通过本章需要掌握Java设置类集的主要目的与实现原理,掌握Collection接口的作用及小狐妖操作方法,掌握Collection子接口List、Set的区别及常用子类的使用与核心实现原理,掌握Map接口的作用及与Collection接口的区别,理解Map接口设计结构以及常用子类的实现原理。掌握集合的3中常用输出方式:Iterator、Enumeration、foreach。掌握Queue队列结构的使用,理解单端队列与双端队列,掌握Properties类的使用,并可以结合资源文件(*.properties)实现属性操作,了解类集工具类Collections的作用,了解Stream数据流处理与统计分析操作。
类集时Java中的一个重要特征,是Java针对常用数据结构的官方实现,在开发中被广泛应用,如果要想写好一个程序,则一定要将类集的作用和各个组成部分的特点掌握清楚。本章将对Java类集进行完整的介绍,针对一些常用的操作也将进行深入的讲解。在JDK1.5之后,为了使类集操作更加安全,对类集框架进行了修改,加入了泛型的操作。
18.1 Java类集框架
在开发语言中数组是一个重要的概念,使用传统数组虽然可以保存多个数据,但是却存在程度的使用限制。而正是因为长度的问题,开发者不得不使用数据结构来实现动态数组处理(核心的数据结构:链表、树等),但是对于数据的开发又不得不面对以下问题
数据结构的代码实现困难,对于一般的开发者而言难度较高
随着业务的不断变化,也需要不断地对数据结构进行优化与结构更新,这样才可以保证较好地处理性能。
数据结构的实现需要考虑多线程并发处理控制
需要提供行业认可的标准
为了解决这些问题,从JDK1.2版本开始,Java就引入了类集开发框架,提供了一系列的标准数据操作接口与各个实现主类,帮助开发者减少开发数据结构带来的困难。但是在最初提供的JDK版本中由于技术所限全部采用Object类型实现数据接收(可能会导致ClassCastException安全隐患),而在JDK1.5之后由于由于泛型技术的推广,类集结构也得到了改进,可以直接利用泛型来同意类集存储数的数据类型,而随着数据量的不断增加,从JDK1.8开始类集中的实现算法也得到了良好的性能提升。
在类集中为了提供标准的数据结构操作,提供了若干核心接口,分别是Collection、List、Set、Map、Iterrator、Enumeration、Queue、ListIterator
18.2 Collection接口集合
java.util.Collection是单值集合操作的最大负借口,在噶借口中定义了所有的单值数据的处理操作。这个接口中的核心方法是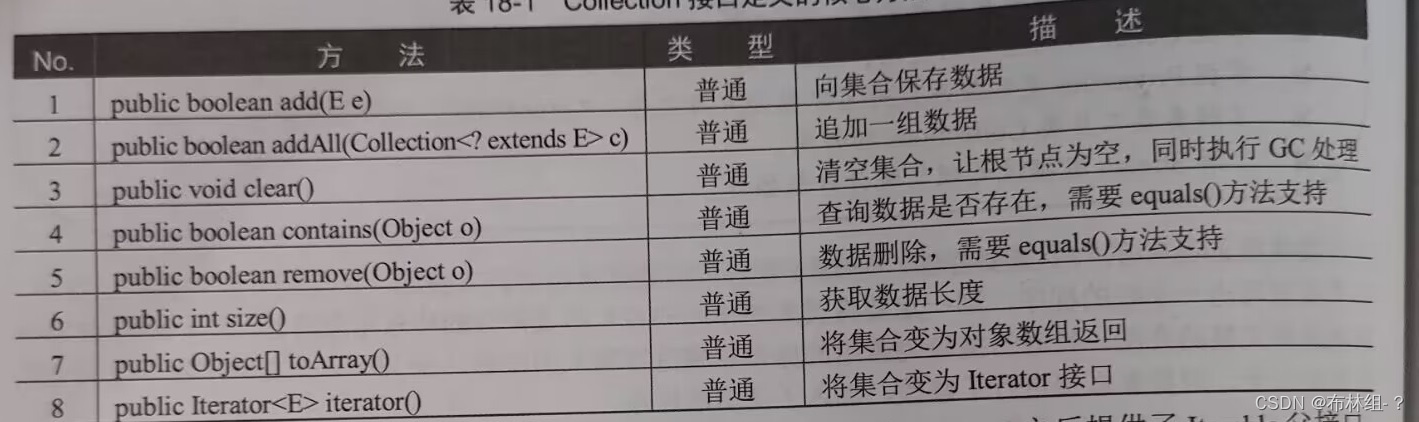
在JDK1.5版本以前,Collection只是一个独立的接口,但是从JDK1.5之后提供了Iterator负借口,并且在JDK1.8之后对Iterable接口进行了一些补充。另外,在JDK1.2-1.4时如果要进行集合的使用往往会直接操作Collection接口,但是从JDK1.5开始更多情况下选择的都是Collection的两个子接口,即允许重复的List子接口、不允许重复的Set子接口Collection与其子接口的继承关系如下: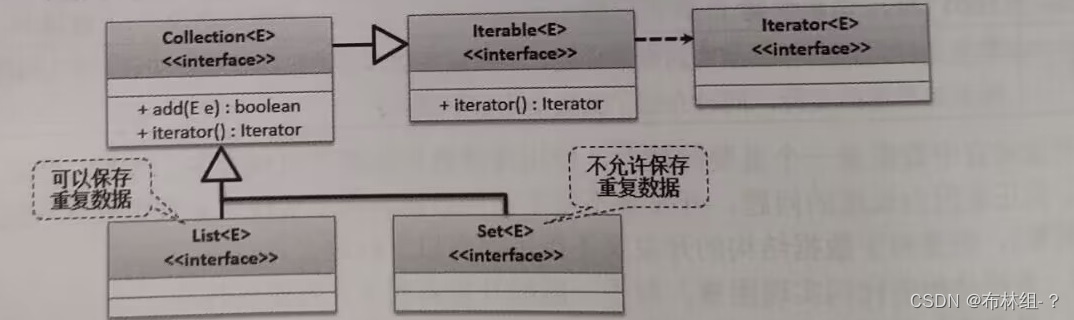
18.3 List集合
List是Collection的子接口,其最大的特点是允许保存重复元素数据
public interface List<E> extends Collection<E>{} 在使用List接口进行开发时,主要是用其子类实例化,该接口常用的子类为ArrayList、Vector、LinkList
在使用List接口进行开发时,主要是用其子类实例化,该接口常用的子类为ArrayList、Vector、LinkList
从JDK1.9后List接口提供了of()静态方法,利用此方法可以方便的将若干个数据直接转为List集合保存
范例:将多个数据转为List集合保存
package cn.mldn.demo;
import java.util.List;
public class JavaCollectDemo
{
public static void main(String[]args)
{
List<String>all=List.of("mldn","AAA","BBB");//多个数据转为List集合
Object result[]=all.toArray();//将List集合转为数组保存
for(Object temp:result){System.out.print(temp+"、");}
}
}
本程序直接利用List.of()方法将多个字符串对象保存在了List集合中,随后利用toArray()方法将集合的内容转为对象数组后去除利用foreach迭代输出,同时也可以发现,数据的设置顺序也是数据的保存顺序。
18.3.1 ArrayList子类
package cn.mldn.demo;
import java.util.ArrayList;
import java.util.List;
public class JavaCollectDemo
{
public static void main(String[]args)
{
List<String>all=new ArrayList<String>();//为负借口进行实例化
all.add("mldnjava");//保存数据
all.add("mldnjava");//保存重复数据
all.add("AAA");//保存数据
all.add("BBB");//保存数据
all.forEach((str)->{System.out.print(str+"、");})
}
}
范例:集合操作方法
package cn.mldn.demo;
import java.util.ArrayList;
import java.util.List;
public class JavaCollectDemo
{
List<String>all=new ArrayList<String>();//为List父接口进行实例化
System.out.println("集合是否为空?"+all.isEmpty()+"集合的个数"+all.size());
all.add("MLDNJava");//保存数据
all.add("MLDNJava");//保存重复数据
all.add("AAA");//保存数据
all.add("BBB");//保存数据
System.out.println("数据存在判断:"+all.contains("AAA"));
all.remove("mldnJava");
System.out.println("集合是否为空?"+all.isEmpty()+"集合元素个数"+all.size());
System.out.println(all.get(1));//获取指定索引元素,所以从0开始
}
本程序利用Collection接口中提供的标准操作方法获取了集合中的数据信息以及相关的操作,需要注意的是,List子接口提供的get()方法可以根据索引获取数据,这也是List子接口中的重要操作方法。
提示:ArrayList实现原理分析
从ArrayList子类的名称上就可以清楚的指导它利用数组(Array)实现了List集合操作标准,实际上在ArrayList子类中是通过一个数组实现了数据保存,该数组的定义如下
transient Object[]elementData;//方便内部类访问,所以没有封装
ArrayList类中数组是在构造方法中为其进行空间开辟的,在ArrayList类中提供有以下两种构造方法。
无参构造(public ArrayLits()):使用空数组(长度为0)初始化,在第一次使用时会为其开辟空间(初始长度为10)
有参构造(public ArrayList(int initialCapacity)):长度大于0则以指定长度开辟数组空间,如果长度为0,则无参构造开辟模式相同;如果为负数,则会抛出IllegalArgumentException异常。
由于ArrayList中利用数组进行数据保存,而数组本身有长度限制,所以当所保存的数据超过了数组容量时,ArrayList会帮助开发者进行数组容量的扩充,扩充原则如下
int oldCapacity=elementData.length;//数组长度
int new Capacity=oldCapacity+(oldCapacity>>1);//容量扩充
int new Capacity=oldCapacity+(oldCapacity>>1);//容量扩充
当数组扩充后会利用数组复制的形式,将旧数组中的数据复制到新开辟的新数组中。当然数组不能无限制扩充,在ArrayList中定义了数组的最大长度
private static finale int MAX_ARRAY_SIZE=Interger.MAX_VALUE-8;
如果保存的数据超过了该长度,则在执行中就会出现OutOfMemoryError错误
经过一系列的分析可以发现,在ArrayList通过数组保存数据,由于数组的吸纳性特征,所以数据保存顺序就是数据添加时的顺序。另外,由于需要不断地进行新数组的创建与引用修改,这必然会造成大量的垃圾内存产生,因此在使用ArrayLisy的时候一定要估算好集合保存的数据长度。
18.3.2 ArrayList保存自定义类对象
String类是一个由JDK提供的核心基础类,这个类的整体设计非常完善,因而在进行类集操作时可以保存任意的数据类型,这也包括了开发者自定义的程序诶。为了保证集合中的contains()与remove()两个方法的正确执行,所以必须保证类中已经正确覆写了equals()方法。
范例:在集合中保存自定义类对象
pakcage cn.mldn.demo;
import java.util.ArrayList;
import java.util.List;
class Member{
//自定义程序类
private String name;
private int age;
public Member(String name,int age){this.name=name;this.age=age;}
@Override
public boolean equals(Object obj)
{
//对象比较
if(this==obj){return true;}
if(obj==null){return false;}
