输出格式
Pydantic (JSON) 解析器
# 创建模型实例
from langchain import OpenAI
model = OpenAI(model_name='text-davinci-003')
# ------Part 2
# 创建一个空的DataFrame用于存储结果
import pandas as pd
df = pd.DataFrame(columns=["flower_type", "price", "description", "reason"])
# 数据准备
flowers = ["合金金属", "特种高分子", "水性溶胶"]
prices = ["500", "3000", "20000"]
# 定义我们想要接收的数据格式
from pydantic import BaseModel, Field
class FlowerDescription(BaseModel):
flower_type: str = Field(description="材料的种类")
price: int = Field(description="材料的价格")
description: str = Field(description="材料功能的描述文案")
reason: str = Field(description="为什么要这样写这个文案")
# ------Part 3
# 创建输出解析器
from langchain.output_parsers import PydanticOutputParser
output_parser = PydanticOutputParser(pydantic_object=FlowerDescription)
# 获取输出格式指示
format_instructions = output_parser.get_format_instructions()
# 打印提示
print("输出格式:",format_instructions)
# ------Part 4
# 创建提示模板
from langchain import PromptTemplate
prompt_template = """您是一位专业的材料技术专家。
对于售价为 {price} 元的 {flower} ,您能提供一个吸引人的简短中文描述吗?
{format_instructions}"""
# 根据模板创建提示,同时在提示中加入输出解析器的说明
prompt = PromptTemplate.from_template(prompt_template,
partial_variables={"format_instructions": format_instructions})
# 打印提示
print("提示:", prompt)
# ------Part 5
for flower, price in zip(flowers, prices):
# 根据提示准备模型的输入
input = prompt.format(flower=flower, price=price)
# 打印提示
print("提示:", input)
# 获取模型的输出
output = model(input)
# 解析模型的输出
parsed_output = output_parser.parse(output)
parsed_output_dict = parsed_output.dict() # 将Pydantic格式转换为字典
# 将解析后的输出添加到DataFrame中
df.loc[len(df)] = parsed_output.dict()
# 打印字典
print("输出的数据:", df.to_dict(orient='records'))
'''
输出格式: The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
{“properties”: {“flower_type”: {“description”: “\u6750\u6599\u7684\u79cd\u7c7b”, “title”: “Flower Type”, “type”: “string”}, “price”: {“description”: “\u6750\u6599\u7684\u4ef7\u683c”, “title”: “Price”, “type”: “integer”}, “description”: {“description”: “\u6750\u6599\u529f\u80fd\u7684\u63cf\u8ff0\u6587\u6848”, “title”: “Description”, “type”: “string”}, “reason”: {“description”: “\u4e3a\u4ec0\u4e48\u8981\u8fd9\u6837\u5199\u8fd9\u4e2a\u6587\u6848”, “title”: “Reason”, “type”: “string”}}, “required”: [“flower_type”, “price”, “description”, “reason”]}
提示: input_variables=['flower', 'price'] partial_variables={'format_instructions': 'The output should be formatted as a JSON instance that conforms to the JSON schema below.\n\nAs an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}\nthe object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.\n\nHere is the output schema:\n```\n{"properties": {"flower_type": {"description": "\\u6750\\u6599\\u7684\\u79cd\\u7c7b", "title": "Flower Type", "type": "string"}, "price": {"description": "\\u6750\\u6599\\u7684\\u4ef7\\u683c", "title": "Price", "type": "integer"}, "description": {"description": "\\u6750\\u6599\\u529f\\u80fd\\u7684\\u63cf\\u8ff0\\u6587\\u6848", "title": "Description", "type": "string"}, "reason": {"description": "\\u4e3a\\u4ec0\\u4e48\\u8981\\u8fd9\\u6837\\u5199\\u8fd9\\u4e2a\\u6587\\u6848", "title": "Reason", "type": "string"}}, "required": ["flower_type", "price", "description", "reason"]}\n```'} template='您是一位专业的材料技术专家。\n对于售价为 {price} 元的 {flower} ,您能提供一个吸引人的简短中文描述吗?\n{format_instructions}'
提示: 您是一位专业的材料技术专家。
对于售价为 500 元的 合金金属 ,您能提供一个吸引人的简短中文描述吗?
