java springBoot js 大文件上传分片上传 断点续传 秒传
文件上传在项目开发中再常见不过了,大多项目都会涉及到图片、音频、视频、文件的上传,通常简单的一个Form表单就可以上传小文件了,但是遇到大文件时比如1GB以上,或者用户网络比较慢时,简单的文件上传就不能适用了,会出现以下隐患或问题
1、网络传输速度慢
上传时间长,大文件完整上传需要占用持续稳定的上行带宽,如果网络条件不好,上传会非常慢,损耗用户体验。
2、中间失败需重新上传
上传过程中如果由于网络等原因发生中断,整个传输会失败。这就需要用户重新再上传一遍完整文件,重复劳动。
3、服务器压力大
服务端需要占用较多资源持续处理一个大文件,对服务器性能压力较大,可能影响到其他服务。
4、流量资源浪费
一次完整上传大文件,如果遇到已经存在相同文件,会重复消耗大量网络流量,是数据浪费。
5、难以实现上传进度提示
用户无法感知上传进度,如果上传失败也不知道已经上传了多少数据。
所以为了解决以上这些问题,使用分片、断点续传等技术就非常重要。它可以分批次上传数据块,避免一次性全量上传的弊端。同时结合校验、记录已上传分片等手段,可以使整个上传过程可控、可恢复、节省流量,大幅提升传输效率。
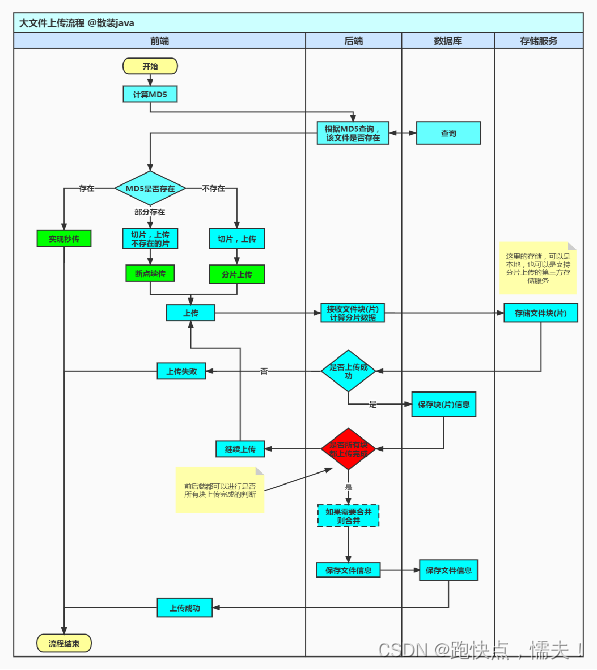
大文件上传主要是借助于分治思想(任务分解法)实现,将大文件分解为多个易处理的小文件,并循环递归的上传小文件,最后把子问题的结果合并为原始问题的结果。

小文件上传
文件小传非常的简单,本项目后端我们使用SrpingBoot 3.1.2 + JDK17,前端我们使用原生的JavaScript+spark-md5.min.js实现。
项目引入
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.3</version>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
后端代码
public static final String UPLOAD_PATH = "D:\\upload\\";
/**
* 小文件上传
* @param file
* @return
* @throws IOException
*/
@PostMapping(value = "/upload", consumes = "multipart/form-data")
public ResponseEntity<Map<String, String>> upload(@RequestParam MultipartFile file) throws IOException {
File dstFile = new File(UPLOAD_PATH, String.format("%s.%s", UUID.randomUUID(), StringUtils.getFilename(file.getOriginalFilename())));
file.transferTo(dstFile);
Map result = new HashMap();
result.put("path", dstFile.getAbsolutePath());
