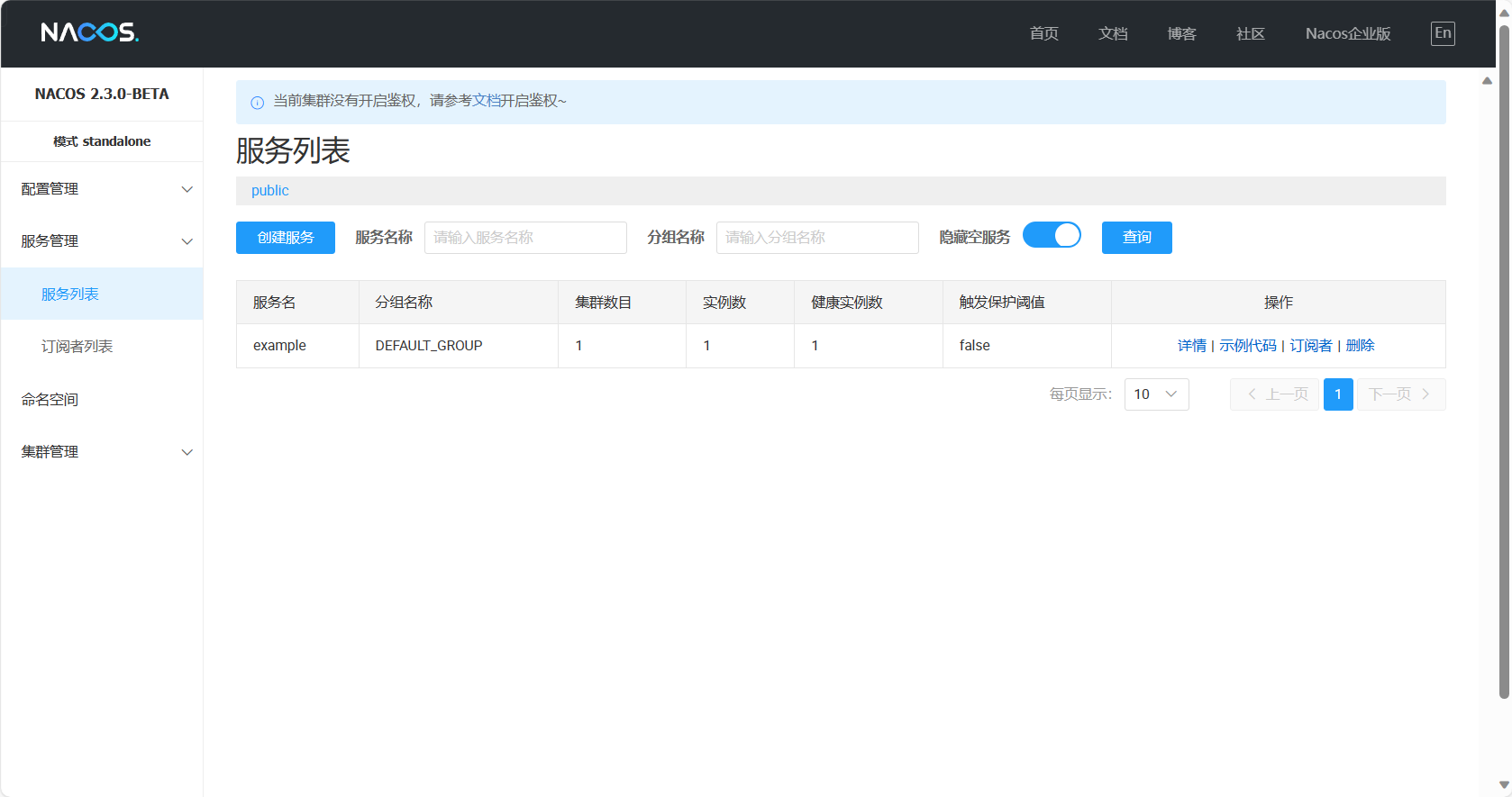
自己配置开发环境的时候踩了不少坑,现在记录下来,以后需要了可以直接找到现成的代码,也希望能够帮到有需要的小伙伴
目录
- (一)、运行环境搭建
- 1、Anaconda部分
- Anaconda安装
- Anaconda创建虚拟环境指令
- Anaconda Prompt工作路径的切换
- 2、 PaddleOcr部分
- paddleocr 安装
- 点击这里实现下载:
- paddleocr其他依赖库安装
- 3、Paddle部分
- paddle2.5.1安装CPU版本
- 4、 验证环境
- (二)、训练属于自己的模型
- 1、数据准备
- (1)、数据标注
- (2)、数据集制作
- 2、训练文字检测模型
- (1)、下载模型训练文件:
- (2)、 配置模型文件
- (3)、开始训练
- (4)、测试训练模型
- 3、训练文字识别模型
- (1)、 配置模型文件
- (2)、模型训练
- (3)、模型测试
- 4、转换成推理模型
- 5、推理模型应用
- 三、总结
- (1)、File No found文件没找到:
- 01、paddleocr里面的文件没找到
- 02、paddle里面的文件没找到
- (2)Import Error:
- (3)Os相关的报错
- 四、参考博客
(一)、运行环境搭建
1、Anaconda部分
Anaconda安装
本站有很多安装教程,我就不再重复造车轮了,选了一个讲的比较详细的,可以参考使用Anaconda安装教程
Anaconda创建虚拟环境指令
在开始菜单搜索Anaconda,点击以下应用进入anaconda终端。

输入以下代码用来创建虚拟环境,Al_Ocr为虚拟环境命名,可以自己取名字,后面是要安装的python版本。
conda create -n Al_Ocr python=3.8
如图



#进入虚拟环境指令
activate Al_Oc
#离开虚拟环境指令
deactivate
Anaconda Prompt工作路径的切换
因为我遇到的情况需要切换代码执行路径,所以也记录一下切换方法
# 切换到根目录
cd /
# 切换到D盘
D:
# 切换到D盘指定目录
cd D:\Anaconda\envs\Al_Ocr\Lib\site-packages\PaddleOCR-release-2.5

2、 PaddleOcr部分
paddleocr 安装
点击这里实现下载:
paddleocr下载
下载完成之后解压缩到当前虚拟环境中的sitepakges目录下,比如我这个目录是
D:\Anaconda\envs\Al_Ocr\Lib\site-packages\paddleocr
paddleocr其他依赖库安装
打开anaconda终端,进入PaddleOC目录下激活环境并输入以下指令
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
3、Paddle部分
paddle2.5.1安装CPU版本
python -m pip install paddlepaddle==2.5.1 -i https://mirror.baidu.com/pypi/simpl
【顺利就不用看这里】如果出现以下错误可以换地址重新安装
ERROR: HTTP error 403 while getting https://pypi.tuna.tsinghua.edu.cn/packages/0
报上面的错误信息换成下面的地址下载和安装
python -m pip install paddlepaddle==2.5.1 -i https://pypi.douban.com/simpl
需要先升级:
python.exe -m pip install --upgrade pi
4、 验证环境
进入以下网址下载官方模型:
https://hub.nuaa.cf/PaddlePaddle/PaddleOCR/blob/release/2.7/doc/doc_ch/models_list.md
官网模型下载链接直达
需要下载两个模型用来进行验证,分别为文本检测模型和文本识别模型,选择下载推理模型
文本检测模型

文本识别模型

模型下载后为两个压缩包,在PaddleOCR根目录下新建文件夹inference_model

将下载好的模型解压缩在刚刚新建的文件夹,处理好是这样的层级

打开anaconda终端激活环境Al_Ocr进入到paddleocr目录下运行以下指令,其中image_dir为所要识别的图片路径,det_model_dir为刚才下载的文字检测模型,rec_model_dir为刚才下载的文字识别模型。
python tools/infer/predict_system.py --image_dir="D:\OCR\New_model\cut1\test.jpg" --det_model_dir="./inference_model/ch_PP-OCRv3_det_infer/" --rec_model_dir="./inference_model/ch_PP-OCRv3_rec_infer"
原图如下:


如果出现上面的界面,说明环境搭建成功,接下来就是训练自己的模型了
(二)、训练属于自己的模型
1、数据准备
(1)、数据标注
在Anaconda Prompt终端进入paddleOC根目录下,再输入
cd PPOCRLabel 进入目录,
cd PPOCRLabel
输入以下代码打开打标软件
python PPOCRLabel.py --lang ch
如果报错说PPCORLabel没找到,就去安装一下PPOCORLabel库
pip install PPOCRLabel
#如果运行了这一步,后面切换执行文件时应该在.\site-packages\PPOCRLabel,而不是.\site-packages\paddleocr\PPOCRLabel,如果还想按照之前的地址执行就需要把PPOCRLabel文件夹复制到paddleocr文件夹下
打开后点击文件,点击打开目录选择需要打标签的数据集文件夹,我这以刚刚的截图为例。如下图所示。

选择自动标注点击ok等待自动标注完成

然后从第一张开始检查,漏打标的按下Q框出字体,打标文字错误的,点击方框,在右边修改,并对每一个方框给出关键词列表(点击编辑点击更改box关键词信息)。最后删除无用信息,切换下一张快捷键为D,如下图所示。

全部打标完成之后,点击文件选择导出标记结果,再点击文件选择导出识别结果,完成后再文件夹多出四个文件fileState,Label,rec_gt, crop_img。其中crop_img中的图片用来训练文字识别模型,fileState记录图片的打标完成与否,Label为训练文字检测模型的标签,rec_gt为训练文字识别模型的标签。

打标签告一段落。下面进行数据集的制作。
(2)、数据集制作
在PaddleOCR根目录下建立train_data文件夹,并且将打标签生成的文件和图片放在该文件夹下

打开Anaconda Prompt终端进入PPOCRLabel的文件夹下,输入以下代码进行数据集的划分
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ../train_data/drivingData
输入指令之后,在train_data文件夹下会出现以下文件,其中det是用来训练文字检测的数据集,rec是用来训练文字识别的数据集。此时可以删去drivingData。


此时文字检测和文字识别的数据集就都制作好了。
2、训练文字检测模型
(1)、下载模型训练文件:
模型下载链接直达
https://hub.nuaa.cf/PaddlePaddle/PaddleOCR/blob/release/2.7/doc/doc_ch/models_list.md
在上面网站下载官方训练模型,注意不是推理模型。
文本检测模型:

文本识别模型:

下载之后在paddleocr根目录下建立pretrain_models文件夹,并将训练模型解压至该文件夹下。如下图所示:

(2)、 配置模型文件
下面配置模型文件。
打开模型配置文件,如下图所示,我一般用ch_det_res18_db_v2.0.yml这个配置文件。

对于配置文件的说明可以查看官网的说明文件,链接放在这里了
配置文件说明
https://hub.nuaa.cf/PaddlePaddle/PaddleOCR/blob/release/2.7/doc/doc_ch/config.md
我们需要手动更改的有以下几个地方:


 配置好了之后就可以开始训练了
配置好了之后就可以开始训练了
(3)、开始训练
打开anaconda prompt终端,激活环境进入到paddleocr根目录下。输入以下指令开始模型训练。
python tools/train.py -c configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml



如果报错说yaml没找到的话我们手动安装一下即可
pip install pyyaml
(4)、测试训练模型
模型训练完之后会在文件夹下保存训练好的模型,具体保存的文件夹看配置文件,这就是模型保存的路径。
save_model_dir: ./output/ch_db_res18/
打开文件夹,文件组成大概如下图所示。

我们使用best_accuracy.pdparams进行我们的模型测试。
在anaconda prompt终端中输入以下指令进行测试。 其中Global.pretrained_model是我们训练好并且需要测试的模型,Global.infer_img为所要检测的图片路径。
python tools/infer_det.py -c configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml -o Global.pretrained_model=output/ch_db_driving/best_accuracy.pdparams Global.infer_img="D:\Anaconda\envs\Al_Ocr\Lib\site-packages\paddleocr\train_data\det\test\1.jpg"
测试结果图片没有
文字检测模型的训练和测试就告一段落,下面进行文字识别模型的训练和测试。
3、训练文字识别模型
(1)、 配置模型文件
在第三节已经下载了文字识别的模型所以不再多叙述。文字识别我一般使用的配置文件为ch_PP-OCRv3_rec.yml

修改的地方和文字检测修改的差不多。



(2)、模型训练
打开anaconda prompt终端,激活环境进入到paddleocr根目录下。输入以下指令开始模型训练。
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
训练完之后模型保存路径和文件组成和文字检测差不多,不再多叙述。
(3)、模型测试
在anaconda prompt终端中输入以下指令进行测试。 其中Global.pretrained_model是我们训练好并且需要测试的模型,Global.infer_img为所要检测的图片路径。
python tools/infer_rec.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=output/rec/best_accuracy.pdparams Global.infer_img=“D:\Anaconda\envs\Al_Ocr\Lib\site-packages\paddleocr\train_data\rec\test\3.jpg”
文字识别模型的训练和测试就告一段落。
4、转换成推理模型
在anaconda prompt终端中输入以下指令进行测试。 其中Global.pretrained_model是我们训练好并且需要推理的模型,Global.save_inference_dir为所要保存推理模型的位置。推理模型是可以直接被调用进行识别和检测。分别把训练好的文字检测模型和文字识别模型推理。
文字检测模型推理
python tools/export_model.py -c "./configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml" -o Global.pretrained_model="./output/ch_db_driving/latest.pdparams" Global.save_inference_dir="./inference_model/det/"
文字识别模型推理
python tools/export_model.py -c "./configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml" -o Global.pretrained_model="./output/rec_mobile_pp-OCRv2/latest.pdparams" Global.save_inference_dir="./inference_model/rec/"
输入上面指令后推理模型将会出现在paddleoce根目录下文件夹inference_model,他的文件结构如下图所示。

其中det和rec即是我们的推理模型,可以用predict_system.py进行验证。打开anaconda终端输入以下指令
python tools/infer/predict_system.py --image_dir="D:\Anaconda\envs\Al_Ocr\Lib\site-packages\paddleocr\train_data\drivingData\0.jpg" --det_model_dir="./inference_model/det/" --rec_model_dir="./inference_model/rec"
识别图片会保存到inference_results文件夹下
5、推理模型应用
把模型训练出来之后还要对其进行应用,怎么去利用模型来实现我们需要的效果也是非常关键的一部分。
通过以下代码可以将咱们训练的模型在程序中调用,file_path为所要识别的图片路径,result为识别结果,texts是将结果中的纯文字部分提取出来进行下一步处理。
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(use_angle_cls=True, rec_model_dir='./inference_model/rec',
det_model_dir='./inference_model/det')
result = ocr.ocr(file_path, cls=True)
result = result[0]
texts = [line[1][0] for line in result]
三、总结
这一路搭建环境遇到了很多的坑,总结下来有三类:
(1)、File No found文件没找到:
01、paddleocr里面的文件没找到
有ppocr、PPOCRLabel,总之就是paddleocr下的任意文件没找到都会报错,解决办法就是去官网下载压缩包,解压
02、paddle里面的文件没找到
这个一定要根据自己机器的配置来,cpu版的装gpu版的包就会各种报错,解决办法就是卸载重装一遍
(2)Import Error:
这个一般都是因为包没找到,以及版本不兼容,建议通过requirements.txt安装
(3)Os相关的报错
这个是跟文件名以及分隔符与系统不匹配导致的,可以尝试往这个方向去解决
四、参考博客
这篇博客一来是记录了我自己实践的一些经验,踩的一些坑,为了避免后面换了一个设备搭建环境时再踩一遍,二来也做一个备份,我看到了一篇写的特别详细的教程,怕因为各种原因找不着了,所以改了改做成了自己的,方便后面找他
:
PaddleOCR训练属于自己的模型详细教程