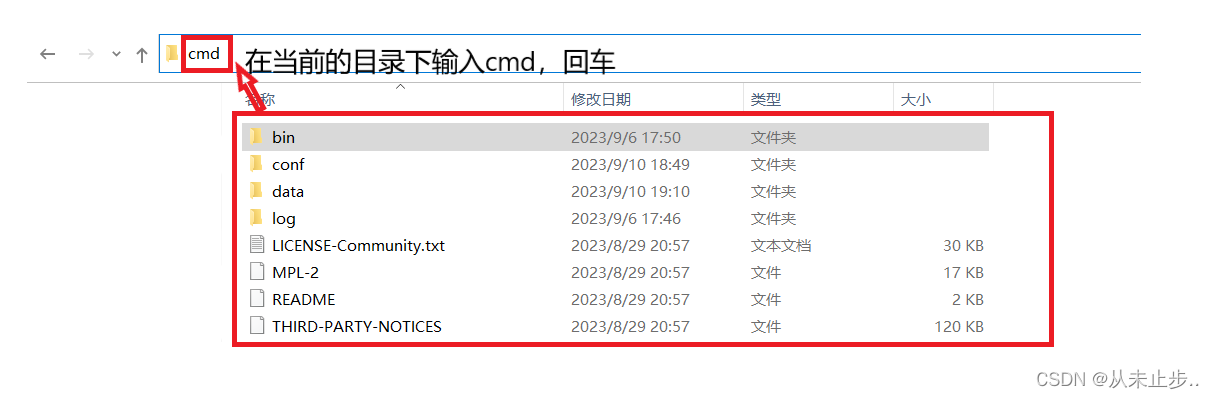
mongod --dbpath=..\data\db
我们在启动信息中可以看到,mongoDB的默认端口号是27017
连接mongoDB:
通过shell连接:
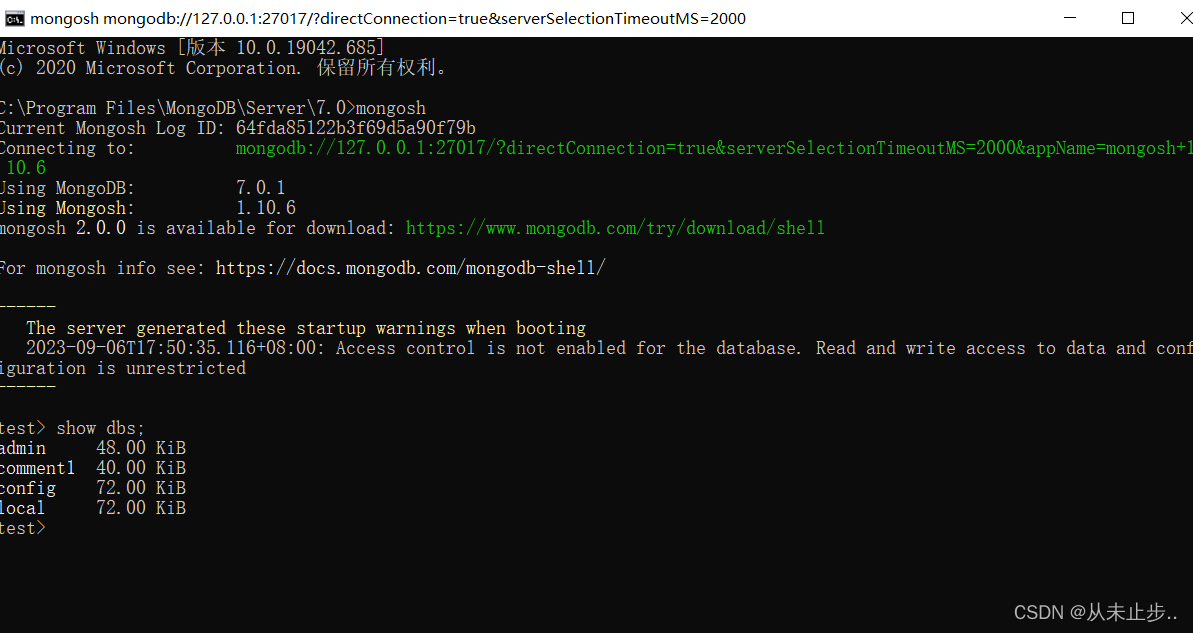
在mongoDB的bin目录下cmd回车,输入mongosh,如下所示
通过图形可视化界面来连接:
在官网下载该软件即可!传送门
MongoDB对数据库进行操作的基本命令:
默认数据库的作用:
在MongDB中有以下四个是MongoDB为我们创建的数据库:

admin:从权限的角度看,这是"root"数据库,如果我们将一个用户添加到该数据库,那么这个用户就自动被赋予所有数据库的权限,一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local:这个数据库永远不会被复制,可以用来存储本地单台服务器的任意集合
config:当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息
comment1:在MongoDB中,comment1是一个特殊的数据库名称,它并没有特殊的作用或功能。这个名称仅仅是一个示例,用于说明如何在MongoDB中添加注释。注释可以在MongoDB命令中使用。
查看当前的所有数据库:
show dbs或show databases
选择和创建数据库的语法格式:
use 数据库名;
如果该数据库名不存在,那么会自动创建,如下所示:

第二次显示所有数据库时,我们会发现articledb数据库并没有被包含其中呀,原因是在MongoDB中,它的存储分为两部分,一部分是内存存储,一部分是磁盘存储,而当我们使用use articledb;进行存放时,实际上是存放在内存中,此时MongoDB并没有将该数据库持久化到磁盘中,因此,我们当前使用show命令是无法查出该数据库的,而只有当该数据库中包含数据,不为空时,它就会被持久化到磁盘中
查看当前使用正在使用的数据库:
db
虽然我们创建的articledb数据库并没有被持久化到磁盘中,但我们已经将其创建到了内存中,因此也是可以直接使用的,如下所示:

MongoDB中默认的数据库为test,如果我们没有选择数据库,那么所有的数据都会被放在test数据库中
数据库的命名要求和我们之前学过的结构化数据库(MySql,SQL server)是完全一样的,这里我们就不过多赘述了
删除持久化数据库:
db.dropDatabase()

MongoDB对集合操作的基本命令:
创建集合:
集合类似于关系型数据库中的表,可以显式的创建,也可以隐式地创建
显式创建:通过操作命令将其创建
//创建集合
db.createCollection(name)
//查询集合
show collections
举例:
//集合名无论什么类型都要使用双引号引用
db.createCollection("MyMongoDB");
隐式创建:
直接插入文档如下所示,如果当前集合不存在,那么会直接创建一个集合
