拜占庭将军
假设多位拜占庭将军中没有叛军,信使的信息可靠但有可能被暗杀的情况下,将军们如何达成是否要进攻的一致性决定?解决问题的思路是,从多位处于平等地位的将军中选举出一位大将军,所有作战指令由大将军发出。如果这位大将军被杀,那么只需要从剩下的将军中再次选举出大将军即可。这就是解决分布式共识问题的思路。如何选举、指令如何传达则是实现分布式共识的手段。下面我们尝试推演一下这个过程。
假设拜占庭有三座城池,由3位将军掌管,每位将军都在等消息,等待了一个随机时间后,如果没收到任何消息,将派出自己的信使向另外两位将军发起自己当大将军的投票。其它将军如果收到了将军的投票请求,默认会将自己的一票投给信使最先到达的将军,后到者则拒绝。所有将军都是这个做法,那么最终必定能选出一个大将军。选出后,后面的作战指令就通过信使定期向其它将军发出,如果超过预设时间没收到指令,则认为大将军已死,苍天已死,黄天当立,剩下的将军们开始新一轮拉票当大将军活动.....
基本上,分布式共识或说分布式数据一致性大体上是按上面的思路来实现的。
分布式共识
假设我们对单一的节点就某个值进行写操作,是很容易达成共识的,毕竟只有一个节点,写成功了就达成一致。但是,如果我们有多个节点,我们该如何达成共识呢?

这个就是分布式共识问题。例如mongodb副本机制,写入一个文档是需要在所有副本节点之间进行同步的,但节点间的数据如何同步,哪个节点提供读或写服务?这些都涉及到分布式共识问题,分布式共识问题可以简单理解成在一个多节点数据集群中(此集群有可能出现分区),如何对数据进行同步,使所有节点的数据达到一致的问题。
共识算法通常具备如下特性:
-
高可用。只要集群中多数节点是可用、与客户端的通信也是正常的,那么整个系统就是正常可用的,少数节点故障并不会影响系统的运行。
-
强一致性。数据一致性不依赖时序,最坏的情况会产生可用性问题,但不会产生一致性问题。
Raft
raft是一个用于实现分布式共识的协议。
节点状态
在一个使用Raft共识算法的集群中,集群节点会存在三个节点状态,分别是Follwer、Candidate、Leader。
-
Follwer:接受 Leader 的心跳和日志同步数据,投票给 Candidate
-
Candidate:Leader候选角色,Follwer倒计时时钟结束转化成Candidate,可发起投票参与Leader竞选
-
Leader:集群领导角色,负责发起心跳,响应客户端,创建日志,同步日志
在一个非分区集群中,只会有一个Leader(网络分区可能会造成出现多个leader的情况),剩下的都是Follwer,Candidate只会出现在集群选举过程中,成功获取多数票的Candidate节点直接成为Leader。
任期

任期是一个连续递增的数字,每一个任期的开始都是一次选举,在选举开始时,一个或多个 Candidate 会尝试成为 Leader。如果一个 Candidate 赢得了选举,它就会在该任期内担任 Leader。如果没有选出 Leader,将会开启另一个任期,并立刻开始下一次选举。
每个节点都会存储当前的 term 号,当服务器之间进行通信时会交换当前的 term 号;如果有服务器发现自己的 term 号比其他人小,那么他会更新到较大的 term 值。如果一个 Candidate 或者 Leader 发现自己的 term 过期了,他会立即退回成 Follower。如果一台服务器收到的请求的 term 号是过期的,那么它会拒绝此次请求。
日志
-
entry:每一个事件成为 entry,只有 Leader 可以创建 entry。entry 的内容为<term,index,cmd>其中 cmd 是可以应用到状态机的操作。 -
log:由 entry 构成的数组,每一个 entry 都有一个表明自己在 log 中的 index。只有 Leader 才可以改变其他节点的 log。entry 总是先被 Leader 添加到自己的 log 数组中,然后再发起共识请求,获得同意后才会被 Leader 提交给状态机。Follower 只能从 Leader 获取新日志和当前的 commitIndex,然后把对应的 entry 应用到自己的状态机中。
Leader选举过程
开始选举时,所有节点处于Follwer状态,节点会有一个随机倒计时时钟(随机时间在150ms到300ms内),这个随机时钟是为了有节点能更快的达到Candidate状态发出选举,从而成为Leader。避免可能出现的多个节点同时成为Candidate从而导致选举效率低下问题。