if(!(obj instanceof(Member))){return false;}
Member mem=(Member)obj;
return this.name.equals(mem.name)&&this.age==mem.age;
}
public String toString(){return "姓名"+this.name+"年龄"+this.age;}
}
public class JavaCollectDemo
{
public static void main(String[]args)
{
List<Memeber>all=new ArrayList<Member>();//实例化接口集合
all.add(new Member("zs",30));
all.add(new Member("ls",30));
all.add(new Member("ww",30));
System.out.println(all.contains(new Member("ww",78)));
all.remove(new Member("zs",30));//删除数据
all.forEach(System.out::println);
}
}
本程序通过List集合保存了自定义的Member类对象,由于contains()与remove()方法的时限要求是通过对象比较的形式来处理,所以必须在Member类中实现equals()方法的覆写。
18.3.3 LinkedList子类
LinkedList子类是基于链表形式实现的List接口标准,该类定义如下
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>,Deque<E>,Cloneable,Serializable{}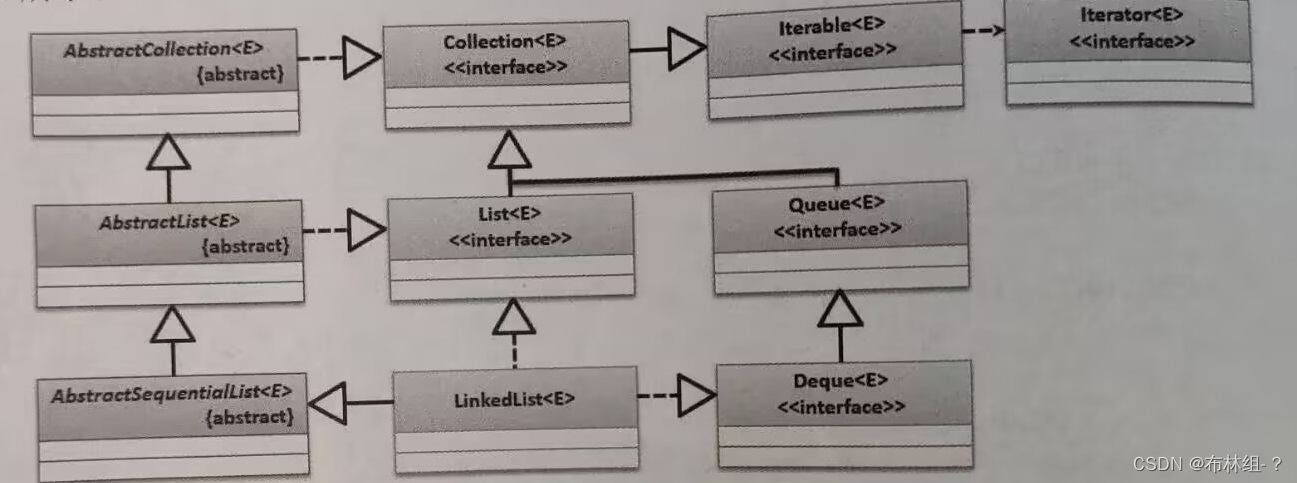
通过继承关系可以发现,该类除了实现List接口外,也实现了Deque接口(双端队列)。
范例:使用LinkedList子类实现集合操作
pakcage cn.mldn.demo;
import java.util.LinkedList;
import java.util.List;
public class JavaCollectDemo
{
public static void main(String []args)
{
List<String>all=new LinkedList<String>();//实例化集合接口
all.add("AAA");
all.add("AAA");
all.add("BBB");
System.out.println(all);
}
}
本程序更换了List接口的实例化子类,由于LinkedList与ArrayList都遵从List实现标准,所以代码的形式与ArrayList完全相同。
提示:关于LinkedList子类实现原理
LinkedList是基于链表结构实现地List集合标准,其核心原理与12章中讲解的链表形式,都是基于Node节点实现数据存储关系
链表与数组的最大区别在于:链表实现不需要进行新数组的空间开辟,但是数组在根据索引获取数据时(List接口扩展get()方法)时间复杂度是O(1),而链表的时间复杂度是O(n)
18.3.4 Vector子类
Vector是一个原始的程序类,这个类在JDK1.0的时候就提供过,而JDK1.2的时候由于很多开发者已经习惯用Vector,而且许多系统类也是基于Vector实现的,考虑到其使用的的广泛性,所以类集框架将其保存了下来,并且让其多实现一个List接口,下面来观察Vector定义结构
public class Vector<E>extends AbstractList<E>implements List<E>,RandomAccess,Cloneable,Serializable{}
从定义可以发现Vextor类与ArrayList类都是AbstractList抽象类的子类,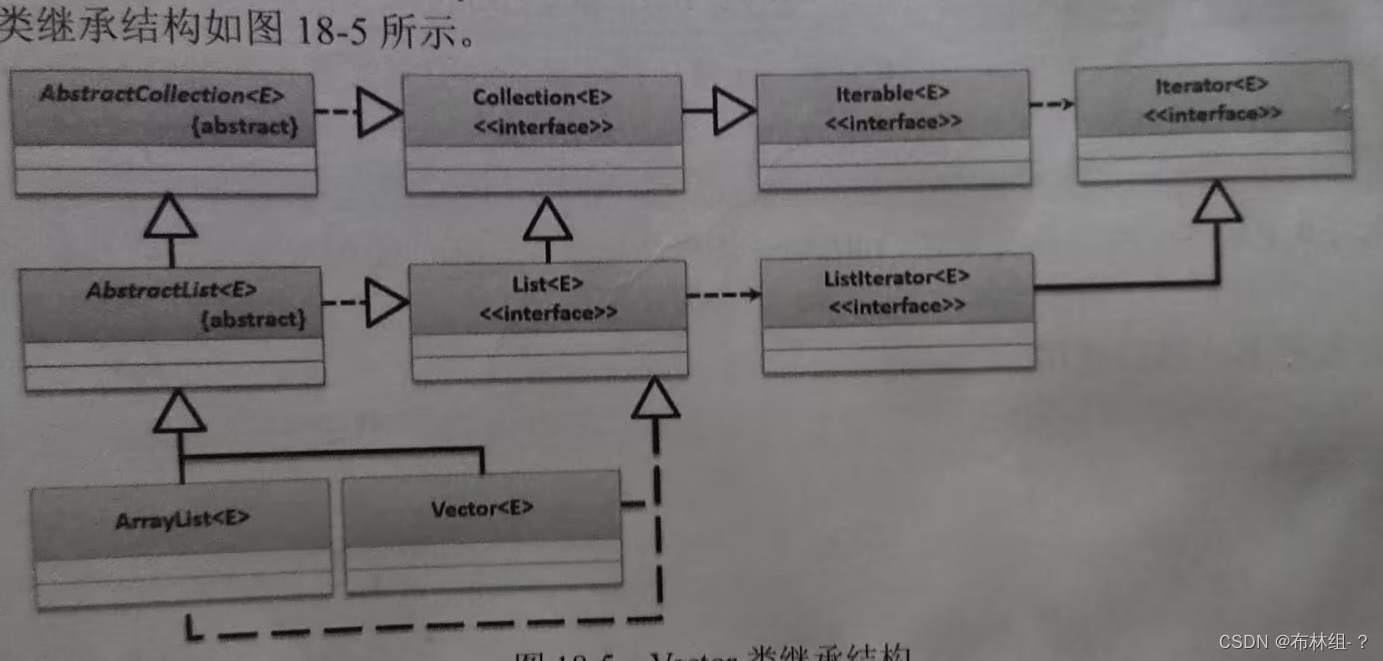
范例:使用Vextor类实例化List接口
package cn.mldn.demo;
import java.util.List;
import java.util.Vector;
public class JavaCollectDemo
{
public static void main(String[]args)
{
List<String>all=nre Vector<String>();//实例化集合接口
all.add("AAA");
all.add("AAA");
all.add("BBB");
System.out.println(all);
}
}
本程序通过Vector实例化了List接口对象,随后利用List接口提供的标准操作方法进行了数据的添加与输出。
提示:关于Vector实现的进一步说明
ArrayList与Vector除了退出的时间不同外,实际上他们的内部实现机制也有所不同。通过源代码的分析可以看出Vector类中的操作方法采用的都是synchronized同步处理,而ArrayList并没有考虑同步处理。所以Vector类中的方法在多线程访问的时候属于线程安全的,但是性能不如ArrayList高,所以考虑线程并发访问的情况下才回去使用Vector子类。
18.4 Set集合
为了与List接口的使用有所区分,在进行Set接口程序设计时要求其内部不允许保存重复元素,Set接口定义如下
public interface Set<E>extends Collection<E>{}
在JDK1.9之前Set接口并没有对Collection接口功能进行扩充,而在JDK1.9之后Set接口追加了许多static方法,同时提供了将许多对象转为Set集合的操作支持。
范例:观察Set接口使用
package cn.mldn.demo;
import java.util.Set;
public class JavaColectDemo
{
Set<String>all=Set.of("AAA","AAA","BBB");
System.out.println(all);
}
由于Set接口本身的特点,所以当通过of()方法向Set集合中保存重复元素师会抛出异常。在Set接口中有两个常用的子类:HashSet(散列存放)、TreeSet(有序存放)这些子类的继承关系
18.4.1 HaseSet子类
HashSet是Set接口较为常见的一个子类,该子类的最大特点是不允许保存重复元素,并且所有的内容都采用散列(无序)的方式进行存储
public class HaseSet<E> extends AbstractSet<E> implements Set<E>,Cloneable,Serializable{}
HashSet子类继承了AbstractSet的抽象类,同时实现了Set接口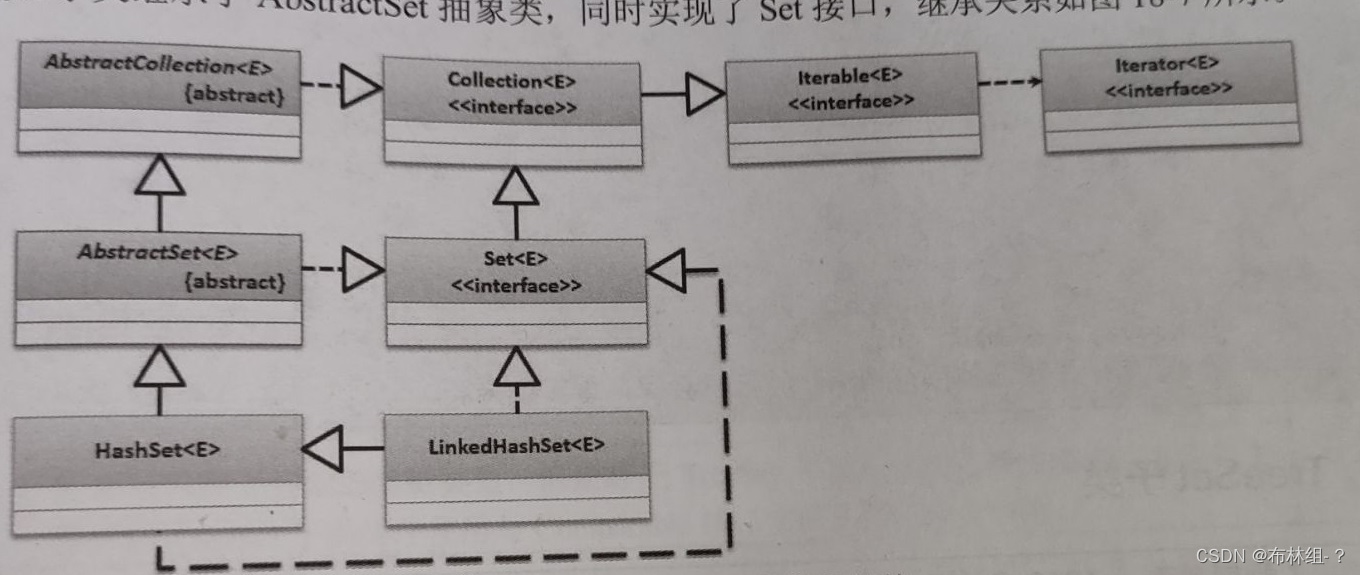 范例:使用HashSet保存数据
范例:使用HashSet保存数据
package cn.mldn.demo;
import java.util.HashSet;
import java.util.Set;
public class JavaCollectDemo
{
public static void main(String []args)
{
Set<String>all=new HashSet<String>();
all.add("AAA");
all.add("BBB");
all.add("BBB");
System.out.println(all);
}
}
执行结果BBB,AAA
本程序向Set集合中保存了重复的数据,但通过输出的集合内容里来看,重复数据并没有八寸,并且所有数据散列排放。
提示:顺序式保存
在Ste接口中,HashSet的使用限制少,而HashSet唯一的问题在于无序处理。为了解决这一问题,在JDK1.4后提供了LinkedHashSet子类,实现基于链表的数据保存。
范例:使用LinkedHashSet子类
package cn.mldn.demo;
import java.util.LinkedHashSet;
import java.util.Set;
public class JavaCollectDemo
{
public static void main(String []args)
{
Set<String>all=new LinkedHashSet<String>();//为Set父接口进行实例化
all.add("AAA");
all.add("BBB");
all.add("CCC");
all.add("DDD");
System.out.println(all);
}
}
此时输出的结果就是集合的保存顺序,并且不会重复保存数据
18.4.2 TreeSet子类
TreeSet子类可以针对设置的数据进行排序保存,TreeSet子类的定义结构如下
public class TreeSet<E>extends AbstractSet<E>implements NavigableSet<E>,Cloneable,Serializable{}
通过继承关系可以发现,TreeSet继承AbstractSet抽象类并实现了NavigableSet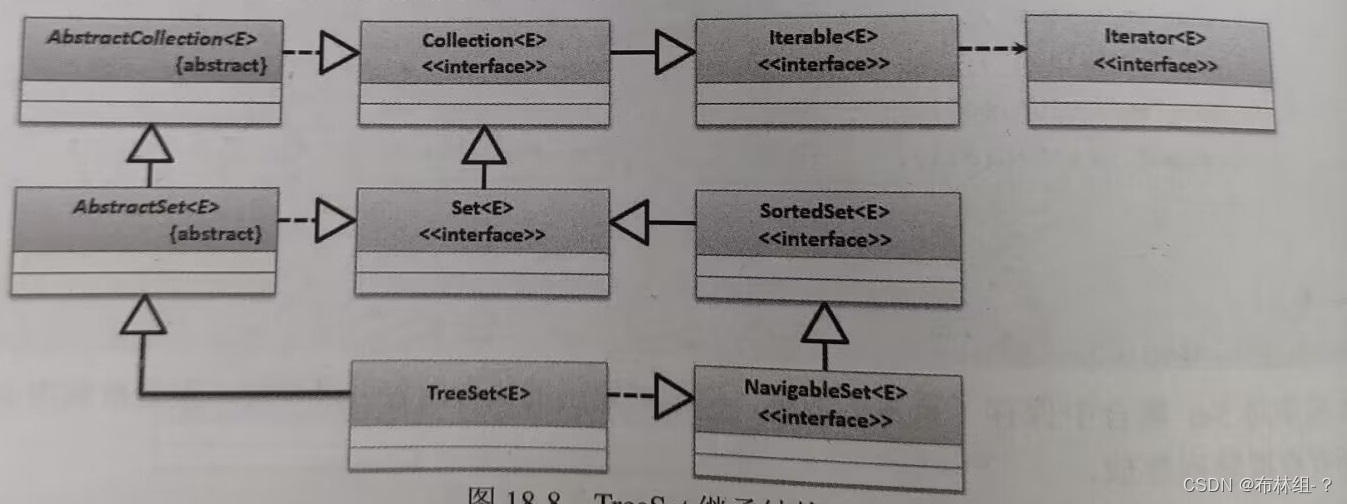 范例:使用TreeSet保存数据
范例:使用TreeSet保存数据
package cn.mldn.demo;
import java.util.Set;
import java.util.TreeSet;
public class JavaCollectDemo
{
public static void main(String []args)
{
Set<String>all=new TreeSet<String>();//为Set负借口进行实例化
all.add("AAA");
all.add("BBB");
all.add("CCC");
all.add("Hello");
System.out.println(all);
}
}
本程序使用TreeSet子类进行数据保存,所有保存的数据会按照由小到大的顺序进行排列。
18.4.3 TreeSet子类排序分析
TreeSet类在进行有序数组存储时依据Comparable接口实现排序,并且也是根据Comparable接口中的conpareTo()方法来判断重复元素,所以在使用TreeSet进行自定义类对象保存时必须实现Comparable接口。但是在覆写compareTo()方法时需要进行类中全部属性的比较,否则会出现部分属性相同时被误判为同一个对象,导致重复元素判断失败。
