NodeJs - 单线程模型和高并发处理原理
- 前言
- 一. NodeJs 线程模型
- 1.1 NodeJs 模型分析
- 1.2 NodeJs处理事件请求的流程
- 1.3 NodeJs 和传统 Server 的对比
- 二. Cluster 模块利用多核CPU处理
- 三. 总结
前言
我们都知道JavaScript是单线程的处理。但是我们在Node开发、Egg开发下,我们的程序又能够处理高并发的请求。明明是单线程却能高并发处理,这是什么原理呢?我们本篇文章来探究一下。
一. NodeJs 线程模型
先分块解答一下 ”单线程“、 ”高并发“ 的含义:
- 单线程:
Node遵循的是单线程单进程的模式。单线程则指的是Js的引擎只有一个实例,它在NodeJs主线程中执行。但是它可以通过事件驱动的方式来处理异步IO操作。 - 那如何处理高并发的?
Node拥有一个主线程,但是它只负责任务的往返调度,并不会真正执行用户请求等IO操作。而所有的IO操作则交给内部的work线程池去实现。
1.1 NodeJs 模型分析
我们看一下下面一张图:
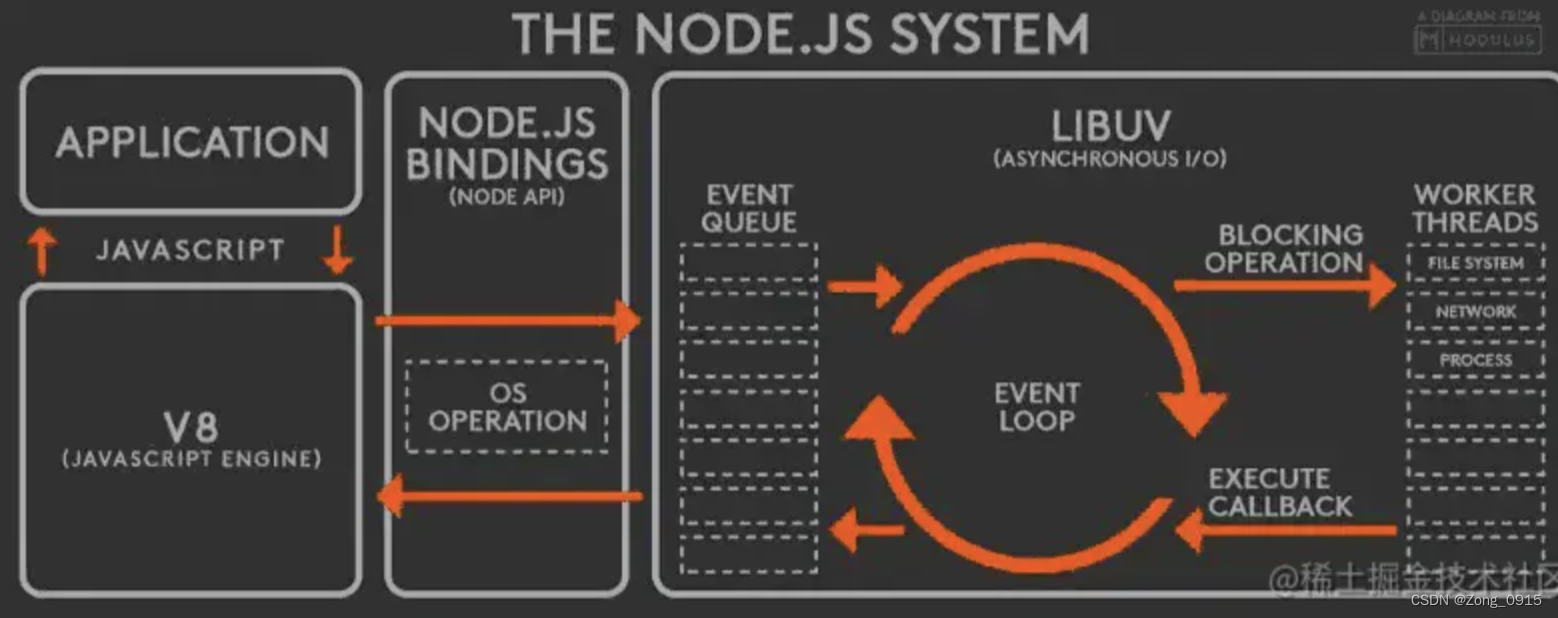
首先我们从上图中,将Node模型分成4个功能模块:
Application:应用层。即JS的交互层,例如NodeJs中的模块:http、fs等。V8引擎层:解析JS语法,和下层API进行交互。NodeAPI层:为上层模块系统提供系统调用、底层则和操作系统进行交互。LIBUV层:一种跨平台的底层封装。实现事件循环、文件操作等功能,是Node里面实现异步的核心模块。
再来讲一下和上图有关的几个基本概念:
- 事件循环:事件循环是一种编程构造,用于等待和分派程序中的事件或消息。主线程从 事件队列中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为
Event Loop(事件循环) - 事件队列(任务队列):当用户的网络请求或者其它的异步操作到来时,
node都会把它放到Event Queue之中,此时并不会立即执行它,代码也不会被阻塞,继续往下走,直到主线程代码执行完毕。 - 事件驱动:实质是通过主循环加事件触发方式运行程序。
Node.js 不是一门语言也不是框架,它只是基于 Google V8 引擎的 JS 运行时环境,是对 JS 功能的拓展。提供了网络、文件、dns 解析、进程线程等功能。
1.2 NodeJs处理事件请求的流程
结合上文的几个相关概念,流程如下:
Node主线程接收到了用户的网络请求,会把它丢到Event Queue(事件队列)中,并不会立即执行它。主线程不会阻塞。Node主线程代码执行完毕,通过Event Loop(事件循环),每次循环都取出队列中的第一个事件,把它丢给LIBUV库的线程池中的线程让它执行,我们这里就叫libuv线程。备注:这个过程中,一旦有新的事件加入到队列中,都会通知主线程去按顺序取出来处理。- 而
libuv线程池的维护则是由底层的LIBUV来完成维护。默认打开4个,最多拥有128个线程。 - 当事件执行完毕,就会通知主线程,主线程执行回调拿到结果,
libuv线程则归还给线程池,等待下一次调度。
因此对于Node而言,主线程执行JS,这个过程是单线程的。但是可以同时处理大量的IO事件(底层的libuv线程池来完成),非常适合IO密集型的任务处理。相反,若主线程JS进行了CPU密集型,那性能就会非常差,导致长时间的阻塞。
1.3 NodeJs 和传统 Server 的对比
| 对比项 | NodeJs | 传统Server |
|---|---|---|
| 高并发处理 | NodeJs只有一个主线程(单线程),但是可以通过底层的LIBUV库中维护的libuv线程池处理高并发请求 | 每个请求都会生成一个线程 |