当某节点election timeout心跳结束,但没收到主节点的心跳信息,它就会转成Candidate 。
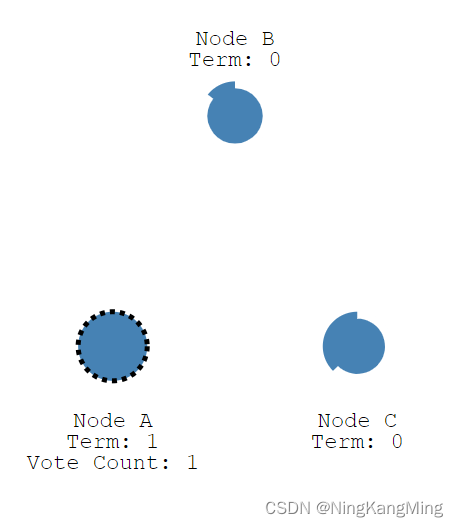
此时,NodeA成为Candidate并开启亲的任期,然后向B、C节点发起投票

此时如果B、C的任期小于收到的1,自身也还没成为Candidate,此时B、C将票投到A。B、C重置election timeout时钟。在 Candidate 等待选票的时候,它可能收到其他节点声明自己是 Leader 的心跳,此时有两种情况:
-
该 Leader 的 term 号大于等于自己的 term 号,说明对方已经成为 Leader,则自己回退为 Follower。
-
该 Leader 的 term 号小于自己的 term 号,那么会拒绝该请求并让该节点更新 term。
收到选票的A获得集群大多数票(N/2+1),成功转成Leader,并向集群其它节点定期发送心跳(heartbeat timeout)以保住自己的Leader地位。
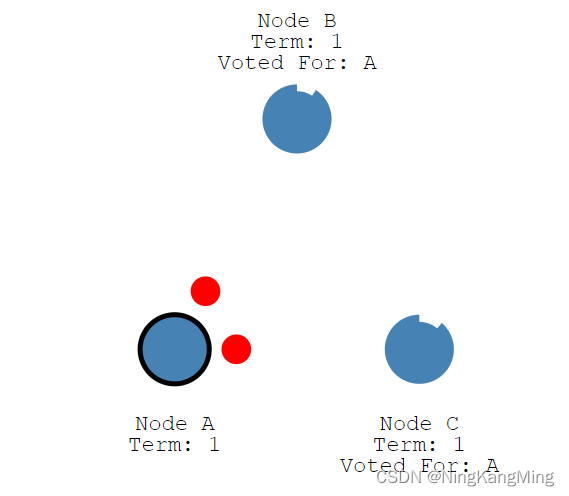
其他节点收到心跳(Append Entries)后响应主节点然后再次重置election timeout时钟。这个选举任期将持续到Follwer心跳time_out而成为Candidate。

主节点下线后,集群就会出现重选举,新选出的Leader的任期递增。正常情况下,获取多数票的节点成为主节点,但如果出现偶数节点时,可能会出现两个节点获取了相同票数的情况。

比如上面的情况,A、C加上自身的票数,都是2票,此时这个任期是选不出Leader的。只能重新发起一轮选举。如此反复,最终选出一个Leader。

可见,Raft协议下,节点无论是奇数还是偶数都是能正常选举出Leader的,但是偶数节点容易出现选票僵持的情况,从性能上考虑,使用奇数节点去部署集群是较好的选择。
日志复制
在上面的描述中,当集群选举出节点后,主节点会通过广播心跳到其它节点以保住自己的Leader地位,在这个过程,Leader的心跳包会携带Append Entries,这个Append Entries通常只是作心跳保持使用,但当主节点出现数据变化时,主节点在下一次的心跳中,将数据变化写到Append Entries,其它节点收到后先写到节点日志中,但数据处于uncommit状态,当然,此时主节点的数据也是uncommit,直到收到所有节点的响应,主节点的数据直接转成commit状态。

