
🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据预处理
4.3词云图可视化
4.4为LDA模型训练准备数据
4.5确定主题个数K
4.6LDA模型训练
4.7主题建模可视化
5.总结
文末推荐与福利
1.项目背景
《老友记》是一部备受欢迎的美国情景喜剧,由David Crane和Marta Kauffman创作,于1994年至2004年间播放。该剧讲述了六位年轻人在纽约的生活,以及他们之间的友谊、爱情和生活经历。由于其风趣、幽默的对白和真实的情感描绘,《老友记》在全球范围内赢得了大量观众。
LDA(Latent Dirichlet Allocation)主题分析是一种文本挖掘和机器学习技术,旨在从大量文本数据中发现主题结构。该方法假设每个文档都是由多个主题组成,而每个主题又由一组单词表示。LDA的应用领域包括信息检索、社交媒体分析、新闻主题挖掘等。
研究者们对《老友记》进行主题分析的兴趣可能源自以下几个方面:
-
剧情深度分析: 通过LDA主题分析,《老友记》的剧本可以被分解为不同的主题,揭示剧情的深度和多样性。这有助于理解故事情节的发展、人物关系的演变以及情景喜剧的幽默元素。
-
观众反馈分析: 通过分析观众对《老友记》的评论、讨论和反馈,可以了解哪些主题引起了观众的关注和讨论。这有助于制片人和编剧更好地了解观众的反应,从而指导后续剧集的制作方向。
-
文本挖掘技术应用: 将LDA等文本挖掘技术应用于影视剧本分析,可以为电视剧的创作和改进提供新的方法。这种方法也可以在其他文本数据集上得到推广应用,拓展到更广泛的娱乐产业或文本分析领域。
-
文化研究角度: 通过主题分析,研究者可以深入挖掘《老友记》所反映的文化元素、社会现象和时代特征。这有助于理解该剧在文化中的地位以及对观众产生的影响。
在本研究中,利用LDA主题分析技术对《老友记》情景喜剧的剧本进行建模,旨在深入挖掘该剧的主题结构,揭示其故事内涵和文本特征。这样的分析有望为电视剧创作、文本挖掘技术的应用以及文化研究领域提供有益的见解。
2.数据集介绍
本数据集来源于kaggle,《老友记》是一部美国情景喜剧,由大卫·克兰和玛尔塔·考夫曼创作,于1994年9月22日至2004年5月6日在美国全国广播公司播出,共十季。这部剧由詹妮弗·安妮斯顿、柯特妮·考克斯、丽莎·库卓、马特·勒布朗、马修·佩里和大卫·修默主演,围绕着六个住在纽约曼哈顿的二三十岁的朋友展开。该系列由Bright/Kauffman/Crane Productions与华纳兄弟电视公司联合制作。最初的执行制片人是凯文·s·布莱特、考夫曼和克兰。原始数据集共有67373条,6个特征变量,各变量含义如下:
text:对话作为文本
speaker:演讲者的名字
season:季节号
episode:第1集
scene:场景编号
utterance:话语数
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
import pandas as pd
friends_data = pd.read_csv('friends.csv')
friends_data.head()
4.2数据预处理
# 导入库、类和数据集
import re
import nltk
from gensim.parsing.preprocessing import STOPWORDS
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer, WordNetLemmatizer
nltk.download('stopwords')
nltk.download('punkt')
nltk.download('wordnet')
为了消除对话中的冗余词,我使用了Gensim库提供的STOPWORDS数据集,其中包含337个最常用的停止词的汇编。
# 检查gensim中的停用词列表
print(STOPWORDS)
print(len(STOPWORDS))