范例:使用TreeSet保存自定义对象
package cn.mldn.demo;
import java.util.Set;
import java.util.TreeSet;
public class JavaCollectDemo
{
public static void main(String []args)
{
Set<String>all=new TreeSet<String>();
all.add("AAA");
all.add("BBB");
all.add("CCC");
all.add("CCC");
}
}
本程序利用TreeSet子类进行数据保存,所有保存的数据会按照由小到大的顺序排列。
18.4.3 TreeSet子类排序分析
TreeSet类在进行有序数据存储时依据的是Comparable接口实现排序,并且也是依据Comparable接口中的compareTo()方法来判断重复元素,所以在使用TreeSet进行自定义类对象保存时必须实现Comparable接口。但是在覆写compareTo()方法时需要在类中进行全部属性的比较,否则会出现部分属性相同时被误判为同一对象,导致重复元素判断失败。
范例:使用TreeSet保存自定义类对象
package cn.mldn.demo;
import java.util.Set;
import java.util.TreeSet;
class Member implements Comparable<Member>
{
//比较器
private String name;
private int age;
public Member(String name,int age)
{
this.name=name;
this.age=age;
}
public String toString(){
return ""+this.name+this.age;
}
@Override
public int compareTo(Member per)
{
if(this.age<per.age)return -1;
else if(this.age>per.age)return 1;
else return this.name.compareTo(per.name);//年龄相同时进行姓名比较
}
}
public class JavaCollectDemo
{
public static void main(String[]args)
{
Set<Member>all=new TreeSet<Member>();
all.add(new Member("zs",19));
all.add(new Member("zsl",19));
all.add(new Member("ww",20));
all.forEach(System.out::println);
}
}
zs 19
zsl 19
ww 20
本程序利用TreeSet保存自定义Member对象,由于存在排序的需求,Member类实现了Comparable接口并正确覆写了compareTo()方法,这样TreeSet就可以依据compareTo()方法的判断结果来判断是否为重复元素。
18.4.4 重复元素消除
由于TreeSet子类有排序的需求,所以利用Comparable接口实现了重复元素的判断,但是在非排序的集合中对于重复元素的判断依靠的是Object类中提供的两个方法
hash码:public int hashCode()
对象比较:public boolean equals(Object obj)
在进行对象比较的过程中,首先会使用hashCode()方法对已保存到集合中的对象的hashCode()方法进行比较,如果代码相同,则再使用equals()方法进行属性的依次判断,如果全部相同,则为相同元素。
范例:消除重复元素
package cn.mldn.demo;
import java.util.HashSet;
import java.util.Set;
class Member
{
//比较器
private String name;
private int age;
public Member(String name,int age
{
//属性赋值
this.name=name;
this.age=age;
}
public String toString()
{
return ""+this.name+"年龄"+this.age;
}
@Override
public int hashCode()
{
final int primw=31;
int result=1;
result=prime*result+age;
result=primae*result+((name==null)?0:name.hashCode());
return result;
}
@Override
public boolean equals(Object obj)
{
if(this=obj)return true;
if(obj==null)return false;
if(getClass()!=obj.getClass())return false;
Member other=(Member)obj;
if(age!=other.age)return false;
if(name==null)
{
if(other.name!=null)return false;
}else if(!name.equals(other.name))
return false;
return true;
}
}
public class JavaCollectDemo
{
public static void main(String []args)
{
Set<Member>all=new HashSet<Member>();
all.add(new Member("zs",19));
all.add(new Member("ls",19));
all.add(new Member("ww",20));
all.add(new Member("ww",20));
}
}
本程序通过HashSet保存了重复元素,由于hashCode()方法与equals()方法的作用,所以对于重复元素不进行保存。
18.5 集合输出
Collection接口提供有toArray()方法可以将集合保存的数据转为对象数组返回,用户可以利用数组的循环方式进行内容获取,但是此类方法由于性能不高并不是集合输出的首选方案。在类集框架中对于集合的输出提供了4种方式:Iterrator、ListIterrator、Enumeration、foreach
18.5.1 Iterrator迭代输出
Iterrator是专门的迭代输出接口,所谓的迭代输出,是指依次判断每个元素,判断其是否有内容,如果有内容则把内容输出:
Iterator接口依靠Iterator接口中的iterate()方法实例化
范例:使用Iterator输出Set集合
package cn.mldn.demo;
import java.util.Iterator;
import java.util.Set;
public class JavaCollectDemo
{
public static void main(String []args)
{
Set<String>all=Set.of("hello","mldnjava","java");//创建Set集合
Iterrator<String>iter=all.iterator();//实例化Iterator接口对象
Iterator<String>iter=all.iterator();
while(iter.hasNext())
{
String str=iter.next();
System.out.print(str+"、");
}
}
}
Set接口示Collection的子接口,所以Set接口中听过有iterate()方法可以直接获取Iterator接口实例,这样就可以采用迭代的方式实现内容输出
提示:关于数据删除操作
在Iterator接口中提供有remove()方法、Collection接口中也提供有remove()方法,这两种删除方法有什么区别
回答:迭代输出时,每一次输出都需要依据存储的数据内容进行判断,如果直接通过Collection接口提供的remove()方法删除了集合中的数据,那么就会出现访问异常,所以Iterator接口才提供remove()方法以实现正确的删除操作。
范例:迭代输出删除数据
package cn.mldn.demo;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class JavaCollectDemo
{
public static void main(String[]args)
{
Set<String>all=new HashSet<String>();
all.add("AAA");
all.add("BBB");
all.add("BBB");
all.add("CCC");
Iterator<String iter=all.iterator();
while(iter.hasNext())
{
String str=iter.next();//获取数据
if("mldn".equals(str)){iter.remove();}
else{System.out.print(str+"、");}
}
}
}
18.5.2 ListIterator双向迭代输出
Iter完成的是由前往后的单向输出操作,如果想在需要可以完成由前向后和由后向前输出,那么就可以利用ListIterator接口完成,此接口时Iterator的子接口。ListIterator接口主要使用两个扩充方法: Iterator接口可以通过Collection接口实现实例化操作,而ListIterator接口只能够通过List子接口进行实例化(Set子接口无法使用ListIterator接口输出)
Iterator接口可以通过Collection接口实现实例化操作,而ListIterator接口只能够通过List子接口进行实例化(Set子接口无法使用ListIterator接口输出)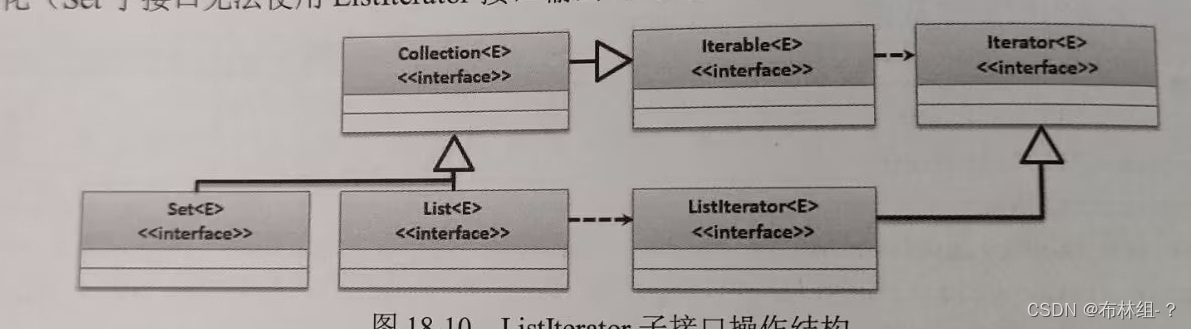
范例:执行双向迭代操作
package cn.mldn.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class JavaCollectDemo
{
public static void main(String[]args)
{
List<String>all=new ArrayList<String>();//为List父接口进行实例化
all.add("xl");//保存数据
all.add("mldn");//保存数据
all.add("AAA");
ListIterator<String>iter=all.listIterator();//获取ListIterator接口实例
System.out.print("由前往后输出");
while(iter.hasNext())
{
System.out.print(iter.next()+"、");
}
System.out.print("由后往前输出");
while(iter.hasPrevious()){System.out.print(iter.previous());}
}
}
本程序通过ListIterator接口实现了List集合的双向迭代输出操作。需要注意的是,在进行由后向前的反向迭代前一定要先进行由前往后的迭代后才可以正常使用。
18.5.3 Enumeration枚举输出
Enumeration是在JDK1.0时推出的早期集合输出接口(最初被称为枚举输出),该接口设置的主要目的时输出Vector几何数据,并且在JDK1.5后使用泛型重新进行了接口定义。Enumeration借口常用方法如下:
在程序中,如果要将Enumeration的实例化对象,只能够依靠Vector类完成。在Vector子类中定义了如下方法:public Enumeration<E>elements()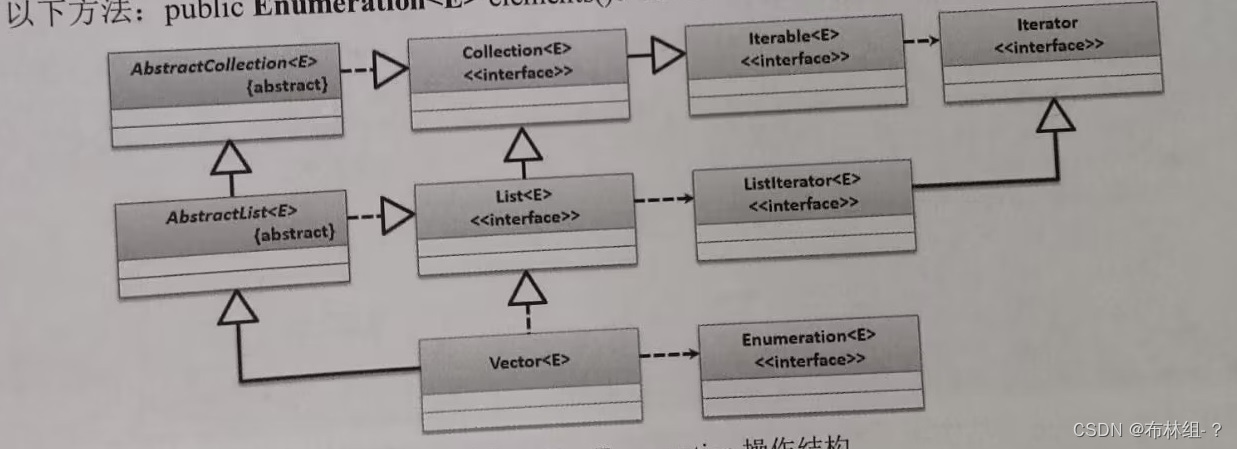 范例:使用Enumeration输出Vector集合数据
范例:使用Enumeration输出Vector集合数据
package cn.mldn.demo;
import java.util.Enumeration;
import java.util.Vector;
public class JavaCollectDemo
{
public static void main(String[]args)
{
Vector<String>all=new Vector<String>();//实例化Vector
all.add("xl");
all.add("mldn");
all.add("AAA");
Enumeration<String>enu=all.elements();
while(enu.hasMoreElements())
{
String str=enu.nextElements();
System.out.print(str+"、");
}
}
}
本程序通过Vector获取了Enumeration接口实例,这样就额可以利用循环的方式实现内容的获取操作,但是需要注意的是,Enumeration接口并没有提供删除方法,即只支持输出操作。
18.5.4 foreach输出
package cn.mldn.demo;
import java.util.HashSet;
import java.util.Set;
public class JavaCollectDemo
{
public static void main(String[]args)
{
Set<String>all=new HashSet<String>();//实例化Set
all.add("xl");
for(String str:all)
{
System.out.println(str+"、");
}
}
}
本程序通过foreach语法实现了Set集合内容的输出,其操作形式与数组输出完全相同
提示:能否自定义foreach输出
本程序通过foreach实现了类的迭代输出支持,那么能否通过foreach实现自定义类的输出操作。
回答:需要Iterator接口支持
Iterator接口是在JDK1.5之后提供的迭代支持接口,并且在JDK1.5之后Colleaction也继承了Iterable接口。Java规定Iterable接口可以支持foreach输出,所以只有Set或List集合才可以通过fareach实现。
范例:自定义类使用foreach输出
package cn.mldn.demo;
import java.util.Iterator;
class Message implements Iterable<String>
{
private String[]content=new String[]{"AAA","BBB","CCC"};//信息内容
private int foot;
@Override
public Iterator<String>iterator()
{
return new MessageIterator();
}
private class MessageIterator implements Iterator<String>
{
@Override
public boolean hasNext()//判定是否存在内容
{
return Message.this.foot<Message.this.content.length;
}
@Override
public String next(){return Message.this.content[Message.this.foot++];}
}
}
public class JavaCollectDemo
{
public static void main(String []args)
{
Message message=new Message();
for(String msg:message){System.out.print(msg+"、");}
}
}
18.6 Map集合
Map是进行·二元偶对象(存储结构为key=value的形式)数据操作的标准接口,这样开发者就可以根据key获取到value内容:
从JDK1.9后为了方便进行Map数据的操作,提供的Map.of()方法可以将接收到的每一组数据转为Map保存。
范例:使用Map保存key-value数据
pakcage cn.mldn.demo;
import java.util.Map;
public class JavaCollectDemo
{
public static void main(String[]args)
{
Map<String,Interger>map=Map.of("one",1,"two",2);
System.out.println(map);
}
}
本程序利用Map.of()方法将两组数据转为了ap集合,但是利用此种方式设置数据时需要注意以下两点
如果设置的key重复,则程序会弹出异常信息,提示key重复
如果设置的key或value为null,则程序执行中会抛出异常
在实际开发中对于Map接口的使用往往需要借助其子类进行实例化,常见的子类有HashMap、LinkedHashMap、Hashtable、TreeMap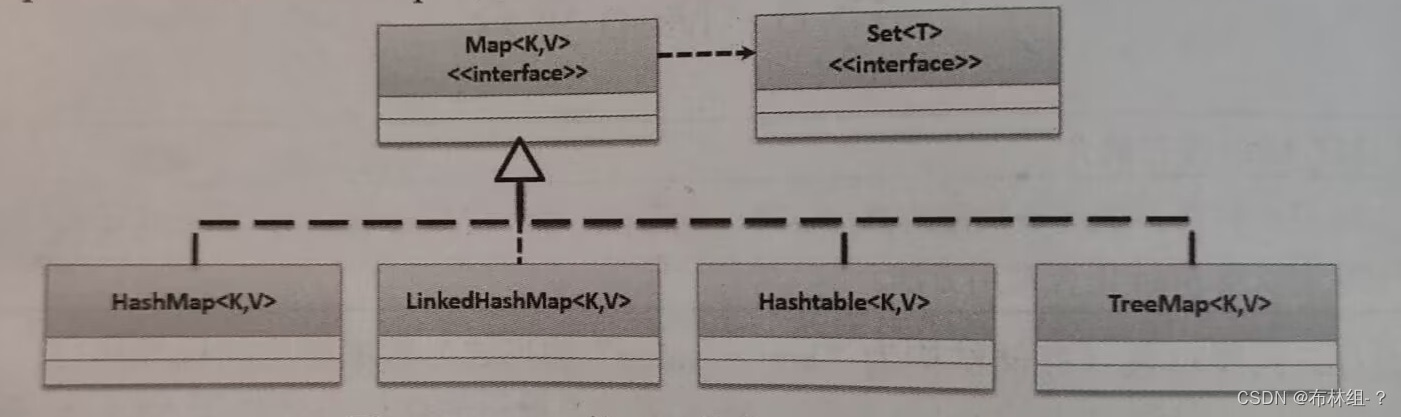
18.6.1 HashMap子类
HashMap是Map接口的常用子类,该类的主要特点是采用散列方式进行存储。HashMap子类的定义结构如下
public class HashMap<K,V>extends AbstractMap<K,V>implements Map<K,V>,Cloneable,Serializable{}
HashMap继承了AbstarctMap抽象类并实现了Map接口。HashMap子类继承结构如下: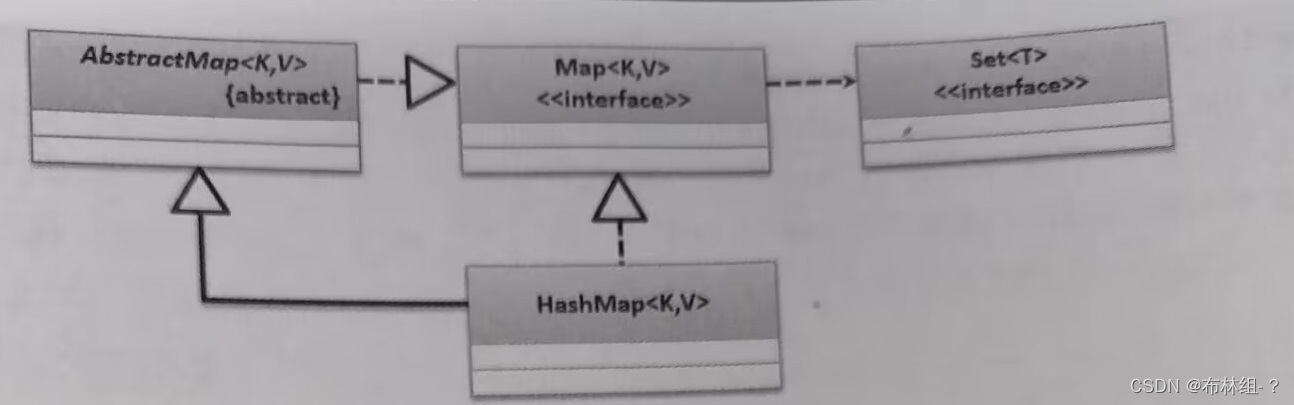
范例:使用HashMap进行Map集合操作
package cn.mldn.demo;
import java.util.HashMap;
import java.util.Map;
public class JavaCollectDemo
{
public void main(String[]args)
{
Map<String,Interger>map=new HashMap<String,Interger>();//创建Map集合
map.put("one",1);
map.put("two",2);
map.put("one",101);
map.put("zero",null);
System.out.println(map.get("one"));
System.out.println(map.get(null));
System.out.println(map.get("ten"));
}
}
本程序利用Map接口中的put()方法保存了两组数据,并且在HashMap子类进行数据保存时,key或value的数据都可以为null;当使用get()方法根据key获得指定数据时,如果key不存在,则返回null
提示:Map和Collection在操作上的不同
通过这一代码可以发现,Map集合和Collection集合在保存数据后操作上的不同如下
Collection接口设置完内容的目的是输出
Map接口设置完内容的目的是查找。
在Map中提供的put()方法设置数据时,如果设置的key不存在,则可以直接保存,并且返回null;如果设置的key存在,则会发生覆盖,并返回覆盖前的内容。
范例:观察Map集合中的数据保存方法
package cn.mldn.demo;
import java.util.HashMap;
import java.util.Map;
public class JavaCollectDemo
{
public static void main(String[]args)
{
Map<String,Interger>map=new LinkedHashMap<String,Interger>();
map.put("one",1);
map.put("two",2);
map.put(null,0);
map.put("zero",null);
System.out.println(map);
}
}
本程序利用LnkedHashMap子类实现数据存储,通过输出结果可以发现,集合的保存顺序与数据增加顺序相同,同时在LinkedHashMap子类中允许保存的key或value内容为null.
18.6.3 Hashtable子类
Hashtable子类是从JDK1.0时提供的二元偶对象保存集合,在JDK1.2进行类集框架设计师,为了保存HshTable子类,使其多实现了一个ap接口。Hashtable子类定义结构如下
public class Hashtable<K,V>extends Dictionary<K,V>implements Map<K,V>,Clonable,Serializabale{}
Hashtable是最早的Dictionary子类,从JDK1.2才实现了Map接口。Hashtable子类继承结构如图
范例:使用Hashtable子类保存数据
package cn.mldn.demo;
import java.util.HashTable;
import java.util.Map;
public class JavaCollectDemo
{
public static void main(String[]args)
{
Map<String,Interger>map=new Hashtable<String,Interger>();//创建Map
map.put("one",1);
map.put("two",2);
System.out.println(map);
}
}
本程序通过Hashtable子类实例化了ap集合对象,可以发现ashtable中所保存的数据采用散列方法存储。
注意:HashMap与Hashtable区别
HashMap中的方法都属于异步操作(非线程安全),HashMap允许保存null数据
Hashtable中的方法都属于同步操作(线程安全),Hashtable不允许保存null数据,否则会出现错误。
18.6.4 TreeMap子类
TreeMap子类属于有序的Map集合类型,他可以按照key进行排序,所以在使用这个自雷的时候一定要配合Comparable接口共同使用。TreeMap子类的定义如下
public class TreeMap<K,V> extends AbstractMap<K,V>implements NavigableMap<K,V>,Cloneable,Serializable{}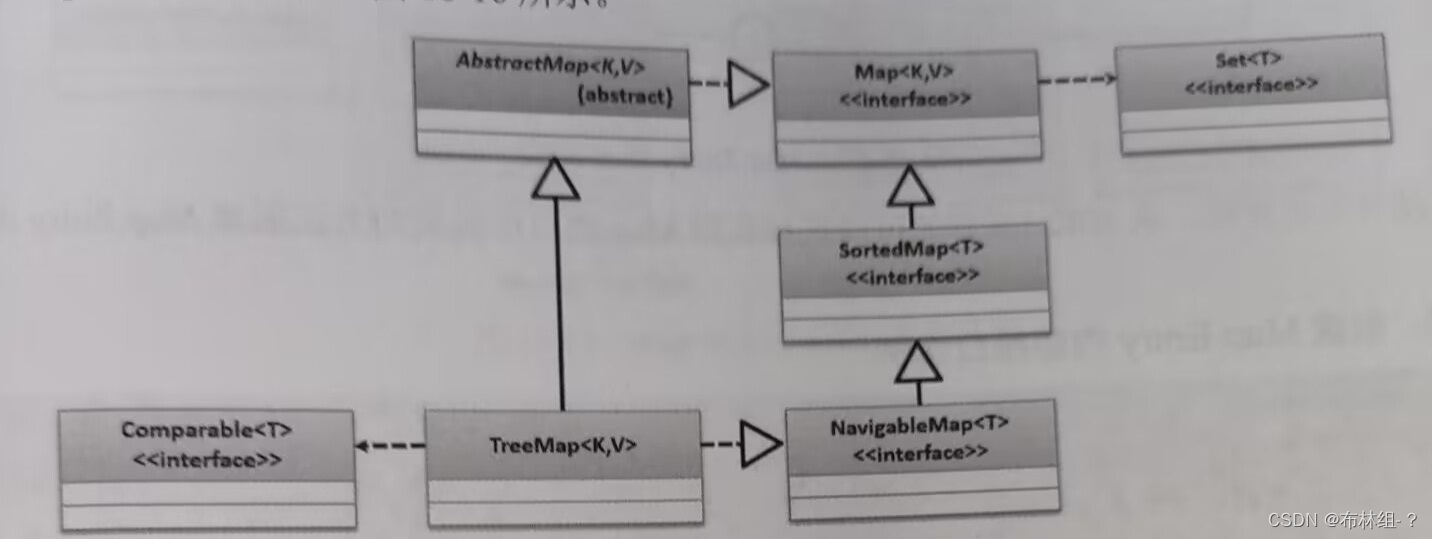 范例:使用TreeMap进行数据Key排序
范例:使用TreeMap进行数据Key排序
package cn.mldn.demo;
import java.util.Map;
import java.util.TreeMap;
public class JavaCollectDemo
{
public static void main(String[]args)
{
Map<String,Interger>map=new TreeMap<String,Interger>();//创建Map集合
map.put("C",3);
map.put("B",2);
map.put("A",1)
System.out.println(map);
}
}
程序执行结果:
{A=1,B=2,C=3}本程序将TreeMap中保存的key类型设置为String,由于String实现了Comparable接口,所以此时可以根据保存字符的编码由低到高进行排序。
18.6.5 Map.Entry内部接口
在Map集合中,所有保存的对象都属于二元偶对象,所以针对偶对象的数据操作标准就提供一个Map.Entry的内部接口。以HashMap子类为例可以得到以下: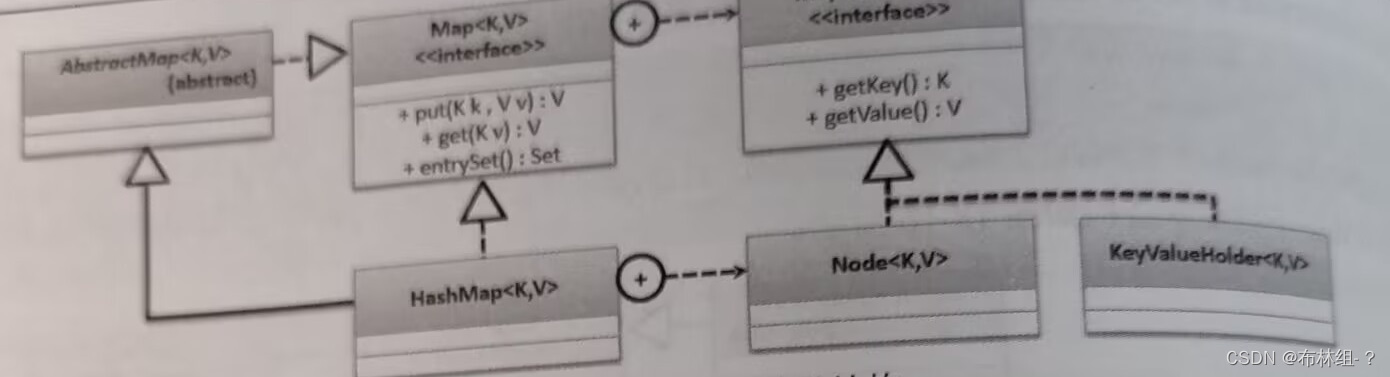
为方便开发者的使用,从JDK1.9开始可以直接利用Map接口提供的方法创建Map.Entry内部接口实例
范例:创建Map.Entry内部接口实例
package cn.mldn.demo;
import java.util.Map;
public class JavaCollectDemo
{
public static void main(String[]args)
{
Map.Entry<String,Interger>entry=Map.entry("one",1);//创建Map.Entry接口实例
System.out.println("获取key"+entry.getKey());//获取保存的key
System.out.println("获取value"+entry.getValue());//获取保存value
System.out.println(entry.getClass().getName());
}
}
本程序在进行Map.Entry对象构建时,只传入key和value就会自动利用KeyValueHolder子类实例化Map.Entry接口对象,对于开发者而言只需清楚如何通过每一组Map.Entry获取对应的key(getKey()与value(getValue()))数据即可。
18.6.6 Iterator输出Map集合
集合数据输出的标准形式是基于Iterator接口完成的,Collection接口直接提供iterator()方法可以获得Iterator接口实例。但是由于Map接口中保存的数据是多个Map.Entry
接口封装的二元偶对象(Collection与Map存储的区别如下):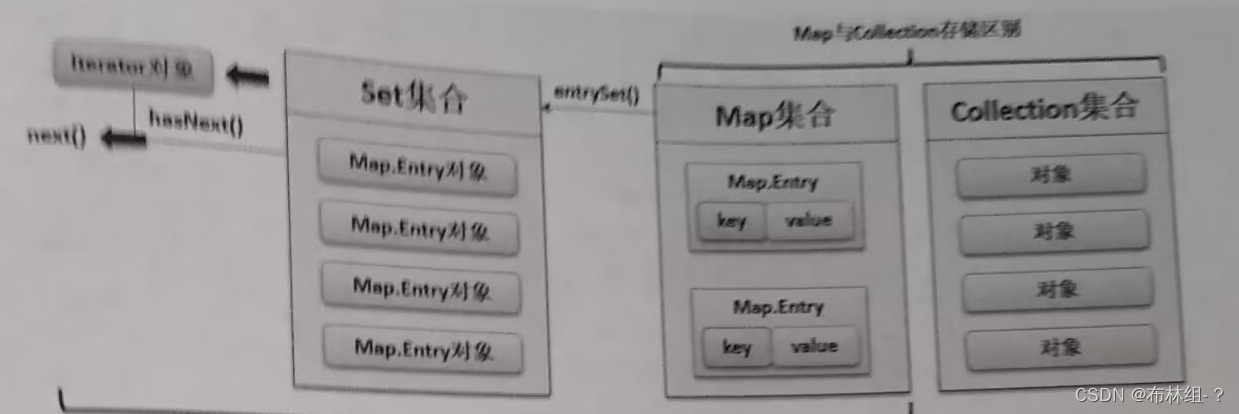 所以就必须采用以下的不走实现ap集合的迭代输出
所以就必须采用以下的不走实现ap集合的迭代输出
使用Map接口中的entryMap()方法,将Map集合变为Set集合
取得Set接口实例后就可以利用iterator()方法取得iterator实例化对象。
使用Iterator迭代找到每一个Map.Entry对象,并进行key与value的分离
范例:使用Iterator输出Map集合
package cn.mldn.demo;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class JavaCollectDemo
{
public static void main(String[]args)
{
Map<String,Interger>map=new HashMap<String,Interger>();//获取Map接口实例
map.put("one",1);//保存数据
map.put("two",2);//保存数据
Set<Map,Entry<String,Interger>>set=map.entrySet();//Map变为Set集合
Iterator<Map.Entry<String,Interger>>iter=set.iterator();//获取Iterator
while(iter.hasNext())
{
Map.Entry<String,Interger>me=iter.next();
System.out.println(mw.getKey()+"="+me.getValue());
}
}
}
本程序通过entrySet()方法将ap集合转为了Set集合,由于Set集合保存的是多个Map.Entry接口实例,所以当使用Iterator迭代时就必须通过Map.Entry接口中提供的方法实现key和value的分离,对于Map集合的输出操作,除了使用Iterator接口外,也可以利用foreach循环实现,其基本操作与Iterator输出类似。
范例:通过foreach循环输出Map集合
package cn.mldn.demo;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class JavaCollectDemo
{
public static void main(String []args)
{
Map<String,Interger>map=new HashMap<String,Interger>();//获取Map接口实例
map.put("one",1);
map.put("two",2);
Set<Map.Entry<String,Interger>>set=map.entrySet();//Map变为Set
for(Map.Entry<String,Interger>entry:set)//foreach迭代
{
System.out.println(entry.getKey()+"="+entry.getValue());
}
}
}
foreach在进行爹带的是无法直接通过map接口完成,必须将Map转换为Set存储接口,才可以在每次迭代时获取Map.Entry接口实例。
18.6.7 自定义key类型
在使用Map接口进行数据保存时,里面所存储的key与value的数据类型可以全部由开发者自己设置,除了使用系统类作为key类型外也可以自定义类的形式实现,但是作为key类型的类由于存在数据查找需求,所以必须在类中覆写hasCode()和equals()方法
范例:使用自定义类型作为Map集合中的key
package cn.mldn.demo;
import java.util.HashMap;
import java.util.Map;
class Member
{
private String name;
private int age;
}
public class JavaCollectDemo
{
public static void main(String[]args)
{
Map<Member,String>map=new HashMap<Member,String>();//实例化Map接口对象
map.put(new Member("xl",18),"1111");
System.out.println(map.get(new Member("xl",18)));//通过key找到value
}
}
本程序使用自定义的类进行Map集合中key类型的指定,由于Member类已经正确覆写了hasCode()和equals()方法,所以可以直接根据属性内容来实现内容查找。
提示:关于Hash冲突的解决
Map集合是根据key实现的value数据查询,所以在整体实现中就必须保证key的·1唯一性,但是在开发中依然可能出现key重复的问题,而这种情况就成为sh冲突。在实际开发中,Hash冲突的解决有4中:开放定址法、链地址法、再哈希法、建立公共一出去。在ava中猜中链地址法解决Hash冲突,即将相同的key内容保存在一个链表中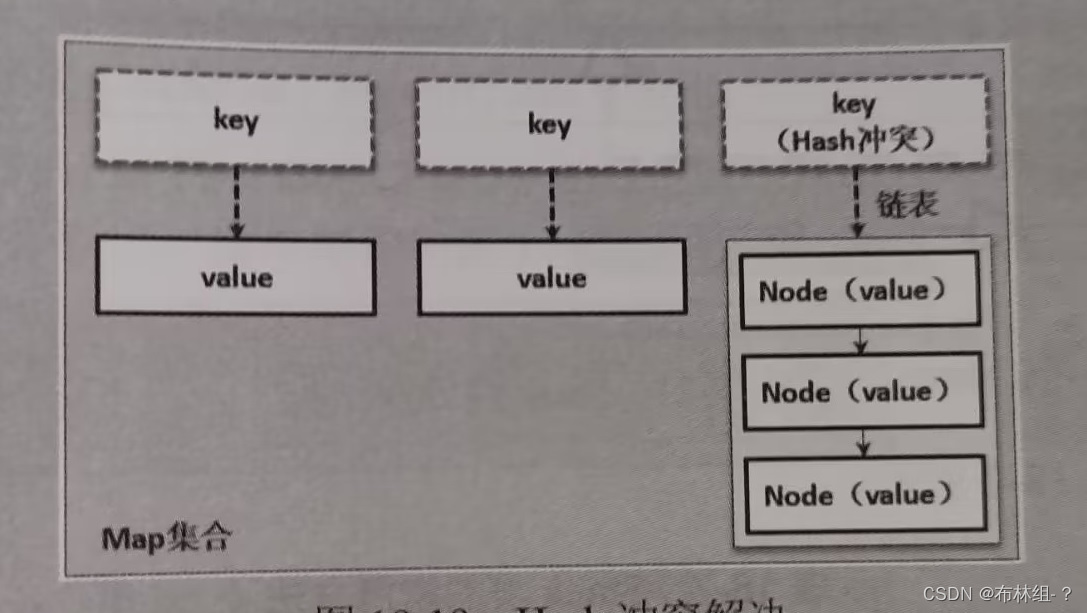
18.7 Stack栈
栈是有序的数据结构,采用的是先进先出(First In Last Out)存储模式,在栈结构中分为栈顶与栈底,开发者只可以对栈顶操作,而不允许进行栈底操作,在栈中有两类核心操作:入栈、出栈、
提示:栈的应用
经常上网的读者应该清楚,在浏览器存在一个后退的按钮,每次后退都是退回到上一步的操作,那么实际上这就是一个栈的应用,采用的是一个先进后出的操作:
Java从JDK1.0开始,提供了Stack栈操作类,Stack类的定义形式如下
public class Stack<E> extends Vector<E>{}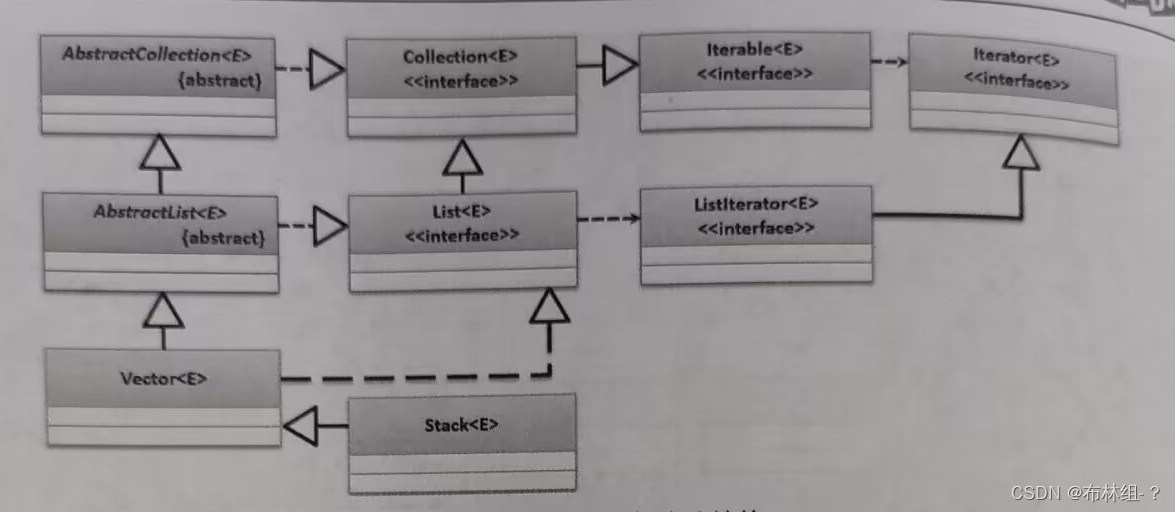
Stack类常用方法
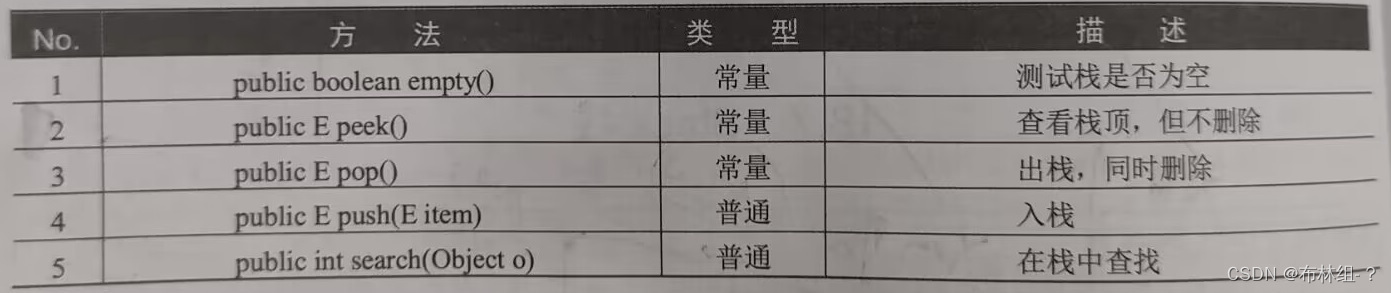
范例:入栈操作与出栈操作
package cn.mldn.demo;
import java.util.Stack;
public class JavaCollectDemo
{
Stack<String>all=new Stacl<String>();//实例化栈结构
all.push("A");入栈操作
all.push("B");
all.push("C");
System.out.println(all.pop());//出站操作
System.out.println(all.pop());//出站操作
}
程序执行结果
C
B
A
本程序通过Stack集合实现了入栈操作和出栈操作,在出栈时最后保存的数据最先出栈,当栈中已经没有数据保存时在执行出栈操作时会出现空栈异常。
18.8 Queue队列
队列是一种先进先出(First In First Out,FIFO)的线性数据结构,所有的数据通过队尾部进行添加,而后通过队列前端进行取出 继承关系如图
继承关系如图 Queue接口常用方法如表
Queue接口常用方法如表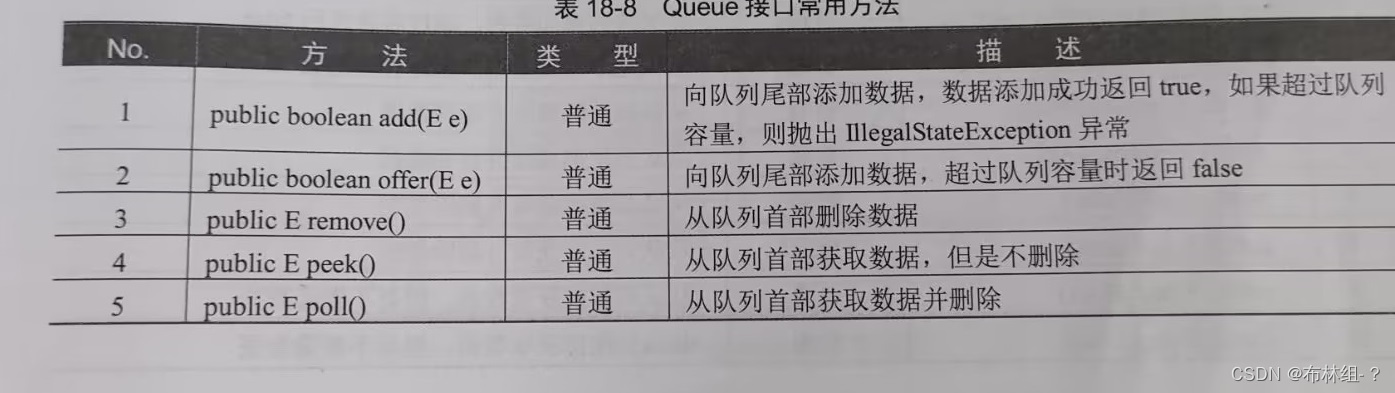
范例:使用Queue接口实现队列存储
package cn.mldn.demo;
import java.util.PriorityQueue;
import java.util.Queue;
public class JavaCollectDemo
{
public static void main(String[]args)
{
//PriorityQueue为优先级队列,会自动为队列中的数据进行排序操作,排列需要Comparable支持
Queue<String>queue=new PriorityQueue<String>();//实例化Queue队列
System.out.println(queue.add("java"));//队尾存储数据
System.out.println(queue.offer("hello"));//队尾存储数据
System.out.println(queue.offer("only"));//队尾存储数据
System.out.println(queue.poll());//队首获取数据并删除