| 内存消耗 | 由于1000个请求是丢到队列当中(并不是立马执行的),排队等待最多128个libuv线程去处理。内存消耗小得多,时间换空间。 | 假设1个进程需要1M内存,为了能同时处理1000个请求,就可能需要1G左右的内存 |
| 上下文切换 | 由于单线程,不需要切换 | 例如Java,线程之间需要进行上下文的切换 |
这么看下来,NodeJs 更像是 ”非阻塞“ 而不是并发。
- 再多的请求都是丢到队列,主线程不会受到阻塞。
- 主线程通过回调机制来拿到结果,只负责不断的往返调度,从而实现异步非阻塞
IO。
但是,在我们知道 JavaScript 代码是运行在单线程上后,即一个 Node.js 进程只能运行在一个 CPU 上,那是不是就无法利用到多核运算的好处了?
并不是,NodeJs 官方提供了一种解决方案:cluster 模块。
二. Cluster 模块利用多核CPU处理
官网当中提供了一段简介:
- 单个
Node.js实例在单线程环境下运行。为了更好地利用多核环境,用户有时希望启动一批Node.js进程用于加载。 - 集群化模块使得你很方便地创建子进程,以便于在服务端口之间共享。说白了就是多个子进程共享一个端口。
而Cluster简单的说就是:
- 可以在服务器上同时启动多个进程。
- 这些进程同时监听同一个端口。跑的也是同一份源代码。
- 有一个专门负责启动其他进程的
Master进程(包工头),它只负责启动其他进程。 - 而被启动的线程则叫做
Worker进程,是真正干活的工人。接收请求,提供对外服务。而启动的Worker进程数量一般由服务器的CPU核数来决定。
即前面的小章节,都是建立在单个Worker的基础上来完成的。每个Worker都有属于他自己的一套事件队列以及底层的LIBUV库线程池。
现在有两个问题:
Cluster是如何做到多个进程共享同一个端口的?Master是如何将接收到的请求传递给worker然后去执行的?
源码的详解可以参考:源码解析
原理如下:
- 主线程负责监听指定的端口,并接收来自客户端的请求。
- 主线程接收到请求后,将请求通过轮询负载均衡的方式丢给可用的
Worker进程来处理。 - 主进程和
Worker进程之间通过IPC(进程间通信)来传递连接和其他信息。主进程将接收到的连接分配给Worker进程,并将连接的套接字(socket)传递给对应的Worker进程。Worker进程接收到连接后,可以像单个Node.js应用程序一样处理连接。执行完业务逻辑处理之后,返回。 - 通过这种方式,多个
Worker进程可以共享同一个端口,并且能够处理并发的连接请求。
三. 总结
总结下NodeJs的单线程模型和高并发处理原理,假设我们有一台4核CPU的机器。
NodeJs会创建出一个Master进程,它负责创建Worker进程,数量一般会和服务器的核数一致,也就是4个Worker进程。- 外部的用户请求到服务器,会由
Master进程进行轮询负载均衡丢给Worker进程来处理。 - 同时
Master会通过IPC通信,传递相关的信息给Worker进程,让他们能够正确地处理用户请求。
这里是nodejs对多核服务的一个利用机制。每个CPU同一时间可以处理一个用户请求。
那再说一下单个Worker进程的处理:
Worker进程开始处理当前用户请求。这个请求过程中遇到的任何一个IO请求(事件),统一丢给Event Queue事件队列中,而非立即执行。- 主线程(
JS单线程)处理完毕之后(即你的代码已经跑完了,但是期间涉及到的异步任务还没执行完毕),会进行事件循环,不断地访问事件队列中的队列,依次取出,将它丢给LIBUV库中维护的线程池。 - 最终的异步任务则由底层的线程池来完成,完成好后通知给主线程,主线程通过回调机制拿到结果。
- 从而实现了主线程的非阻塞异步
IO。