本文参考文档为
AMD64 Architecture Programmer’s Manual Volume 2: System Programming,版本号3.41,这不是对原英文文档的翻译,但是所有内容的排版都是根据原手册的排版来的,如有与官方文档冲突的内容,以官方文档为准。

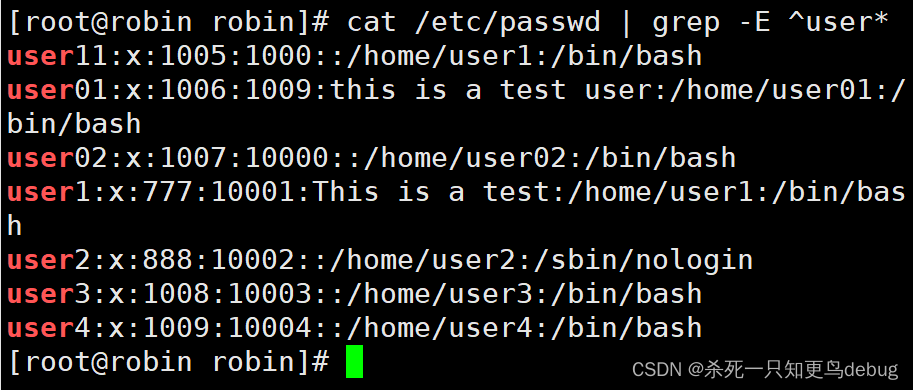
Host内存属性:
Guest内存属性:
由于Guest没有MTRR的硬件支持,MTRR属性可以通过嵌套页表模拟,所以可以假设嵌套页表的内存属性就是Guest的MTRR属性。为了让Guest使用的内存其属性完全由Guest决定,一般都会将嵌套页表、hPAT、物理MTRR对应的Guest可见的内存全部映射为WB。
3 System Resources
3.1 System-Control Registers
3.1.1 CR0 Register
CR0寄存器与内存属性相关的是缓存控制位Cache Disable (CD) Bit 。
当CD被清0后,内部缓存被使能。
当CD被置1后,新的指令或数据都不会再进入缓存,但是在如下情况,处理器任然是可以访问缓存的,只是不会再产生读分配和写分配:
-
缓存被读命中的时候,数据任然会从缓存读取;
-
缓存被写命中的时候,数据会被直接写入内存,并且命中的缓存会被无效掉;
在CD = 1时Cache Misses不会影响缓存。软件可以通过将CD置1并无效掉缓存来阻止对缓存的访问。
✳分页被使能的时候,如果CD被设置为1,那么页级缓存控制位(PWT和PCD)将会被忽略。这些位位于页转换表和CR3寄存器中。
3.2 Model-Specific Registers (MSRs)
3.2.1 System Configuration Register (SYSCFG)
SYSCFG寄存器包含使能和配置总线特性的控制位。SYSCFG是MSR寄存器,其地址为C001_0010h。

✳内存加密和安全相关的位在这里不作解释:
- **MtrrFixDramEn Bit.**设置这个位为
1使能固定范围MTRRs的RdMem和WrMem属性。当清除为0的时候,属性被禁止。RdMem和WrMem允许系统软件在使用固定范围MTRRs的时候定义固定范围的IORRs。 - **MtrrFixDramModEn Bit.**设置这个位为
1的时候允许软件去读写RdMem和WrMem位。当清除为0的时候,写是不会产生效果的,读的话会返回0。 - **MtrrVarDramEn Bit.**设置这个位为
1使能TOP_MEM寄存器和可变范围的IORRs。当清除为0的时候这些寄存器被禁止。 - **MtrrTom2En Bit.**设置这个位为
1使能TOP_MEM2寄存器。当清除为0的时候寄存器被禁止。 - **Tom2ForceMemTypeWB.**设置这个位为
1的时候,强制位于4-Gbyte到TOP_MEM2之间的内存属性为WB,而不是MTRRdefType定义的默认内存类型。这个位要产生效果的话,MTRRdefType必须为1。MTRR可变范围和PAT属性都可以覆盖这个内存类型。
7 Memory System
7.7 Memory-Type Range Registers
AMD64提供了三种机制去管理物理内存区域属性,并且三种机制是可以配合使用的,比较复杂:
- MTRRs
- PAT
- top-of-memory
7.7.1 MTRR Type Fields
MTRR有如下几种编码:

在配置MTRR的时候,可根据设备类型(e.g., ROM, flash, memory-mapped I/O)将对应的物理地址区域配置为如上的这些属性。
内存类型字段编码有两种变体:
- standard
- extended
在两种类型中都使用bits 2:0去指定内存类型,对于extended类型,还使用bits 4:3分别代表RdMem和 WrMem 。
只有固定范围的MTRRs支持extended类型编码,可变范围的MTRRs只支持standard类型的编码(✳实际上后面的IORR变相的支持了extended)。
✳如果在支持MTRR的硬件中禁止了MTRRs(MTRRdefType.E = 0),那么默认的内存类型会被设置为UC。即使通过将CR0.CD清除为0来启用缓存,内存访问也不会被缓存。必须使用MTRR建立可缓存内存类型,才能缓存内存访问。
7.7.2 MTRRs
MTRR有fixed-size和variable-size地址范围两种机制。fixed-size地址范围仅限于1M地址以内,而variable-size地址范围可位于整个物理地址空间。
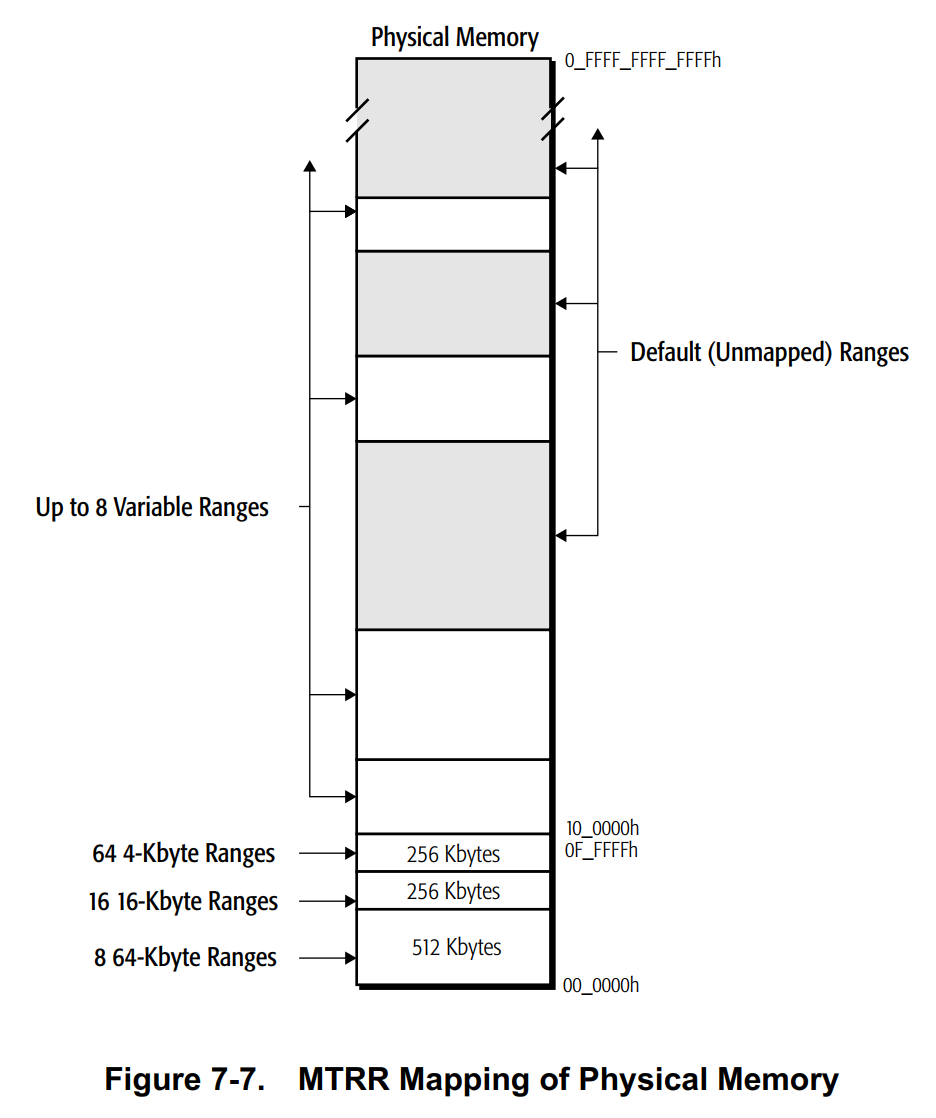
**Fixed-Range MTRRs.**固定范围的MTRRs地址都是固定的,每一个固定地址范围都被分成了8段,对应MSR中设置的8个type字段。
**Variable-Range MTRRs.可变范围的MTRRs支持至多8个地址范围,每段范围由两个MSR描述:MTRRphysBasen and MTRRphysMaskn (n is the address-range number from 0 to 7) 。
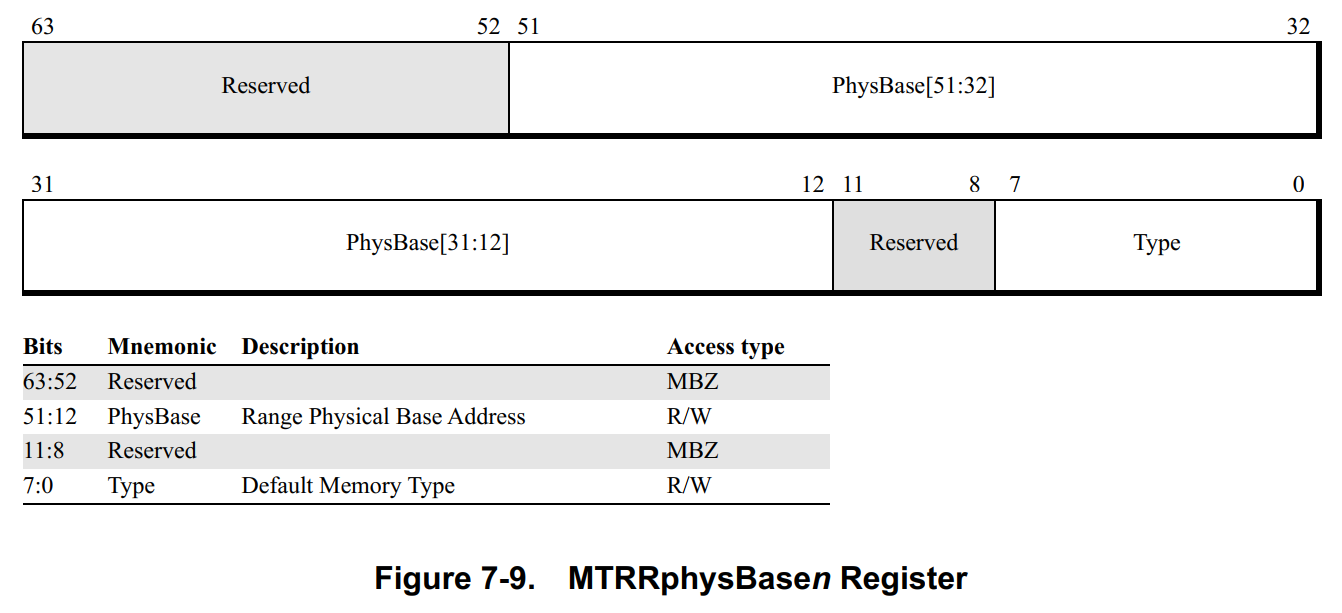

✳Variable Range Size and Alignment.MTRRs和IORRs的大小和对其规则如下:
- 对齐边界必须大于等于范围大小,例如:地址范围是
16 Mbytes,那么对齐边界必须是16-Mbyte对齐的。 - 地址范围大小必须是
2的幂次方,允许的最小大小为4 Kbytes。
**PhysMask and PhysBase Values.**假设当前处理器支持的最大物理地址空间为52-bit,要配置一段起始地址为200_0000h,大小为32M bytes的地址范围的内存属性,PhysBase和PhysMask两个MSR如何配置:
PhysBase = 0x2000000 | memory_type
PhysMask的计算稍微复杂一些:
- addr_mask = F_FFFF_FFFF_FFFFh = (1 << 52-bit) - 1
- PhysMask = addr_mask - (32M bytes - 1) | valid_bit
✳**Default-Range MTRRs.**没有包含在固定范围和可变范围的物理地址,其内存属性都是使用默认的内存属性。
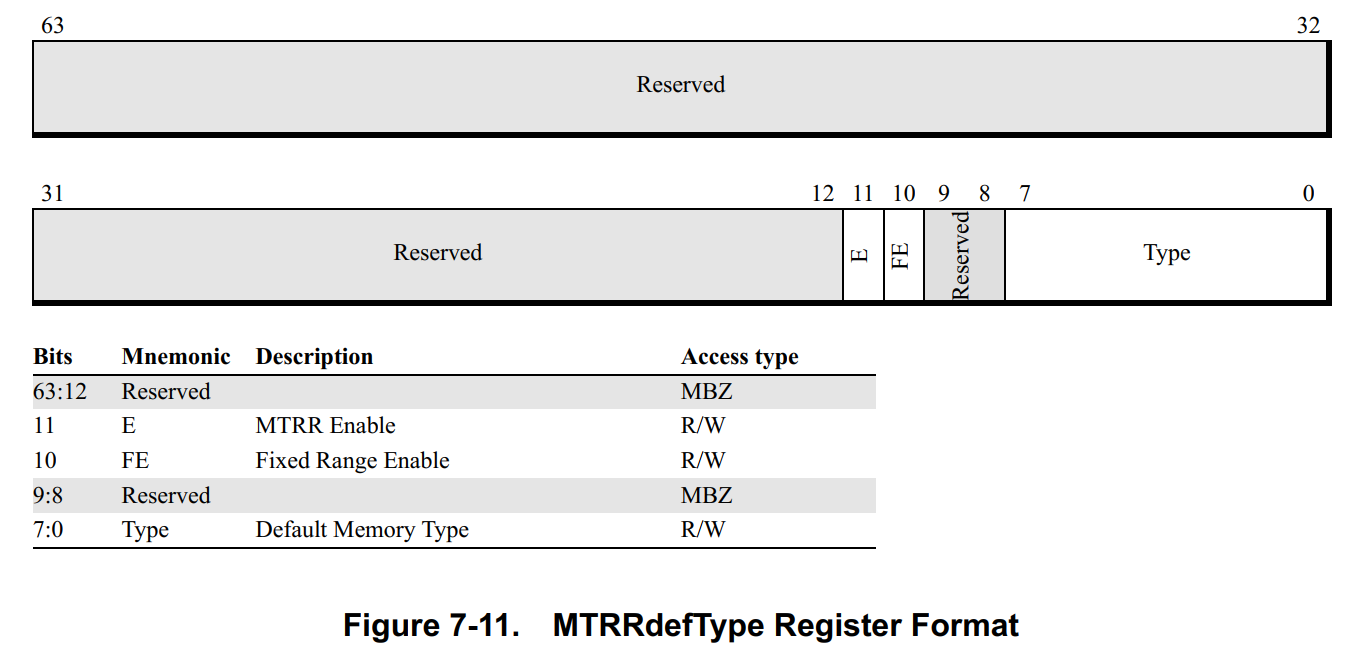
- Type—Bits 7:0.
