文章目录
- 一、窗口函数概述
- 1、什么是窗口函数
- 2、窗口函数有哪些
- (1)聚合函数(聚合函数不是本文讨论的重点)
- (2)专用窗口函数
- 3、基本语法
- 4、测试数据准备
- 二、窗口函数使用
- 1、初识窗口函数:使用聚合函数
- 2、序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
- 3、分布函数:PERCENT_RANK()、CUME_DIST()
- 4、前后函数
- 5、头尾函数:FIRST_VALUE()、LAST_VALUE()
- 6、其他函数:NTH_VALUE()、NTILE()
- 三、窗口函数的命名
- 1、语法格式
- 2、使用示例
- 四、窗口函数框架
- 参考资料
一、窗口函数概述
1、什么是窗口函数
MySQL从8.0开始支持窗口函数,有的也叫分析函数(处理相对复杂的报表统计分析场景),这个功能在大多商业数据库和部分开源数据库中早已支持。
窗口的意思是将数据进行分组,每个分组即是一个窗口,这和使用聚合函数时的group by分组类似,但与聚合函数不同的地方是:
聚合函数(例如:sum/avg/min/max)会针对每个分组(窗口)聚合出一个结果(每一组返回一个结果)。
窗口函数会对每一条数据进行计算,并不会使返回的数据变少(每一行返回一个结果)。
2、窗口函数有哪些
窗口函数可以分为两类:
一类既可以做为聚合函数,也可以作为窗口函数,当函数单独使用时是聚合函数,当与over关键字同时使用时作为窗口函数。
另一类是专用窗口函数,他们必须与 over 关键字同时使用。
(1)聚合函数(聚合函数不是本文讨论的重点)
MySQL聚合函数详解——让查询变得很简单
- AVG() 返回自变量的平均值
- BIT_AND() 返回按位AND
- BIT_OR() 返回按位或
- BIT_XOR() 返回按位异或
- COUNT() 返回返回的行数的计数
- COUNT(DISTINCT) 返回多个不同值的计数
- GROUP_CONCAT() 返回串联的字符串
- JSON_ARRAYAGG() 将结果集作为单个JSON数组返回
- JSON_OBJECTAGG() 将结果集作为单个JSON对象返回
- MAX() 返回最大值
- MIN() 返回最小值
- STD() 返回总体标准差
- STDDEV() 返回总体标准差
- STDDEV_POP() 返回总体标准差
- STDDEV_SAMP() 返回样本标准偏差
- SUM() 归还总数
- VAR_POP() 返回总体标准方差
- VAR_SAMP() 返回样本方差
- VARIANCE() 返回总体标准方差
(2)专用窗口函数
序号函数:
- row_number() 顺序排序:对数据中的序号进行顺序显示,不管其排序结果是否出现重复值,排序结果为1,2,3,4,5…
- rank() 并列排序:相同字段数值并列排序,且跳过重复序号,如, 1,1,3,4,5 。rank函数没有参数,但需要指定按照那个字段进行排名,所以使用rank函数必须用order by参数,order by的排序字段就是排名字段
- dense_rank() 并列排序:相同字段数值并列排序,且不跳过重复序号,如:1,1,2,3,4
分布函数:
- percent_rank()
累计百分比。函数计算结果为:小于该条记录值的所有记录的行数/该分组的总行数-1,所以该记录的返回值为[0,1]。和之前的RANK()函数相关,每行按照如下公式进行计算: (rank - 1) / (rows - 1) 其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数。 - cume_dist()
累计分布值。分组值小于等于当前值的行数与分组总行数的比值 ,(0,1]。 分组内大于等于当前rank值的行数/分组内总行数。(常用)
前后函数:
- lag(expr,n) 返回当前行的前n行的expr的值
- lead(expr,n) 返回当前行的后n行的expr的值
头尾函数:
- first_value(expr) 返回第一个expr的值
- last_value(expr) 返回最后一个expr的值
其他函数:
- nth_value(expr,n) 返回第n个expr的值