return ResponseEntity.ok(result);
}
前端代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>upload</title>
<script src="https://cdn.bootcdn.net/ajax/libs/spark-md5/3.0.2/spark-md5.min.js"></script>
</head>
<body>
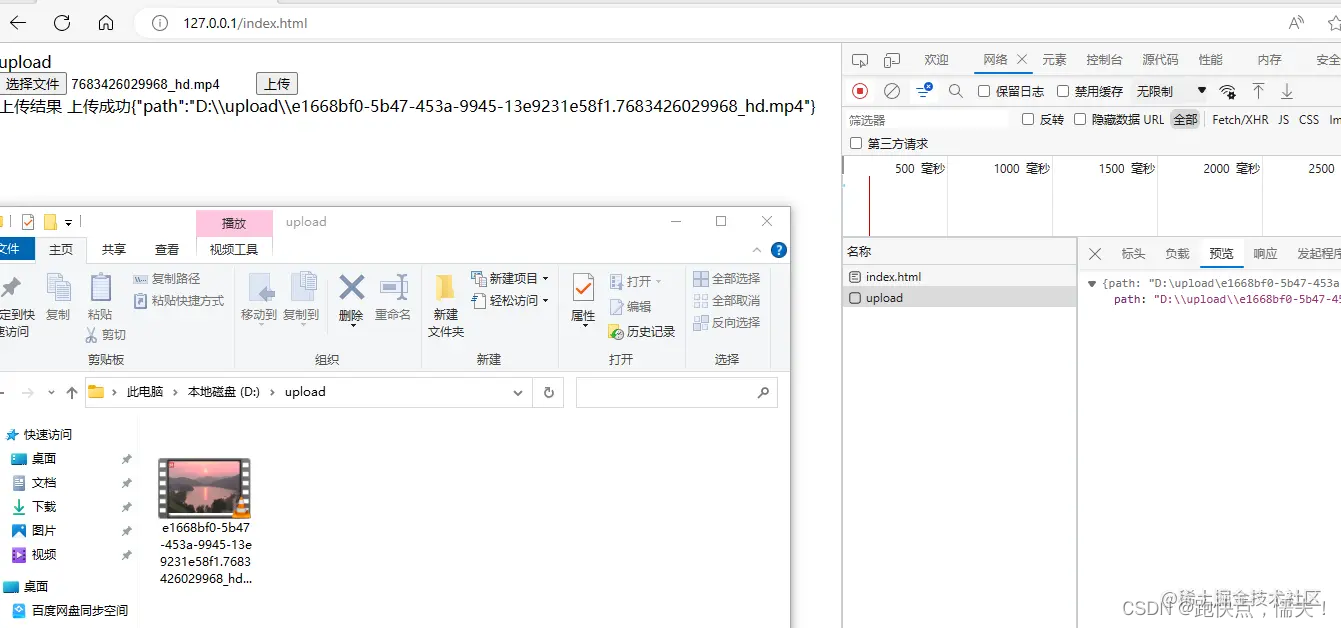
upload
<form enctype="multipart/form-data">
<input type="file" name="fileInput" id="fileInput">
<input type="button" value="上传" onclick="uploadFile()">
</form>
上传结果
<span id="uploadResult"></span>
<script>
var uploadResult=document.getElementById("uploadResult")
function uploadFile() {
var fileInput = document.getElementById('fileInput');
var file = fileInput.files[0];
if (!file) return; // 没有选择文件
var xhr = new XMLHttpRequest();
// 处理上传进度
xhr.upload.onprogress = function(event) {
var percent = 100 * event.loaded / event.total;
uploadResult.innerHTML='上传进度:' + percent + '%';
};
// 当上传完成时调用
xhr.onload = function() {
if (xhr.status === 200) {
uploadResult.innerHTML='上传成功'+ xhr.responseText;
}
}
xhr.onerror = function() {
uploadResult.innerHTML='上传失败';
}
// 发送请求
xhr.open('POST', 'http://localhost:8080/demo/api/upload', true);
var formData = new FormData();
formData.append('file', file);
xhr.send(formData);
}
</script>
</body>
</html>
注意事项
在上传过程会报文件大小限制错误,主要有三个参数需要设置:
server:
port: 8080
servlet:
context-path: /demo
spring:
servlet:
multipart:
max-file-size: 1024MB
max-request-size: 1024MB
大文件分片上传
如何实现分片上传?
