文章目录
- 索引实现
- 索引存储
- B+树
- 为什么 MySQL InnoDB 选择 B+ 树作为索引的数据结构?
- B+ 树层高问题
- 关于自增id
- 最左匹配原则
- 覆盖索引
- 索引下推
- innodb体系结构
- Buffer pool
- change buffer
- 总结
索引实现
索引存储
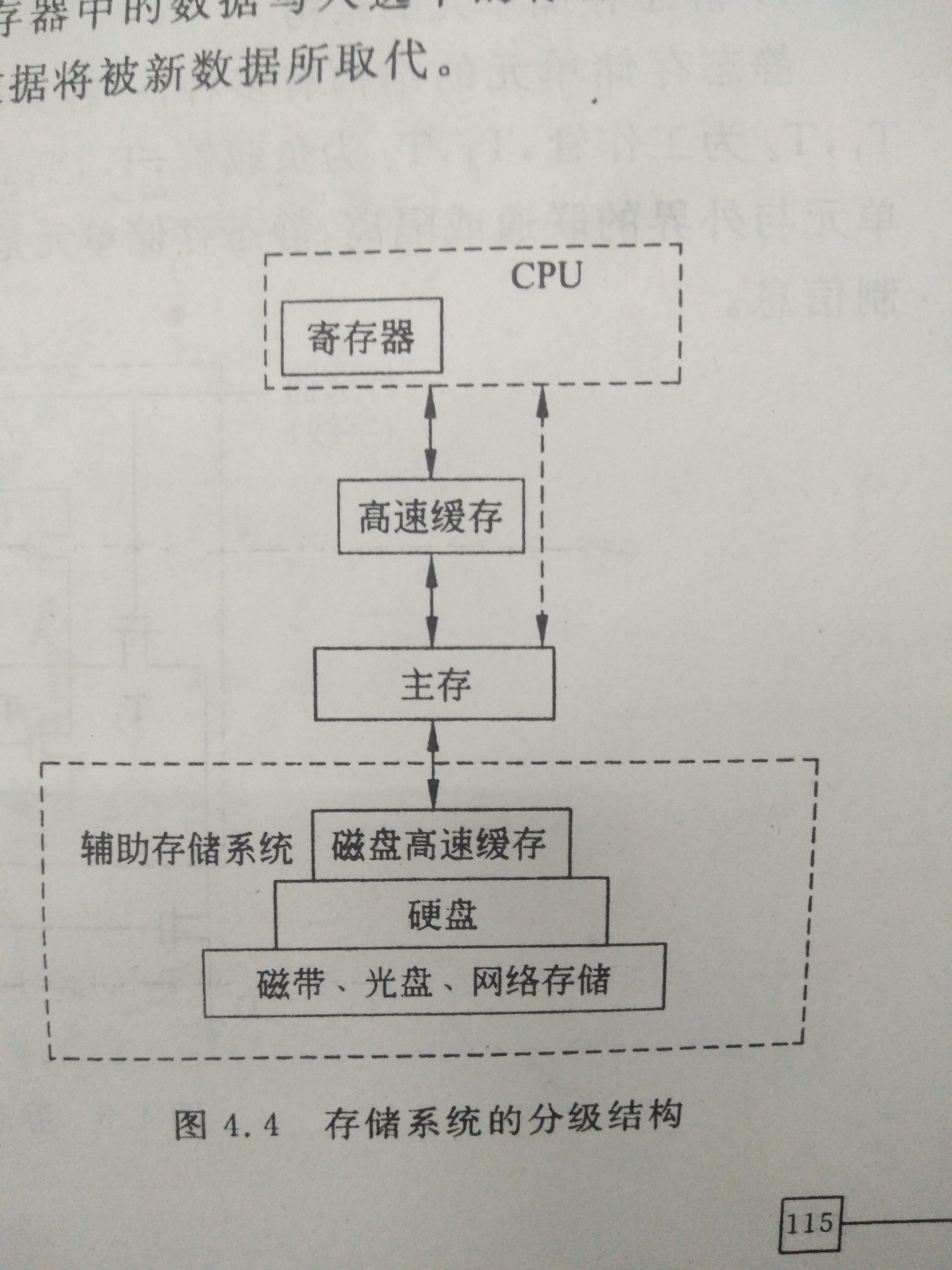
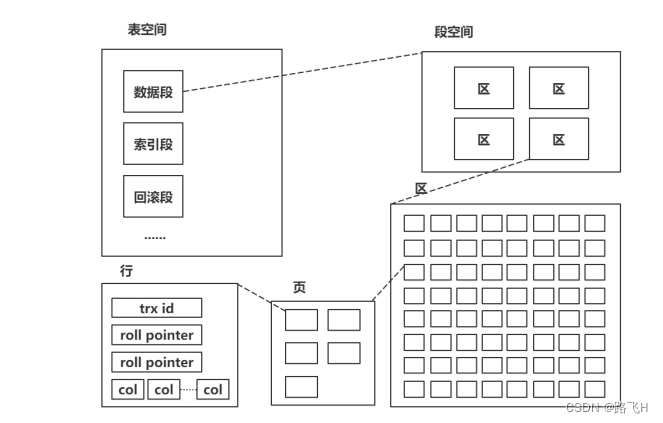
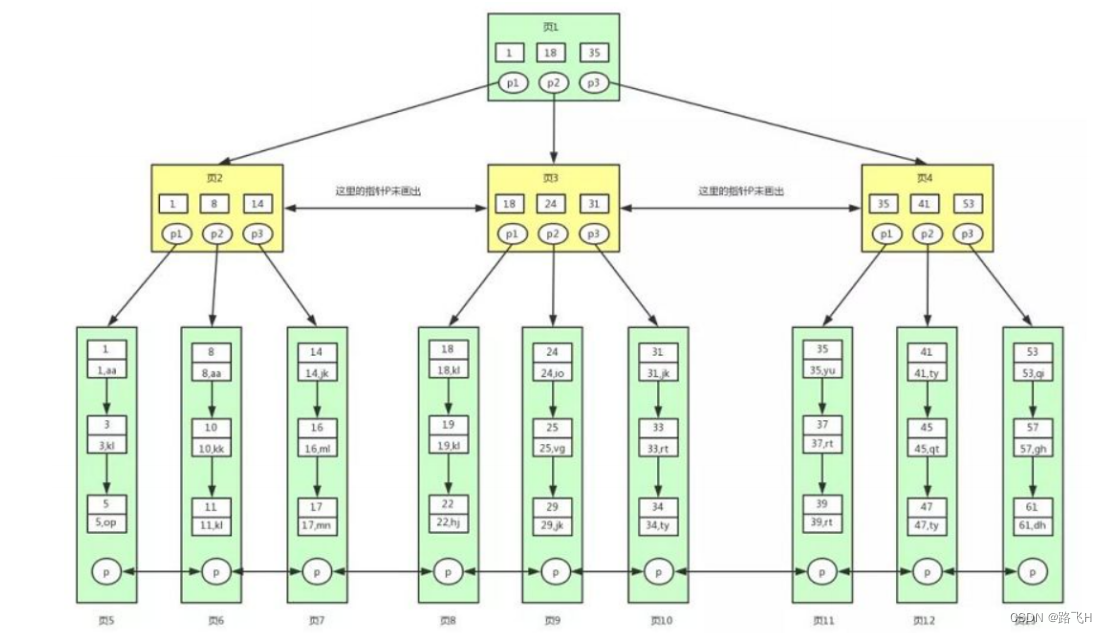
innodb 由段、区、页组成。段分为数据段、索引段、回滚段等。
区大小为 1 MB(一个区由 64 个连续页构成)。页的默认值为 16KB。页为逻辑页,磁盘物理页大小一般为 4K 或者 8K。