- ntile(n) 将分区中的有序数据分为n个桶,记录桶的编号
3、基本语法
select 窗口函数 over (partition by 用于分组的列名, order by 用于排序的列名)
函数名([expr]) over(partition by <要分列的组> order by <要排序的列> rows between <数据范围>)
4、测试数据准备
CREATE TABLE `student` (
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '姓名',
`course` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '课程',
`score` int DEFAULT NULL COMMENT '分数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('张三', '语文', 90);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('张三', '数学', 80);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('张三', '英语', 80);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('张三', '历史', 85);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('张三', '物理', 86);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('张三', '化学', 88);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('李四', '语文', 90);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('李四', '数学', 88);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('李四', '英语', 85);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('李四', '历史', 82);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('李四', '物理', 70);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('李四', '化学', 75);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('王五', '语文', 88);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('王五', '数学', 88);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('王五', '英语', 83);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('王五', '历史', 83);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('王五', '物理', 80);
INSERT INTO `athena_opencourse`.`student`(`name`, `course`, `score`) VALUES ('王五', '化学', 82);
二、窗口函数使用
1、初识窗口函数:使用聚合函数
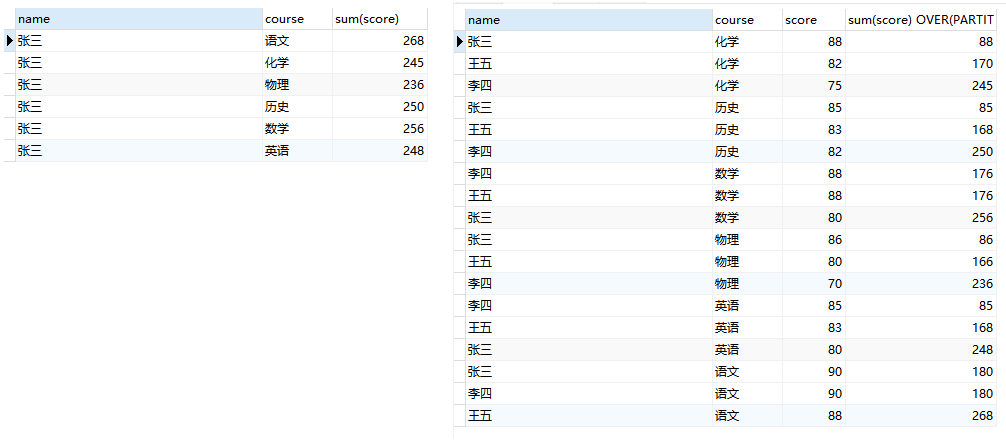
通常来说,我们写一个聚合函数,会将分组内的数据进行聚合,形成一行。而窗口操作不会将多组查询行折叠成单个输出行。相反,它们为每一行产生一个结果:
SELECT
name,
course,
sum(score)
FROM