- **Fixed-Range Enable (FE).**设置为
0的时候,所有固定范围的MTRRs被禁止,但不影响可变范围的MTRRs。 - **MTRR Enable (E).**设置为
0的时候,所有可变和固定范围的MTRRs全部被禁止,并且type字段的内容会被忽略,默认类型被视为UC。不会影响RdMem和WrMem字段。
7.7.3 Using MTRRs
**Identifying MTRR Features.**可通过CPUID指令使用功能号0000_0001h或8000_0001h查询是否支持MTRRs。
如果支持MTRRs的话,可读取MTRRcap寄存器,获取MTRRs的相关能力:
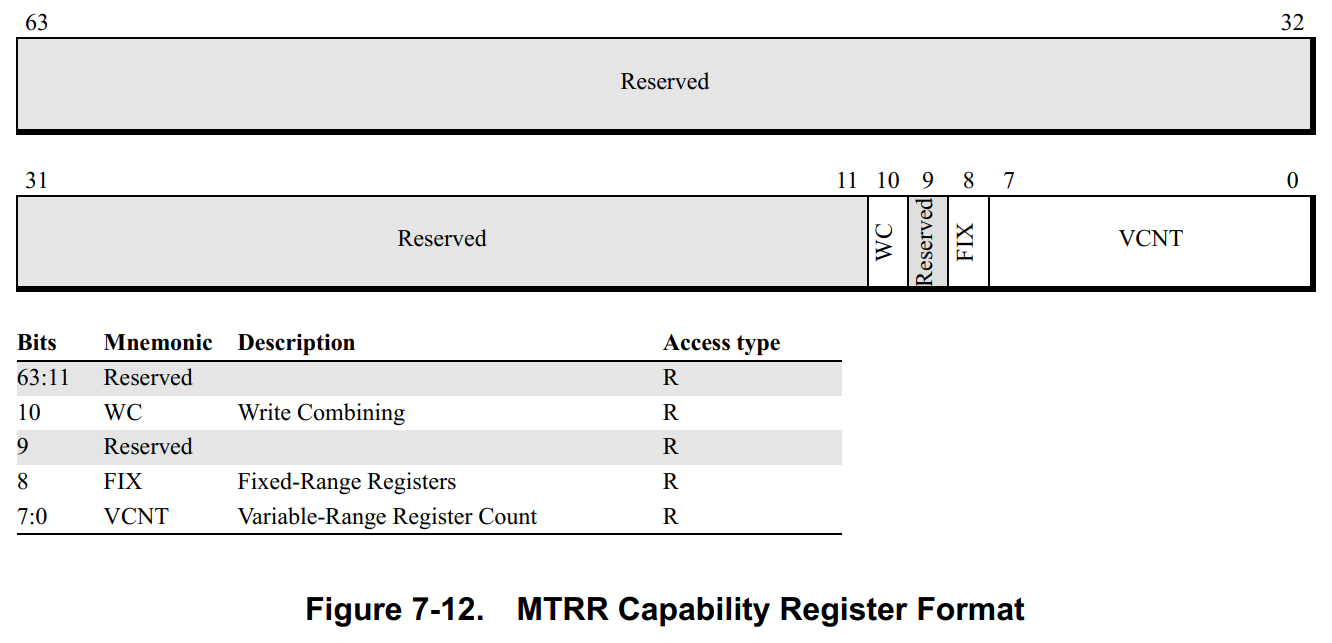
- **Variable-Range Register Count (VCNT).**指示有多少可变范围
MTRRs组被支持。 - **Fixed-Range Registers (FIX).**指示固定范围
MTRRs是否被支持。 - **Write-Combining (WC).**指示
WC内存类型是否被支持。
7.7.4 MTRRs and Page Cache Controls
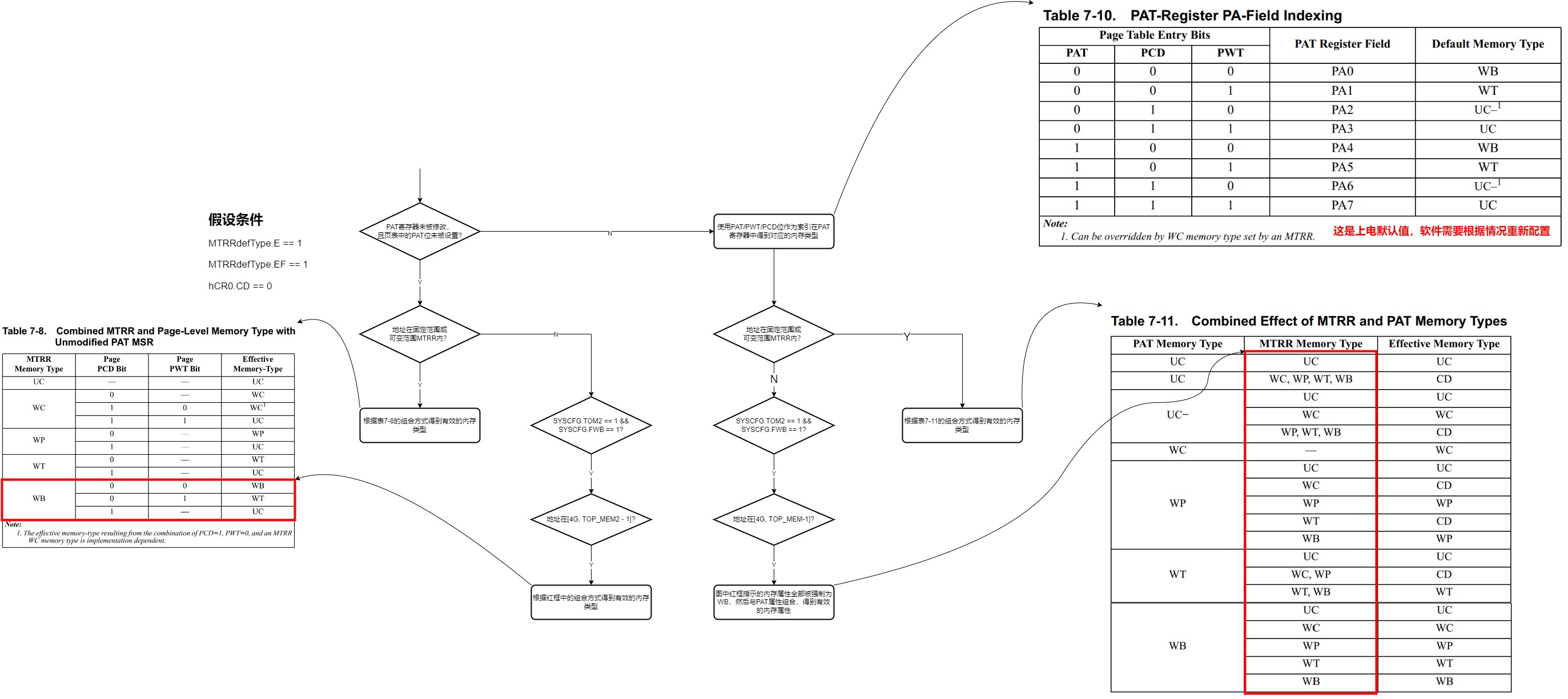
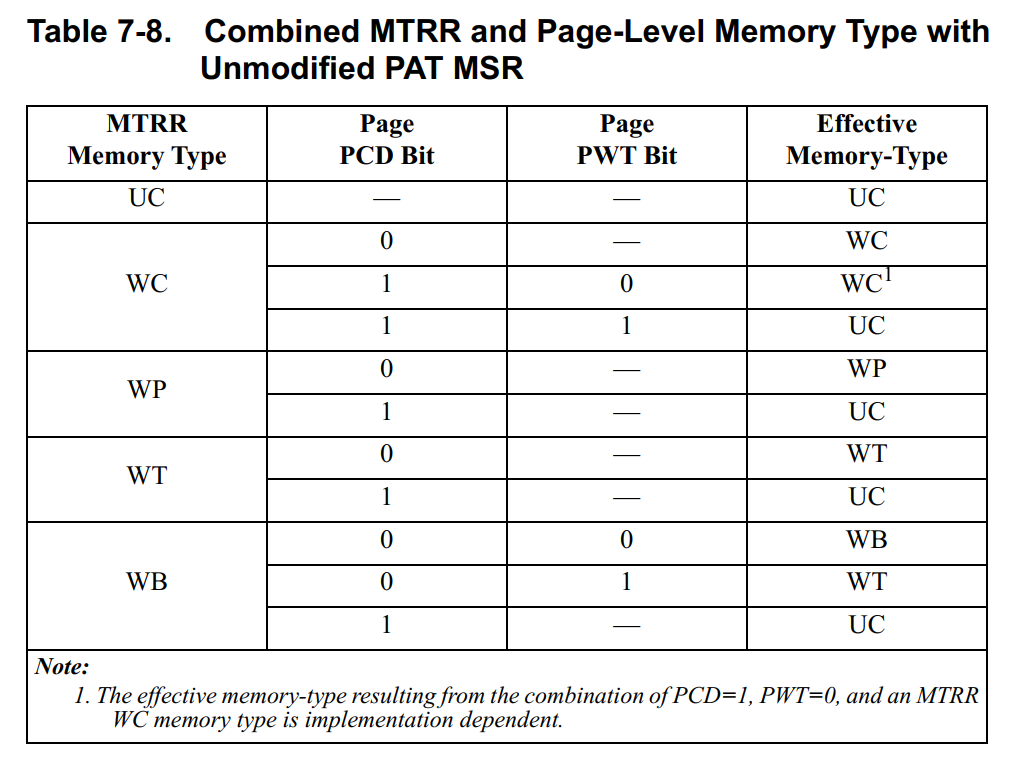
MTRRs和分页机制都被使能的时候,有效的内存类型有以下几种情况,这里描述的是未修改的PAT,也就是PAT里面的值是上电默认值,只使用PCD和PWT,没有PAT bit:
- 如果页是可缓存并且是写回(
WB)的属性(PCD=0 and PWT=0),那么有效的内存类型由MTRR决定。 - 如果页是不可缓存(
PCD=1)的,那么有效的内存类型是UC。 - 如果页是可缓存并且是写直通的属性(
PCD=0 and PWT=1),那么有效的内存类型由MTRR决定,除非MTRR指定是WB的内存,这种情况有效的内存类型是WT。
文字描述起来不太好懂,还是表格比较好理解:
**Large Page Sizes.**启用分页后,除了典型的4 KB页大小之外,软件还可以使用大页(2 MB和4 MB)。当使用大页时,多个MTRR可能会跨越单个大页内的内存范围。每个MTRR可以表征页面内具有不同内存类型的区域。如果发生这种情况,则处理器在大页中使用的有效内存类型是未定义的。
软件可以下面的方法去避免这种情况:
- 避免使用多个
MTRRs去表征单个大页 - 使用多个