为了保证区中的页的连续,存储引擎一般一次从磁盘中申请4~5 个区。
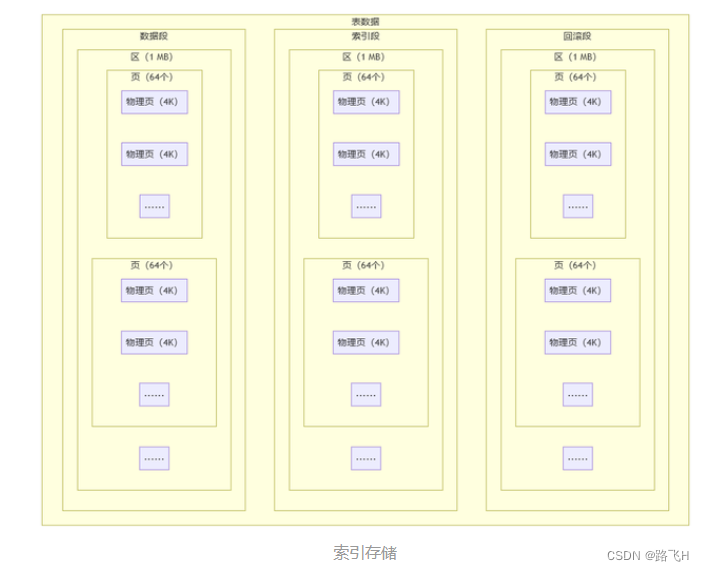
页是 innodb 磁盘管理的最小单位;默认16K,可通过innodb_page_size 参数来修改。B+ 树的一个节点的大小就是该页的值。
B+树
B+树全称:多路平衡搜索树,是为了减少磁盘访问次数。用来组织磁盘数据,以页为单位,物理磁盘页一般为 4K,innodb 默认页大小为16K;对页的访问是一次磁盘 IO,缓存中会缓存常访问的页。
innodb中的B+树的特征:
(1)多路平衡搜索树。
(2)所有的叶子节点都在同一层。
(3)并且叶子节点构成一个双向链表。
(4)节点的大小是固定的,都为数据页大小(16K)。
(5)非叶子节点只记录索引信息,叶子节点记录数据信息。
为什么 MySQL InnoDB 选择 B+ 树作为索引的数据结构?