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
{“properties”: {“flower_type”: {“description”: “\u6750\u6599\u7684\u79cd\u7c7b”, “title”: “Flower Type”, “type”: “string”}, “price”: {“description”: “\u6750\u6599\u7684\u4ef7\u683c”, “title”: “Price”, “type”: “integer”}, “description”: {“description”: “\u6750\u6599\u529f\u80fd\u7684\u63cf\u8ff0\u6587\u6848”, “title”: “Description”, “type”: “string”}, “reason”: {“description”: “\u4e3a\u4ec0\u4e48\u8981\u8fd9\u6837\u5199\u8fd9\u4e2a\u6587\u6848”, “title”: “Reason”, “type”: “string”}}, “required”: [“flower_type”, “price”, “description”, “reason”]}
提示: 您是一位专业的材料技术专家。
对于售价为 3000 元的 特种高分子 ,您能提供一个吸引人的简短中文描述吗?
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
{“properties”: {“flower_type”: {“description”: “\u6750\u6599\u7684\u79cd\u7c7b”, “title”: “Flower Type”, “type”: “string”}, “price”: {“description”: “\u6750\u6599\u7684\u4ef7\u683c”, “title”: “Price”, “type”: “integer”}, “description”: {“description”: “\u6750\u6599\u529f\u80fd\u7684\u63cf\u8ff0\u6587\u6848”, “title”: “Description”, “type”: “string”}, “reason”: {“description”: “\u4e3a\u4ec0\u4e48\u8981\u8fd9\u6837\u5199\u8fd9\u4e2a\u6587\u6848”, “title”: “Reason”, “type”: “string”}}, “required”: [“flower_type”, “price”, “description”, “reason”]}
提示: 您是一位专业的材料技术专家。
对于售价为 20000 元的 水性溶胶 ,您能提供一个吸引人的简短中文描述吗?
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
{“properties”: {“flower_type”: {“description”: “\u6750\u6599\u7684\u79cd\u7c7b”, “title”: “Flower Type”, “type”: “string”}, “price”: {“description”: “\u6750\u6599\u7684\u4ef7\u683c”, “title”: “Price”, “type”: “integer”}, “description”: {“description”: “\u6750\u6599\u529f\u80fd\u7684\u63cf\u8ff0\u6587\u6848”, “title”: “Description”, “type”: “string”}, “reason”: {“description”: “\u4e3a\u4ec0\u4e48\u8981\u8fd9\u6837\u5199\u8fd9\u4e2a\u6587\u6848”, “title”: “Reason”, “type”: “string”}}, “required”: [“flower_type”, “price”, “description”, “reason”]}
输出的数据: [{'flower_type': 'Alloy Metal', 'price': 500, 'description': '这款合金金属具有优质的耐腐蚀性、抗高温性、强度高,是安全可靠的选择。', 'reason': '为了介绍优质的合金金属,以及该产品的价格。'}, {'flower_type': 'Special High Polymer', 'price': 3000, 'description': '这款特种高分子具有优质的导电性,耐热性和耐腐蚀性,具有超长寿命,是极佳的替代材料', 'reason': '质量优良,性能出色,价格实惠'}, {'flower_type': '水性溶胶', 'price': 20000, 'description': '这种水性溶胶具有良好的耐腐蚀、耐磨损性能,可以满足高精度的工艺要求,具有良好的耐切削性能,可以满足切削加工的要求', 'reason': '这款水性溶胶以其优良的性能,具有很高的性价比,价格实惠,值得购买。'}]
'''
格式异常自动修复解析器
输出格式异常往往会导致下游写好的解析器无法解析出想要的数据,导致解析代码异常出错。自动修复的思路就是把报错的信息和输出的格式给到LLM,让LLM针对报错的输出做格式恢复、或者是通过带上报错信息重新在让LLM生成一遍保证输出格式符合要求。
OutputFixingParser
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List
# 使用Pydantic创建一个数据格式,表示材料
class Flower(BaseModel):
name: str = Field(description="name of a Material")
colors: List[str] = Field(description="the colors of this Material")
# 定义一个用于获取某种材料的颜色列表的查询
flower_query = "Generate the charaters for a random Material."