下一次主节点心跳会告诉其它节点,此数据已处于commit状态,那么其它节点也会将数据设置成commit状态。引时整个集群的数据处于一致性状态,后续再加2走同样的流程,最终集群的某个值都被设置成了7。

网络分区
当一个集群中出现了网络分区,可能会导致整个集群出现多个leader的情况,此时集群的数据一致性如何保证?

假设此时两个客户端分别通过主节点B设置x=3,主节点E设置x=8,那么集群最终x将等于8。因为在网络分区中,占少数节点的主节点因在设置值的时候未能得到大多数节点的回复(集群总节点数在集群设置完毕后就是明确的),因此x=3只是保持一个uncommit状态,并不会真的提交。
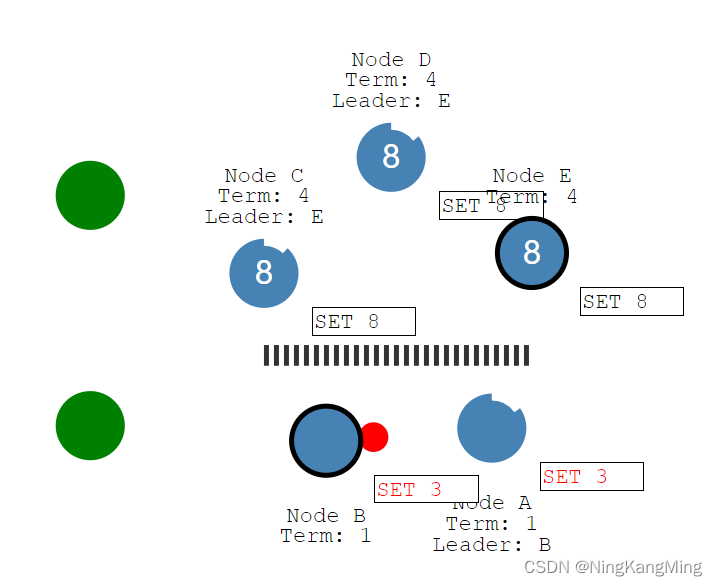
当网络恢复时,节点B、A会看到任期更高的主节点,于是将自身设置为Foller,回滚uncommit的数据并去同步主节点的数据。
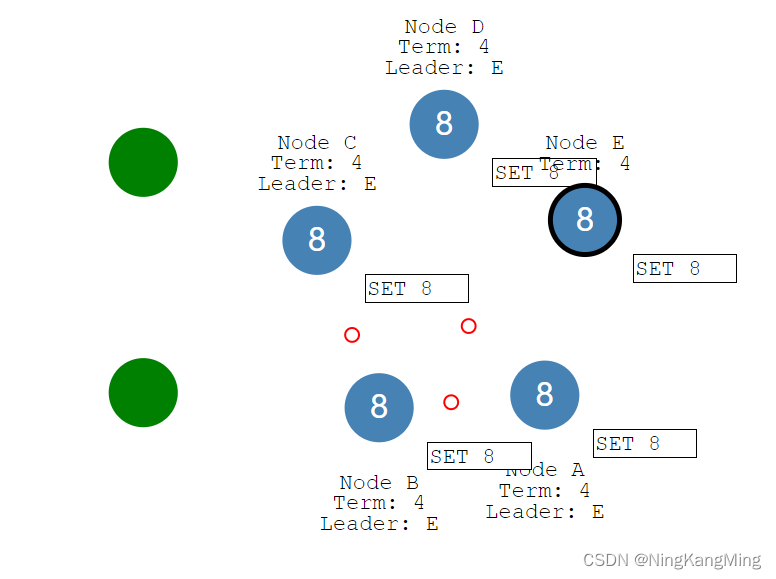
此时整个集群又回到了一致性的状态。