为了只关注角色之间的对话文本,我首先删除了不必要的列。
# 删除未使用的列
friends_data = friends_data.drop(columns=['scene','utterance'], axis=1)
friends_data.head()
随后,我进行了预处理阶段,去掉了标点符号和停顿词。在此之后,我将所有单词转换为小写,然后对文本进行标记、词干提取和依序排列。
# 初始化Porter词干分析器和WordNet词形化器
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
# Gensim停用词
gensim_stop_words = set(stopwords.words('english'))
# 删除标点符号、停止词、转换为小写、标记化、词干和引体化
def preprocess_text(text):
cleaned_text = re.sub(r'[^\w\s]', '', text) # 从文本中删除所有非单词和非空白字符
stop_words = set(gensim_stop_words)
words = word_tokenize(cleaned_text.lower())
filtered_words = [word for word in words if word not in stop_words and len(word) >= 4] # 删除少于4个字符的单词
stemmed_words = [stemmer.stem(word) for word in filtered_words]
lemmatized_words = [lemmatizer.lemmatize(word) for word in stemmed_words]
return lemmatized_words
# 对“text”列应用预处理
friends_data['processed_text'] = friends_data['text'].apply(preprocess_text)
friends_data.head()
4.3词云图可视化
在完成文本预处理后,我创建了最初的可视化来探索《老友记》角色之间的对话主题。我使用了WordCloud库生成的词云。这个工具根据单词的频率自动缩放单词的大小,突出显示流行的单词,同时减少不常见的单词的大小。
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 为特定说话人生成词云的函数
def generate_wordcloud_for_speaker(speaker_name, text_data):
# 组合特定说话者的所有文本数据,并将令牌连接到单个字符串中
speaker_text = ' '.join(' '.join(tokens) for tokens in text_data[text_data['speaker'] == speaker_name]['processed_text'])
# 创建WordCloud对象
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(speaker_text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title(f'WordCloud for Speaker: {speaker_name}')
plt.show()
# 要可视化的具体演讲者列表
speakers_to_visualize = ["Monica Geller", "Joey Tribbiani", "Chandler Bing", "Phoebe Buffay", "Ross Geller", "Rachel Green"]
# 为每个角色绘制词云
for speaker_name in speakers_to_visualize:
generate_wordcloud_for_speaker(speaker_name, friends_data)
词云提供了每个人物最常用的词的视觉表示,其中较大的词在他们的对话中表示更高的频率和重要性。正如我们从可视化中看到的那样,他们在日常对话中主要谈论彼此和其他随意的话题,就像大多数朋友群一样!
4.4为LDA模型训练准备数据
在下一节中,我的目标是使用LDA模型训练来更深入地研究和探索角色所从事的典型主题。
from gensim.corpora import Dictionary
from gensim.models import LdaModel
from pprint import pprint
import numpy as np
# 创建字典和语料库
# 从标记化的文本数据创建字典
id2word = Dictionary(friends_data['processed_text'])
# 文件频率
corpus = [id2word.doc2bow(tokens) for tokens in friends_data['processed_text']]
4.5确定主题个数K
使用网格搜索找到最佳数量的主题
为了有效地训练LDA模型,需要预定义数量的主题。为了确定主题的最佳数量,我在一个范围内(从3到最多30个主题)进行了网格搜索。在每次迭代中生成的模型将使用一致性评分进行评估。这种方法旨在确定产生最有意义结果的主题数量。
from gensim.models.coherencemodel import CoherenceModel
# 指定要在其中搜索的主题数量范围
min_topics = 3
max_topics = 30
step_size = 5
topics_range = range(min_topics, max_topics+1, step_size)
# 执行网格搜索并计算不同数量主题的一致性分数
coherence_scores = []
for num_topics in topics_range:
lda_model = LdaModel(corpus=corpus, id2word=id2word, num_topics=num_topics)
coherence_model_lda = CoherenceModel(model=lda_model, texts=friends_data['processed_text'], dictionary=id2word, coherence='c_v')
coherence_lda = coherence_model_lda.get_coherence()
coherence_scores.append(coherence_lda)
# 找出具有最高连贯分数的最佳主题数量
optimal_num_topics = topics_range[np.argmax(coherence_scores)]
print("Optimal Number of Topics:", optimal_num_topics)
print("Coherence Score for Optimal Number of Topics:", max(coherence_scores))
# 绘制主题数与连贯分数之间的关系
plt.figure(figsize=(10, 6))
plt.plot(topics_range, coherence_scores, marker='o', color='b', label='Coherence Score')
plt.xlabel('Number of Topics')
plt.ylabel('Coherence Score')
plt.title('Number of Topics vs Coherence Score')
plt.xticks(topics_range)
plt.legend()
plt.grid(True)
plt.show()

print(coherence_scores)