∘ \circ ∘ 降低磁盘IO:B+树的非叶节点只包含键,而不包含真实数据,因此每个节点可以存储更多的记录个数。所以B+树的高度更低,访问时所需要的IO次数更少。此外,由于每个节点存储的记录数更多,所以对访问局部性原理的利用更好,缓存命中率更高。相比之下,红黑树在磁盘上的存储方式相对随机,导致磁盘 I/O 操作更频繁。哈希表则不适合直接存储在磁盘上,因为哈希表需要通过哈希函数计算位置,无法充分利用磁盘的顺序读写特性。
∘ \circ ∘ 范围查询:B+树的叶子节点间构成一个双向链表,范围查询只需要对链表进行遍历即可。相比之下,红黑树和哈希表无法提供高效的范围查询支持。红黑树虽然能够支持有序访问,但在范围查询时需要遍历整个树,性能较差。而哈希表是基于哈希函数进行快速查找的,适用于单个键值查询,但对于范围查询则需要扫描整个表格,效率较低。
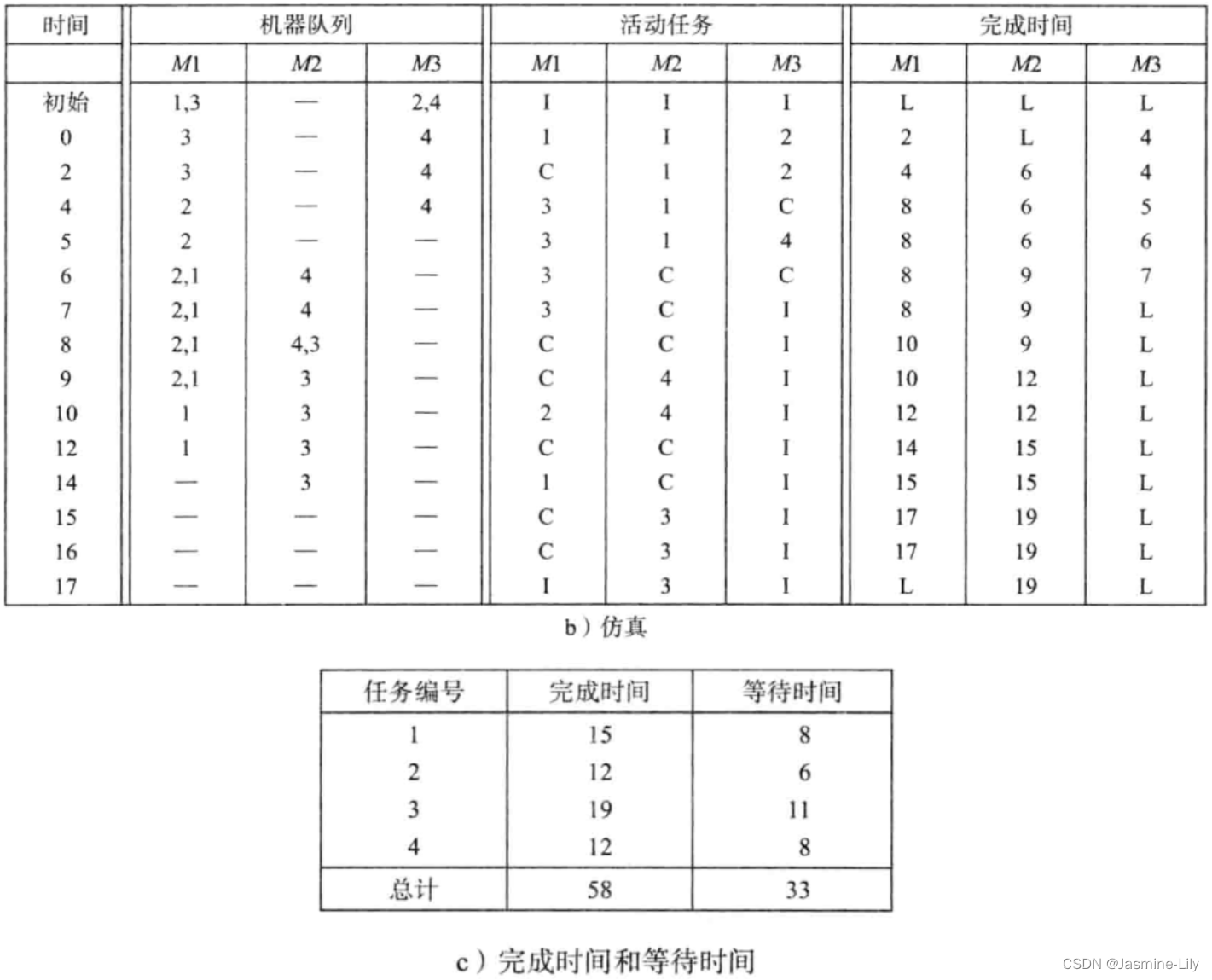
B+ 树层高问题
B+ 树的一个节点对应一个数据页;B+ 树的层越高,那么要读取到内存的数据页越多,IO 次数越多;
innodb 一个节点 16KB;
假设:
key 为 10byte 且指针大小 6byte,假设一行记录的大小为1KB;那么一个非叶子节点可存下 16 KB / 16 byte=1024 个
(key+point);每个叶子节点可存储 1024 行数据;
结论:
2层B+树叶子节点1024个,可容纳最大记录数为: 1024 * 16 = 16384;
3层B+树叶子节点1024 * 1024,可容纳最大记录数为:1024 * 1024 * 16 = 16777216;
4层B+数叶子节点1024 * 1024 * 1024,可容纳最大记录数为:1024 * 1024 * 1024 * 16 = 17179869184;
关于自增id
超过类型最大值会报错;
类型 bigint 范围: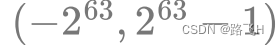
假设采用 bigint,1 秒插入 1 亿条数据,大概需要 5849 年才会用完索引;
最左匹配原则
主要针对组合索引。从左到右依次匹配,遇到模糊匹配(>、<、between、like等)时就停止匹配;如果没有第一个索引也停止匹配。
示例:
DROP TABLE IF EXISTS `left_match_t`;
CREATE TABLE `left_match_t` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) DEFAULT NULL,
`cid` INT(11) DEFAULT NULL,
`age` SMALLINT DEFAULT 0,
PRIMARY KEY (`id`),
KEY `name_cid_idx` (`name`, `cid`)
)ENGINE = INNODB AUTO_INCREMENT=0 DEFAULT CHARSET = utf8;
INSERT INTO `left_match_t` (`name`, `cid`, `age`)
VALUES
('FLY', 10001, 12),
('fly', 10002, 13),
('cc', 10003, 14),
('ff', 10004, 15)
SHOW INDEX FROM `left_match_t`;
# 作用优化器
EXPLAIN SELECT * FROM `left_match_t` WHERE `name` = 'mark';
# 优化器
EXPLAIN SELECT * FROM `left_match_t` WHERE `cid` = 1 AND `name` = 'mark';
# 不会走索引
EXPLAIN SELECT * FROM `left_match_t` WHERE `cid` = 1;
覆盖索引
覆盖索引是一种数据查询方式,主要针对辅助索引。从辅助索引中就能找到数据,而不需通过聚集索引查找;利用辅助索引树高度一般低于聚集索引树, 可以较少的磁盘 IO。
也就是,如果查询的字段是辅助索引,那么查询过程中就不需要回表查询,直接使用辅助索引B+树就可以查询到数据。
示例:
DROP TABLE IF EXISTS `covering_index_t`;
CREATE TABLE `covering_index_t` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) DEFAULT NULL,
`cid` INT(11) DEFAULT NULL,
`age` SMALLINT DEFAULT 0,
`score` SMALLINT DEFAULT 0,
PRIMARY KEY (`id`),
KEY `name_cid_idx` (`name`, `cid`)
)ENGINE = INNODB AUTO_INCREMENT=0 DEFAULT CHARSET = utf8;
INSERT INTO `covering_index_t` (`name`, `cid`, `age`, `score`)
VALUES
('FLY', 10001, 12, 99),
('fly', 10002, 13, 98),
('cc', 10003, 14, 97),
('ff', 10004, 15, 100);
SHOW INDEX FROM `covering_index_t`;
-- 需要回表查询
SELECT * FROM `covering_index_t` WHERE `name` = 'FLY';
-- 查询字段是辅助索引(`name`, `cid`, `id`),不需要回表查询
SELECT `name`, `cid`, `id` FROM `covering_index_t` WHERE `name` = 'FLY';
总结:
在使用中,尽量不要使用select * …来获取数据;因为里面有些字段可能没有创建索引,没有创建索引就需要回表查询,这会增加磁盘IO。所以,在select中尽量写所需的字段。
索引下推
具体原理查看mysql索引下推。
innodb体系结构
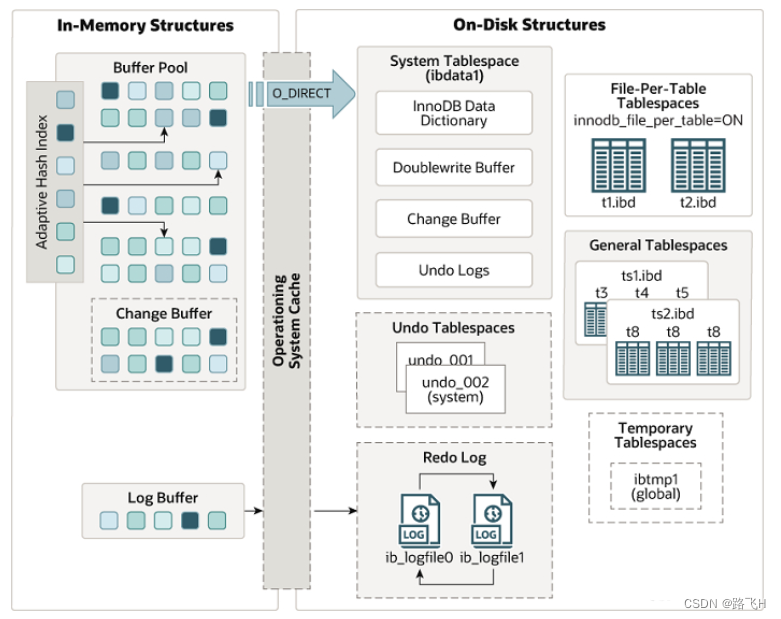
Buffer pool
Buffer Pool是一个用于存储数据和索引页的内存区域,它以固定大小的页为单位进行管理,通常以16KB为一页。它的作用是采用 LRU 算法将最常用的数据页(热点数据)保留在内存中,以减少对磁盘IO的需求。当数据被查询或更新时,首先通过自适应hash索引查询数据是否在buffer pool中;如果数据不在,则通过mmap将磁盘数据映射到buffer pool中;如果数据存在buffer pool中就直接操作。
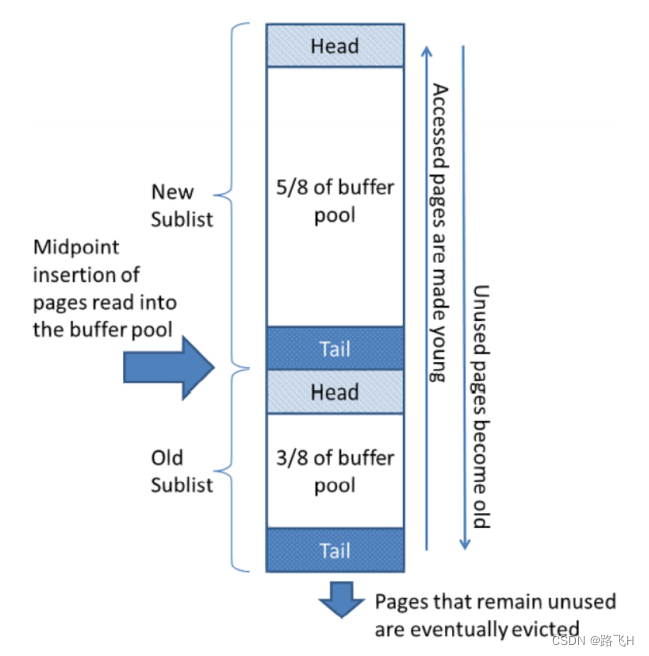
buffer pool 用于缓存若干数据页,降低磁盘IO次数。
change buffer