System.out.println(queue.poll());//队首获取数据并删除
System.out.println(queue);
}
}
本程序通过Priority子类实例化了Queue接口,并且利用add()和offer()方法在队列尾部进行数据添加,使用poll()方法通过队首并获取删除排序后的数据,所以最终队列的内容为null。
从JDK1.6开始为了方便队列操作,为Queue定义了一个Deque子接口。Deque接口的最大特点是可以实现数据的FIFO与FILO操作,即队首和队尾都可以进行数据操作。常用方法如表: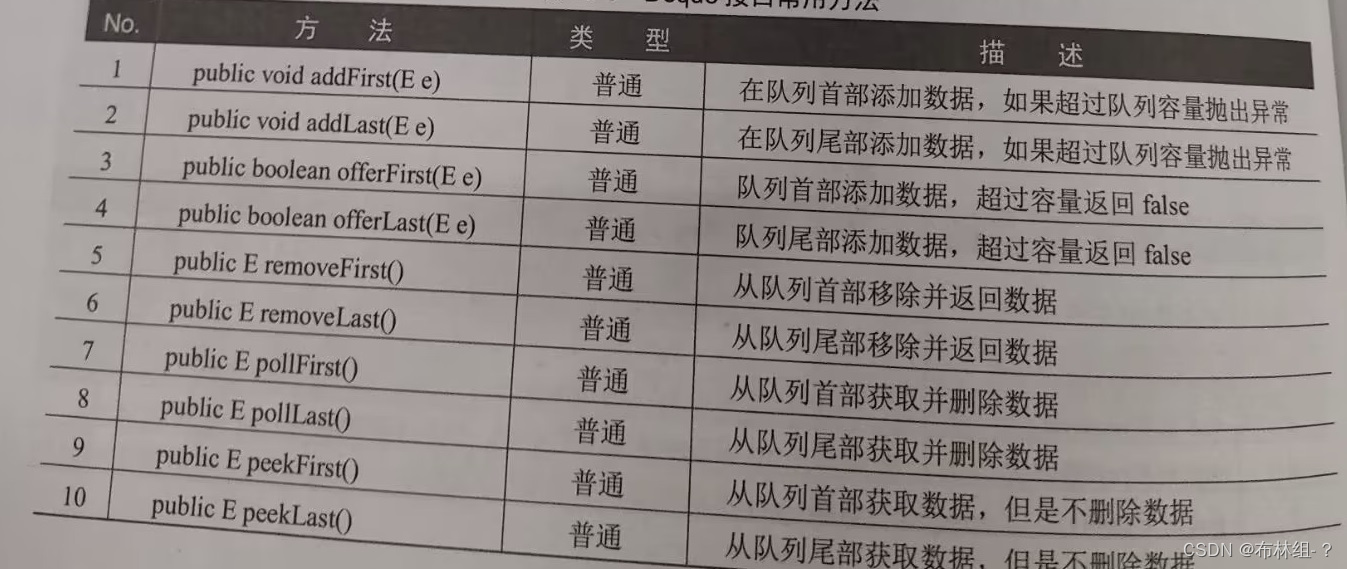
范例:使用Deque接口实现双端队列操作
package cn.mldn.demo;
import java.util.Deque;
import java.util.LinkedList;
public class JavaCollectDemo
{
public static void main(String[]args)
{
Deque<String>deque=new LinkedList<String>();//实例化Deque队列
deque.offer("java");//队尾存储数据
deque.offerFirst("hello");//队首存储数据
deque.offerLast("obly");//队尾存储数据
System.out.println(deque);//输出队列数据
System.out.println(deque.poll());
}
}
Deque是Queue的子接口,所以使用Deque时也可以直接使用Queue接口定义的方法进行队列操作,而除了Queue支持的方法外也可以实现队首和队列的数据操作。
18.9 Properties属性操作
属性一般都是通过字符串数据实现的键值对(key=value,根据key找到对应的value)数据定义,在Java中可以使用Properties类进行操作,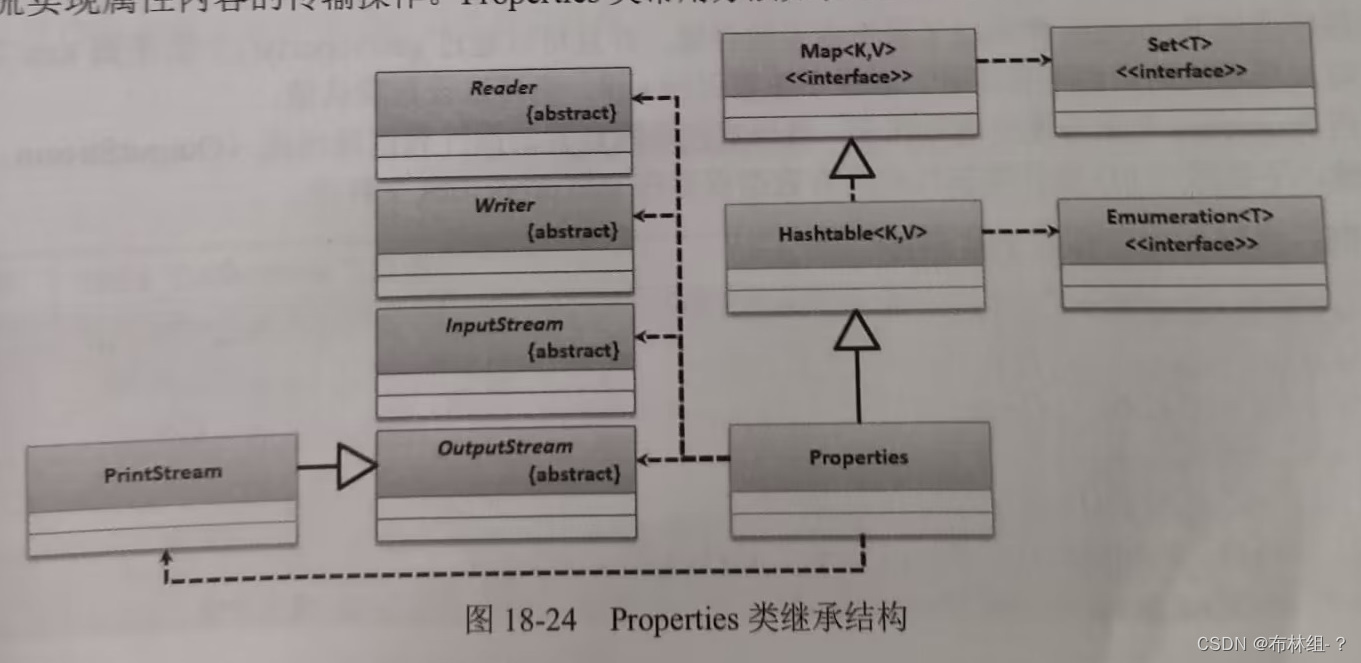 Properties类虽然是Hashtable的子类,但是其可以操作的数据类型只能是String,并且也可以利用输入\输出流实现属性内容的传输操作,常用方法如下:
Properties类虽然是Hashtable的子类,但是其可以操作的数据类型只能是String,并且也可以利用输入\输出流实现属性内容的传输操作,常用方法如下: 范例:属性操作
范例:属性操作
package cn.mldn.demo;
import java.util.Properties;
public class JavaCollectDemo
{
Properties prop=new Properties();//属性存储
prop.setProperty("mldn","java");//设置属性内容
prop.setProperty("mldnjava","java");//设置属性内容
System.out.println(prop.getProperty("mldn"));//根据key查找属性
System.out.println(prop.getProperty("AA","NotFound"));//根据key查找属性
System.out.println(prop.getProperty("AA"));
}
程序执行结果:
java("prop.getProperty("mldn")"代码执行,属性存在返回对应的key)
NotFound("prop.getProperty("AA","NotFound")")代码执行,属性不存在返回默认值。
null("prop.getProperty("AA")"代码执行,属性不存在,默认值返回null)
本程序通过Properties类实现了属性内容的存储,并且可以通过getProperty()方法根据key实现属性内容获取,当查找的属性不存在是,如果不希望返回null,也可以设置默认值
使用Properties类实现属性内容的存储最方便的地方在于,可以直接将所设置的属性通过输出流(OutputStream、Writer)进行传输。下面通过I/O属性通过输出流(OutputStream、Writer)进行传输。下面通过I/O操作将塑性的所有数据保存在info.properties文件中。
范例:将属性内容保存在文件中
package cn.mldn.demo;
import java.io.File;
import java.io.FileOutputStream;
import java.util.Properties;
public class JavaCollectDemo
{
public static void main(String[]args)throws Exception
{
Properties prop=new Properties();
prop.setProperty("mldn","AAA");
prop.setProperty("java","AAA");
prop.store(new FileOutputStream(new File("D:"+File.separator+"info.properties")),"Very Import URL");
}
}
本程序通过FileOutputStream将属性内容以及相关注释保存在了文件中,而对于程序而言就可以在需要的情况下通过Properties类提供的load()方法加载文件内容。
范例:通过Properties类读取属性文件
package cn.mldn.demo;
import java.io.File;
import java.io.FileInputStream;
import java.util.Properties;
public class JavaCollectDemo
{
public static void main(String[]args)throws Exception
{
Properties prop=new Properties();//属性存储
prop.load(new FileInputStream(new File("D:"+File.separator+info.properties)));//读取属性资源
System.out.println(prop.getProperty("mldn"));//读取属性内容
}
}
由于所有的属性内容都保存在了info.properties文件中,所以直接利用FileInputStream通过文件流可以将属性内容加载到程序中进行属性查询操作。
18.10 Collection工具类