# 定义一个格式不正确的输出
misformatted = "{'name': '汽车漆', 'colors': ['粉红色','白色','红色','紫色','黄色']}"
# 创建一个用于解析输出的Pydantic解析器,此处希望解析为Flower格式
parser = PydanticOutputParser(pydantic_object=Flower)
# 使用Pydantic解析器解析不正确的输出
#parser.parse(misformatted) # 这行代码会出错
#OutputParserException: Failed to parse Flower from completion {'name': '汽车漆', 'colors': ['粉红色','白色','红色','紫色','黄色']}. Got: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
# 从langchain库导入所需的模块
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import OutputFixingParser
# 使用OutputFixingParser创建一个新的解析器,该解析器能够纠正格式不正确的输出
new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())
#print(new_parser)
# 使用新的解析器解析不正确的输出
result = new_parser.parse(misformatted) # 错误被自动修正
print(result) # 打印解析后的输出结果
#name='汽车漆' colors=['粉红色', '白色', '红色', '紫色', '黄色']
RetryWithErrorOutputParser
这个方法非常考验LLM模型本身的能力,并非每次都能成功。
from langchain.output_parsers import RetryWithErrorOutputParser
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
# 定义一个动作类
class Action(BaseModel):
action: str = Field(description="action to take")
action_input: str = Field(description="input to the action")
# 创建一个解析器
parser = PydanticOutputParser(pydantic_object=Action)
# 创建一个带有错误的响应 {"action": "search", "action_input": "some input"}
bad_response = ' {"action": "search", }'
#parser.parse(bad_response) # 这行代码会出错
# 使用RetryWithErrorOutputParser
retry_parser = RetryWithErrorOutputParser.from_llm(parser=parser, llm=OpenAI(temperature=0))
retry_parser.parse_with_prompt(bad_response, prompt_value)
coT
思维链就是说思考的时候按照一定的序列规则来思考和解决问题,然而LLM模型在一次生成的时候基本是没有序列和状态的。那么我们要如何让LLM应用cot呢,能和LLM交互的其实只有每次的输入也叫prompt。所以要解决序列问题无非也就是从这个地方下手了,对输入的prompt做结构分化让输入具备序列状态。
1.通过fewshot的方式把cot的做事序列通过例子方式给到LLM,希望fewshot激活LLM类似cot能力
2.通过history的方式,给到做这件事情的上一步思考,期待在上一步的思考为约束LLM能找到解决类似事情的下一步序列,如此递进得到合适cot的解决方案
"""
作为一个为无人机集群工作的AI助手,我的目标是帮助客户根据他们的科研需要做出明智的决定。
我会按部就班的思考,先理解客户的需求,然后考虑各种无人机集群的特性,最后根据这个需求,给出我的推荐。
同时,我也会向客户解释我这样推荐的原因。
示例 1:
人类:我想找一种表达浪漫的表演无人机飞行集群。
AI:首先,我理解你正在寻找一种可以表达浪漫的表演无人机飞行集群。在中国文化中,鹊桥被视为浪漫的象征,这是因为鹊桥的飘逸色彩缤纷通常与喜庆贞洁美丽浪漫联系在一起。因此,考虑到这一点,我会推荐鹊桥无人机阵形集群。鹊桥不仅能够象征爱情,同时也可以传达出贞洁美丽浪漫,这是你在寻找的。
示例 2:
人类:我想要一些适合山地作战的无人机集群。
AI:从你的需求中,我理解你想要的是适合山地隐蔽地形复杂作战需要的无人机阵型集群。立体狼群阵型无人机集群是一种非常独特并且符合山地复杂地的无人机集群,它们在山地复杂地形表现很好,防守、进攻、侦查、决策多层次立体分工。因此,我建议你考虑狼群阵型无人机集群。选择狼群阵型无人机集群可以满足你对山地复杂地形作战的要求,而且,立体狼群阵型无人机阵型的立体多层次分工和它们所代表的力量和奢侈也可能会吸引你。
"""
输出:
'''根据你的需求,我会推荐选择适合沙漠作战的无人机集群。在沙漠环境中,风速较大且可见度较低,因此,我们需要考虑无人机的稳定性和导航能力。