//插入文档后,查询所有的集合就包括My
db.My.insert({id:1,name:"张三",age:10
})
删除集合:
db.要删除的集合名称.drop()
MongoDB对文档操作的基本命令:
单个文档插入:
使用insert()方法:
db.要插入的集合名称.insert(document)
批量文档插入:
使用insertMany():
db.要插入的集合名称.insertMany([{document1},{document2}....])
举例:
db.wjr.insertMany([{id:2,name:"易烊千玺",age:19},{id:3,name:"王俊凯",age:24},{id:4,name:"王源",age:23}]);
查询集合中的所有文档:
//查询所有的
db.要查询的集合名称.find()
//条件查询
db.要查询的集合名称.find(限制条件)
//条件查询--返回符合条件的第一条数据
db.要查询的集合名称.findOne(限制条件)
//投影查询--将某个字段名的值设置成1表示查询结果只显示该字段的内容,将_id的值设置成0表示不显示默认字段_id这一列
db.要查询的集合名称.find([字段名:1,_id:0])
文档使用插入try-catch:
插入时指定了_id,则主键就是该值,如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉,因为批量插入由于数据较多容易出现失败,因此,可以使用try catch进行异常捕捉处理,测试的时候可以不处理
//如果插入数据时发生错误,那么错误信息会被输出
try{
db.要插入数据的集合名称.insert([{"_id":1,"姓名":"Lisa"}]);
}catch(e){
print(e);
}
文档的更新:
通过使用修改器$set来实现:
//将_id为1的名字修改为李萍
db.要修改的集合名称.update({_id:1},{$set:{"姓名":"李萍"}})
批量的修改:
//将id为2的所有姓名修改为张明
db.要修改的集合的名称.update({id:"2"},{$set:{"姓名":"张明"}},{multi:true})
注意:{multi:true}不能省略,否则会出现只将满足条件的第一条数据修改
列值增长的修改:
//将_id为9的用户年龄设置为+1,通过$inc运算符来实现
db.要修改的集合名称.update({_id:9},{$inc:{"年龄":NumberInt(1)}})
文档的删除:
删除文档的命令:
//条件删除
db.要删除的集合名称.remove(条件)
//删除所有的数据
db.要删除的集合名称.remove({})
文档的分页查询:
统计所有的记录数:
//统计当前集合中的所有记录条数
db.要统计的集合名称.count()
//统计该集合中姓名为张三的记录条数
db.要统计的集合名称.count({姓名:"张三"})
分页列表查询:
可以使用limit()方法来读取指定数量的数据,使用skip()方法来跳过指定数量的数据
//返回当前集合查询结果的Number条数据