Collection是专门提供的一个集合的工具类,可以通过该工具类实现Collection、Map、List、Set、Queue登记和接口的数据操作。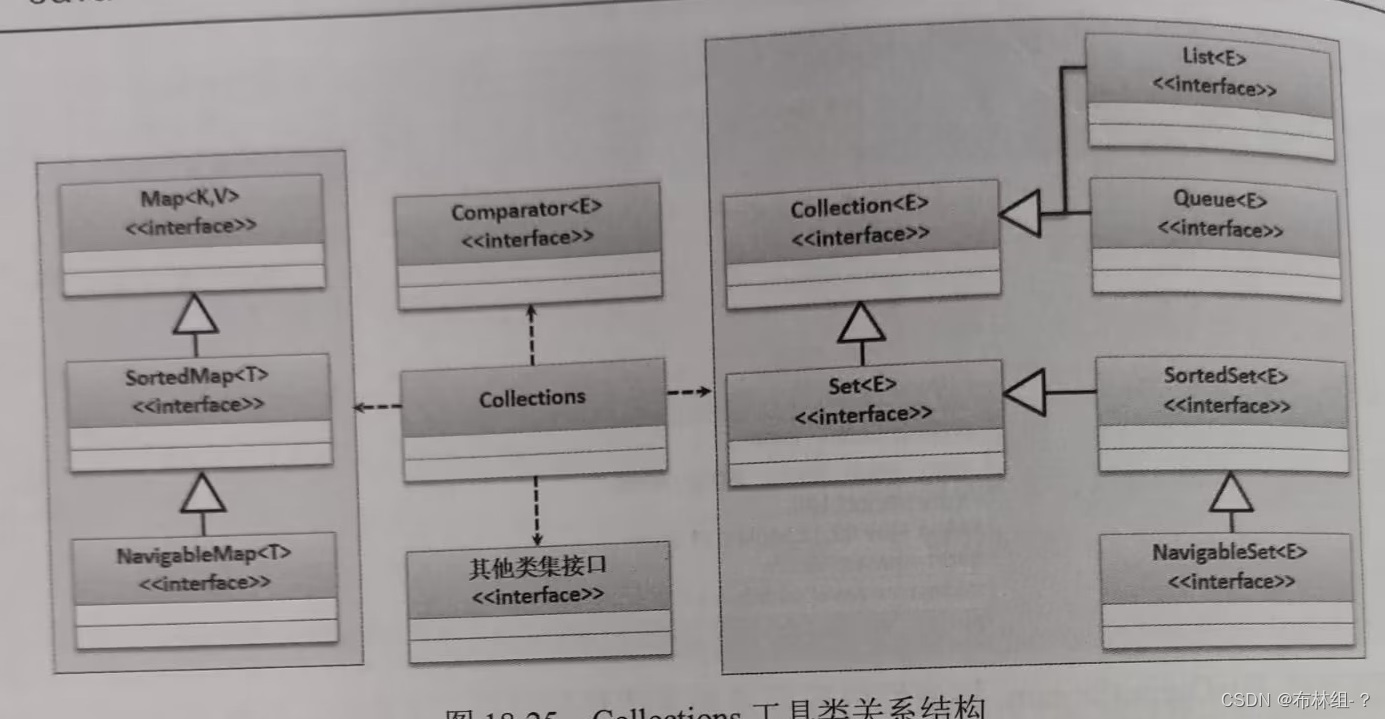
范例:使用Collection类操作List集合
package cn.mldn.demo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class JavaCollectDemo
{
public static void main(String[]args)throws Exception
{
List<String>all=new ArrayList<String>();//实例化List集合
Collection.addAll(all,"hello","mldn","mldnjava");//保存数据
System.out.println(all);
Collection.reverse(all);//集合反转
System.out.println(all);
System.out.println(Collection.binarySearch(all,"mldn"));
}
}
本程序通过Collections工具类实现了List集合内容的操作,可以发现数据存储反转以及二分数据查找等功能都是原始集合标准未提供的方法,而这些操作都通过Collections工具类提供给开发者使用。
18.11 Stream
Stream是从JDK1.8版本后提供的一种数据流的分析操作标准,可以利用其与Lambda表达式结合进行数据统计操作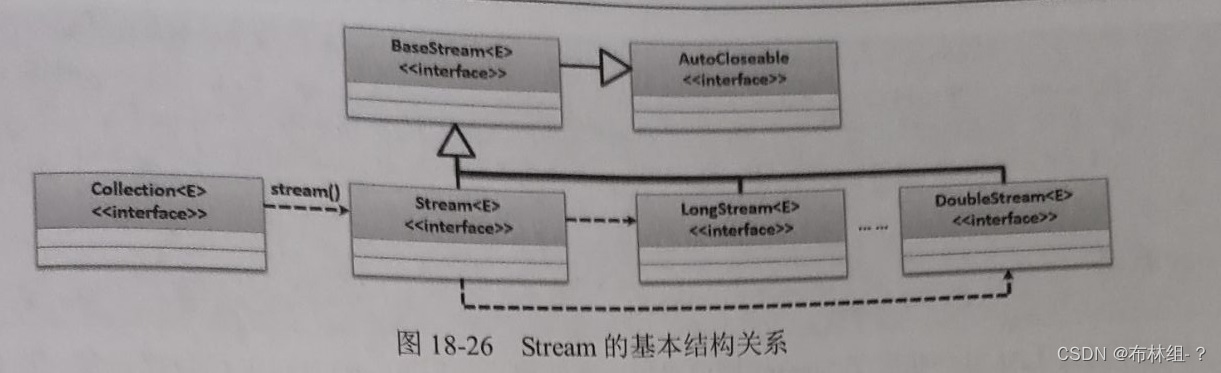
18.11.1 Stream基础操作
Stream接口的主要作用是进行数据流分析处理操作,为了方便可以利用Lambda表达式定义数据分析操作的处理流程,其常用方法如下: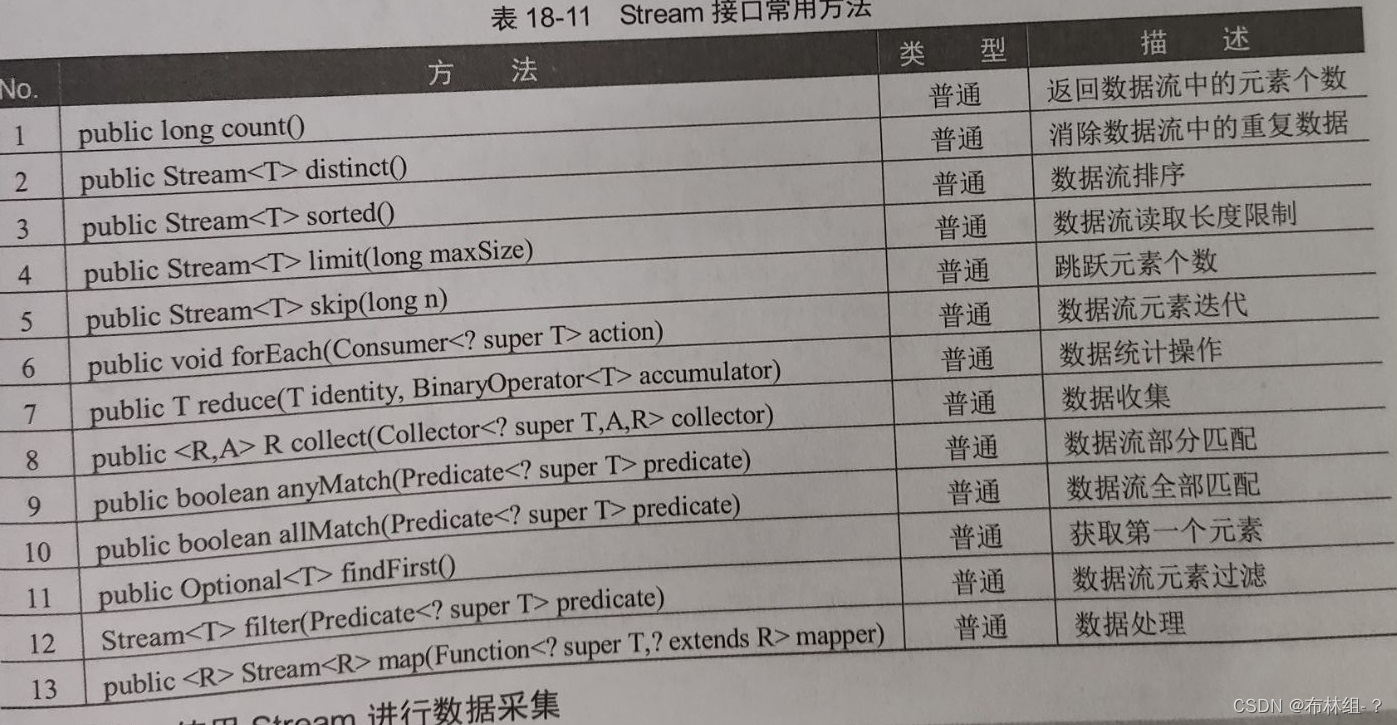
范例:使用Stream进行·1数据采集
package cn.mldn.demo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Stream;
public class JavaCollectDemo
{
List<String>all=new ArrayList<String>();
Collections.addAll(all,"Java","JavaScript","JSP","Json","Python","Ruby","Go");
Stream<String>stream=all.stream();
//将每一个元素全部变为小写字母,而后查询是否存在字母“J”,如果存在则进行个数统计
System.out.println(stream.filter((ele)->ele.toLowerCase().contains("j")).count());
}
本程序通过List集合获取了Stream接口对象,而获取后利用filter()方法进行数据过滤,而后对满足条件的数据采用count()方法进行个数统计。
范例:数据采集
package cn.mldn.demo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Stream.Collections;
import java.util.stream.Stream;
public class JavaCollectDemo
{
public static void main(String[]args)throws Exception
{
List<String>all=new ArrayList<String>();//实例化List集合
Collecttions.addAll(all,"Java","Jsp");//集合数据保存
Stream<String>stream=all.stream();//获取Stream接口对象
//获取元素中包含字母“J”的数据,利用skip()跳过2个数据,利用limit()去除2个数据
List<String>result=stream.filter((ele)->ele.toLowerCase().contains("j")).skip(2).limit(2).collect(Collectors.toList());//活的处理后的数据
}
}
18.11.2 MapRduce
MapRduce是一种分布式计算模型,最初由Google提出,主要用于搜索领域,解决海量数据的计算问题,在MapReduce模型中一共分为两个部分:map(数据处理)与reduce(统计计算),在Stream中既可以利用MapRduce对集合中的数据进行分析。
范例:使用Stream实现Meduce数据分析
package cn.mldn.demo;
import java.util.ArrayList;
import java.util.DoubleSummaryStatics;
import java.util.List;
class Order
{
//订单信息
priavte String name;
private double price;
private int amount;
public Order(String name,double price,int amount){this.name=name;this.price=price;this.amount=amount;}
public int getAmount(){return amount;}
public String getName(){return name;}
public double getPrice(){return price;}
}
public class JavaCollectDemo
{
public static void main(String[]args)throws Exception
{
List<Order>all=new ArrayList<Order>();//List集合
all.add(new Order("AAA狗熊娃娃",9.9,10));//数据添加
all.add(new Order("AAA111"),2009,3);
all.add(new Order("AAA222"),2009,3);
//分析购买商品中带有AAA的数据信息,并且进行商品单价和数量的处理,随后分析汇总
DoubleSummaryStatics stat=all.stream().filter((ele)->ele.getName().toLowerCase().contains("AAA")).mapToDouble((orderObject)->orderObject.getPrice()*orderObject.getAmount()).summerStatictics();
}
}