print(optimal_num_topics)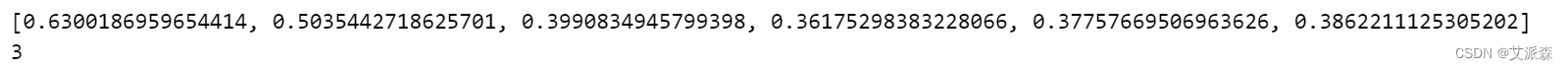
4.6LDA模型训练
在进行网格搜索分析之后,很明显,我们的数据集的最佳主题数量被确定为3。这个特定数量的话题产生了最高的连贯分数,表明对话中的话题更好地对齐。随后,我利用这个最优值作为训练LDA模型的输入参数,以确保对Friends对话中呈现的潜在主题进行集中而深刻的探索。
# LDA模型的主题数
num_topics = 3
# 构建LDA模型
lda_model = LdaModel(corpus=corpus, id2word=id2word, num_topics=num_topics)
# 打印主题
pprint(lda_model.print_topics())
用连贯性评分评价LDA模型
在前面的步骤中,我确定了主题的最佳数量,我利用一致性分数来评估LDA模型。但是,让我们在本节中更详细地探讨这个分数。
主题一致性指标通过评估该主题中排名较高的单词之间的语义相似性来评估单个主题。Gensim库提供了一个类,实现了四个最著名的相干模型:u_mass, c_v, c_uci, c_npmi。
在《老友记》的数据集中,文本由剧中角色之间的日常对话组成。由于这种简单直接的语言,不需要复杂的模型来评估主题一致性。在LDA分析中,我选择了c_v相干模型。它具体评估词的共现性和主题的独特性。考虑到随意对话的性质,这种方法为我们的数据集提供了充分和合适的评估。
# 计算连贯分数
coherence_model = CoherenceModel(model=lda_model, texts=friends_data['processed_text'], dictionary=id2word, coherence='c_v')
coherence_score = coherence_model.get_coherence()
# 打印结果
print(f'Coherence Score: {coherence_score}')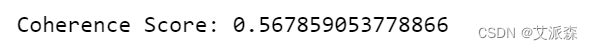
考虑到c_v连贯分数的范围为0 ~ 1,当c_v连贯分数为0.567时,表明从《老友记》数据集中提取的主题具有合理的可解释性和连贯性。
4.7主题建模可视化
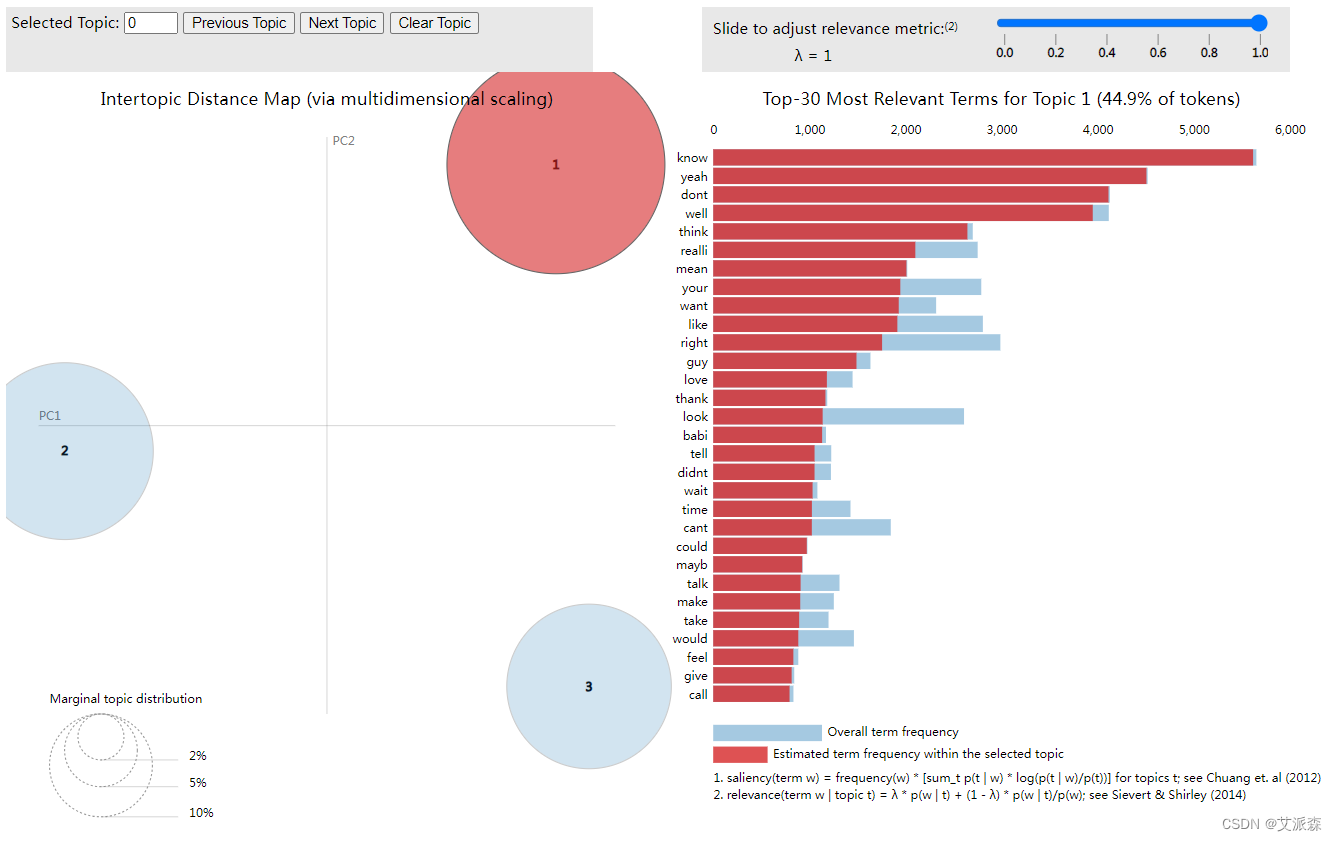
利用Python中的pyLDAvis交互式可视化库,我为前面在“Friends”数据集中发现的3个主题生成了交互式可视化。这些可视化已保存为HTML文件。您可以在web浏览器中手动打开HTML文件以与可视化交互。
import pyLDAvis.gensim
import pickle
import pyLDAvis
import os
# 如果'results'目录不存在,创建它
os.makedirs('results', exist_ok=True)
# 准备LDA可视化数据
LDAvis_data_filepath = './results/ldavis_prepared_' + str(num_topics) + '.pkl'
# 如果您还没有准备可视化数据,请创建它
if 1 == 1:
LDAvis_prepared = pyLDAvis.gensim.prepare(lda_model, corpus, id2word)
with open(LDAvis_data_filepath, 'wb') as f:
pickle.dump(LDAvis_prepared, f)
# 将交互式可视化保存为HTML文件
pyLDAvis.save_html(LDAvis_prepared, './results/ldavis_prepared_' + str(num_topics) + '.html')
# 打印一条消息,指出HTML文件的保存位置
print(f"Interactive LDA visualization saved as 'ldavis_prepared_{num_topics}.html'")