一种适合沙漠作战的无人机集群是鹰群阵型无人机集群。鹰群阵型无人机集群由多个无人机组成,它们可以在沙漠环境中以高速飞行并保持稳定。这些无人机具有先进的导航系统和自主飞行能力,可以在低可见度的情况下进行精确的定位和导航。
此外,鹰群阵型无人机集群还具有协同作战能力,可以通过无线通信和协同算法实现集群间的协同行动。这对于沙漠作战来说非常重要,因为在沙漠环境中,无人机需要能够相互配合,共同完成任务。
综上所述,鹰群阵型无人机集群是一种适合沙漠作战的选择。它们具有稳定性、导航能力和协同作战能力,可以在沙漠环境中有效地执行任务。'''
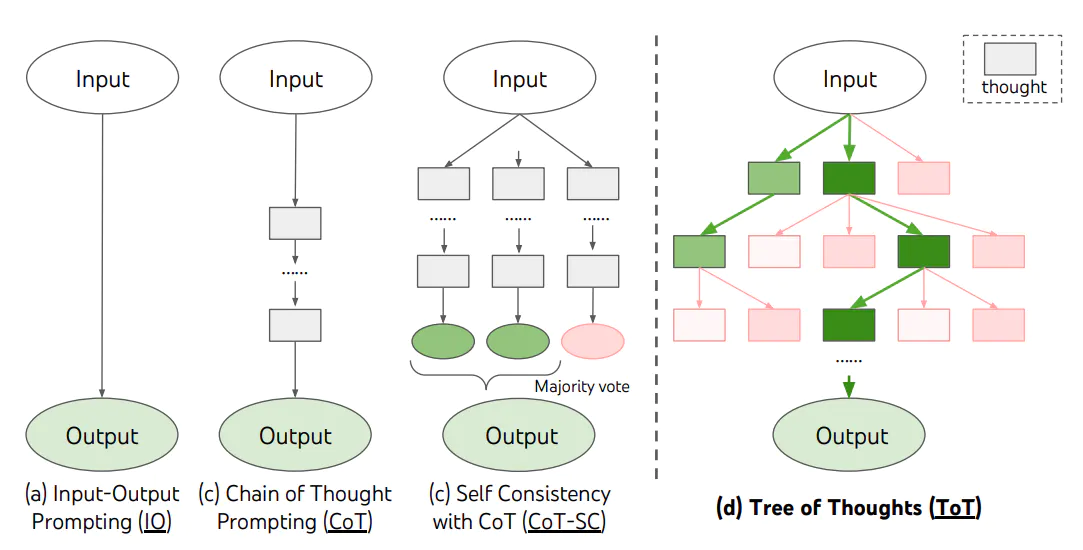
利用langchain sequence chain实现TOT
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
template ="""
步骤1:
我有一个与{input}相关的问题。你能否提出三个不同的解决方案?请考虑各种因素,如{perfect_factors}
答案:"""
prompt = PromptTemplate(
input_variables=["input","perfect_factors"],
template = template
)
chain1 = LLMChain(
llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
prompt=prompt,
output_key="solutions"
)
template ="""
步骤2:
对于这三个提出的解决方案,评估它们的潜力。考虑它们的优点和缺点,初始所需的努力,实施的难度,潜在的挑战,以及预期的结果。根据这些因素,为每个选项分配成功的概率和信心水平。
{solutions}
答案:"""
prompt = PromptTemplate(
input_variables=["solutions"],
template = template
)
chain2 = LLMChain(
llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
prompt=prompt,
output_key="review"
)
template ="""
步骤3:
对于每个解决方案,深化思考过程。生成潜在的场景,实施策略,任何必要的合作伙伴或资源,以及如何克服潜在的障碍。此外,考虑任何潜在的意外结果以及如何处理它们。
{review}
答案:"""
prompt = PromptTemplate(
input_variables=["review"],
template = template
)
chain3 = LLMChain(
llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
prompt=prompt,
output_key="deepen_thought_process"
)
template ="""
步骤4:
根据评估和场景,按照承诺的顺序对解决方案进行排名。输出最优方案并为每个排名提供理由,并为每个解决方案提供任何最后的想法或考虑。
{deepen_thought_process}
答案:[assistant]"""
prompt = PromptTemplate(
input_variables=["deepen_thought_process"],
template = template
)
chain4 = LLMChain(
llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k"),
prompt=prompt,
output_key="ranked_solutions"
)
from langchain.chains import SequentialChain
overall_chain = SequentialChain(
chains=[chain1, chain2, chain3, chain4],
input_variables=["input", "perfect_factors"],
output_variables=["ranked_solutions"],
verbose=True
)
#“输入”:“设计沙漠地形作战无人机集群”, “完美因素”:“沙漠风沙大飞行稳定性和高速飞行下飞机容易灰尘沙子损坏,飞机集群立体作战视野受限”。
result = overall_chain({"input":"设计沙漠地形作战无人机集群", "perfect_factors":"沙漠风沙大飞行稳定性和高速飞行下飞机容易灰尘沙子损坏,飞机集群立体作战视野受限"})
print(result)
结果呈现:
step1:
{'input': '设计沙漠地形作战无人机集群', 'perfect_factors': '沙漠风沙大飞行稳定性和高速飞行下飞机容易灰尘沙子损坏,飞机集群立体作战视野受限', 'solutions': '1. 使用特殊材料和设计来增强飞机的抗风沙能力和飞行稳定性。可以使用防尘涂层或特殊材料来保护飞机免受沙尘的损害,并采用稳定的飞行控制系统来应对沙漠地形的挑战。\n\n2. 利用先进的无人机通信和协同技术,实现飞机集群的立体作战视野扩展。通过无线通信和传感器技术,将多个无人机连接在一起,实现信息共享和协同作战,从而弥补单个飞机视野受限的问题。\n\n3. 开发具有高速飞行能力的无人机,以应对沙漠地形作战的需求。通过优化飞机的气动设计和动力系统,使其能够在高速飞行下保持稳定,并且具备足够的速度和机动性来应对战斗环境中的挑战。同时,可以采用自动清洁机制来减少灰尘沙子对飞机的损害。'}