db.要查询的集合名称.find().limit(Number)
//将当前集合查询结果的前Number条数据不显示,默认值是0
db.要查询的集合名称.find().skip(Number)
两者也可以同时使用:
//返回当前集合查询结果的Number1条数据,并不显示查询结果的前Number2条数据
db.要查询的集合名称.find().limit(Number1).skip(Number2)
排序查询:
sort()方法可以通过参数指定排序的字段,并使用1和-1来指定排序的方式,其中1为升序排列,而-1是用于降序排列
//将查询结果根据_id进行降序排列,字段也可以指定多个,比如我们可以同时设定根据某个字段进行升序排列,某个字段进行降序排列
db.要查询的集合名称.find().sort({_id:-1})
注:skip(),limit(),sort()三个同时执行时,执行的顺序是先sort(),然后是skip(),最后是显示的limit(),和命令编写的顺序无关
正则的复杂条件查询:
MongoDB的模糊查询是通过正则表达式的方式实现的,格式为:
//查询该集合中姓名以张开头的文档
db.要查询的集合名称.find({"姓名":/^张/})
//查询该集合中姓名中包含明的文档
db.要查询的集合名称.find({"姓名":/明/})
比较查询:
//查询该集合中age大于12的所有文档
db.要查询的集合名称.find({age:{$gt:NumberInt(12)}})
//查询该集合中age小于12的所有文档
db.要查询的集合名称.find({age:{$lt:NumberInt(12)}})
//查询该集合中age大于等于12的所有文档
db.要查询的集合名称.find({age:{$gte:NumberInt(12)}})
//查询该集合中age小于等于12的所有文档
db.要查询的集合名称.find({age:{$lte:NumberInt(12)}})
//查询该集合中age不等于12的所有文档
db.要查询的集合名称.find({age:{$ne:NumberInt(12)}})
包含查询:
包含使用$in操作符
//查询该集合中姓名字段包含a或者c
db.要查询的集合名称.find({"姓名":{$in:["a","c"]}})
不包含使用$nin操作符
//查询该集合中姓名字段不包含a或者c
db.要查询的集合名称.find({"姓名":{$in:["a","c"]}})
条件连接查询:
我们如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联,相当于我们之前学学过的结构化数据库中的and
格式为:
$and:[{},{},{},....]
//查询该集合中age大于等于12并且小于等于19的文档
db.要查询的集合.find({$and:[{age:{$gte:NumberInt(12)}},{age:{$lt:NumberInt(19)}}]})
如果两个以上条件之间是或者的关系,我们使用$or操作符进行关联,与前面的and格式相同
$or:[{},{},{},....]
