Paimon
Apache Paimon (incubating) 是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。Paimon 采用开放的数据格式和技术理念,可以与 ApacheFlink / Spark / Trino 等诸多业界主流计算引擎进行对接,共同推进 Streaming Lakehouse 架构的普及和发展。
Paimon x Spark
Apache Spark,作为大数据处理的统一计算分析引擎的,不仅支持多种语言的高级 API 使用,也支持了丰富的大数据场景应用,包括结构化数据处理的Spark SQL、用于机器学习的 MLlib,用于图形处理的 GraphX,以及用于增量计算和流处理的Structured Streaming。Spark 已经成为了大数据领域软件栈中必不可少的组成部分。作为数据湖领域新起的 Paimon,与 Spark 的深度、全面的集成也将为 Paimon在准实时场景、离线湖仓场景提供了便利。
接下来我们介绍一些在 Paimon 新版本中基于 Spark 计算引擎支持的主要功能。
Schema Evolution
Schema evolution 是一个数据湖领域一个非常关键的特性,它允许用户方便的修改表的当前 Schema 以适应现有数据,或随时间变化的新数据,同时保持数据的完整性和一致性。
在离线场景中,我们可以通过计算引擎,如 Spark 或者 Flink,提供的 Alter Table 的 SQL 语法来实现对 Schema 的操作。在某些场景下,我们并非都能实时准确的获取上游数据较当前表的 Schema 变化;另外在 Streaming 流式场景中以离线 Alter Table 的方式完成 Schema 的更新需要执行1)停止流作业,2)完成 Schema 更新操作,3)重启流作业这样的流程,这是较为低效的。
Paimon 支持了在数据写入的同时,自动完成 Source 数据和当前表数据的 Schema 合并,并将合并后的 Schema 作为表的最新 Schema,仅需要配置参数 write.merge-schema。
data.write
.format("paimon")
.mode("append")
.option("write.merge-schema", "true")
.save(location)新增列
比较常见的是,在执行数据追加或覆盖操作时使用,以自动调整 Schema 以包含一个或多个新列。
假设原表的 Schema 为:
a INT
b STRING新数据 data 的 Schema 为:
a INT
b STRING
c LONG
d Map<String, Double>操作完成后的表的 Schema 变更为:
a INT
b STRING
c LONG
d Map<String, Double>提升字段类型
Paimon 的 Schema Evolution 也同时支持数据类型的提升,如 Int 提升为 Long,Long提升为 Decimal 等;以上述表继续写入数据,假设新数据的 Schema 为:
a Long
b STRING
c Decimal
d Map<String, Double>操作完成后的表的 Schema 变更为:
a Long
b STRING
c Decimal
d Map<String, Double>强制类型转换
如以上示例所示,Paimon 支持数据字段类型的提升,如数值型向更高的精度提升(由 Int 提升至 Long,由 Long 提升至 Decimal),同时 Paimon 也支持一些类型之间的强制转换,如 String 强转成 Date 类型或者 Long 转换成 Int,但需要显式的配置参数 write.merge-schema.explicit-cast。
data.write
.format("paimon")
.mode("append")
.option("write.merge-schema", "true")
.option("write.merge-schema.explicit-cast", "true")
.save(location)假设原表的 Schema为:
a LONG
b STRING //内容为2023-08-01的格式新数据 data 的 Schema 为:
a INT
b DATE操作完成后的表的 Schema 变更为:
a INT
b DATE需要注意的是:
数据写入(追加或覆盖写)时的 Schema Evolution 不支持删除列和重命名列操作的,也不支持不在隐式/显式转换范围内的数据类型提升。当具体数值不能转换成目标类型时,为了避免将表数据破环,当前会报错,终止该操作。
Spark Structured Streaming
Spark Structured Streaming 是一个基于 Spark SQL 引擎构建的可扩展且容错的流处理引擎,可以像表达静态数据的批量计算一样的表达流计算。Spark SQL 引擎将负责增量且持续地运行它,并随着流数据不断到达而更新最终结果。Structured Streaming 支持流之间的聚合、事件时间窗口、流批之间 Join 等。Spark 通过 checkpointing 和 write-ahead logs 实现了端到端的 exactly-once。简而言之,Structured Streaming 提供快速、可扩展、容错、端到端的一次性流处理,而用户无需考虑流处理。
Paimon 在 0.5 和 0.6 两个版本逐步完善了 Spark Structured Streaming 的读写支持,提供了基于 Spark 引擎的流式读写能力。
■ Streaming Sink
Spark Structured Streaming 定义了三种输出模式(https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#basic-concepts),Paimon 仅支持 Append 模式和 Complete 模式。
// `df` is the upstream source data.