student
group by course order by score desc;
SELECT
name,
course,
score,
sum(score) OVER(PARTITION BY course ORDER BY score desc)
FROM
student
;
由结果我们可以看出,窗口函数会逐行渲染数据,每一行数据不会合并,而是一行一行的累加:
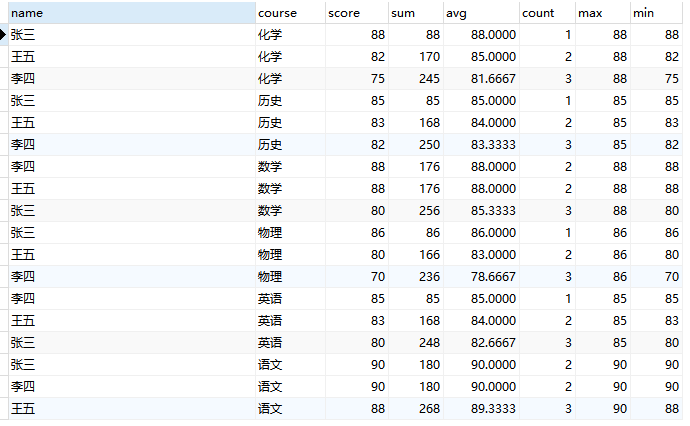
SELECT
name,
course,
score,
sum(score) OVER w 'sum',
avg(score) OVER w 'avg',
count(score) OVER w 'count',
max(score) OVER w 'max',
min(score) OVER w 'min'
FROM
student
window w AS (PARTITION BY course ORDER BY score desc)
;
2、序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
序号函数中,ORDER BY影响行的编号顺序。没有ORDER BY,行编号是不确定的。
- row_number() 顺序排序:对数据中的序号进行顺序显示,不管其排序结果是否出现重复值,排序结果为1,2,3,4,5…
- rank() 并列排序:相同字段数值并列排序,且跳过重复序号,如, 1,1,3,4,5 。rank函数没有参数,但需要指定按照那个字段进行排名,所以使用rank函数必须用order by参数,order by的排序字段就是排名字段
- dense_rank() 并列排序:相同字段数值并列排序,且不跳过重复序号,如:1,1,2,3,4
SELECT
name,
course,
score,
ROW_NUMBER() OVER(partition by course order by score desc) AS 'row_number',
RANK() OVER(partition by course order by score desc) AS 'rank',
DENSE_RANK() OVER(partition by course order by score desc) AS 'dense_rank'
FROM
student;
根据结果我们很明显的可以看出这三个函数的区别,虽然都是用于产生序号,用法稍微有一些区别。
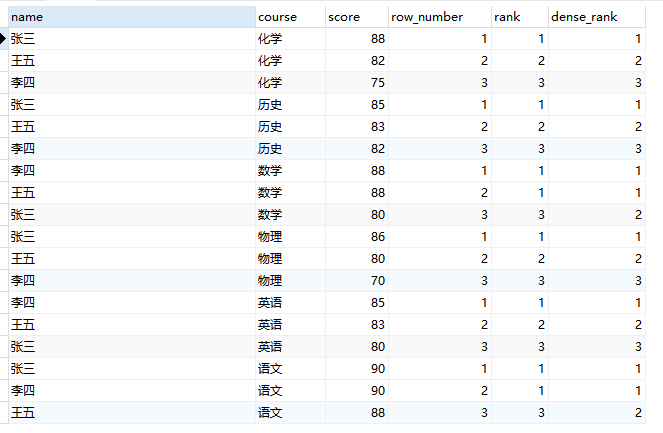
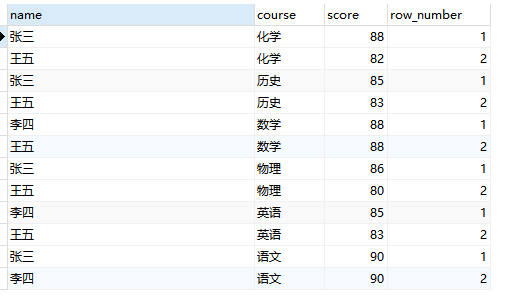
通过使用序号函数,我们可以很轻松的获取分组内前几条数据:
select * from (
SELECT
name,
course,
score,
ROW_NUMBER() OVER(partition by course order by score desc) AS 'row_number'
FROM
student) tmp
where tmp.row_number < 3;
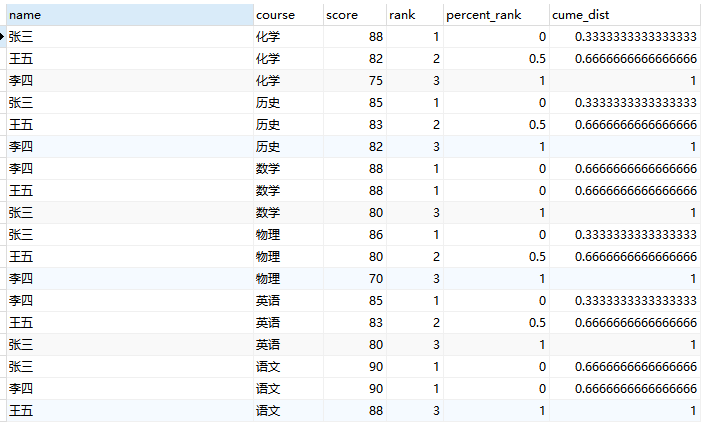
3、分布函数:PERCENT_RANK()、CUME_DIST()
- percent_rank()
累计百分比。函数计算结果为:小于该条记录值的所有记录的行数/该分组的总行数-1,所以该记录的返回值为[0,1]。和之前的RANK()函数相关,每行按照如下公式进行计算: (rank - 1) / (rows - 1) 其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数。 - cume_dist()
累计分布值。分组值小于等于当前值的行数与分组总行数的比值 ,(0,1]。 分组内大于等于当前rank值的行数/分组内总行数。(常用)
SELECT
name,
course,
score,
RANK() OVER(partition by course order by score desc) AS 'rank',
PERCENT_RANK() OVER(partition by course order by score desc) AS 'percent_rank' ,
