语音识别正在侵入我们的生活。它内置于我们的手机、游戏机和智能手表中。它甚至使我们的房屋自动化。你只需 50 美元,你就可以获得一个 Amazon Echo Dot——一个神奇盒子,你只需大声说出你的需求就可以帮你订购披萨、获取天气预报甚至购买垃圾袋。

但是语音识别已经存在了几十年,那么为什么它现在才成为主流呢?原因是深度学习最终使语音识别足够准确,可以在精心控制的环境之外发挥作用。
Andrew Ng 早就预测,随着语音识别准确率从 95% 提高到 99%,它将成为我们与计算机交互的主要方式。这个想法是,这 4% 的准确率差距是令人讨厌的不可靠和非常有用之间的区别。感谢深度学习,我们终于达到了顶峰。
让我们学习如何使用深度学习进行语音识别!
机器学习并不总是一个黑匣子
如果您知道神经机器翻译的工作原理,您可能会猜到我们可以简单地将录音输入神经网络并训练它生成文本:
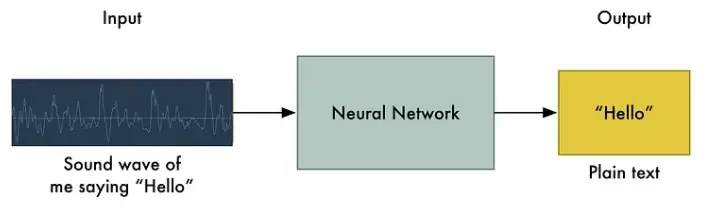
最大的问题是语音速度不同。一个人可能会说“hello!” 很快,另一个人可能会说“heeeelllllllllllllooooo!” 非常缓慢,产生一个包含更多数据的更长的声音文件。两个声音文件都应该被识别为完全相同的文本——“hello!” 事实证明,将各种长度的音频文件自动对齐到一段固定长度的文本非常困难。
为了解决这个问题,除了深度神经网络之外,我们还必须使用一些特殊的技巧和额外的进动。让我们看看它是如何工作的!
把声音变成比特流
语音识别的第一步很明显——我们需要将声波输入计算机。
在前面的学习中,我们学习了如何拍摄图像并将其视为数字数组,以便我们可以直接输入神经网络进行图像识别:

但是声音是以波的形式传播的。我们如何将声波转化为数字?让我们用这段我说“hello”的声音片段:
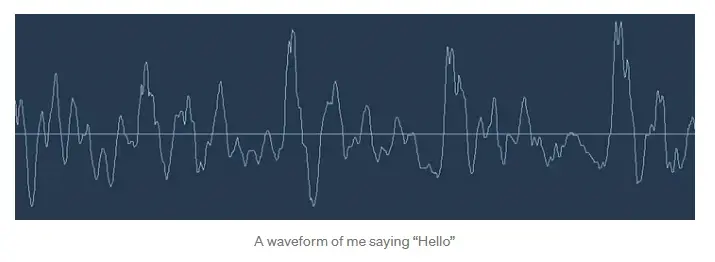
声波是一维的。在每个时刻,它们都有一个基于波浪高度的单一值。让我们放大声波的一小部分看看:
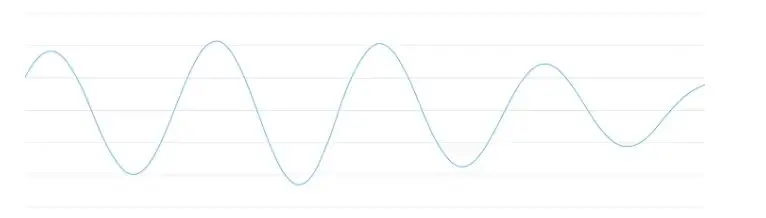
要将此声波转换为数字,我们只需记录等距点处的波高:

这称为抽样。我们每秒读取数千次读数,并记录一个代表该时间点声波高度的数字。这基本上就是一个未压缩的 .wav 音频文件的全部内容。
“CD 质量”音频以 44.1khz(每秒 44,100 个读数)采样。但对于语音识别,16khz(每秒 16,000 个样本)的采样率足以覆盖人类语音的频率范围。
让我们以每秒 16,000 次的频率对我们的“Hello”声波进行采样。这是前 100 个样本:

关于数字采样的额外思考
您可能认为采样只是创建原始声波的粗略近似值,因为它只是随机读取数据。我们的读数之间存在差距,所以我们一定会丢失数据,对吧?
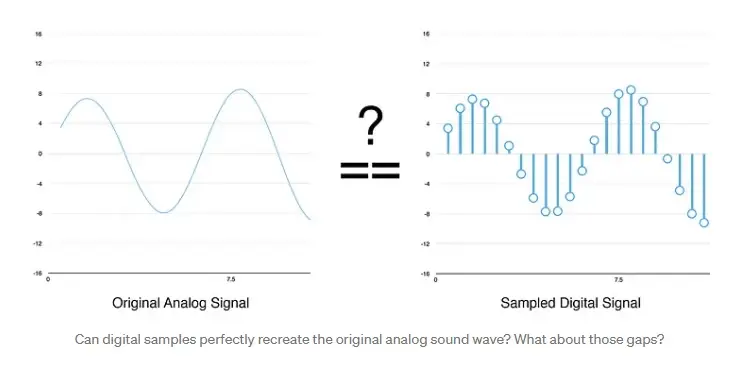
但多亏了奈奎斯特定理,我们知道我们可以使用数学从间隔开的样本中完美地重建原始声波——只要我们的采样速度至少是我们想要记录的最高频率的两倍。
我提到这一点只是因为几乎每个人都误解了这一点,并假设使用更高的采样率总是会带来更好的音频质量。它没有。
预处理我们的采样声音数据
我们现在有一个数字数组,每个数字代表以 1/16,000 秒为间隔的声波振幅。
我们可以将这些数字直接输入神经网络。但试图通过直接处理这些样本来识别语音模式是很困难的。相反,我们可以通过对音频数据进行一些预处理来简化问题。
让我们首先将我们的采样音频分组为 20 毫秒长的块。这是我们的前 20 毫秒音频(即我们的前 320 个样本):
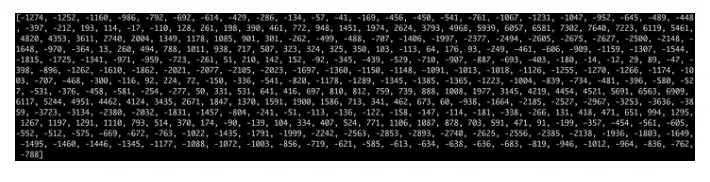
将这些数字绘制成简单的折线图,可以粗略估计 20 毫秒时间段内的原始声波:
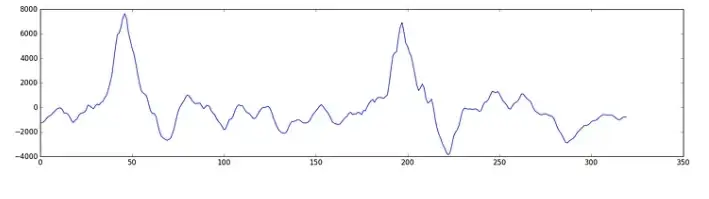
这段录音只有 1/50 秒长。但即使是这段简短的录音也是不同频率声音的复杂混搭。有一些低音,一些中音,甚至还有一些高音。但总的来说,这些不同的频率混合在一起构成了人类语音的复杂声音。
为了让神经网络更容易处理这些数据,我们将把这个复杂的声波分解成它的组成部分。我们将打破低音部分,下一个最低音部分,等等。然后通过将每个频段(从低到高)中的能量相加,我们为该音频片段创建了某种指纹。
想象一下,您录制了某人在钢琴上弹奏 C 大调和弦的录音。该声音是三个音符(C、E 和 G)的组合,它们全部混合在一起形成一个复杂的声音。我们想将复杂的声音分解成单独的音符,以发现它们是 C、E 和 G。这是完全相同的想法。
我们使用称为傅立叶变换的数学运算来执行此操作。它将复杂的声波分解成组成它的简单声波。一旦我们有了这些单独的声波,我们就会把每个声波中包含的能量加起来。
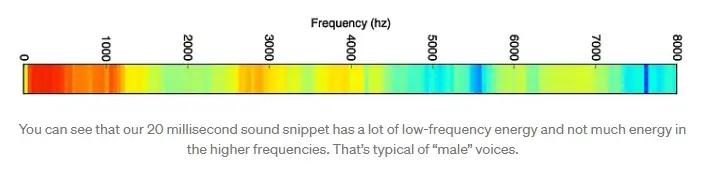
最终结果是每个频率范围的重要性得分,从低音(即低音音符)到高音。下面的每个数字代表我们 20 毫秒音频剪辑的每个 50hz 频段中的能量:

但是,当您将其绘制为图表时,这会更容易看到:
如果我们对每 20 毫秒的音频块重复这个过程,我们最终会得到一个频谱图(从左到右的每一列都是一个 20 毫秒的块):
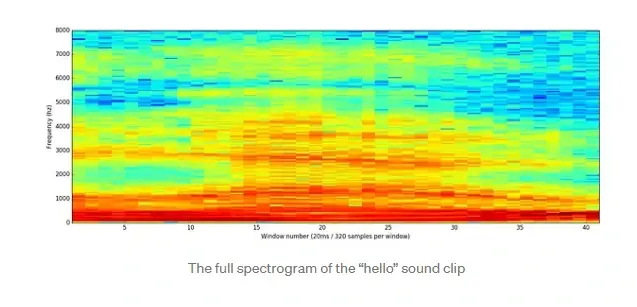
频谱图很酷,因为您实际上可以在音频数据中看到音符和其他音高模式。与原始声波相比,神经网络可以更容易地在此类数据中找到模式。所以这是我们实际输入神经网络的数据表示。
从短音中识别字符
现在我们的音频格式易于处理,我们将把它输入深度神经网络。神经网络的输入将是 20 毫秒的音频块。对于每个小音频片段,它会尝试找出与当前所说的声音相对应的字母。
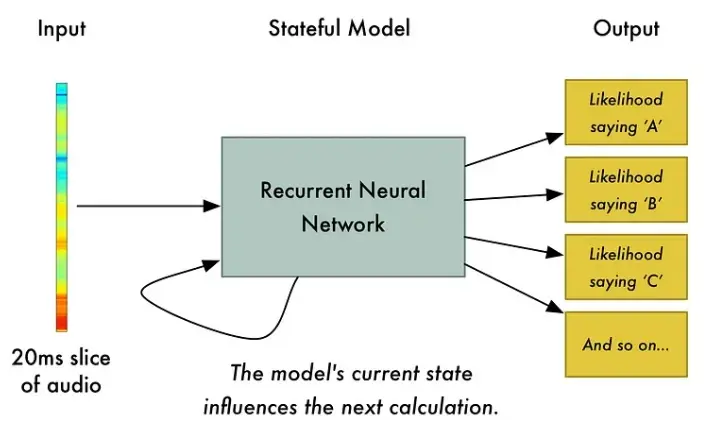
我们将使用循环神经网络——即具有影响未来预测的记忆的神经网络。这是因为它预测的每个字母都会影响它预测的下一个字母的可能性。例如,如果到目前为止我们已经说了“HEL”,那么接下来我们很可能会说“LO”来完成“Hello”这个词。接下来我们不太可能说出像“XYZ”这样无法发音的东西。因此,拥有对先前预测的记忆有助于神经网络做出更准确的预测。
在我们通过神经网络运行整个音频剪辑(一次一个块)之后,我们最终将每个音频块映射到该块中最有可能说出的字母。这是我说“你好”时映射的样子:
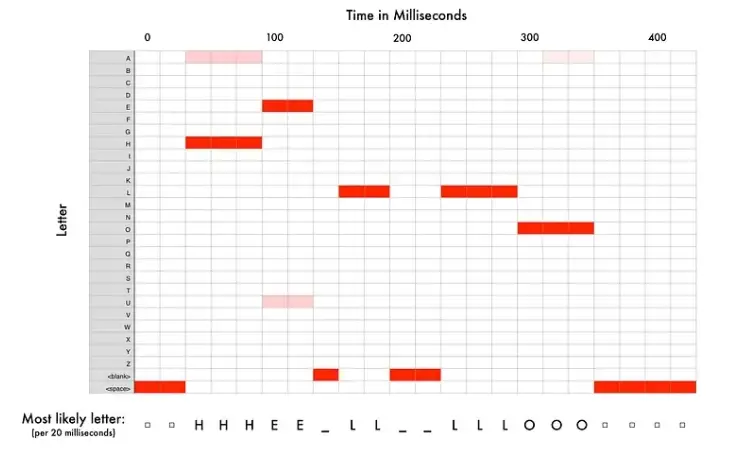
我们的神经网络预测我说的可能是“HHHEE_LL_LLLOOO”。但它也认为我说的可能是“HHHUU_LL_LLLOOO”甚至“AAAUU_LL_LLLOOO”。
我们有一些步骤来清理这个输出。首先,我们将任何重复的字符替换为单个字符:

然后我们将删除任何空白:

这给我们留下了三种可能的转录——“Hello”、“Hullo”和“Aullo”。如果你大声说出来,所有这些听起来都类似于“你好”。因为它一次预测一个字符,所以神经网络会提出这些非常可靠的转录。例如,如果您说“He would not go”,它可能会给出一种可能的转录为“He wud net go”。
诀窍是将这些基于发音的预测与基于大型书面文本(书籍、新闻文章等)数据库的似然分数相结合。你扔掉看起来最不可能是真实的抄本并保留看起来最真实的抄本。
在我们可能的转录“Hello”、“Hullo”和“Aullo”中,显然“Hello”会更频繁地出现在文本数据库中(更不用说在我们原始的基于音频的训练数据中),因此可能是正确的。所以我们将选择“Hello”作为我们的最终转录而不是其他。完毕!
等一下!
你可能会想“但是如果有人说‘Hello’怎么办?这是一个有效的词。也许‘你好’是错误的转录!”

当然,有可能有人实际上说的是“你好”而不是“你好”。但是像这样的语音识别系统(接受美式英语训练)基本上永远不会产生“Hullo”作为转录。与“Hello”相比,用户不太可能说出这样的话,无论你多么强调“U”的发音,它总是会认为你在说“Hello”。
试试看!如果你的手机设置为美国英语,试着让你手机的数字助理识别世界“你好”。你不能!它拒绝!它总是会把它理解为“你好”。
不识别“你好”是一种合理的行为,但有时你会发现你的手机拒绝理解你所说的有效内容的烦人情况。这就是为什么总是用更多数据对这些语音识别模型进行再训练以修复这些边缘情况的原因。
我可以构建自己的语音识别系统吗?
机器学习最酷的事情之一就是它有时看起来很简单。你得到一堆数据,将其输入机器学习算法,然后神奇地在你的游戏笔记本电脑的视频卡上运行了一个世界级的人工智能系统……对吧?
在某些情况下确实如此,但对于演讲而言则不然。识别语音是一个难题。您必须克服几乎无限的挑战:质量差的麦克风、背景噪音、混响和回声、口音变化等等。所有这些问题都需要出现在你的训练数据中,以确保神经网络能够处理它们。
这是另一个例子:你知道吗,当你在嘈杂的房间里说话时,你会不自觉地提高声音的音调,以便能够盖过噪音说话?无论哪种方式,人类都可以理解你,但需要训练神经网络来处理这种特殊情况。所以你需要训练数据和人们在噪音中大喊大叫!
要构建一个性能达到 Siri、Google Now! 或 Alexa 级别的语音识别系统,您将需要大量训练数据——远远超过您在不雇用数百人为您记录的情况下可能获得的数据。而且由于用户对质量差的语音识别系统的容忍度很低,因此您不能吝啬这一点。没有人想要一个 80% 的时间都能工作的语音识别系统。
对于像谷歌或亚马逊这样的公司来说,在现实生活中录制的数十万小时的语音音频是黄金。这是将他们的世界级语音识别系统与您的爱好系统区分开来的最大因素。Google Now 的全部意义所在!免费在每部手机上安装 Siri 或出售 50 美元不收取订阅费的 Alexa 设备是为了让您尽可能多地使用它们。你对其中一个系统说的每一件事都会被永久记录下来,并用作未来版本语音识别算法的训练数据。这就是整个游戏!