val stream = df
.writeStream
.outputMode("append")
.option("checkpointLocation", "/path/to/checkpoint")
.format("paimon")
.start("/path/to/paimon/sink/table")■ Streaming Source
结合 Spark 支持的多种 Trigger 策略 [1]和 Paimon 拓展的一些流式处理的能力,Paimon 可以支持丰富的 Streaming Source 的应用场景。
Paimon 提供了多样了 ScanMode,允许用户以合适的参数指定初始状态从 Paimon 表读取的数据。
ScanMode | 描述 |
latest | 仅读取后续持续写入的数据。 |
latest-full | 读取当前快照的数据,以及后续持续写入的数据。 |
from-timestamp | 读取参数 scan.timestamp-millis 指定的时间戳之后持续写入的数据。 |
from-snapshot | 读取参数 scan.snapshot-id 指定的版本后续持续写入的数据。 |
from-snapshot-full | 读取参数 scan.snapshot-id 指定的版本快照数据,以及后续持续写入的数据。 |
default | 默认等同于 latest-full 模式;如果指定 scan.snapshot-id,等同于 from-snapshot 模式;如果指定 scan.timestamp-millis,等同于 from-timestamp 模式; |
Paimon 通过拓展 SupportsAdmissionControl [2]接口,实现了 Source 端的流量控制,避免了由于要处理的单个 Batch 的数据量过大而引起的流式作业运行失败的问题。Paimon 目前支持以下ReadLimit [3]的实现。
Readlimit 参数 | 描述 |
read.stream.maxFilesPerTrigger | 一个 Batch 最多返回的Splits数 |
read.stream.maxBytesPerTrigger | 一个 Batch 最多返回的byte数 |
read.stream.maxRowsPerTrigger | 一个 Batch 最多返回的行数 |
read.stream.minRowsPerTrigger | 一个 Batch 最少返回的行数,和 maxTriggerDelayMs 搭配使用构成ReadMinRows [4] |
read.stream.maxTriggerDelayMs | 一个 Batch 触发的最大延时,和 minRowsPerTrigger 搭配使用构成ReadMinRows [4] |
以两个示例说明 Paimon Spark Structured Streaming 的用法。
示例一:
普通的流式增量 ETL 场景。
// Paimon source表的Schema为:time Long, stockId INT, avg_price DOUBLE
val query = spark.readStream
.format("paimon")
.option("scan.mode", "latest")
.load("/path/to/paimon/source/table")
.selectExpr("CAST(time AS timestamp) AS timestamp", "stockId", "price")
.withWatermark("timestamp", "10 seconds")
.groupBy(window($"timestamp", "5 seconds"), col("stockId"))
.writeStream
.format("console")
.trigger(Trigger.ProcessingTime(180, TimeUnit.SECONDS))
.start()该示例以 3 分钟的间隔流式读取 Paimon 后续的增量数据,进行 ETL 转化后同步到下游。
示例二:
适用于追补数据的场景,流式读取 Paimon 表自某个指定快照之后的数据,读取完成后不再读取后续写入的数据,同时限定了每个 Batch 大致的数据规模。
val query = spark.readStream
.format("paimon")
.option("scan.mode", "from-snapshot")
.option("scan.snapshot-id", 345)
.option("read.stream.maxBytesPerTrigger", "134217728")
.load("/path/to/paimon/source/table")
.writeStream
.format("console")
.trigger(Trigger.AvailableNow())