CUME_DIST() OVER(partition by course order by score desc) AS 'cume_dist'
FROM
student;
由结果我们可以看出,PERCENT_RANK就是统计小于该值的比例,也就是排名的百分比。CUME_DIST()函数主要用于查询小于或等于该值的比例。
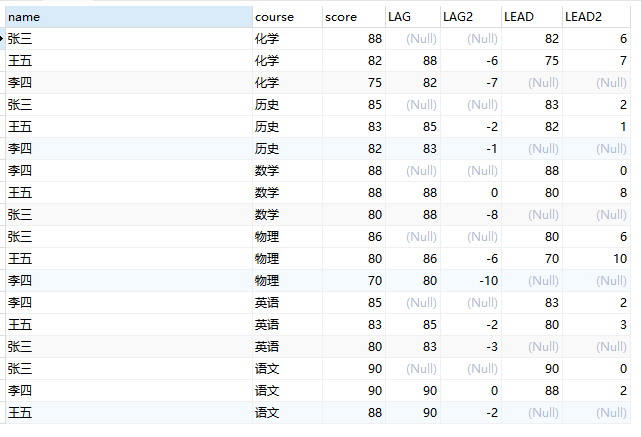
4、前后函数
- lag(expr,n) 返回当前行的前n行的expr的值
- lead(expr,n) 返回当前行的后n行的expr的值
LAG() 函数用于在查询结果中访问当前行之前的行的数据。它允许您检索前一行的值,并将其与当前行的值进行比较或计算差异。LAG()函数对于处理时间序列数据或比较相邻行的值非常有用。LAG()函数完整的表达式为 LAG(column, offset, default_value),包含三个参数:
column:就是列名,获取哪个列的值就是哪个列名,很好理解。
offset: 就是向前的偏移量,取当前行的前一行就是1,前前两行就是2。
default_value:是可选值,如果向前偏移的行不存在,就取这个默认值。
SELECT
name,
course,
score,
-- LAG默认直接显示上一个的值,可用于查看与上一个值的变化
LAG(score) OVER w AS 'LAG',
score - LAG(score) OVER w AS 'LAG2',
-- LEAD默认直接显示下一个的值,可用于查看与下一个值的变化
LEAD(score) OVER w AS 'LEAD',
score - LEAD(score) OVER w AS 'LEAD2'
FROM
student
window w as (partition by course order by score desc)
;
我们通过结果也可以看出,LAG显示该值与上一个值的变化(默认n为1),LEAD正好相反显示该值与下一个值的变化。常用于计算上一个值与下一个值的分数差,也可以用于统计两次请求之间相差的时间等等。
细心的小伙伴也发现了,此处我们的sql有一些变化。没错,window函数可以在最后进行命名,复用起来更加方便,后续我们会详细介绍。
5、头尾函数:FIRST_VALUE()、LAST_VALUE()
FIRST_VALUE(expr)函数返回第一个expr的值。
LAST_VALUE(expr)函数返回最后一个expr的值。
SELECT
name,
course,
score,
FIRST_VALUE(score) OVER w AS 'first',
LAST_VALUE(score) OVER w AS 'last'
FROM
student
window w as (partition by course order by score desc)
;
从结果看,我们对FIRST_VALUE()很清晰,就是获取的第一个值,但是LAST_VALUE()获取的值跟我们想象中的不太一样呢?
没错,LAST_VALUE()是获取的框架中的最后一个值,这里引入了一个重要概念:框架(frame),框架是一个动态的概念,是组的子集,从LAST_VALUE函数可以更好看出框架的动态变化,也就是说,LAST_VALUE()获取的是截止当前行的框架内最后一个值(就是当前行自己),而不是整个组的最后一个值。
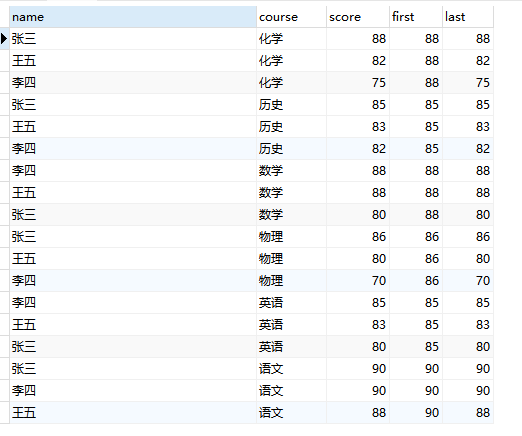
6、其他函数:NTH_VALUE()、NTILE()
- nth_value(expr,n) 返回第n个expr的值
- ntile(n) 将分区中的有序数据分为n个桶,记录桶的编号
SELECT
name,
course,
score,
nth_value( score, 2 ) over w 框架内第二个值,
nth_value( score, 3 ) over w 框架内第三个值
FROM
student window w AS ( PARTITION BY course ORDER BY score DESC );
获取框架内指定的值:
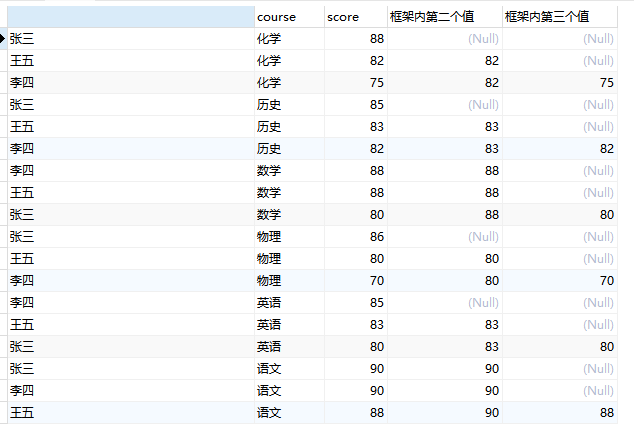
SELECT
name,
course,
score,
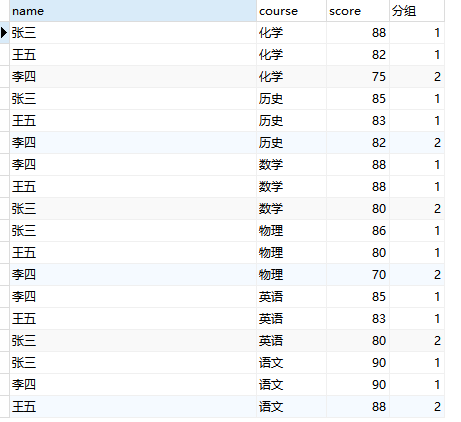
NTILE(2) over w '分组'
FROM
student window w AS ( PARTITION BY course ORDER BY score DESC );
将框架内数据再分成2组,展示所分的组:
三、窗口函数的命名
1、语法格式
WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...
window_spec表达式的格式:
[window_name] [partition_clause] [order_clause] [frame_clause]
2、使用示例
下面的例子我们同时使用了同一个window,但是写起来非常啰嗦:
SELECT
val,
ROW_NUMBER() OVER (ORDER BY val) AS 'row_number',
RANK() OVER (ORDER BY val) AS 'rank',
DENSE_RANK() OVER (ORDER BY val) AS 'dense_rank'
FROM numbers;
使用以下命令可以更简单地编写查询WINDOW定义一次窗口并在OVER 使用:
SELECT
val,
ROW_NUMBER() OVER w AS 'row_number',
RANK() OVER w AS 'rank',
DENSE_RANK() OVER w AS 'dense_rank'
FROM numbers
WINDOW w AS (ORDER BY val);
以下使用也是可以的,最终将PARTITION 与ORDER BY部分合并:
SELECT
DISTINCT year, country,
FIRST_VALUE(year) OVER (w ORDER BY year ASC) AS first,
FIRST_VALUE(year) OVER (w ORDER BY year DESC) AS last
FROM sales
WINDOW w AS (PARTITION BY country);
但是要注意以下的场景:
-- 可以这样用,因为窗口定义和引用OVER子句不包含相同种类的属性:
OVER (w ORDER BY country)
... WINDOW w AS (PARTITION BY country)
-- 不能这样用,因为OVER子句指定PARTITION BY对于已经具有的命名窗口PARTITION BY:
OVER (w PARTITION BY year)
... WINDOW w AS (PARTITION BY country)
-- 可以这样用,它包含向前和向后引用,但不包含循环:
WINDOW w1 AS (w2), w2 AS (), w3 AS (w1)
-- 不能这样用,因为它包含一个循环:
WINDOW w1 AS (w2), w2 AS (w3), w3 AS (w1)
四、窗口函数框架
参考:
https://dev.mysql.com/doc/refman/8.0/en/window-functions-frames.html
https://blog.csdn.net/frostlulu/article/details/130729113
参考资料
https://blog.csdn.net/CaiJin1217/article/details/129155992
https://blog.csdn.net/frostlulu/article/details/130729113
https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html
https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html

![用友NC Cloud accept.jsp接口任意文件上传漏洞复现 [附POC]](https://img-blog.csdnimg.cn/bee64cf481f64a7e937200eaf7e2e74f.png)