如果一个机器学习初学者,仅用三行代码就训练了一个模型,并且模型的性能要比从业数十年的都要好,这是一种什么样的感觉?
AutoGluon就能帮你梦想成真。
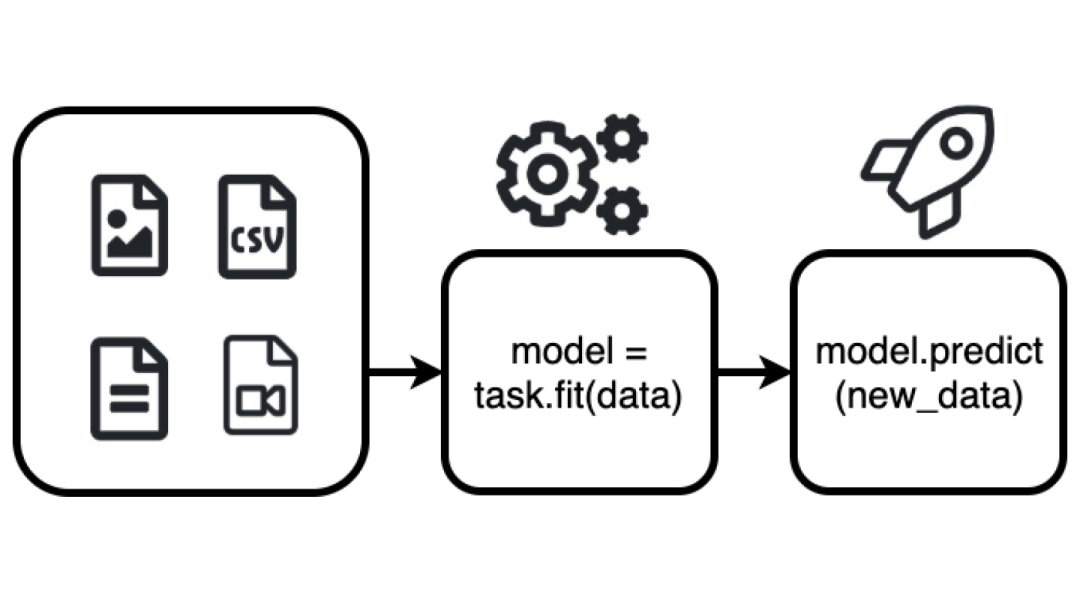
上面这张图片就是AutoGluon的工作流,多么简单啊!根据数据类型(问题定义)实例化任务,仅通过一个fit函数就完成了训练过程,仅通过一个predict函数就完成了对新数据的预测过程。
那么,模型,损失函数,优化器,超参数的选择哪去了?
所有这一切AutoGluon都帮你做了。
AutoML(一):概述
AutoML(二):微软NNI框架
AutoML(三):利用贝叶斯优化进行超参数搜索
https://nni.readthedocs.io/en/stable/index.html
我之前介绍过微软的NNI,同样是AutoML工具,为什么还要介绍AutoGluon呢?
因为NNI不够亲民。
来看一下NNI是如何进行超参数搜索的?
Step1:准备模型
Step2:定义搜索空间
Step3:配置实验
配置实验代码
配置搜索空间
配置微调算法
配置实验次数
Step4:开始实验
实验可以理解为一个超参数搜索过程,为什么说它不够亲民呢?
第一步你需要自己选择模型,可我是个初学者,我咋知道选择什么模型?我甚至连模型是啥都不知道,就算有点经验的人,在是选择传统的机器学习还是神经网络方面也会犯糊涂,毕竟,就连吴恩达老师在这个问题上都承认犯过错误。
可见,选择多了也不是什么好事。
可这还没完,接下来你仍然要面临选择,例如,传统机器学习中能完成分类任务的也不止一个,有基于树的分类器:决策树,提升树,贝叶斯分类器,逻辑回归,SVM等等。
神经网络中也有卷积神经网络CNN,前馈神经网络类ANN以及循环神经网络RNN,仍然要面临类似的选择问题,例如,对于NLP任务,大家首先想到的是RNN,但你可知道CNN也能完成同样的任务。
第二步你需要自己定义搜索空间,空间定义大了,搜索过程会慢,定义小了会错过最优解,甚至连划分粒度都得小心翼翼。
第三步中你需要自己定义搜索算法,是选择基于贝叶斯优化的搜索算法还是强化学习的搜索算法?虽然是个选择题,可是选择哪个鬼真是一点思路都没有啊!
。。。
之前对NNI的一顿吹真是啪啪打自己的脸?
总结来说,不是NNI不好,而是NNI需要有一定的经验和基础。
封装程度
NNI的问题在AutoGluon中三行代码就搞定了。
可见,AutoGluon的封装程度很高。什么是封装程度呢?
举个例子,要使用GPU的并行计算能力。
你是个软件工程师,不想触碰硬件,显卡驱动代替你与硬件交流,你就不用读硬件手册,不用了解寄存器或者总线地址什么的了。
可你仍然不想内核编程,所以CUDA出现了,CUDA代替你与驱动交流,你就不用去了解系统调用等复杂的API了。
可是面对浩如烟海的CUDA API仍然令人头疼,所以机器学习框架代替你与CUDA交流,你只需要一句话device=“gpu”就用上并行计算了。
但封装程度越高,也就意味着可控程度越低。
如何使用AutoGluon?
官方网址:
https://auto.gluon.ai
源码:
https://github.com/autogluon/autogluon
使用AutoGluon,你的工作重心就一个:选择任务类型。
每一个任务类型都有两个重要的角色:DataSet和Predictor。前者用于处理数据,后者用于拟合模型。
在AutoGluon中有三种任务类型。表格任务,多模态任务,以及时序任务。
表格任务
机器学习界的hello world想必你肯定知道吧,加利福尼亚房价预测,也就是输入房屋的面积,房间数,是否邻街道等等特征,输出预测的房价。

我们通常把这种类型的数据称为表格数据。
能处理表格数据的任务就是表格任务。对应的DataSet和Predictor为TabularDataset和TabularPredictor。
来看一个具体的例子:
使用TabularDataset加载数据,可以加载网络数据也可以加载本地数据。
重要的是,你不需要进行数据预处理操作,AutoGluon会帮你数据清理,归一化,异常值处理等操作。
data_url = 'https://raw.githubusercontent.com/mli/ag-docs/main/knot_theory/'
train_data = TabularDataset(f'{data_url}train.csv')
train_data.head()
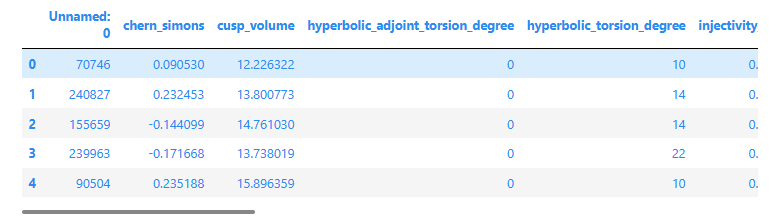
除此之外,还可以输出数据的统计信息。
label = 'signature'
train_data[label].describe()
count 10000.000000
mean -0.022000
std 3.025166
min -12.000000
25% -2.000000
50% 0.000000
75% 2.000000
max 12.000000
Name: signature, dtype: float64
label = 'signature’指定输出列,这很重要,因为后续要根据这个选择模型,之后就可以模型训练了。
predictor = TabularPredictor(label=label).fit(train_data)
虽然一行代码就搞定了。但通过日志可知它背着我们做了很多事。
No path specified. Models will be saved in: "AutogluonModels/ag-20230913_185705/"
Beginning AutoGluon training ...
AutoGluon will save models to "AutogluonModels/ag-20230913_185705/"
AutoGluon Version: 0.8.2b20230913
Python Version: 3.10.8
Operating System: Linux
Platform Machine: x86_64
Platform Version: #1 SMP Tue Nov 30 00:17:50 UTC 2021
Disk Space Avail: 226.64 GB / 274.87 GB (82.5%)
Train Data Rows: 10000
Train Data Columns: 18
Label Column: signature
Preprocessing data ...
AutoGluon infers your prediction problem is: 'multiclass' (because dtype of label-column == int, but few unique label-values observed).
First 10 (of 13) unique label values: [-2, 0, 2, -8, 4, -4, -6, 8, 6, 10]
If 'multiclass' is not the correct problem_type, please manually specify the problem_type parameter during predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Warning: Some classes in the training set have fewer than 10 examples. AutoGluon will only keep 9 out of 13 classes for training and will not try to predict the rare classes. To keep more classes, increase the number of datapoints from these rare classes in the training data or reduce label_count_threshold.
Fraction of data from classes with at least 10 examples that will be kept for training models: 0.9984
Train Data Class Count: 9
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
Available Memory: 31055.66 MB
Train Data (Original) Memory Usage: 1.44 MB (0.0% of available memory)
Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.
Stage 1 Generators:
Fitting AsTypeFeatureGenerator...
Note: Converting 5 features to boolean dtype as they only contain 2 unique values.
Stage 2 Generators:
Fitting FillNaFeatureGenerator...
Stage 3 Generators:
Fitting IdentityFeatureGenerator...
Stage 4 Generators:
Fitting DropUniqueFeatureGenerator...
Stage 5 Generators:
Fitting DropDuplicatesFeatureGenerator...
Useless Original Features (Count: 1): ['Symmetry_D8']
These features carry no predictive signal and should be manually investigated.
This is typically a feature which has the same value for all rows.
These features do not need to be present at inference time.
Types of features in original data (raw dtype, special dtypes):
('float', []) : 14 | ['chern_simons', 'cusp_volume', 'injectivity_radius', 'longitudinal_translation', 'meridinal_translation_imag', ...]
('int', []) : 3 | ['Unnamed: 0', 'hyperbolic_adjoint_torsion_degree', 'hyperbolic_torsion_degree']
Types of features in processed data (raw dtype, special dtypes):
('float', []) : 9 | ['chern_simons', 'cusp_volume', 'injectivity_radius', 'longitudinal_translation', 'meridinal_translation_imag', ...]
('int', []) : 3 | ['Unnamed: 0', 'hyperbolic_adjoint_torsion_degree', 'hyperbolic_torsion_degree']
('int', ['bool']) : 5 | ['Symmetry_0', 'Symmetry_D3', 'Symmetry_D4', 'Symmetry_D6', 'Symmetry_Z/2 + Z/2']
0.1s = Fit runtime
17 features in original data used to generate 17 features in processed data.
Train Data (Processed) Memory Usage: 1.01 MB (0.0% of available memory)
Data preprocessing and feature engineering runtime = 0.08s ...
AutoGluon will gauge predictive performance using evaluation metric: 'accuracy'
To change this, specify the eval_metric parameter of Predictor()
Automatically generating train/validation split with holdout_frac=0.1, Train Rows: 8985, Val Rows: 999
User-specified model hyperparameters to be fit:
{
'NN_TORCH': {},
'GBM': [{'extra_trees': True, 'ag_args': {'name_suffix': 'XT'}}, {}, 'GBMLarge'],
'CAT': {},
'XGB': {},
'FASTAI': {},
'RF': [{'criterion': 'gini', 'ag_args': {'name_suffix': 'Gini', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'entropy', 'ag_args': {'name_suffix': 'Entr', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'squared_error', 'ag_args': {'name_suffix': 'MSE', 'problem_types': ['regression', 'quantile']}}],
'XT': [{'criterion': 'gini', 'ag_args': {'name_suffix': 'Gini', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'entropy', 'ag_args': {'name_suffix': 'Entr', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'squared_error', 'ag_args': {'name_suffix': 'MSE', 'problem_types': ['regression', 'quantile']}}],
'KNN': [{'weights': 'uniform', 'ag_args': {'name_suffix': 'Unif'}}, {'weights': 'distance', 'ag_args': {'name_suffix': 'Dist'}}],
}
Fitting 13 L1 models ...
Fitting model: KNeighborsUnif ...
0.2232 = Validation score (accuracy)
0.02s = Training runtime
0.02s = Validation runtime
Fitting model: KNeighborsDist ...
0.2132 = Validation score (accuracy)
0.02s = Training runtime
0.01s = Validation runtime
Fitting model: NeuralNetFastAI ...
0.9429 = Validation score (accuracy)
9.56s = Training runtime
0.01s = Validation runtime
Fitting model: LightGBMXT ...
0.9459 = Validation score (accuracy)
4.08s = Training runtime
0.05s = Validation runtime
Fitting model: LightGBM ...
0.956 = Validation score (accuracy)
3.69s = Training runtime
0.03s = Validation runtime
Fitting model: RandomForestGini ...
0.9449 = Validation score (accuracy)
1.2s = Training runtime
0.11s = Validation runtime
Fitting model: RandomForestEntr ...
0.9499 = Validation score (accuracy)
1.62s = Training runtime
0.11s = Validation runtime
Fitting model: CatBoost ...
0.956 = Validation score (accuracy)
21.26s = Training runtime
0.01s = Validation runtime
Fitting model: ExtraTreesGini ...
0.9469 = Validation score (accuracy)
0.97s = Training runtime
0.1s = Validation runtime
Fitting model: ExtraTreesEntr ...
0.9429 = Validation score (accuracy)
0.95s = Training runtime
0.11s = Validation runtime
Fitting model: XGBoost ...
0.957 = Validation score (accuracy)
5.08s = Training runtime
0.08s = Validation runtime
Fitting model: NeuralNetTorch ...
0.9409 = Validation score (accuracy)
33.75s = Training runtime
0.01s = Validation runtime
Fitting model: LightGBMLarge ...
0.9499 = Validation score (accuracy)
9.33s = Training runtime
0.07s = Validation runtime
Fitting model: WeightedEnsemble_L2 ...
0.964 = Validation score (accuracy)
0.52s = Training runtime
0.0s = Validation runtime
AutoGluon training complete, total runtime = 94.25s ... Best model: "WeightedEnsemble_L2"
TabularPredictor saved. To load, use: predictor = TabularPredictor.load("AutogluonModels/ag-20230913_185705/")
通过日志可知,它首先进行特征工程,根据输出列数据类型判断是分类任务还是回归任务,然后训练了多个模型,并将多个模型集成到一起作为最终模型。
同样一行代码就完成了新数据的预测。
test_data = TabularDataset(f'{data_url}test.csv')
y_pred = predictor.predict(test_data.drop(columns=[label]))
y_pred.head()
0 -4
1 -2
2 0
3 4
4 2
Name: signature, dtype: int64
多模态任务
MultiModalPredictor包含各种深度学习模型,用于处理多模态输入,例如,图像,文本,表格数据。
AutoGluon能自动识别数据类型,例如,AutoGluon的多模态数据格式要求,图像列应包含一个字符串,该字符串的值为指向单个图像文件的路径。
举个例子,根据宠物的文本描述,体重等表格特征,以及宠物的图片来预测宠物的被收养率。
解压数据
from autogluon.core.utils.loaders import load_zip
download_dir = './ag_multimodal_tutorial'
zip_file = 'https://automl-mm-bench.s3.amazonaws.com/petfinder_for_tutorial.zip'
load_zip.unzip(zip_file, unzip_dir=download_dir)
使用pandas读取CSV文件,并转换成DataFrame格式,指定输出列。
import pandas as pd
dataset_path = f'{download_dir}/petfinder_for_tutorial'
train_data = pd.read_csv(f'{dataset_path}/train.csv', index_col=0)
test_data = pd.read_csv(f'{dataset_path}/test.csv', index_col=0)
label_col = 'AdoptionSpeed'
将图像列转换为标准路径格式。
image_col = 'Images'
train_data[image_col] = train_data[image_col].apply(lambda ele: ele.split(';')[0])
test_data[image_col] = test_data[image_col].apply(lambda ele: ele.split(';')[0])
def path_expander(path, base_folder):
path_l = path.split(';')
return ';'.join([os.path.abspath(os.path.join(base_folder, path)) for path in path_l])
train_data[image_col] = train_data[image_col].apply(lambda ele: path_expander(ele, base_folder=dataset_path))
test_data[image_col] = test_data[image_col].apply(lambda ele: path_expander(ele, base_folder=dataset_path))
开始训练
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor(label=label_col).fit(
train_data=train_data,
time_limit=120
)
No path specified. Models will be saved in: "AutogluonModels/ag-20230913_184512/"
AutoGluon infers your prediction problem is: 'binary' (because only two unique label-values observed).
2 unique label values: [0, 1]
If 'binary' is not the correct problem_type, please manually specify the problem_type parameter during predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
INFO:lightning_fabric.utilities.seed:Global seed set to 0
AutoMM starts to create your model. ✨
- AutoGluon version is 0.8.2b20230913.
- Pytorch version is 1.13.1+cu117.
- Model will be saved to "/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/AutogluonModels/ag-20230913_184512".
- Validation metric is "roc_auc".
- To track the learning progress, you can open a terminal and launch Tensorboard:
```shell
# Assume you have installed tensorboard
tensorboard --logdir /home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/AutogluonModels/ag-20230913_184512
```
Enjoy your coffee, and let AutoMM do the job ☕☕☕ Learn more at https://auto.gluon.ai
1 GPUs are detected, and 1 GPUs will be used.
- GPU 0 name: Tesla T4
- GPU 0 memory: 15.74GB/15.84GB (Free/Total)
CUDA version is 11.7.
INFO:pytorch_lightning.utilities.rank_zero:Using 16bit None Automatic Mixed Precision (AMP)
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
INFO:pytorch_lightning.callbacks.model_summary:
| Name | Type | Params
----------------------------------------------------------
0 | model | MultimodalFusionMLP | 198 M
1 | validation_metric | BinaryAUROC | 0
2 | loss_func | CrossEntropyLoss | 0
----------------------------------------------------------
198 M Trainable params
0 Non-trainable params
198 M Total params
396.017 Total estimated model params size (MB)
INFO:pytorch_lightning.utilities.rank_zero:Epoch 0, global step 1: 'val_roc_auc' reached 0.44559 (best 0.44559), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/AutogluonModels/ag-20230913_184512/epoch=0-step=1.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 0, global step 4: 'val_roc_auc' reached 0.67578 (best 0.67578), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/AutogluonModels/ag-20230913_184512/epoch=0-step=4.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 1, global step 5: 'val_roc_auc' reached 0.68862 (best 0.68862), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/AutogluonModels/ag-20230913_184512/epoch=1-step=5.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 1, global step 8: 'val_roc_auc' reached 0.75642 (best 0.75642), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/AutogluonModels/ag-20230913_184512/epoch=1-step=8.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 2, global step 9: 'val_roc_auc' reached 0.76535 (best 0.76535), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/AutogluonModels/ag-20230913_184512/epoch=2-step=9.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Epoch 2, global step 12: 'val_roc_auc' reached 0.75642 (best 0.76535), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/AutogluonModels/ag-20230913_184512/epoch=2-step=12.ckpt' as top 3
INFO:pytorch_lightning.utilities.rank_zero:Time limit reached. Elapsed time is 0:02:04. Signaling Trainer to stop.
Start to fuse 3 checkpoints via the greedy soup algorithm.
AutoMM has created your model 🎉🎉🎉
- To load the model, use the code below:
```python
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor.load("/home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/AutogluonModels/ag-20230913_184512")
```
- You can open a terminal and launch Tensorboard to visualize the training log:
```shell
# Assume you have installed tensorboard
tensorboard --logdir /home/ci/autogluon/docs/tutorials/multimodal/multimodal_prediction/AutogluonModels/ag-20230913_184512
```
- If you are not satisfied with the model, try to increase the training time,
adjust the hyperparameters (https://auto.gluon.ai/stable/tutorials/multimodal/advanced_topics/customization.html),
or post issues on GitHub: https://github.com/autogluon/autogluon
根据日志可知AutoGluon选择了MultimodalFusionMLP模型,也就是将提取的图像特征,文本特征以及表格特征拼接到一起,然后送入MLP网络。
因为输出的是概率,所以选择了交叉熵损失函数。
时序任务
时序任务的对应的DataSet和Predictor为TimeSeriesDataFrame和TimeSeriesPredictor。
例如,用AutoGluon预测未来某个时间的股票值。
加载数据
import pandas as pd
from autogluon.timeseries import TimeSeriesDataFrame, TimeSeriesPredictor
df = pd.read_csv("https://autogluon.s3.amazonaws.com/datasets/timeseries/m4_hourly_subset/train.csv")
df.head()
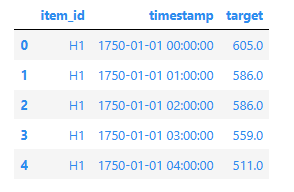
转换为TimeSeriesDataFrame格式
train_data = TimeSeriesDataFrame.from_data_frame(
df,
id_column="item_id",
timestamp_column="timestamp"
)
train_data.head()
target为输出列。
模型训练
predictor = TimeSeriesPredictor(
prediction_length=48,
path="autogluon-m4-hourly",
target="target",
eval_metric="MASE",
)
predictor.fit(
train_data,
presets="medium_quality",
time_limit=600,
)
================ TimeSeriesPredictor ================
TimeSeriesPredictor.fit() called
Setting presets to: medium_quality
Fitting with arguments:
{'enable_ensemble': True,
'evaluation_metric': 'MASE',
'excluded_model_types': None,
'hyperparameter_tune_kwargs': None,
'hyperparameters': 'medium_quality',
'num_val_windows': 1,
'prediction_length': 48,
'random_seed': None,
'target': 'target',
'time_limit': 600,
'verbosity': 2}
Provided training data set with 148060 rows, 200 items (item = single time series). Average time series length is 740.3. Data frequency is 'H'.
=====================================================
AutoGluon will save models to autogluon-m4-hourly/
AutoGluon will gauge predictive performance using evaluation metric: 'MASE'
This metric's sign has been flipped to adhere to being 'higher is better'. The reported score can be multiplied by -1 to get the metric value.
Provided dataset contains following columns:
target: 'target'
Starting training. Start time is 2023-09-13 18:41:37
Models that will be trained: ['Naive', 'SeasonalNaive', 'Theta', 'AutoETS', 'RecursiveTabular', 'DeepAR']
Training timeseries model Naive. Training for up to 599.78s of the 599.78s of remaining time.
-6.6629 = Validation score (-MASE)
0.13 s = Training runtime
4.21 s = Validation (prediction) runtime
Training timeseries model SeasonalNaive. Training for up to 595.43s of the 595.43s of remaining time.
-1.2169 = Validation score (-MASE)
0.12 s = Training runtime
0.22 s = Validation (prediction) runtime
Training timeseries model Theta. Training for up to 595.08s of the 595.08s of remaining time.
-2.1425 = Validation score (-MASE)
0.12 s = Training runtime
28.63 s = Validation (prediction) runtime
Training timeseries model AutoETS. Training for up to 566.32s of the 566.32s of remaining time.
-1.9399 = Validation score (-MASE)
0.12 s = Training runtime
103.07 s = Validation (prediction) runtime
Training timeseries model RecursiveTabular. Training for up to 463.12s of the 463.12s of remaining time.
-0.8988 = Validation score (-MASE)
14.48 s = Training runtime
2.50 s = Validation (prediction) runtime
Training timeseries model DeepAR. Training for up to 446.13s of the 446.13s of remaining time.
-1.2728 = Validation score (-MASE)
92.80 s = Training runtime
2.01 s = Validation (prediction) runtime
Fitting simple weighted ensemble.
-0.8836 = Validation score (-MASE)
5.99 s = Training runtime
107.80 s = Validation (prediction) runtime
Training complete. Models trained: ['Naive', 'SeasonalNaive', 'Theta', 'AutoETS', 'RecursiveTabular', 'DeepAR', 'WeightedEnsemble']
Total runtime: 254.76 s
Best model: WeightedEnsemble
Best model score: -0.8836
AutoGluon会训练多个模型,并按照性能排序。