4-Kbyte页去替代这个大页 - 如果必须用多个
MTRRs去表征单个大页,可以将MTRR类型设置为相同的值 - 如果多个
MTRRs必须有不同的类型,软件可以将大页PCD和PWT位设置为由多个MTRR定义的最严格的内存类型
**Overlapping MTRR Registers. **如果两个或多个MTRR的地址范围重叠,则应用以下规则来确定用于表征重叠地址范围的内存类型:
- 当物理地址在
1 Mbyte以下时,固定范围的MTRRs比可变范围的MTRRs优先级更高。 - 如果两个或多个可变范围
MTRRs重叠,则遵循以下规则:- 如果内存类型相同,则使用该内存类型。
- 只要有一个
UC内存类型,那内存类型就是UC。 - 如果只有
WT和WB两种内存类型,那么内存类型就是WT。 - 如果内存类型的组合未在上面几种情况列出,则所使用的内存类型是未定义的。
7.7.5 MTRRs in Multi-Processing Environments
在多处理器环境,所有处理器的MTRRs、CR0.CD、PAT都必须是一致的,不然就会违反一致性和原子原则。硬件不会去检查这些值在各个处理器是否是一致的,需要软件去初始化和维护它们在所有处理器之间的一致性。
7.8 Page-Attribute Table Mechanism
PAT机制提供和MTRRs相同的内存类型能力,但是更加的灵活。PAT和MTRR机制是可以一起使用的。
7.8.1 PAT Register
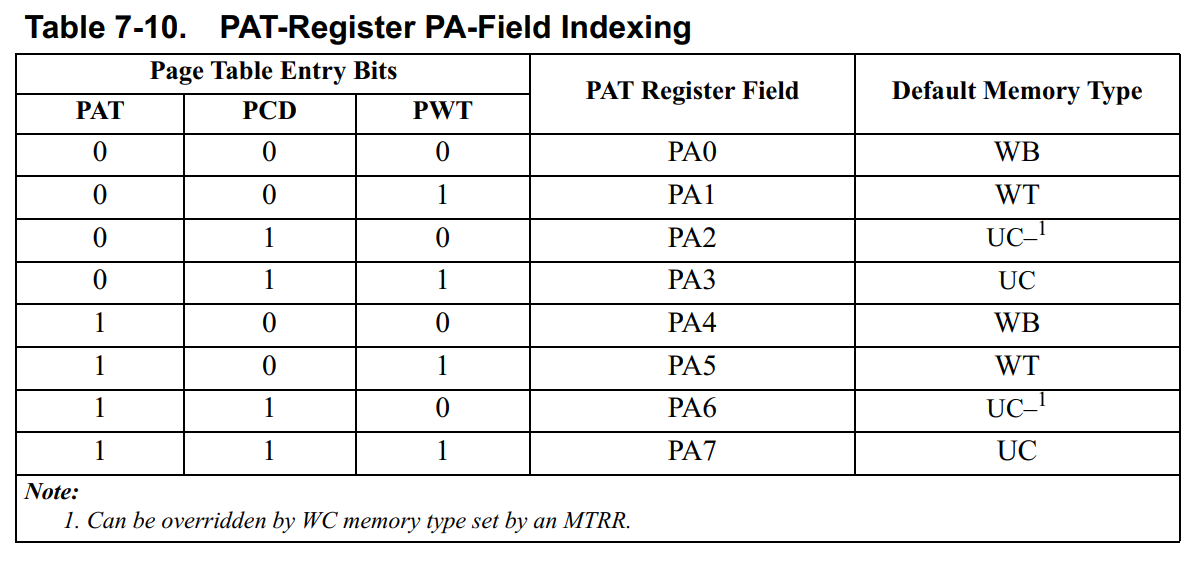
PAT寄存器有8个字段,也就是最大支持8种内存类型:

其支持的内存类型如下,比MTRR多了一个UC-:

7.8.2 PAT Indexing
PAT索引由三个bit组成:
- **PAT.**在
4-Kbyte页中,PAT位位于PTEs的bit7;在2-Mbyte和4-Mbyte页中,PAT位位于PDEs的bit12。 - **PCD.**位于所有页表条目的
bit4。 - **PWT.**位于所有页表条目的
bit3。
下图是上电复位后PAT对应的默认内存类型:
7.8.3 Identifying PAT Support
可通过CPUID指令使用功能号0000_0001h或8000_0001h查询是否支持PAT。
✳如果处理器支持PAT的话,那它默认就是使能的。并且不能通过软件禁止。但是软件可以使用如下方式避开使用PAT:
- 在页表条目中不将
PAT位设置为1。 - 不修改
PAT寄存器的上电默认值。
这样的话就和不支持PAT机制的实现是一样的。
7.8.4 PAT Accesses