1、分片上传的目的是将大文件切割为多个小块,实现并发上传以提高传输速度。
2、分片上传可以按配置的分片大小(例如1M一个分片)将大文件分割。
3、前端项目将切割的每个分片按顺序上传至后端服务器。
4、后端收到分片后可以暂存于本地,并记录这个分片的特征信息,如分片序号、文件MD5等,写入到数据库。
5、全部分片上传完成后,后端按序号顺序重新组装成原完整文件。
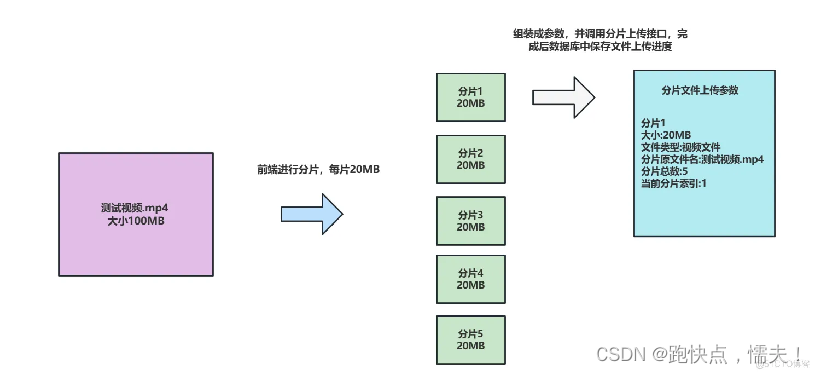
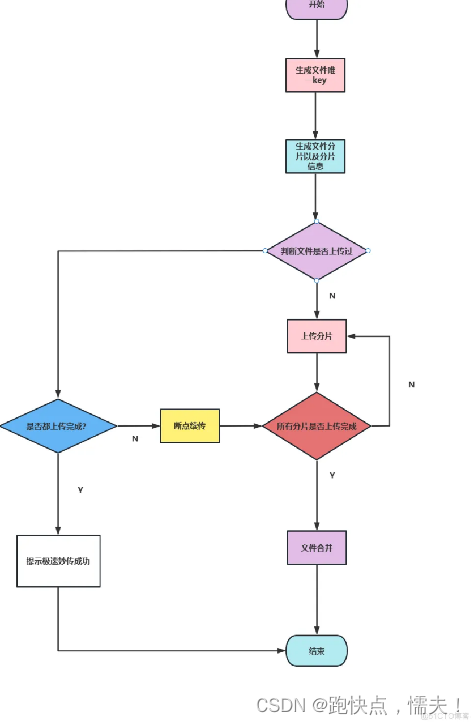
前端
大文件分片上传前端主要有三步:
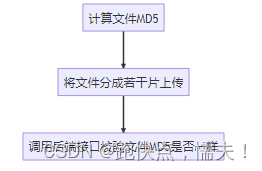
前端上传代码计算文件MD5值用了spark-md5这个库,使用也是比较简单的。这里为什么要计算MD5简单说一下,因为文件在传输写入过程中可能会出现错误,导致最终合成的文件可能和原文件不一样,所以要对比一下前端计算的MD5和后端计算的MD5是不是一样,保证上传数据的一致性。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>upload</title>
<script src="https://cdn.bootcdn.net/ajax/libs/spark-md5/3.0.2/spark-md5.min.js"></script>
</head>
<body>
upload
上传结果
<span id="uploadResult"></span>
分片上传
<form enctype="multipart/form-data">
<input type="file" name="fileInput" id="bigFileInput">
<input type="button" value="计算文件MD5" onclick="calculateFileMD5()">
<input type="button" value="上传" onclick="uploadBigFile()">
<input type="button" value="检测文件完整性" onclick="checkFile()">
</form>
<p>
文件MD5:
<span id="fileMd5"></span>
</p>
<p>
上传结果:
<span id="bigUploadResult"></span>
</p>
<p>
检测文件完整性:
<span id="checkFileRes"></span>
</p>
<script>
//每片的大小
var chunkSize = 1 * 1024 * 1024;
var bigUploadResult = document.getElementById("bigUploadResult")
var fileMd5Span = document.getElementById("fileMd5")
var checkFileRes = document.getElementById("checkFileRes")
var fileMd5;
function calculateFileMD5(){
var fileInput = document.getElementById('bigFileInput');
var file = fileInput.files[0];
getFileMd5(file).then((md5) => {
console.info(md5)
fileMd5=md5;
fileMd5Span.innerHTML=md5;
})
}
function uploadBigFile() {
var fileInput = document.getElementById('bigFileInput');
var file = fileInput.files[0];
if (!file) return;
if (!fileMd5) return;
//获取到文件
let fileArr = this.sliceFile(file);
//保存文件名称
let fileName = file.name;
let start = new Date();
fileArr.forEach((e, i) => {
//创建formdata对象
let data = new FormData();
data.append("totalNumber", fileArr.length)
data.append("chunkSize", chunkSize)
data.append("chunkNumber", i)
data.append("md5", fileMd5)
data.append("file", new File([e],fileName));
upload(data);
})
let end = new Date();
console.log(end - start);
}
/**
* 计算文件md5值
*/
function getFileMd5(file) {
return new Promise((resolve, reject) => {
let fileReader = new FileReader()
fileReader.onload = function (event) {
let fileMd5 = SparkMD5.ArrayBuffer.hash(event.target.result)