//查询该集合中age大于等于12或者小于等于19的文档
db.要查询的集合.find({$or:[{age:{$gte:NumberInt(12)}},{age:{$lt:NumberInt(19)}}]})
索引—Index:
索引支持在MongoDB中高效地执行查询。如果没有索引,MongoDB必须执行全集合扫描,即扫描集合中的每个文档,以选择与查询语句匹配的文档。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒其至几分钟,这对网站的性能是非常致命的。
如果查询存在适当的索引,MongoDB可以使用该索引限制必须检查的文栏数。
索引是特殊的数据结构,它以易于遍历的形式存储集合数据集的一小部分。索引存储特定字段或一组字段的值,按字段值排序。索引项的排序支持有效的相等匹配和基于范围的查询操作。此外,MongoDB还可以使用索引中的排序返回排序结果。
单字段索引:
MongoDB支持在文档的单个字段上创建用户定义的升序/降序索引,称为单字段索引(Single FieldIndex)。对于单个字段索引和排序操作,索引键的排序顺序(即升序或降序)并不重要,因为MongoDB可以在任何方向上遍历索引。
复合索引:
MongoDB还支持多个字段的用户定义索引,即复合索引(CompoundIndex)。复合索引中列出的字段顺序具有重要意义。例如,如果复合索引由[ userid: 1,score:-1组成,则索引首先按userid正序排序,然后在每个userid的值内,再在按score倒序排序。
索引的管理操作:
索引的查看:
说明:返回一个集合中的所有索引的数组。
语法:
db.collection.getIndexes()
注:该语法命令运行要求是MongoDB3.0+
索引的创建:
在集合上创建索引:
语法:
db.collection.createIndex(keys,options)
keys:它的类型为document,包含字段和值对的文档,其中字段是索引键,值描述该字段的索引类型,对于字段上的升序索引,请指定值1;对于降序索引,请指定值-1;比如:{字段:1或-1},其中1为指定按升序创建索引,如果你想按降序来创建索引指定为-1即可,另外,MongoDB支持几种不同的索引类型,包括文本,地理空间和哈希索引。
options:它的类型为document,它是可选的,包含一组控制索引创建的选项的文档。
options的常见可选参数如下所示:
unique:它的类型为Boolean,它表示创建的索引是否唯一,指定true创建唯一索引,默认为false
name:它的类型为String,它表示索引的名称,如果未指定,MongoDB通过连接索引的字段名和排序顺序生成一个索引名称。
索引的移除:
说明:可以移除指定的索引,或者移除所有索引
指定索引的移除:
db.collection.dropIndex(index)
参数:
index:它的类型为string或者document,它用来指定要删除的索引,可以通过索引名称或索引规范文档指定索引,若要删除文本索引,请指定索引名称。
所有索引的删除:
db.collection.dropIndexs()
索引的使用:
执行计划:
分析查询性能通常使用执行计划(解释计划)来查看查询的情况,如查询耗费的时间,是否基于索引查询等。
那么通常,我们想知道建立的索引是否有效,效果如何,都需要通过执行计划查看。
语法:
db.collection.find(query,options).explain(options)
涵盖的查询:
当查询条件和查询的投影仅包含索引字段时,MongoDB直接从索引返回结果,而不扫描任何文档或将文档带入内存,这些覆盖的查询可以非常有效。
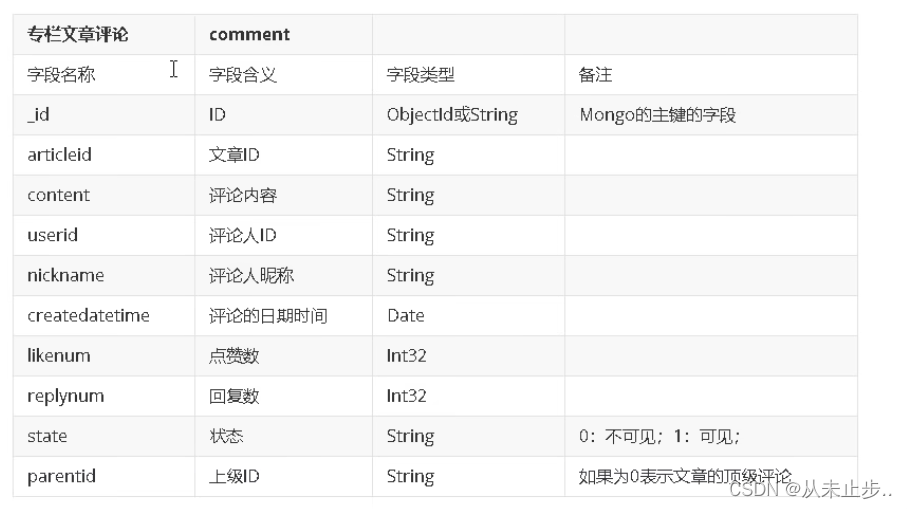
存放文章评论的数据放入MongoDB中,数据结构参考如下: