文章目录
- 概要
- 版本:
- 参考资料
- STM32CUBEAI安装
- CUBEAI模型支持
- LSTM模型转换注意事项
- 模型转换
- 模型应用
- 1 错误类型及代码
- 2 模型创建和初始化
- 3 获取输入输出数据变量
- 4 获取模型前馈输出
- 模型应用小结
- 小结
概要
STM32 CUBE MX扩展包:X-CUBE-AI部署流程:模型转换、CUBEAI模型验证、CUBEAI模型应用。
深度学习架构使用Pytorch模型,模型包括多个LSTM和全连接层(包含Dropout和激活函数层)。
版本:
STM32CUBEMX:6.8.1
X-CUBE-AI:8.1.0 (推荐该版本,对LSTM支持得到更新)
ONNX:1.14.0
参考资料
遇到ERROR和BUG可到ST社区提问:ST社区
CUBEAI入门指南下载地址:X-CUBE-AI入门指南手册
官方应用示例:部署示例
STM32CUBEAI安装
CUBEAI扩展包的安装目前已有许多教程,这里不再赘述。CUBEAI安装
需要注意的是,在STM32CUBEMX上安装CUBEAI时,可能并不能安装到最新版本的CUBEAI,因此可以前往ST官网下载最新版本(最新版本会对模型实现进行更新)。https://www.st.com/zh/embedded-software/x-cube-ai.html

CUBEAI模型支持
目前,CUBEAI支持三种类型的模型:
- Keras:.h5
- TensorFlow:.tflite
- 一切可以转换成ONNX格式的模型:.onnx
Pytorch部署CUBEAI需要将Pytorch生成模型.pth转换成.onnx。
LSTM模型转换注意事项
- 由于CUBEAI扩展包和ONNX对LSTM的转换限制,在Pytorch模型搭建时,需要设置LSTM的
batch_first=False(并不影响模型训练和应用),设置后,需要注意输入输出数据的格式。 - LSTM模型内部全连接层的输入前,将数据切片,取最后时间步,可避免一些问题。
- 对于多LSTM,可以采取
forward函数多输入x的形式,每一个x是一个LSTM的输入。
模型转换
-
Pytorch->Onnx
使用torch.onnx.export()函数,其中可动态设置变量,函数使用已有很多教程,暂不赘述。Pytorch转ONNX及验证
由于部署后属于模型应用阶段,输入数据batch=1,seq_length和input_num可自行设置,也可设置动态参数(设置seq_length为动态参数后,CUBEMX验证的示例数据中的seq_length=1)。 -
Onnx->STM32
大致流程可参考: STM32 模型验证
STM32CUBEMX中选中相应模型即可,可修改模型名称方便后续网络部署(不要使用默认network名字)。
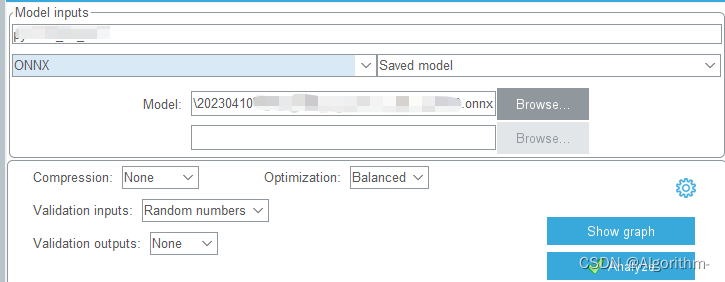
验证阶段可能会发生多种问题,问题错误种类参见:

模型应用
到目前为止,Pytorch模型已经成功转换成ONNX并在CUBEMX进行了验证且得到通过,下面则是STM32的模型应用部分。
通过keil打开项目后,在下面的目录下存放模型相关文件,主要用到的函数为:modelName.c、modelName.h,其中modelName为在CUBEMX中定义的模型名称。

主要使用的函数如下:
ai_modelName_create_and_init:用于模型创建和初始化ai_modelName_inputs_get:用于获取模型输入数据ai_modelName_outputs_get:用于获取模型输出数据ai_pytorch_ftc_lstm_run:用于前馈运行模型得到输出ai_mnetwork_get_error:用于获取模型错误代码,调试用
各函数相关参数及用法如下。
相似代码可参见:X-CUBE-AI入门指南手册
1 错误类型及代码
/*!
* @enum ai_error_type
* @ingroup ai_platform
*
* Generic enum to list network error types.
*/
typedef enum {
AI_ERROR_NONE = 0x00, /*!< No error */
AI_ERROR_TOOL_PLATFORM_API_MISMATCH = 0x01,
AI_ERROR_TYPES_MISMATCH = 0x02,
AI_ERROR_INVALID_HANDLE = 0x10,
AI_ERROR_INVALID_STATE = 0x11,
AI_ERROR_INVALID_INPUT = 0x12,
AI_ERROR_INVALID_OUTPUT = 0x13,
AI_ERROR_INVALID_PARAM = 0x14,
AI_ERROR_INVALID_SIGNATURE = 0x15,
AI_ERROR_INVALID_SIZE = 0x16,
AI_ERROR_INVALID_VALUE = 0x17,
AI_ERROR_INIT_FAILED = 0x30,
AI_ERROR_ALLOCATION_FAILED = 0x31,
AI_ERROR_DEALLOCATION_FAILED = 0x32,
AI_ERROR_CREATE_FAILED = 0x33,
} ai_error_type;
/*!
* @enum ai_error_code
* @ingroup ai_platform
*
* Generic enum to list network error codes.
*/
typedef enum {
AI_ERROR_CODE_NONE = 0x0000, /*!< No error */
AI_ERROR_CODE_NETWORK = 0x0010,
AI_ERROR_CODE_NETWORK_PARAMS = 0x0011,
AI_ERROR_CODE_NETWORK_WEIGHTS = 0x0012,
AI_ERROR_CODE_NETWORK_ACTIVATIONS = 0x0013,
AI_ERROR_CODE_LAYER = 0x0014,
AI_ERROR_CODE_TENSOR = 0x0015,
AI_ERROR_CODE_ARRAY = 0x0016,
AI_ERROR_CODE_INVALID_PTR = 0x0017,
AI_ERROR_CODE_INVALID_SIZE = 0x0018,
AI_ERROR_CODE_INVALID_FORMAT = 0x0019,
AI_ERROR_CODE_OUT_OF_RANGE = 0x0020,
AI_ERROR_CODE_INVALID_BATCH = 0x0021,
AI_ERROR_CODE_MISSED_INIT = 0x0030,
AI_ERROR_CODE_IN_USE = 0x0040,
AI_ERROR_CODE_LOCK = 0x0041,
} ai_error_code;
2 模型创建和初始化
/*!
* @brief Create and initialize a neural network (helper function)
* @ingroup pytorch_ftc_lstm
* @details Helper function to instantiate and to initialize a network. It returns an object to handle it;
* @param network an opaque handle to the network context
* @param activations array of addresses of the activations buffers
* @param weights array of addresses of the weights buffers
* @return an error code reporting the status of the API on exit
*/
AI_API_ENTRY
ai_error ai_modelName_create_and_init(
ai_handle* network, const ai_handle activations[], const ai_handle weights[]);
重点关注输入参数network和activations:数据类型均为ai_handle(即void*)。初始化方式如下:
ai_error err;
ai_handle network = AI_HANDLE_NULL;
const ai_handle act_addr[] = { activations };
// 实例化神经网络
err = ai_modelName_create_and_init(&network, act_addr, NULL);
if (err.type != AI_ERROR_NONE)
{
printf("E: AI error - type=%d code=%d\r\n", err.type, err.code);
}
3 获取输入输出数据变量
/*!
* @brief Get network inputs array pointer as a ai_buffer array pointer.
* @ingroup pytorch_ftc_lstm
* @param network an opaque handle to the network context
* @param n_buffer optional parameter to return the number of outputs
* @return a ai_buffer pointer to the inputs arrays
*/
AI_API_ENTRY
ai_buffer* ai_modelName_inputs_get(
ai_handle network, ai_u16 *n_buffer);
/*!
* @brief Get network outputs array pointer as a ai_buffer array pointer.