.start()示例代码中指定 Trigger.AvailableNow()触发器,表示仅读取流式任务启动时当前 Paimon 可用的数据;使用 from-snapshot 的 ScanMode 标识了读取快照 ID=345 之后写入的数据。在配置 maxBytesPerTrigger 等于 128MB 后,Spark Structured Streaming会将待消费的数据按照 128MB 的 Splits 大小进行 Batch 切分,由多个 Batch 完成当前快照数据的消费。
Spark SQL 拓展
■ Insert Overwrite
Insert Overwrite 是一个常用的 SQL 语法,用于重写整张表或者表中指定分区。该功能在 Paimon 新版本中也得到支持,包括了 static 和 dynamic 两种模式。
Static Overwrite
覆盖整张表:无论当前表是否是分区表,通过以下 SQL 可以完成使用新数据覆盖原表数据的操作。
在 Spark 环境下使用 Paimon,请参考这里 [5]。
USE paimon;
CREATE TABLE T (a INT, b STRING) TBLPROPERTIES('primary-key'='a');
INSERT OVERWRITE T VALUES (1, "a"), (2, "b");
----------
1 a
2 b
----------
INSERT OVERWRITE T VALUES (1, "a2"), (3, "c");
----------
1 a2
3 c
----------覆盖指定的表分区。
USE paimon;
CREATE TABLE T (dt STRING, a INT, b STRING)
TBLPROPERTIES('primary-key'='dt,a')
PARTITIONED BY(dt);
INSERT OVERWRITE T VALUES ("2023-10-01", 1, "a"), ("2023-10-02", 2, "b");
----------------
2023-10-01 1 a
2023-10-02 2 b
----------------
INSERT OVERWRITE T PARTITION (dt = "2023-10-02") VALUES (2, "b2"), (4, "d");
----------------
2023-10-01 1 a
2023-10-02 2 b2
2023-10-02 d 4
----------------Dynamic Parititon Overwrite(DPO)
默认情况下是在 Static 模式下执行 Insert Overwrite 的,用户需要显式的指定要覆盖的分区信息;我们可以通过参数启用 Dynamic 模式来执行 Insert Overwrite,这样Paimon 将自动判断 source 端数据所涉及到的分区来执行覆盖操作。
Paimon 启动 DPO 需要启动 spark session 时额外指定 paimon 的 extension:
--conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensionsUSE paimon;
CREATE TABLE T (dt STRING, a INT, b STRING)
TBLPROPERTIES('primary-key'='dt,a')
PARTITIONED BY(dt);
INSERT OVERWRITE T VALUES ("2023-10-01", 1, "a"), ("2023-10-02", 2, "b");
----------------
2023-10-01 1 a
2023-10-02 2 b
----------------
SET spark.sql.sources.partitionOverwriteMode=DYNAMIC;
INSERT OVERWRITE T VALUES ("2023-10-02", 2, "b2"), ("2023-10-02", 4, "d");
----------------
2023-10-01 1 a
2023-10-02 2 b2
2023-10-02 d 4
----------------在配置 spark.sql.sources.partitionOverwriteMode=DYNAMIC 后,不再需要指定要覆盖 dt="2023-10-02"的分区,实现了数据的动态覆盖。
■ Call procedure
除了由 Spark 框架提供了常用的 SQL 语法(包括 DDL,DML,Query 以及一些表信息查询)外,Paimon 还需要拓展一些额外的 SQL 语法来提供自定义功能的操作接口,便于用户对 Paimon 表的管理和探索。Call Procedure 的引入为这种场景的支持提供了框架层面的支持。
procedure 的语法:
CALL procedure_name(table => 'table_identifier', arg1 => '', ...);目前 Paimon 已经实现了三种 procedure:
Procedure | 描述 | 用法 |
create_tag | 为指定快照创建标签 | CALL create_tag(table => 'T', tag => 'test_tag', snapshot => 2) |
delete_tag | 删除已创建的标签 | CALL delete_tag(table => 'T', tag => 'test_tag') |
rollback | 回滚表到指定标签或者版本 | CALL rollback(table => 'T', version => '2') |
场景示例
以下构造一个流式开启 Schema Evolution 的示例,上游数据实时同步到 paimon 的 user 表(原表仅有 userId 和 name 两个维度),在某时刻上游数据添加了 age 属性,在无需停止作业运维时通过开启 Schema Evolution 自动完成元数据的合并和新数据的写入。
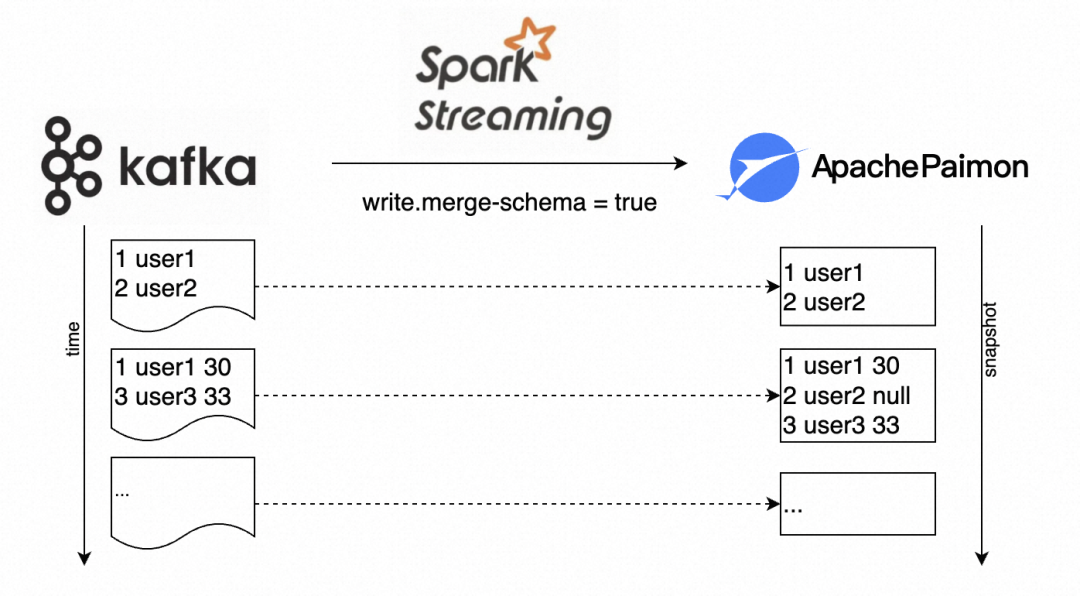
// 原表的定义
// CREATE TABLE T (userId INT, name STRING) TBLPROPERTIES ('primary-key'='userId');
// -- 假设原表的流式写入的数据--
// 1 user1
// 2 user2
// -------------------------
// 使用MemoryStream模拟上游streaming数据
val inputData = MemoryStream[(Int, String, Int)]
val stream = inputData
.toDS()
.toDF("userId", "name", "age")
.writeStream
.option("checkpointLocation", "/path/to/checkpoint")
.option("write.merge-schema", "true")
.format("paimon")
.start("/path/to/user_table")
inputData.addData((1, "user1", 30), (3, "user3", 33))
stream.processAllAvailable()
// -- 该batch数据写入后的表数据--
// 1 user1 30
// 2 user2 null
// 3 user3 33
// ---------------------------后续规划
Paimon 孵化于 Flink 社区,源于流式数仓,但其远不止于此。Paimon 将在与如 Apache Spark 这样的其他引擎的深度集成上,以及在如离线湖仓的场景支持上持续发力。在接下来的时间上,社区在和 Spark 引擎的支持上将逐渐拓展支持更多的 Spark SQL 语法,比如 Update、Merge Into 等;在读写性能上也会进行深层次优化。
参考
[1] Trigger 策略:
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#triggers
[2] SupportsAdmissionControl:
https://spark.apache.org/docs/3.2.1/api/java/org/apache/spark/sql/connector/read/streaming/SupportsAdmissionControl.html
[3] ReadLimit:
https://spark.apache.org/docs/3.2.1/api/java/org/apache/spark/sql/connector/read/streaming/ReadLimit.html
[4] ReadMinRows:
https://spark.apache.org/docs/3.2.1/api/java/org/apache/spark/sql/connector/read/streaming/ReadMinRows.html
[5] 在 Spark 环境下使用 Paimon:
https://paimon.apache.org/docs/master/engines/spark3/#setup
▼ 关注「Apache Spark 技术交流社区」,获取更多技术干货 ▼
 点击「阅读原文」,跳转 Apache Paimon 官网
点击「阅读原文」,跳转 Apache Paimon 官网
![[C/C++]数据结构 链表OJ题:环形链表(如何判断链表是否有环)](https://img-blog.csdnimg.cn/53d9b510d2b8465ebb55d4c7218d99ec.jpeg)