在支持PAT机制的实现中,所有通过分页机制转换的内存访问都会使用PAT去索引PAT寄存器中对应的内存属性字段。过程如下:
- 处理器拿到一个虚拟地址。
MMU通过分页机制将这个虚拟地址转换成物理地址。- 在转换的同时,从相应的页表条目读取
PAT,PCD和PWT位。 - 使用
PAT,PCD和PWT位作为索引从PAT寄存器拿到对应的内存属性值。 - 转换后的物理地址就会以拿到的内存属性去访问物理内存。
✳Page-Translation Table Access.MMU使用的页表是没有PAT位的,只能使用PCD和PWT 位去索引PAT寄存器的前四个字段。
7.8.5 Combined Effect of MTRRs and PAT
如果同一段物理地址同时使用MTRRs和PAT,那么最终的内存属性是有很多种组合情况的:
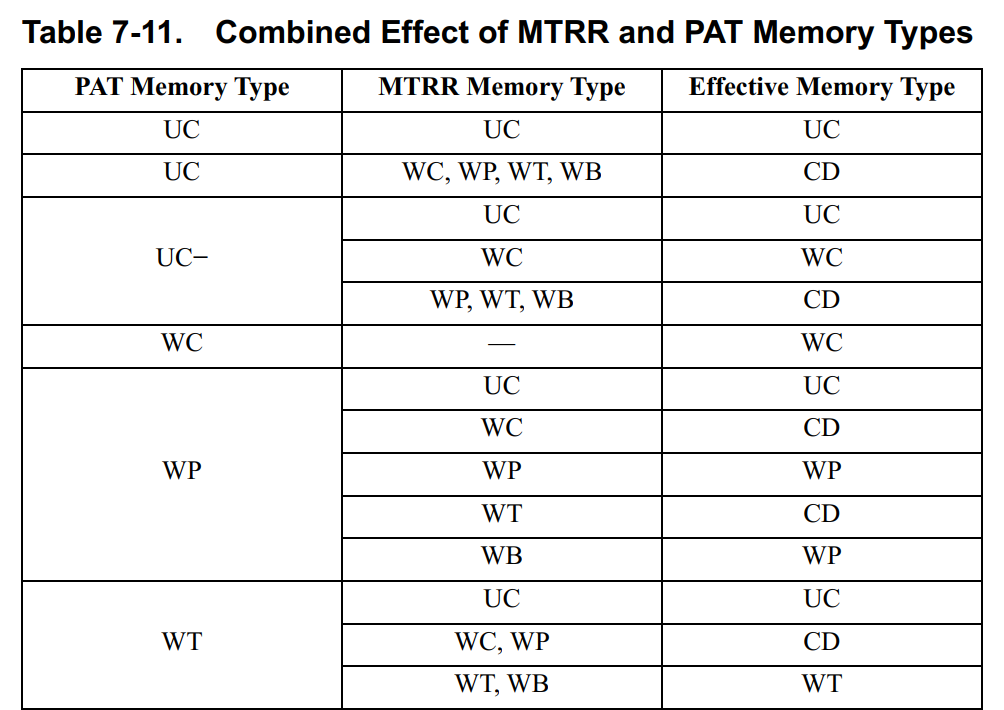
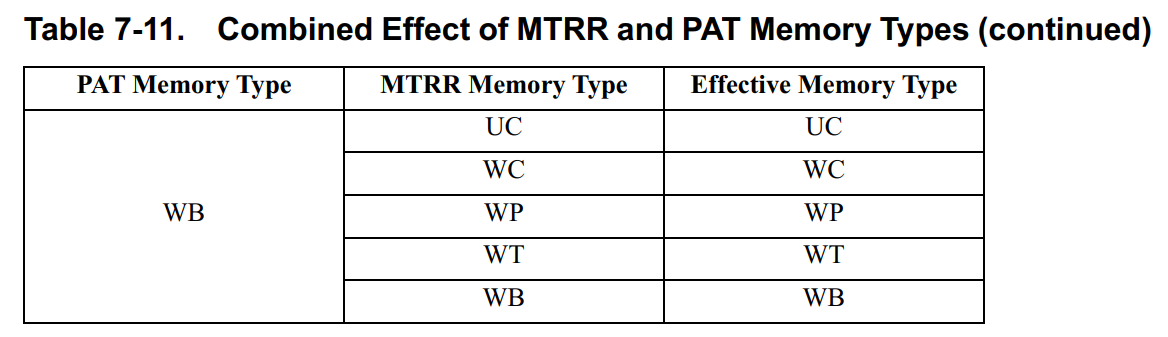
7.8.6 PATs in Multi-Processing Environments
多核一致性和MTRRs是一样的。
7.8.7 Changing Memory Type
物理页不应该通过不同的虚拟映射分配不同的可缓存性类型;它们应该全部是可缓存类型(WB、WT、WP)或全部是不可缓存类型(UC、WC)。否则,这可能会导致缓存一致性丢失,从而导致数据过时和不可预测的行为。因此,在更改页面的内存类型时必须采取一定的预防措施。特别是,当从可缓存内存类型更改为不可缓存类型时,必须刷新缓存,因为处理器的预测执行可能会导致内存被缓存,即使它没有以编程方式引用。下表总结了安全更改内存类型的序列化要求。

- **a.**先删除之前的映射(使其不存在于页表中);刷新
TLB,包括可能使用该映射的其他处理器的TLB,即使是推测性的;使用新类型在页表中创建新映射。 - **b.**除了注释
a中描述的步骤之外,软件还应该从可能使用了先前映射的任何处理器的缓存中刷新页面。这必须在注释a中的TLB刷新完成后完成。
7.9 Memory-Mapped I/O
这段内容网上资料比较少,在Linux源码也没找到相关的用例,猜测是一段物理地址,物理内存和设备都使用了这段相同的地址,在访问时可以设置相关的位来将访问定向为系统内存还是内存映射I/O。
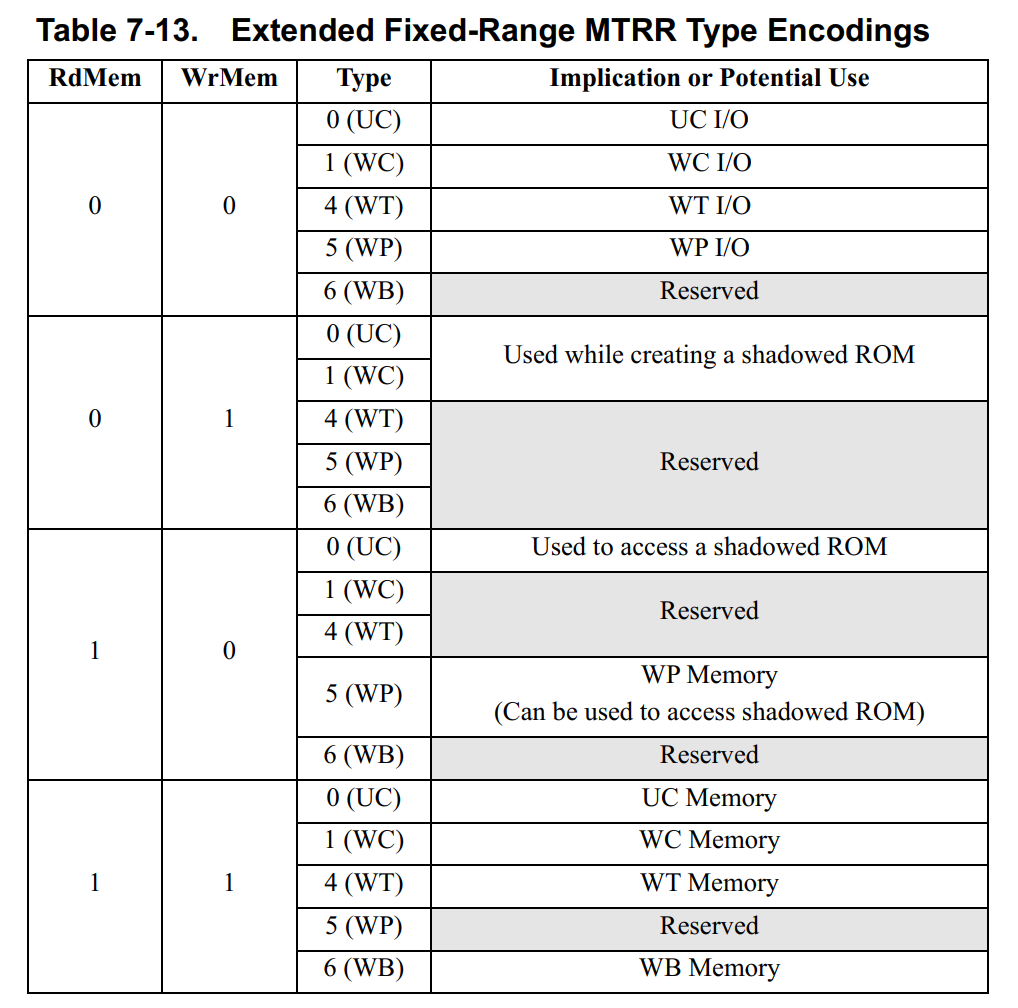
7.9.1 Extended Fixed-Range MTRR Type-Field Encodings
