目录
六、IO流
1.IO流概述
概念
分类
IO体系
简单介绍
最重要,最常用,最常见的两个流
2.File类
路径分隔符
绝对路径和相对路径
构造方法
方法
重命名注意事项
删除注意事项
3.FileInputStream&FileOutputStream
FileInputStream
获取文件输入流
方法
read()方法返回值为什么是int,而不是byte
FileOutputStream
获取文件输出流
方法
4.BufferedInputStream&BufferedOutputStream
小数组的读写和带Buffered的读取哪个更好
BufferedInputStream
获取缓冲输入流
BufferedOutputStream
获取缓冲输出流
方法
5.MultipartFile(springmvc会用到)
6.零拷贝(拓展了解,可以不掌握)
六、IO流
1.IO流概述
概念
作用:IO流用来处理数据传输,java操作数据是通过流的方式,java提供了IO包来进行流操作,使用后需要关闭流
分类
按流向分:输入流,输出流
按操作类型分:
字节流 : 字节流可以操作任何数据,因为在计算机中任何数据都是以字节的形式存储的
字符流 : 字符流只能操作纯字符数据
IO体系
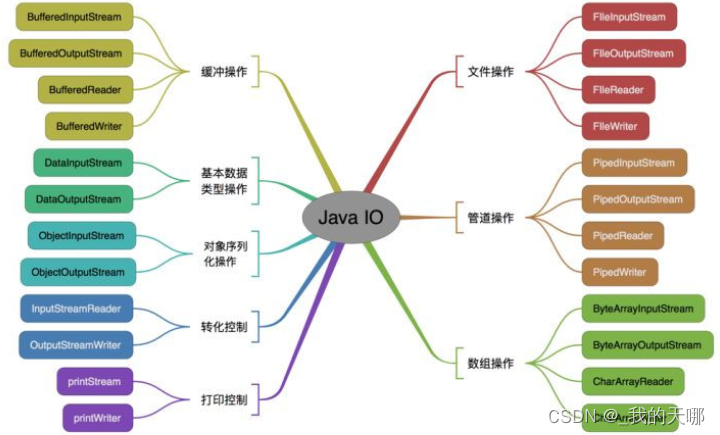
简单介绍
字节流的抽象父类:InputStream,OutputStream
字符流的抽象父类:Reader,Writer
其他子类
最重要,最常用,最常见的两个流
FileInputStream&&FileOutputStream 字节流
BufferedInputStream&&BufferOutputStream 缓冲字节流
可能会用到,但很少见,实际开发中几乎用不到
ServletInputstream 读取客户端的请求信息的输入流
ServletOutputStream 用这个输出流可以将数据返回到客户端
SequenceInputStream 序列流,可以把多个InputStream整合成一个SequenceInputStream
不重要,实际开发不用
FileReader&&FileWriter 字符流,与字节流几乎一样,只是读写的单位是字符
BufferedReader&&BufferedReader 缓冲字符流,与字节流几乎一样,只是读写的单位是字符
LineNumberReader BufferedReader的子类,具有相同的功能,并且可以统计行号
InputStreamReader&OutputStreamWriter 转换流,字节流读入,转为字符流,再转为字节流写出
ByteArrayOutputStream 内存输出流,可以向内存中写数据,把内存当作一个缓冲区(字节数组),写出之后可以一次性获取出所有数据
ObjecOutputStream&&ObjectInputStream 对象操作流,针对对象进行读写,简单理解为序列化和反序列化操作
DataInputStream&&DataOutputStream 数据输入输出流,可以按照基本数据类型大小读写数据
PrintStream 打印流,将对象的toString()结果输出, 并且自动加上换行, 而且可以使用自动刷出的模式
2.File类
定义:文件和目录路径名的抽象表示形式,File类中涉及文件或文件目录的创建、删除、重命名、修改时间、文件大小等
路径分隔符
windows和DOS系统默认使用"\"来表示;
UNIX和URL使用"/"来表示
JAVA提供了一个自适应的常量File.separator
绝对路径和相对路径
绝对路径是一个固定的路径,从盘符开始
相对路径相对于某个位置
构造方法
File(String pathname),根据一个路径得到File对象
File(String parent, String child),根据一个目录和一个子文件/目录得到File对象,通过这种方式可以分别得到某个父目录下不同的子目录文件
File(File parent, String child),根据一个父File对象和一个子文件/目录得到File对象,也可以将父目录封装成File对象,这样比String更强大(有很多属性和方法可以调用)
方法
实际开发中更关注的是流的操作,对File通常不会进行复杂操作,java提供了FileUtils工具类
public boolean createNewFile() 创建文件,如果存在这样的文件,就不创建了
public boolean mkdir() 创建文件夹,如果存在这样的文件夹,就不创建了
public boolean mkdirs() 创建文件夹,如果父文件夹不存在,会自动创建出来
public boolean renameTo(File dest)重命名为指定的文件路径(改名+剪切)
public boolean delete() 删除文件或者文件夹
重命名注意事项
如果路径名相同,就是改名
如果路径名不同,就是改名并剪切
删除注意事项
Java中的删除不走回收站
要删除一个文件夹,请注意该文件夹内不能包含文件或者文件夹
public boolean isDirectory() 判断是否是目录
public boolean isFile() 判断是否是文件
public boolean exists() 判断是否存在
public boolean canRead() 判断是否可读,通过setReadable(true);
public boolean canWrite() 判断是否可写,通过setWriteable(false);
public boolean isHidden() 判断是否隐藏
public String getAbsolutePath() 获取绝对路径
public String getPath() 获取路径(构造方法中传入的路径)
public String getName() 获取名称
public long length() 获取长度(字节数)
public long lastModified() 获取最后一次的修改时间(距1970的毫秒值)
public String[] list() 获取指定目录下的所有文件或者文件夹的名称数组