5.总结
通过对《老友记》情景喜剧剧本的LDA主题分析,我们获得了深刻的洞见,有助于更全面地理解这部经典电视剧。以下是该实验的主要总结:
-
主题结构的发现: LDA分析揭示了《老友记》剧本中存在的多个主题,每个主题都由一组相关的单词组成。这有助于理解剧情的多样性和复杂性,以及编剧如何巧妙地将不同元素融合在一起。
-
情节和人物关系的解读: 通过主题分析,我们能够深入了解不同主题与剧情发展、人物关系之间的关联。这种解读有助于揭示故事的深度,理解人物之间的互动以及主题如何随着剧情的发展而演变。
-
观众关注点的识别: 分析观众评论和反馈中与不同主题相关的关键词,我们可以识别观众在剧集中关注的重点。这对于制片人和编剧来说是宝贵的信息,可以指导后续剧集的制作和改进。
-
文本挖掘技术的应用: 该实验展示了如何成功地将LDA主题分析技术应用于电视剧剧本,为文本挖掘技术在影视产业中的应用提供了示范。这种方法不仅适用于《老友记》,还可以推广到其他电视剧或文本数据集中。
-
文化研究和社会反映: 主题分析不仅有助于理解剧本本身,还能够揭示剧集对当时文化和社会现象的反映。这对于文化研究者和社会学者来说是一种有趣的途径,可以深入挖掘电视剧在特定时期的影响和意义。
总体而言,通过LDA主题分析,《老友记》的剧本不再只是一系列对话和情节,而是一个丰富的主题网络,其中蕴含着深层次的故事、情感和文化元素。这种分析方法为电视剧的创作、观众互动和文本挖掘技术的应用提供了新的视角和方法。
文末推荐与福利
《计算机考研精炼1000题》免费包邮送出3本!

编辑推荐
【练学结合,助力强化】
结合最新408考纲,按章节精炼梳理重要知识点,帮助强化冲刺的计算机考生迅速回顾复盘考点。按历年真题考查频次、风格、题型分配精选习题,强化冲刺阶段时间紧、任务重,题目不在多而在精。紧跟答案详解,刷题不是目的,总结复盘提分才是终极要义。练、学结合,超详细的答案解析、多种解题思路,让你刷一题吃透一题,直至举一反三。
【难度适中,但不刁钻】
1000题包括选择题和大题。
题目不简单,基础没打好,强化没成效,刷不来这些题,1000题有难度。
题目不刁钻,考查的都是经典角度,想拿高分必须掌握,不是冷门考法。
【题目新颖,独具匠心】
计算机考研人到强化冲刺阶段,有一个痛点——想找好题刷,却没得刷。各类计算机考研教辅资料,题目冗余、陈旧,题目多年不变;真题不够刷,更不敢轻易草率刷。鉴于此,《计算机考研精炼1000题》结合历年真题风格特点,原创70%以上的新编习题,确保题目既符合真题风格又具有新意。
【考题预测,提前准备】
所有教辅,必以提分应试为要义。本书在出题时也以押题为目标,基于历年真题的全方位分析,预测24考研的真题。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-11-15 20:00:00
京东购买链接:https://item.m.jd.com/product/13919097.html
名单公布时间:2023-11-15 21:00:00
免费资料获取,更多粉丝福利,关注下方公众号获取








![[云原生案例2.4 ] Kubernetes的部署安装 【通过Kubeadm部署Kubernetes高可用集群】](https://img-blog.csdnimg.cn/c908fa84bd364dc6a178e534533c8c9b.png)

![[html] 动态炫彩渐变背景](https://img-blog.csdnimg.cn/b4f4c7a437cd45c7af5a85db30f4d8d7.png)
![[量化投资-学习笔记012]Python+TDengine从零开始搭建量化分析平台-策略回测](https://img-blog.csdnimg.cn/8dd2acabe5064d6a9cd1309e16a05697.png#pic_center)