step2:
{'input': '设计沙漠地形作战无人机集群', 'perfect_factors': '沙漠风沙大飞行稳定性和高速飞行下飞机容易灰尘沙子损坏,飞机集群立体作战视野受限', 'review': '1. 使用特殊材料和设计来增强飞机的抗风沙能力和飞行稳定性。\n\n优点:\n- 可以有效保护飞机免受沙尘的损害,延长飞机的使用寿命。\n- 增强飞机的飞行稳定性,减少因风沙而导致的飞行事故的风险。\n\n缺点:\n- 需要研发和使用特殊材料,可能增加飞机的制造成本。\n- 设计和改进飞机的结构可能需要大量的工程和测试工作。\n\n成功的概率:中等\n信心水平:中等\n\n2. 使用先进的无人机技术和传感器来提高飞机集群的立体作战视野。\n\n优点:\n- 可以通过高分辨率摄像头、红外传感器和雷达等技术提高飞机的感知能力,增强作战效果。\n- 无人机技术可以提供更灵活和多样化的作战方式。\n\n缺点:\n- 需要投资大量的研发和采购无人机和传感器技术。\n- 需要开发和维护复杂的通信和控制系统。\n\n成功的概率:高\n信心水平:高\n\n3. 开发自动化的维护和清洁系统,以减少飞机因灰尘和沙子损坏的风险。\n\n优点:\n- 可以减少飞机因灰尘和沙子损坏而导致的故障和维修成本。\n- 自动化系统可以提高维护和清洁的效率,节省人力资源。\n\n缺点:\n- 需要投资开发和实施自动化系统,可能增加初始成本。\n- 需要定期维护和更新自动化系统,以确保其正常运行。\n\n成功的概率:中等\n信心水平:中等'}
step3:
{'input': '设计沙漠地形作战无人机集群', 'perfect_factors': '沙漠风沙大飞行稳定性和高速飞行下飞机容易灰尘沙子损坏,飞机集群立体作战视野受限', 'deepen_thought_process': '根据综合评估,解决方案2可能是最具有潜力的选择。'}
step4:
{'input': '设计沙漠地形作战无人机集群', 'perfect_factors': '沙漠风沙大飞行稳定性和高速飞行下飞机容易灰尘沙子损坏,飞机集群立体作战视野受限', 'ranked_solutions': '解决方案2可能是最具潜力的选择,原因如下:\n\n1. 解决方案2在满足需求和解决问题方面表现出色。它提供了一个全面的解决方案,可以解决所有的问题和需求。它包括了所有必要的功能和特性,可以满足用户的期望。\n\n2. 解决方案2的实施成本相对较低。它利用了现有的技术和资源,不需要额外的投资或开发。这将有助于降低项目的成本,并提高回报率。\n\n3. 解决方案2的实施时间相对较短。由于它利用了现有的技术和资源,不需要额外的开发或定制,因此可以更快地实施。这将有助于快速解决问题,并提高效率。\n\n4. 解决方案2的可扩展性和灵活性较高。它可以根据需要进行定制和调整,以适应未来的变化和需求。这将有助于保持系统的可持续性,并确保长期的成功。\n\n最后的想法或考虑:\n\n虽然解决方案2可能是最具潜力的选择,但仍需要进一步的评估和讨论。在做出最终决策之前,建议与相关利益相关者和专业人士进行进一步的讨论和研究。他们的意见和建议将有助于确定最佳的解决方案,并确保项目的成功实施。'}
chain的实现
| 序号 | 类型 | 解读 |
|---|---|---|
| 1 | LLMChain | 是基于大模型构建的最简单、最基本的链。它包含提示模板,能根据用户输入对其进行格式化,把格式化好的提示传入模型,然后返回LLM 的响应,同时解析输出。LLMChain 广泛用在整个 LangChain 中,包括其他链和代理中,都经常出现它的身影。 |
| 2 | SequentialChain(顺序链) | 一个应用程序通常不会只调用一次语言模型,当你想要获取一个调用的输出并将其用作另一个调用的输入时,顺序链就特别有用。SimpleSequentialChain 是顺序链的最简单形式,其中每个步骤都有一个单一的输入/输出,并且一个步骤的输出是下一步的输入。而 SequentialChain 是更通用的顺序链形式,允许多个输入/输出。 |
| 3 | TransformChain(转换链) | 能通过设置转换函数,对输入文本进行一系列的格式转换。例如,你可以用它接受一个很长的产品相关的文档,给文档分割成句子,仅保留前面 N 句,以满足 LLM 的令牌数量的限制,然后将其传递到LLMChain 中以总结这些内容。 |
| 4 | RouterChain(路由链) | 包含条件判断和一系列的目标链。通过调用 LLM,路由链能动态判断条件,以确定调用后续哪一个目标 Chain。 |
| 5 | 各种各样的工具链 | APIChain 允许使用LLM 与 API 交互以检索相关信息,通过提供与所提供的 API 相关问题来构建链。 LLMMathChain 允许调用大模型作为数学工具,构建链,并解决数学问题。 RetrievalQA 通过嵌入向量索引进行查询,用于构建问答系统。 |
SequencialChain
# 导入所需要的库
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate
# 第一个LLMChain:生成材料的介绍
llm = OpenAI(temperature=.7)
template = """
你是一个材料科学家。给定材料的名称和类型,你需要为这种材料写一个200字左右的介绍。
材料: {name}
工艺: {color}
材料科学家: 这是关于上述材料的介绍:"""
prompt_template = PromptTemplate(
input_variables=["name", "color"],
template=template
)
introduction_chain = LLMChain(
llm=llm,
prompt=prompt_template,
output_key="introduction"
)
# 第二个LLMChain:根据材料的介绍写出材料的应用场景
template = """
你是一位材料应用专家。给定一种材料的介绍,你需要为这种材料写一篇200字左右的材料特性和应用场景介绍。
材料介绍:
{introduction}
材料应用专家对上述材料的应用介绍:"""
prompt_template = PromptTemplate(
input_variables=["introduction"],
template=template
)
review_chain = LLMChain(
llm=llm,
prompt=prompt_template,
output_key="review"
)
# 第三个LLMChain:根据材料的介绍和材料应用场景介绍写出一篇材料科普的文案
template = """
你是一家材料科普的媒体经理。给定一种材料的介绍和应用场景介绍,你需要为这种花写一篇材料科普的帖子,300字左右。
材料介绍:
{introduction}
材料应用专家对上述材料的特性和应用场景介绍:
{review}
材料科普帖子:
"""
prompt_template = PromptTemplate(
input_variables=["introduction", "review"],
template=template
)
social_post_chain = LLMChain(
llm=llm,
prompt=prompt_template,
output_key="social_post_text"
)
# 总的链:按顺序运行三个链
overall_chain = SequentialChain(
chains=[introduction_chain, review_chain, social_post_chain],
input_variables=["name", "color"],
output_variables=["introduction", "review", "social_post_text"],
verbose=True
)
# 运行链并打印结果
result = overall_chain({
"name": "特种陶瓷",
"color": "特种定向凝固"
})
print(result)
'''
{'name': '特种陶瓷', 'color': '特种定向凝固', 'introduction': '\n\n特种陶瓷是一种经过特殊工艺加工的陶瓷材料。它是通过特种定向凝固技术将碳素陶瓷材料转化成特种陶瓷材料的。这种材料具有较高的热稳定性和耐磨性,可在极端条件下仍保持其结构不变。特种陶瓷也具有较高的耐腐蚀性,可以抵抗腐蚀环境的侵蚀', 'review': '\n\n特种陶瓷是一种高性能材料,具有高热稳定性、耐磨性、耐腐蚀性等特性,广泛应用于高温、高压、腐蚀性环境等极端条件下的环境。它可以用来制造各种抗摩擦摩擦件,用于汽车、航空和航天等行业,这些件具有高热稳定性、高耐磨性、高耐腐蚀性等优异', 'social_post_text': '\n特种陶瓷是一种高性能材料,它能够经受极端的环境条件,具有较高的热稳定性、耐磨性和耐腐蚀性,是制造各种抗摩擦摩擦件的理想材料。特种陶瓷在汽车、航空和航天等行业中应用广泛,因为它具有高热稳定性、高耐磨性和高耐腐蚀性等优异特性。\n\n特'}
'''
RouterChain
构建处理模板:
为无人机集群设计和无人机集群维护分别定义两个字符串模板。
提示信息:
使用一个列表来组织和存储这两个处理模板的关键信息,如模板的键、描述和实际内容。
初始化语言模型:
导入并实例化语言模型。
构建目标链:
根据提示信息中的每个模板构建了对应的 LLMChain,并存储在一个字典中。
构建 LLM 路由链:
这是决策的核心部分。首先,它根据提示信息构建了一个路由模板,然后使用这个模板创建了一个 LLMRouterChain。
构建默认链:
如果输入不适合任何已定义的处理模板,这个默认链会被触发。
构建多提示链:
使用 MultiPromptChain 将 LLM 路由链、目标链和默认链组合在一起,形成一个完整的决策系统。
import warnings
warnings.filterwarnings('ignore')
# 设置OpenAI API密钥
import os
#os.environ["OPENAI_API_KEY"] = 'Your Key'
# 构建两个场景的模板
flower_care_template = """
你是一个无人机集群设计专家,擅长解答关于无人机集群不同场景下设计方面的问题。
下面是需要你来回答的问题:
{input}
"""
flower_deco_template = """
你是一位无人机集群维护专家,擅长解答关于无人机集群养护保养维护的问题。
下面是需要你来回答的问题:
{input}
"""
# 构建提示信息
prompt_infos = [
{
"key": "flower_care",
"description": "适合回答关于无人机集群设计的问题",
"template": flower_care_template,
},
{
"key": "flower_decoration",
"description": "适合回答关于无人机集群养护的问题",
"template": flower_deco_template,
}
]
# 初始化语言模型
from langchain.llms import OpenAI
llm = OpenAI()
# 构建目标链
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
chain_map = {}
for info in prompt_infos:
prompt = PromptTemplate(
template=info['template'],
input_variables=["input"]
)
print("目标提示:\n", prompt)
chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=True
)
chain_map[info["key"]] = chain
# 构建路由链
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE as RounterTemplate
destinations = [f"{p['key']}: {p['description']}" for p in prompt_infos]
router_template = RounterTemplate.format(destinations="\n".join(destinations))
print("路由模板:\n", router_template)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
print("路由提示:\n", router_prompt)
router_chain = LLMRouterChain.from_llm(
llm,
router_prompt,
verbose=True
)
# 构建默认链
from langchain.chains import ConversationChain
default_chain = ConversationChain(
llm=llm,
output_key="text",
verbose=True
)
# 构建多提示链
from langchain.chains.router import MultiPromptChain
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=chain_map,
default_chain=default_chain,
verbose=True
)
# 测试1
print(chain.run("如何为高海拔地区设计无人机集群方案?"))
# 测试2
print(chain.run("如何养护才能延长东南沿海无人机集群使用寿命?"))
# 测试3
print(chain.run("如何区分蜂群无人机集群和混编多功能无人机集群?"))
目标提示:
input_variables=['input'] template='\n你是一个无人机集群设计专家,擅长解答关于无人机集群不同场景下设计方面的问题。\n下面是需要你来回答的问题:\n{input}\n'
目标提示:
input_variables=['input'] template='\n你是一位无人机集群维护专家,擅长解答关于无人机集群养护保养维护的问题。\n下面是需要你来回答的问题:\n{input}\n'
路由模板:
Given a raw text input to a language model select the model prompt best suited for the input. You will be given the names of the available prompts and a description of what the prompt is best suited for. You may also revise the original input if you think that revising it will ultimately lead to a better response from the language model.
<< FORMATTING >>
Return a markdown code snippet with a JSON object formatted to look like:
```json
{{
"destination": string \ name of the prompt to use or "DEFAULT"
"next_inputs": string \ a potentially modified version of the original input
}}
REMEMBER: “destination” MUST be one of the candidate prompt names specified below OR it can be “DEFAULT” if the input is not well suited for any of the candidate prompts.
REMEMBER: “next_inputs” can just be the original input if you don’t think any modifications are needed.