public File[] listFiles() 获取指定目录下的所有文件或者文件夹的File对象数组
3.FileInputStream&FileOutputStream
文件字节输入/输出流,对文件数据以字节的形式进行读写
FileInputStream
获取文件输入流
File file = new File("xxxxxxxx");
FileInputStream fileInputStream=new FileInputStream(file); //若File类对象的所代表的文件不能打开(不存在、不是文件是目录等原因),则会抛出FileNotFoundException
FileInputStream fileInputStream = new FileInputStream("C:\\Users\\Coolway26\\Desktop\\ceshi.txt"); //直接传入文件路径也可以获取文件流,底层仍然是先生成File对象,路径需要使用转义字符
方法
public int read() throws IOException //从输入流中读取一个字节的数据,返回读取的数据,是int型变量,若到达文件末尾,则返回-1
public int read(byte[] b) throws IOException //一次读取一个字节显然效率太低了,因此IO流提供了另外一种读取的方式,从输入流中一次性读取b.length个字节到字节数组b中,返回读入数组缓冲区的总字节数,若到达文件末尾,则返回-1
public int read(byte[] b, int off, int len) throws IOException
public void close() throws IOException //关闭流,释放资源
public int available() throws IOException //获取流中字节个数
read()方法返回值为什么是int,而不是byte
目的:为了准确的判断是否到了末尾(末尾是int型的-1)
因为字节输入流可以操作任意类型的文件,比如图片音频等,文件都是以二进制形式存储,如果每次读取都返回byte,有可能在读到中间的时候遇到111111111,那么这11111111是byte类型的-1,流遇到-1就认为到达文件末尾,不会再继续读取后续内容,读取的时候用int类型接收,如果11111111会在其前面补上24个0凑足4个字节,那么byte类型的-1就变成int类型的255,这样可以保证整个数据读完,而结束标记的-1就是int类型
FileOutputStream
获取文件输出流
FileOutputStream fos = new FileOutputStream(file);
FileOutputStream fos = new FileOutputStream("C:\\Users\\Coolway26\\Desktop\\ceshi.txt"); //文件如果不存在,会自动创建,文件存在会清空该文件
FileOutputStream fos = new FileOutputStream("C:\\Users\\Coolway26\\Desktop\\ceshiOut.txt", true); //追加写入,不清空文件
方法
public void write(int b) throws IOException //通过流向文件末尾写入一个字节,虽然入参是int,但实际写入时会默认去掉前面的0
public void write(byte b[]) throws IOException
public void write(byte b[], int off, int len) throws IOException
//桌面上创建一个txt文件,保存 123ceshi测试,然后操作这个文件看看效果
FileInputStream fis = new FileInputStream("C:\\Users\\Coolway26\\Desktop\\ceshi.txt");
int n=0;
StringBuffer sb = new StringBuffer();
while (n != -1) //当n不等于-1,则代表未到末尾
{
n = fis.read(); //读取文件的一个字节(8个二进制位),并将其由二进制转成十进制的整数返回
char by = (char) n; //转成字符,中文会乱码,因为中文不是单个字节存储
sb.append(by);
}
System.out.println(sb.toString());
int m=0;
byte[] b = new byte[1024];
int i = 0;
while (m != -1) //当n不等于-1,则代表未到末尾
{
m = fis.read(b); //返回实际读取到字节数组中的字节数
System.out.println(m);
System.out.println(Arrays.toString(b)); //每次读取后的字节数组内容,数组大小是初始化时侯定好的,没有读到数据的元素是默认值0
System.out.println(new String(b)); //字节数组转为String,这一次不会乱码,因为字节数组完整接收了整个中文汉字
i++;
}
fis.close(); //关流
FileOutputStream fos = new FileOutputStream("C:\\Users\\Coolway26\\Desktop\\ceshiOut.txt", true);
fos.write(99);
byte[] bytes = "这是一个测试".getBytes();
fos.write(bytes);
fos.close();
//举例:文件通过流进行复制
//方式一:一次性读取和写入,弊端:有可能会内存溢出----所以应该定义较小的数组进行流的操作
FileInputStream fis = new FileInputStream("C:\\Users\\Coolway26\\Desktop\\ceshi.txt");
FileOutputStream fos = new FileOutputStream("C:\\Users\\Coolway26\\Desktop\\ceshiOut.txt");