resolve(fileMd5)
}
fileReader.readAsArrayBuffer(file)
})
}
function upload(data) {
var xhr = new XMLHttpRequest();
// 当上传完成时调用
xhr.onload = function () {
if (xhr.status === 200) {
bigUploadResult.append( '上传成功分片:' +data.get("chunkNumber")+'\t' ) ;
}
if (xhr.status === 1000) {
bigUploadResult.append( '分片已存在:秒传成功!' +data.get("chunkNumber")+'\t' ) ;
}
}
xhr.onerror = function () {
bigUploadResult.innerHTML = '上传失败';
}
// 发送请求
xhr.open('POST', 'http://localhost:8080/demo/api/uploadBig', true);
xhr.send(data);
}
function checkFile() {
var xhr = new XMLHttpRequest();
// 当上传完成时调用
xhr.onload = function () {
if (xhr.status === 200) {
checkFileRes.innerHTML = '检测文件完整性成功:' + xhr.responseText;
}
}
xhr.onerror = function () {
checkFileRes.innerHTML = '检测文件完整性失败';
}
// 发送请求
xhr.open('POST', 'http://localhost:8080/demo/api/checkFile', true);
let data = new FormData();
data.append("md5", fileMd5)
xhr.send(data);
}
function sliceFile(file) {
const chunks = [];
let start = 0;
let end;
while (start < file.size) {
end = Math.min(start + chunkSize, file.size);
chunks.push(file.slice(start, end));
start = end;
}
return chunks;
}
</script>
</body>
</html>
前端注意事项
- 前端调用uploadBig接口有四个参数:
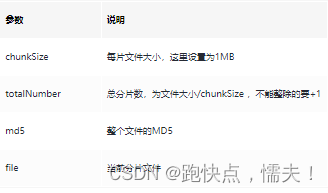
- 计算大文件的MD5可能会比较慢,这个可以从流程上进行优化,比如上传使用异步去计算文件MD5、不计算整个文件MD5而是计算每一片的MD5保证每一片数据的一致性。
后端
后端就两个接口/uploadBig用于每一片文件的上传和/checkFile检测文件的MD5。
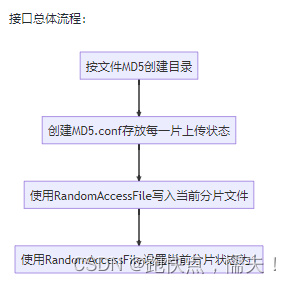
/uploadBig接口总体流程:
这里需要注意的:
- MD5.conf每一次检测文件不存在里创建个空文件,使用byte[] bytes = new byte[totalNumber];将每一位状态设置为0,从0位天始,第N位表示第N个分片的上传状态,0-未上传 1-已上传,当每将上传成功后使用randomAccessConfFile.seek(chunkNumber)将对就设置为1。
- randomAccessFile.seek(chunkNumber * chunkSize);可以将光标移到文件指定位置开始写数据,每一个文件每将上传分片编号chunkNumber都是不一样的,所以各自写自己文件块,多线程写同一个文件不会出现线程安全问题。
- 大文件写入时用RandomAccessFile可能比较慢,可以使用MappedByteBuffer内存映射来加速大文件写入,不过使用MappedByteBuffer如果要删除文件可能会存在删除不掉,因为删除了磁盘上的文件,内存的文件还是存在的。
/checkFile接口设计思路
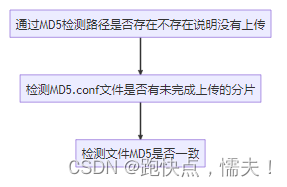
@RestController
public class UploadController {
public static final String UPLOAD_PATH = "D:\\upload\\";
/**
* @param chunkSize 每个分片大小
* @param chunkNumber 当前分片
* @param md5 文件总MD5
* @param file 当前分片文件数据
* @return
* @throws IOException
*/
@RequestMapping("/uploadBig")
public ResponseEntity<Map<String, String>> uploadBig(@RequestParam Long chunkSize, @RequestParam Integer totalNumber, @RequestParam Long chunkNumber, @RequestParam String md5, @RequestParam MultipartFile file) throws IOException {