Change buffer 缓存非唯一索引的数据变更(DML操作),Change buffer 中的数据将会异步merge 到磁盘当中。当执行更新操作(如插入、更新、删除)时,InnoDB会将修改的数据页(包括数据和索引页)首先写入到Change Buffer中,而不是直接写入磁盘。Change Buffer是一个内存中的缓冲区,用于暂时存储待写入的修改操作。
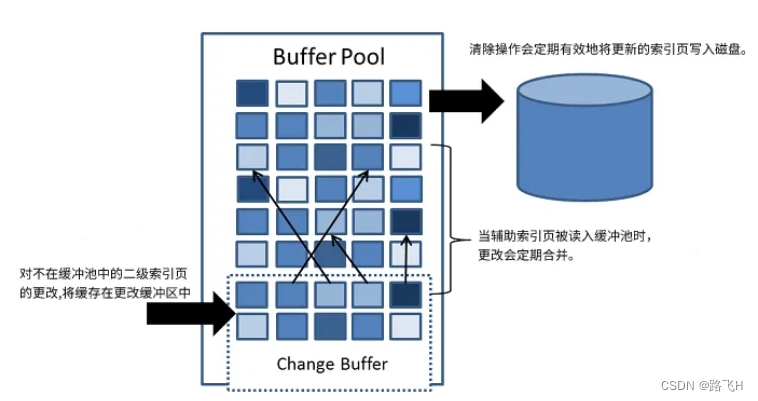
change buffer目的是将DML数据合并到buffer pool。
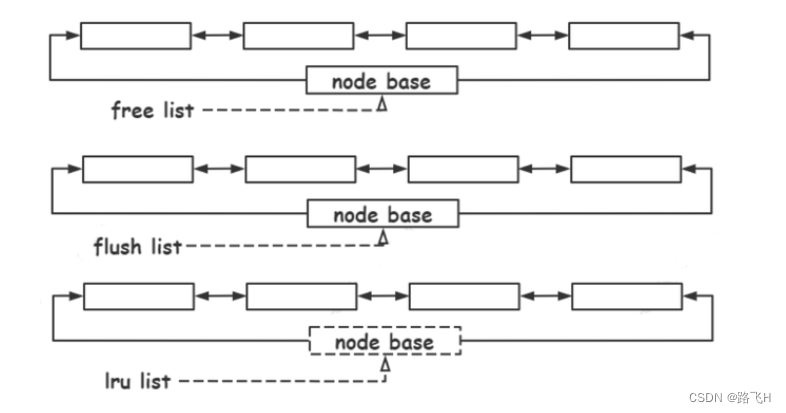
(1)free list 组织 buffer pool 中未使用的缓存页;
(2)flush list 组织buffer pool 中脏页,也就是待刷盘的页;
(3)lru list 组织 bufferpool 中冷热数据,当 buffer pool 没有空闲页,将从 lru list 中最久未使用的数据进行淘汰。
总结
- 一定要确定一个主键索引的原因是:主键索引对应的是聚集索引B+树,所有的数据要存储在主键对应的B+树中。
- innodb中的B+树 非叶子节点只存储索引信息,叶子节点存储具体数据信息;叶子节点之间互相连接,方便范围查询。每个索引对应一个B+树。
- MySQL的索引实现使用B+树而不是使用其他树的原因是降低磁盘IO以及方便范围查询。
- 覆盖索引是一种数据查询方式,主要针对辅助索引;直接通过辅助索引B+树就能获取查询的值,而无需通过回表查询。
- 根据覆盖索引的原理,在select中尽量写所需要的字段,不要写select * … 。
- 没有索引下推机制时,server层向存储引擎层请求数据,在server层根据索引条件判断进行数据过滤。有了索引下推机制,将索引条件下推到存储引擎中过滤数据,最终由存储引擎进行数据汇总返回给server层。
- B+树的页是通过mmap映射到磁盘的数据块,以此来组织数据。
- MySQL通过自适应hash索引快速判断某个页是否在缓存中(buffer pool)。
- MySQL中的explain用于制作执行计划,作用在优化器阶段。
- 工作中不要使用age字段,而是使用生日(年月日)。(因为年龄是经常变化的字段,而生日不会变)