固定范围的MTRRs使用预留的bits 4:3去指定物理地址是定向到系统内存还是内存映射I/O。
- **WrMem—Bit 3.**当设置为
1的时候,处理器定向写请求到系统内存。清除为0的时候,定向到内存映射I/O。 - **RdMem—Bit 4.**当设置为
1的时候,处理器定向读请求到系统内存。清除为0的时候,定向到内存映射I/O。
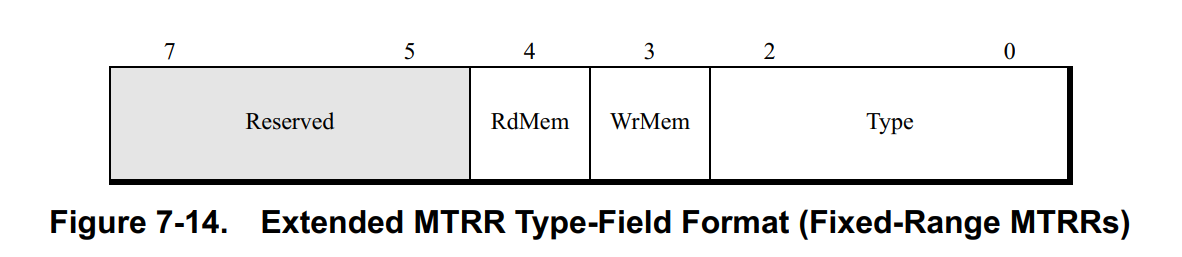
使能条件由SYSCFG这个MSR中的特定位决定:
- **MtrrFixDramEn—Bit 18.**当设置为
1的时候,RdMem和WrMem属性被使能。清除为0的时候,这些属性被禁止。当禁止的时候,访问被定向到内存映射I/O。 - **MtrrFixDramModEn—Bit 19.**当设置为
1的时候,软件可以读写RdMem和WrMem位。清除为0的时候,写是不会产生效果的,读的话会返回0。
要使用这个扩展,软件必须先设置MtrrFixDramModEn=1以允许修改RdMem和WrMem位。在固定范围MTRRs寄存器中初始化这些属性位后,设置MtrrFixDramEn=1去使能这个扩展。
RdMem和WrMem允许处理器独立地定向读取和写入系统内存或内存映射I/O。当隐藏位于内存映射I/O空间中的ROM设备时,RdMem 和 WrMem控制特别有用。在RAM系统内存中隐藏此类设备以提高访问性能通常很有用,但写入RAM位置可能会损坏隐藏的ROM信息。MTRR扩展解决了这个问题。系统软件可以通过为指定的内存范围设置WrMem = 1和RdMem = 0来创建影子位置,然后将ROM位置复制到自身中。读取定向到内存映射ROM,但写入则定向到系统内存中的相同物理地址。复制完成后,系统软件可以将值更改为WrMem = 0和 RdMem = 1。现在读取将定向到位于系统内存中的更快副本,写入将定向到内存映射ROM。ROM像平常一样响应写入,即忽略它。
不是所有的编码组合都被支持,使用保留的编码组合会产生不可预期的行为:
7.9.2 IORRs
IORRs操作类似于可变范围MTRRs。IORRs指定任何物理地址范围中的读取和写入是映射到系统内存还是内存映射I/O。使用IORR最多可以控制两个不同大小的地址范围。每个地址范围由一对IORRs控制:IORRBasen和IORRMaskn(n值的范围0到1)。
IORR范围与等效有效MTRR范围的交集遵循与固定范围MTRR相同的类型编码表(表7-13),其中RdMem/WrMem和内存类型直接绑定在一起。
IORRBasen Registers.