byte[] arr = new byte[fis.available()]; //根据文件大小做一个字节数组
fis.read(arr); //将文件上的所有字节读取到数组中,返回值是读入的有效字节个数
fos.write(arr); //将数组中的所有字节一次写到了文件上,返回值是读出的有效字节个数
fis.close();
fos.close();
//方式二:通过小数组操作,这种方式很重要,通常开发中需要生成缓存文件,或者向云服务器上传文件,会使用这种方式
FileInputStream fis = new FileInputStream("C:\\Users\\Coolway26\\Desktop\\ceshi.txt");
FileOutputStream fos = new FileOutputStream("C:\\Users\\Coolway26\\Desktop\\ceshiOut.txt");
int len;
byte[] arr = new byte[1024 * 8]; //自定义字节数组,1024的整数倍,这是标准形式
while((len = fis.read(arr)) != -1) {
//fos.write(arr);
fos.write(arr, 0, len); //写出字节数组,只写出有效个字节个数,如果不限制,即使用fos.write(arr),那么最后一次写的时候,可能会写入无效字节0,即若干个空字符
}
fis.close();
fos.close();4.BufferedInputStream&BufferedOutputStream
通过操作小数组来读写流数据,显然比一次性读取全部,或者单个字节读写,都要可靠,因为既能保证内存不溢出,又能减少磁盘IO次数提高效率
java提供了自带的缓冲流操作BufferedInputStream&BufferedOutputStream,使用缓冲流,我们将不再需要手动定义小数组
关流时,只需要关闭缓冲流
小数组的读写和带Buffered的读取哪个更好
定义小数组如果是8192个字节大小和Buffered比较的话(1024*8)(这是缓冲区的默认大小),定义小数组会略胜一筹,因为读和写操作的是同一个数组,而Buffered操作的是两个数组
BufferedInputStream
BufferedInputStream内置了一个缓冲区(数组),当使用BufferedInputStream中读取一个字节时,BufferedInputStream会一次性从文件中读取8192个, 存在缓冲区中, 返回给程序一个,程序再次读取时, 就不用找文件了, 直接从缓冲区中获取,直到缓冲区中所有的都被使用过, 才重新从文件中读取8192个
获取缓冲输入流
FileInputStream fis = new FileInputStream("C:\\Users\\Coolway26\\Desktop\\ceshi.txt");
BufferedInputStream bis = new BufferedInputStream(fis);
BufferedOutputStream
BufferedOutputStream也内置了一个缓冲区(数组),程序向流中写出字节时,不会直接写到文件,先写到缓冲区中,直到缓冲区写满,BufferedOutputStream才会把缓冲区中的数据一次性写到文件里
获取缓冲输出流
FileOutputStream fos = new FileOutputStream("C:\\Users\\Coolway26\\Desktop\\ceshiOut.txt");
BufferedOutputStream bos = new BufferedOutputStream(fos);
方法
public void flush(); //刷新此缓冲的输出流,这会使所有缓冲的输出字节被写出到底层输出流中,清空了缓冲区,可以继续写入
public void close() throws IOException //关闭缓冲流,关闭前会执行flush()操作
//拷贝文件
FileInputStream fis = new FileInputStream("C:\\Users\\Coolway26\\Desktop\\ceshi.txt");
BufferedInputStream bis = new BufferedInputStream(fis);
FileOutputStream fos = new FileOutputStream("C:\\Users\\Coolway26\\Desktop\\ceshiOut.txt");
BufferedOutputStream bos = new BufferedOutputStream(fos);
int b;
while ((b = bis.read()) != -1) {
bos.write(b);
}
bis.close();
bos.close();
//当然,也可以一次性读入多个字节到缓冲流,通常也是这么做的
int len;
byte[] arr = new byte[1024*8];
while ((len = bis.read(arr)) != -1) {
bos.write(arr, 0, len);
}
bis.close();
bos.close();5.MultipartFile(springmvc会用到)
WEB接口中接收文件,springmvc提供的简化文件流操作的接口
//如果不使用MultipartFile
public String fileSave(HttpServletRequest request, HttpServletResponse response){
MultipartHttpServletRequest msr = (MultipartHttpServletRequest) request;
MultipartFile targetFile = msr.getFile("file");
}
//使用MultipartFile直接接收文件
public String fileSave(MultipartFile file){
...