* @ingroup pytorch_ftc_lstm
* @param network an opaque handle to the network context
* @param n_buffer optional parameter to return the number of outputs
* @return a ai_buffer pointer to the outputs arrays
*/
AI_API_ENTRY
ai_buffer* ai_modelName_outputs_get(
ai_handle network, ai_u16 *n_buffer);
需要先创建输入输出数据:
// 输入输出结构体
ai_buffer* ai_input;
ai_buffer* ai_output;
// 结构体内容如下
/*!
* @struct ai_buffer
* @ingroup ai_platform
* @brief Memory buffer storing data (optional) with a shape, size and type.
* This datastruct is used also for network querying, where the data field may
* may be NULL.
*/
typedef struct ai_buffer_ {
ai_buffer_format format; /*!< buffer format */
ai_handle data; /*!< pointer to buffer data */
ai_buffer_meta_info* meta_info; /*!< pointer to buffer metadata info */
/* New 7.1 fields */
ai_flags flags; /*!< shape optional flags */
ai_size size; /*!< number of elements of the buffer (including optional padding) */
ai_buffer_shape shape; /*!< n-dimensional shape info */
} ai_buffer;
之后调用函数进行结构体赋值:
ai_input = ai_modelName_inputs_get(network, NULL);
ai_output = ai_modelName_outputs_get(network, NULL);
接下来需要对结构体中的data进行赋值,ai_input和ai_output均为输入输出地址,对于多输入形式的模型,可以数组索引多个输入:
// 单输入
ai_float *pIn;
ai_output[0].data = AI_HANDLE_PTR(pIn);
// 多输入
ai_float *pIn[]
for(int i=0; i<AI_MODELNAME_IN_NUM; i++)
{
ai_input[i].data = AI_HANDLE_PTR(pIn[i]);
}
// 输出
ai_float *pOut;
ai_output[0].data = AI_HANDLE_PTR(pOut);
pIn为指针数组,数组内存储多个输入数据指针;AI_MODELNAME_IN_NUM为宏定义,表示输入数据数量。
AI_HANDLE_PTR是ai_handle类型宏定义,传入ai_float *指针,将数据转换成ai_handle类型。
#define AI_HANDLE_PTR(ptr_) ((ai_handle)(ptr_))
4 获取模型前馈输出
/*!
* @brief Run the network and return the output
* @ingroup pytorch_ftc_lstm
*
* @details Runs the network on the inputs and returns the corresponding output.
* The size of the input and output buffers is stored in this
* header generated by the code generation tool. See AI_PYTORCH_FTC_LSTM_*
* defines into file @ref pytorch_ftc_lstm.h for all network sizes defines
*
* @param network an opaque handle to the network context
* @param[in] input buffer with the input data
* @param[out] output buffer with the output data
* @return the number of input batches processed (default 1) or <= 0 if it fails
* in case of error the error type could be queried by
* using @ref ai_pytorch_ftc_lstm_get_error
*/
AI_API_ENTRY
ai_i32 ai_modelName_run(
ai_handle network, const ai_buffer* input, ai_buffer* output);
函数传入网络句柄,输入输出buffer指针,返回处理的批次数量(应用阶段应该为1),可通过判断返回值是否为1,说明模型运行是否成功。
printf("---------Running Network-------- \r\n");
batch = ai_modelName_run(network, ai_input, ai_output);
printf("---------Running End-------- \r\n");
if (batch != BATCH) {
err = ai_mnetwork_get_error(network);
printf("E: AI error - type=%d code=%d\r\n", err.type, err.code);
Error_Handler();
}
运行后,可通过查看pOut数组数据得到模型输出。
void printData_(ai_float *pOut, ai_i8 num)
{
printf("(Total Num: %d): ", num);
for (int i=0; i < num; i++)
{
if (i == num-1)
{
printf("%.4f. \r\n", pOut[i]);
}
else
{
printf("%.4f, ", pOut[i]);
}
}
}
模型应用小结
可以根据官方部署示例中的方法对AI_Init和AI_Run进行封装。
小结
遇到的BUG持续更新。
![[LeetCode]-622. 设计循环队列](https://img-blog.csdnimg.cn/4d11edafde924437baed73f24bada59a.gif)