- **WrMem—Bit 3.**当设置为
1的时候,处理器定向写请求到系统内存。清除为0的时候,定向到内存映射I/O。 - **RdMem—Bit 4.**当设置为
1的时候,处理器定向读请求到系统内存。清除为0的时候,定向到内存映射I/O。 - **Range Physical-Base-Address (PhysBase)—Bits 51:12.**内存范围的物理基地址。
PhysBase在AMD64架构最大支持52位物理地址空间,且是4-Kbyte(或更大)地址对齐的。PhysBase表示物理地址的高40位有效地址。物理地址位11:0假定为0。

IORRMaskn Registers.
- **Valid (V)—Bit 11.**指示一对
IORR是否有效。当为0的时候是无效的,并且不会被使用。 - **Range Physical-Mask (PhysMask)—Bits 51:12. **指定内存范围的掩码。
PhysMask是4-Kbyte边界对齐的。
7.9.3 IORR Overlapping
不建议使用重叠的IORRs。如果指定了重叠的IORRs,则结果行为取决于具体的实现。
7.9.4 Top of Memory
✳TOP_MEM设置了不知道有什么用处,经测试不管如何配置对内存属性好像都没影响,但是TOP_MEM2对于内存属性是由影响的。
有两个top-of-memory寄存器,TOP_MEM和TOP_MEM2用来指定作为内存映射I/O的物理地址范围。TOP_MEM寄存器指定的内存区域是8-Mbyte对齐的:
- 对于物理地址
0到TOP_MEM - 1的内存访问被定向到系统内存。 - 对于物理地址
TOP_MEM到FFFF_FFFFh的内存访问被定向到内存映射I/O。 - 对于物理地址
1_0000_0000h到TOP_MEM2 - 1的内存访问被定向到系统内存。 - 对于物理地址
TOP_MEM2到支持的最大物理地址空间的内存访问被定向到内存映射I/O。
top-of-memory范围与等效有效MTRR范围的交集遵循与固定范围MTRR相同的类型编码表(表7-13),其中RdMem/WrMem和内存类型直接绑定在一起。
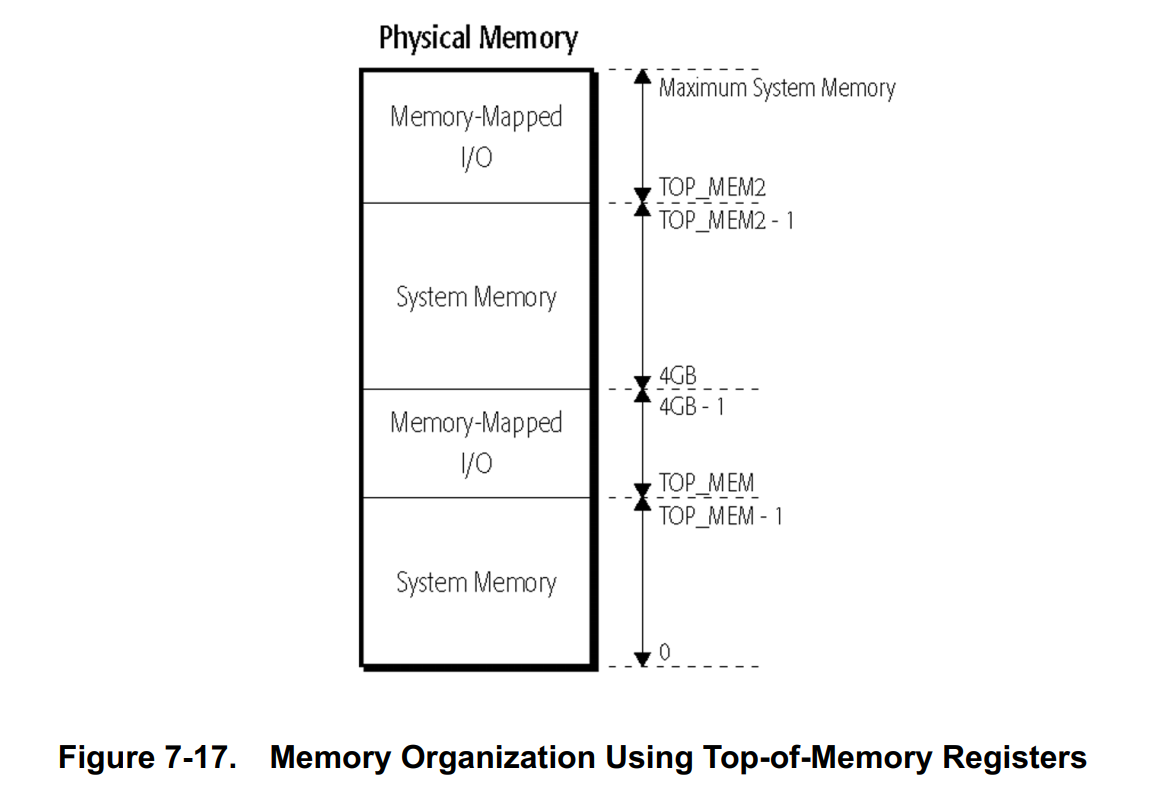
TOP_MEM和TOP_MEM2寄存器的格式如下,bits 51:23指定的是一个8-Mbyte对齐的物理地址。所有剩余的位被保留,并且为了兼容性应该清除为0.