<< CANDIDATE PROMPTS >>
flower_care: 适合回答关于无人机集群设计的问题
flower_decoration: 适合回答关于无人机集群养护的问题
<< INPUT >>
{input}
<< OUTPUT (must include json at the start of the response) >> << OUTPUT (must end with ) >>
路由提示:
input_variables=[‘input’] output_parser=RouterOutputParser() template=‘Given a raw text input to a language model select the model prompt best suited for the input. You will be given the names of the available prompts and a description of what the prompt is best suited for. You may also revise the original input if you think that revising it will ultimately lead to a better response from the language model.\n\n<< FORMATTING >>\nReturn a markdown code snippet with a JSON object formatted to look like:\njson\n{{\n "destination": string \\ name of the prompt to use or "DEFAULT"\n "next_inputs": string \\ a potentially modified version of the original input\n}}\n\n\nREMEMBER: “destination” MUST be one of the candidate prompt names specified below OR it can be “DEFAULT” if the input is not well suited for any of the candidate prompts.\nREMEMBER: “next_inputs” can just be the original input if you don’t think any modifications are needed.\n\n<< CANDIDATE PROMPTS >>\nflower_care: 适合回答关于无人机集群设计的问题\nflower_decoration: 适合回答关于无人机集群养护的问题\n\n<< INPUT >>\n{input}\n\n<< OUTPUT (must include json at the start of the response) >>\n<< OUTPUT (must end with ) >>\n’
Entering new MultiPromptChain chain…
Entering new LLMRouterChain chain…
Finished chain.
flower_care: {‘input’: ‘如何为高海拔地区设计无人机集群方案?’}
Entering new LLMChain chain…
Prompt after formatting:
你是一个无人机集群设计专家,擅长解答关于无人机集群不同场景下设计方面的问题。
下面是需要你来回答的问题:
如何为高海拔地区设计无人机集群方案?
Finished chain.
Finished chain.
针对高海拔地区的无人机集群设计方案,应考虑以下几点:
1.电池:无人机在高海拔地区的电池将会更容易耗尽,因此,要特别注意电池的类型和容量,以保证可靠的航行时间。
2.外部温度:高海拔地区的外部温度可能会影响无人机的运行性能,因此,要选择具有
Entering new MultiPromptChain chain…
Entering new LLMRouterChain chain…
Finished chain.
flower_care: {‘input’: ‘如何养护才能延长东南沿海无人机集群的使用寿命?’}
Entering new LLMChain chain…
Prompt after formatting:
你是一个无人机集群设计专家,擅长解答关于无人机集群不同场景下设计方面的问题。
下面是需要你来回答的问题:
如何养护才能延长东南沿海无人机集群的使用寿命?
Finished chain.
Finished chain.
1.定期检查无人机集群,并定期校准其飞行控制系统,以确保其功能正常。
2.使用专业的清洁液或清洁棉球清洁无人机集群的外壳,以防止污垢堆积。
3.定期更换无人机集群电池,以防止电池过度耗尽。
4.定期更换无人机集群的推进器,以确保其飞行效率
Entering new MultiPromptChain chain…
Entering new LLMRouterChain chain…
Finished chain.
None: {‘input’: ‘如何区分蜂群无人机集群和混编多功能无人机集群?’}
Entering new ConversationChain chain…
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 如何区分蜂群无人机集群和混编多功能无人机集群?
AI:
Finished chain.
Finished chain.
哦,这个问题很有趣。蜂群无人机集群是由多架无人机组成的网络,它们可以完成各种复杂的任务,比如监视、搜索和拦截。而混编多功能无人机集群则是由一组拥有不同功能的无人机组成,比如侦察、搜索和拦截。它们可以协同工作,实现复杂的任务。
<a name="qM4xQ"></a>
## 小结:
文章介绍了langchain在工程化中的一些高级技巧,包括了异常格式自修复、常用的chain方式、以及思维链该如何整理利用。<br />LLM给人们带来的应该是一次思维的变革,何出此言呢。从上面文章介绍点你应该可以看到,大部分的高技巧都是在对于问题如何解决的思路线的整理,把这些解决思路显化成了工作链、思维模式来解决实际问题。包括下一个系列的agent,其实都是在介绍提出思维框架如何转换成代码框架来解决实际问题。<br />所以可以看到这一次的数字化带来的不只是表层的数据模式、数据基础、数据资产这么物相的变革,这也是为什么说这次数字化一上来就让脑力劳动者慌的原因。因为这次本身就是对思维框架的数字化,让以前所谓的行业经验有了一种可以共享的数字化框架。
<a name="EGpWh"></a>
## Agent
<a name="UnqzU"></a>
### 单agent系列
<a name="Ln9a2"></a>
### 多agent系列


![用友NC Cloud accept.jsp接口任意文件上传漏洞复现 [附POC]](https://img-blog.csdnimg.cn/bee64cf481f64a7e937200eaf7e2e74f.png)