//文件存放位置
String dstFile = String.format("%s\\%s\\%s.%s", UPLOAD_PATH, md5, md5, StringUtils.getFilenameExtension(file.getOriginalFilename()));
//上传分片信息存放位置
String confFile = String.format("%s\\%s\\%s.conf", UPLOAD_PATH, md5, md5);
//第一次创建分片记录文件
//创建目录
File dir = new File(dstFile).getParentFile();
if (!dir.exists()) {
dir.mkdir();
//所有分片状态设置为0
byte[] bytes = new byte[totalNumber];
Files.write(Path.of(confFile), bytes);
}
//随机分片写入文件
try (RandomAccessFile randomAccessFile = new RandomAccessFile(dstFile, "rw");
RandomAccessFile randomAccessConfFile = new RandomAccessFile(confFile, "rw");
InputStream inputStream = file.getInputStream()) {
//定位到该分片的偏移量
randomAccessFile.seek(chunkNumber * chunkSize);
//写入该分片数据
randomAccessFile.write(inputStream.readAllBytes());
//定位到当前分片状态位置
randomAccessConfFile.seek(chunkNumber);
//设置当前分片上传状态为1
randomAccessConfFile.write(1);
}
return ResponseEntity.ok(Map.of("path", dstFile));
}
/**
* 获取文件分片状态,检测文件MD5合法性
*
* @param md5
* @return
* @throws Exception
*/
@RequestMapping("/checkFile")
public ResponseEntity<Map<String, String>> uploadBig(@RequestParam String md5) throws Exception {
String uploadPath = String.format("%s\\%s\\%s.conf", UPLOAD_PATH, md5, md5);
Path path = Path.of(uploadPath);
//MD5目录不存在文件从未上传过
if (!Files.exists(path.getParent())) {
return ResponseEntity.ok(Map.of("msg", "文件未上传"));
}
//判断文件是否上传成功
StringBuilder stringBuilder = new StringBuilder();
byte[] bytes = Files.readAllBytes(path);
for (byte b : bytes) {
stringBuilder.append(String.valueOf(b));
}
//所有分片上传完成计算文件MD5
if (!stringBuilder.toString().contains("0")) {
File file = new File(String.format("%s\\%s\\", UPLOAD_PATH, md5));
File[] files = file.listFiles();
String filePath = "";
for (File f : files) {
//计算文件MD5是否相等
if (!f.getName().contains("conf")) {
filePath = f.getAbsolutePath();
try (InputStream inputStream = new FileInputStream(f)) {
String md5pwd = DigestUtils.md5DigestAsHex(inputStream);
if (!md5pwd.equalsIgnoreCase(md5)) {
return ResponseEntity.ok(Map.of("msg", "文件上传失败"));
}
}
}
}
return ResponseEntity.ok(Map.of("path", filePath));
} else {
//文件未上传完成,反回每个分片状态,前端将未上传的分片继续上传
return ResponseEntity.ok(Map.of("chucks", stringBuilder.toString()));
}
}
}
配合前端上传演示分片上传,依次按如下流程点击按钮:
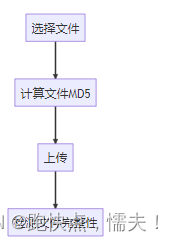
效果

断点续传
如何实现断点续传?