TOP_MEM寄存器被使能,当SYSCFG这个MSR的bit 20(MtrrVarDramEn) 被设置为1时。TOP_MEM2寄存器被使能,当SYSCFG这个MSR的bit 21(MtrrTom2En) 被设置为1时。当相应的位被清除为0的时候,寄存器被禁止。在top-of-memory寄存器被禁止后,默认的内存访问被定向到内存映射I/O。
15 Secure Virtual Machine
15.25 Nested Paging
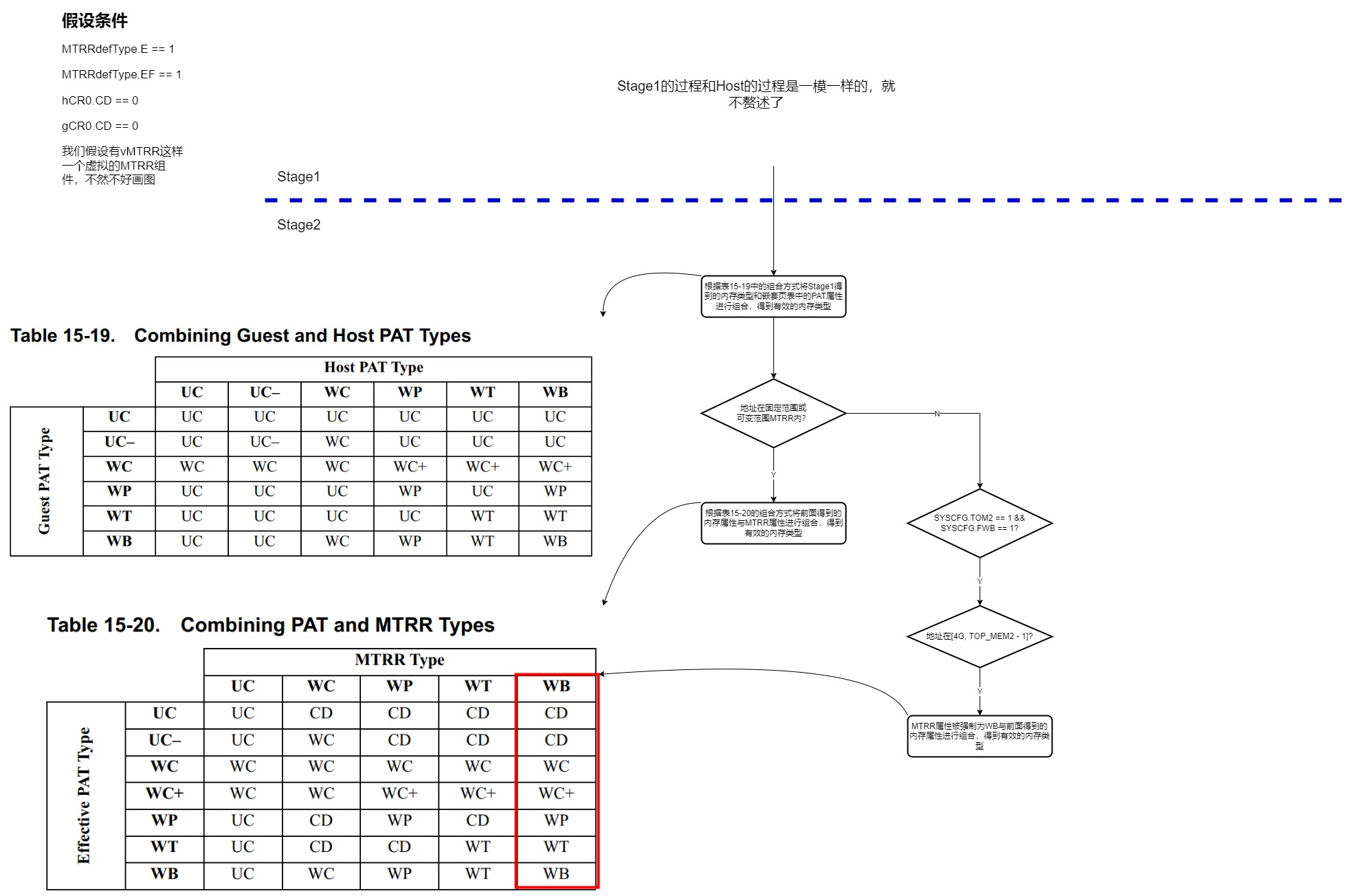
15.25.8 Combining Memory Types, MTRRs
当嵌套分页被禁用时,处理器的行为就像没有gPAT寄存器一样。
Host的PAT MSR确定当前VM的内存类型属性,并且Guest写入未被VMM拦截的PAT MSR将更改Host的PAT MSR。VMM负责在虚拟机之间切换时对PAT MSR内容进行切换。
当嵌套分页被使能时,处理器组合Guest和嵌套页表的内存类型。影响内存类型的寄存器有:
- 嵌套页表和
Guest页表的PCD/PWT/PAT位。 gCR3和nCR3的PCD/PWT位。Guest的PAT类型。Host的PAT类型。MTRRs。gCR0.CD和hCR0.CD。
✳Guest的MTRRs没有硬件支持。VMM可以通过改变嵌套页表中的内存类型来模拟它们的效果。MTRR仅适用于系统物理地址。
构建Guest TLB条目时组合内存类型的规则是:
- 嵌套和
Guest的PAT类型根据表15-19进行组合。 - 组合的
PAT类型进一步根据表15-20与MTRR类型组合,其中相关MTRR由系统物理地址确定。 gCR0.CD或hCR0.CD都可以禁用缓存。
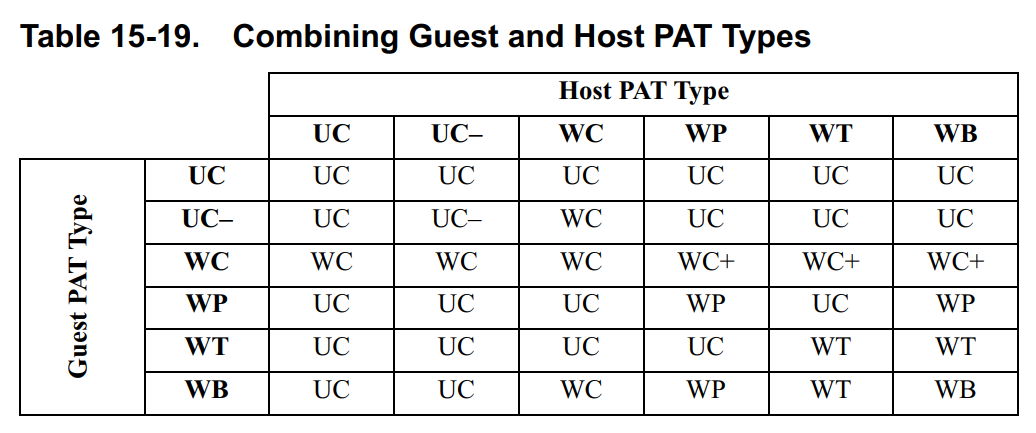

**Memory Consistency Issues.**因为Guest使用额外的字段来确内存类型,所以VMM可以使用与Guest不同的内存类型来访问给定的内存区域。如果一个访问是可缓存的,而另一个访问不可缓存,则VMM和Guest虚拟机可能会观察到不同的内存映像,这是非期望的结果。(多核处理器对这个问题特别敏感,当虚拟cpu被VMM设计为可在物理cpu之间迁移。)
为了解决这个问题,提供了下面的机制:
VMRUN和#VMEXIT刷新写组合。这确保了Guest对WC内存的所有写入对于Host都是可见的(反之亦然),而无论内存类型如何。 (它不能确保一个代理的可缓存写入被另一代理的WC读取或写入正确观察到。)- 引入了新的内存类型
WC+。WC+是一种不可缓存的内存类型,并且像WC一样在写组合缓冲区中组合写操作。与WC不同(但与 CD 内存类型类似),对WC+内存的访问还会监听所有处理器上的缓存(包括自监听发出请求的处理器的缓存)以保持一致性。这可确保 可缓存的写入被WC+访问观察到。 - 当组合与缓存不兼容的嵌套内存类型和
Guest内存类型时,将使用WC+内存类型而不是WC(表 15-20 确保无论Host的MTRR设置如何,都保留监听行为)。
![[LeetCode]-622. 设计循环队列](https://img-blog.csdnimg.cn/4d11edafde924437baed73f24bada59a.gif)