}
//方法
public interface MultipartFile extends InputStreamSource {
//返回参数的名称
String getName();
// 获取源文件的名称
@Nullable
String getOriginalFilename();
// 返回文件的内容类型
@Nullable
String getContentType();
// 判断文件内容是否为空
boolean isEmpty();
// 返回文件大小 以字节为单位
long getSize();
// 将文件内容转化成一个byte[] 返回
byte[] getBytes() throws IOException;
// 返回输入的文件流
InputStream getInputStream() throws IOException;
default Resource getResource() {
return new MultipartFileResource(this);
}
void transferTo(File var1) throws IOException, IllegalStateException;
// 将MultipartFile 转换换成 File 写入到指定路径
default void transferTo(Path dest) throws IOException, IllegalStateException {
FileCopyUtils.copy(this.getInputStream(), Files.newOutputStream(dest));
}
}
//其他
//获取文件名
MultipartFile file = new MultipartFile();
String fileName = file.getOriginalFilename().substring(0,file.getOriginalFilename().lastIndexOf("."))
//获取文件后缀:这个后缀带‘.’如:.zip,如果不想带‘.’这样即可lastIndexOf(".")+1
MultipartFile file = new MultipartFile();
String fileSuffix = file.getOriginalFilename().substring(file.getOriginalFilename().lastIndexOf("."))
6.零拷贝(拓展了解,可以不掌握)
传统IO:一共需要拷贝四次,两次CPU拷贝,两次DMA拷贝
read():把数据从磁盘读到内核缓冲区,从内核缓冲区再拷贝到用户缓冲区
write():把数据写入socket缓冲区,最后写入网卡设备
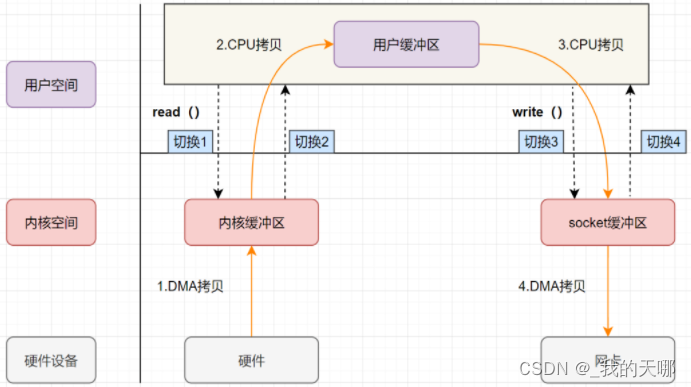
零拷贝:进行数据IO时,数据在用户态下经历了零次CPU拷贝
缺点:零拷贝有一个缺点,不允许进程对文件内容作一些加工再发送,比如数据压缩后再发送
#mmap+write
try {
FileChannel readChannel = FileChannel.open(Paths.get("./jay.txt"), StandardOpenOption.READ);
MappedByteBuffer data = readChannel.map(FileChannel.MapMode.READ_ONLY, 0, 1024 * 1024 * 40);
FileChannel writeChannel = FileChannel.open(Paths.get("./siting.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE);
//数据传输
writeChannel.write(data);
readChannel.close();
writeChannel.close();
}catch (Exception e){
System.out.println(e.getMessage());
}
#sendfile
try {
FileChannel readChannel = FileChannel.open(Paths.get("./jay.txt"), StandardOpenOption.READ);
long len = readChannel.size();
long position = readChannel.position();
FileChannel writeChannel = FileChannel.open(Paths.get("./siting.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE);
//数据传输
readChannel.transferTo(position, len, writeChannel);
readChannel.close();
writeChannel.close();
} catch (Exception e) {
System.out.println(e.getMessage());
}
}