1、前端在上传文件时,将文件切成多个小块,每次上传一个小块。
2、每上传一个小块,后端会记录这个小块的信息,比如该小块的序号、文件MD5、内容Hash等。可以保存在MySQL数据库中。
3、如果上传中断了,前端可以向后端询问已经上传了哪些小块。
4、后端从数据库中查询,返回已上传小块的信息给前端。
5、前端就可以接着只上传中间中断的那一部分小块。
6、后端会根据小块的序号、文件MD5来把这些小块重新拼接成完整的文件。
7、以后如果这个文件再次上传,通过MD5值就可以知道该文件已经存在了,则直接返回上传成功,无需上传实际内容。这样通过切片上传和持久化记录已上传切片的信息,就可以实现断点续传。
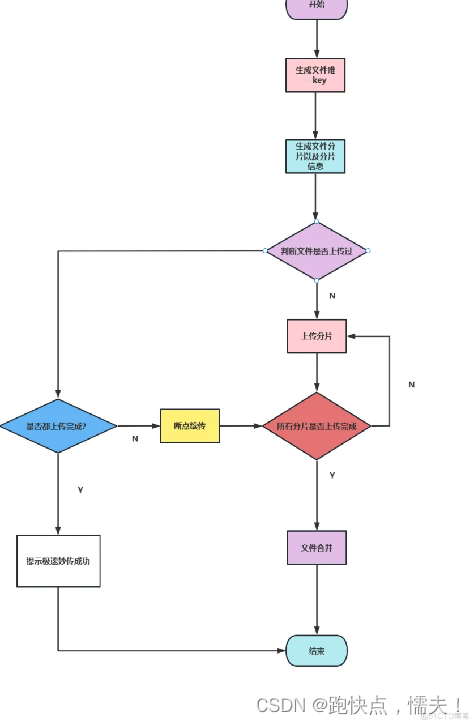
有了上面的设计做断点续传就比较简单的,后端代码不需要改变,只要修改前端上传流程就好了:
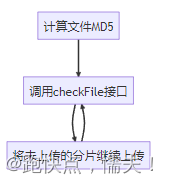
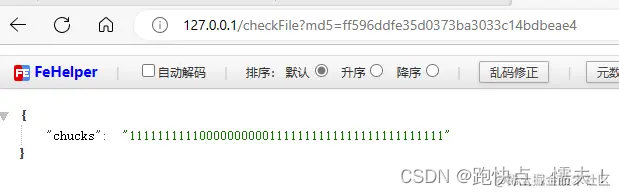
用/checkFile接口,文件里如果有未完成上传的分片,接口返回chunks字段对就的位置值为0,前端将未上传的分片继续上传,完成后再调用/checkFile就完成了断点续传
秒传
如何实现秒传?
1、前端在上传文件时,先计算该文件的MD5值,然后将MD5值发送到后端服务器。
2、后端服务器收到MD5值后,查询MySQL数据库,检查是否已存在相同MD5值的文件。
3、如果存在,表示该文件已上传过,服务器直接从数据库查询到该文件存在哪些分片,并返回给客户端。
4、客户端拿到文件分片信息后,会直接组装完整的文件,而不再上传实际文件内容。
5、如果数据库不存在该MD5值,表示文件未上传过,服务器会返回需要客户端上传整个文件。
6、客户端上传完文件后,服务器才会在MySQL数据库中新增该文件与MD5的对应关系,以及存储文件分片信息。
7、下次再上传同样文件时,通过MD5值就可以实现秒传了
秒传也是比较简单的,只要修改前端代码流程就好了,比如张三上传了一个文件,然后李四又上传了同样内容的文件,同一文件的MD5值可以认为是一样的(虽然会存在不同文件的MD5一样,不过概率很小,可以认为MD5一样文件就是一样),10万不同文件MD5相同概率为110000000000000000000000000000\frac{1}{10000000000000000000000000000}100000000000000000000000000001,福利彩票的中头奖的概率一般为11000000\frac{1}{1000000}10000001 ,具体计算方法可以参考走近消息摘要–Md5产生重复的概率,,所以MD5冲突的概率可以忽略不计。当李四调用/checkFile接口后,后端直接返回了李四上传的文件路径,李四就完成了秒传。大部分云盘秒传的思路应该也是这样,只不过计算文件HASH算法更为复杂,返回给用户文件路径也更为安全,要防止被别人算出文件路径了。
秒传前端代码流程:
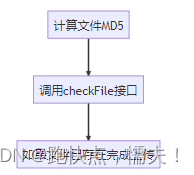
总体设计思路
页面访问 http://localhost:8080/demo/index.html 即可


![用友NC Cloud accept.jsp接口任意文件上传漏洞复现 [附POC]](https://img-blog.csdnimg.cn/bee64cf481f64a7e937200eaf7e2e74f.png)