📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前服务于工业互联网
擅长主流Oracle、MySQL、PG、高斯及Greenplum运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
- 前言
- 📣 1.关于Kafka
- 📣 2.环境准备
- ✨ 2.1 节点规划
- ✨ 2.2 防火墙及selinux
- ✨ 2.3 配置主机名
- ✨ 2.4 JDK环境
- 📣 3.zookeeper集群部署
- ✨ 3.1 解压安装
- ✨ 3.2 环境变量
- ✨ 3.3 集群配置
- ✨ 4.4 zookeeper管理
- 📣 4.kafka集群部署
- 📣 5.kafka 运维
- ✨ 5.1 kafka 命令
- ✨ 5.2 kafka-eagle部署
前言
Kafka 是一款高性能、高可靠性、可水平扩展的分布式消息队列系统📣 1.关于Kafka
Kafka 是一款高性能、高可靠性、可水平扩展的分布式消息队列系统,由 Apache 软件基金会开发和维护。它可以实现消息的异步处理和分布式计算,被广泛应用于大数据、实时数据流处理、监控报警等领域。
除了实现高效的分布式消息订阅之外,还提供数据实时流处理和数据存储功能。当然Kafka还可以将数据集成到大数据平台或者数据中台中.
官方网址:https://kafka.apache.org/
下载二进制安装包即可:kafka_2.13-3.5.1.tgz
📣 2.环境准备
✨ 2.1 节点规划

✨ 2.2 防火墙及selinux
##以下操作每个节点均操作
1.关闭防火墙
查看防火墙是状态
[root@Kafka1 ~]# systemctl status firewalld
关闭防火墙
[root@Kafka1 ~]# systemctl stop firewalld
取消开机自启动
[root@Kafka1 ~]# systemctl disable firewalld
Removed /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
2.关闭selinux
修改参数文件/etc/sysconfig/selinux中SELINUX的值为disabled
[root@Kafka1 ~]# sed -i ‘s/SELINUX=enforcing/SELINUX=disabled/g’ /etc/selinux/config
修改完成后需要重启服务器才生效
✨ 2.3 配置主机名
#每个节点做相关的操作
hostnamectl set-hostname kafka1
hostnamectl set-hostname kafka2
hostnamectl set-hostname kafka3
编辑host 文件
vi /etc/hosts
172.18.12.40 kafka1
172.18.12.41 kafka2
172.18.12.42 kafka3
✨ 2.4 JDK环境
JDK是 Java 语言的软件开发工具包,主要用于移动设备、嵌入式设备上的java应用程序
1.下载Linux环境下的jdk1.8
https://www.oracle.com/java/technologies/downloads/#java8
2.JDK压缩包解压
tar -zxvf jdk-8u391-linux-x64.tar.gz -C /usr/local
3.环境变量导入
vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_391
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
##环境变量生效
source /etc/profile
##确认安装是否成功
javac
java -version
[root@doris ~]# java -version
java version "1.8.0_391"
Java(TM) SE Runtime Environment (build 1.8.0_391-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.391-b13, mixed mode)
📣 3.zookeeper集群部署
直接从这个网址下载即可:https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/
安装前注意事项:
1)zookeeper节点必须是奇数个,因为zookeeper选举的规则:leader选举,要求可用节点数量必须大于总节点数量/2
2)zookeeper 是使用 java 来运行的,所以需要依赖 JDK,所以安装 zookeeper 之前需要安装部署 JDK
3) 注意关闭节点服务器的防火墙
这里要注意!!!官网上有两个tar.gz文件,bin名称结尾的包就是我们要下载的,可以直接使用。
里面有编译好的二进制包,上一个普通的tar.gz包只包含源码,不能直接使用。
在这里我们下载的是3.8.2版本
✨ 3.1 解压安装
tar -zxvf apache-zookeeper-3.8.2-bin.tar.gz
mv apache-zookeeper-3.8.2-bin /usr/local/zookeeper
✨ 3.2 环境变量
添加我们需要的配置信息,ZOOKEEPER_HOME 为你安装的zookeeper目录
vi /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH= J A V A H O M E / b i n : JAVA_HOME/bin: JAVAHOME/bin:JRE_HOME/bin: Z O O K E E P E R H O M E / b i n : ZOOKEEPER_HOME/bin: ZOOKEEPERHOME/bin:PATH
cat >> /etc/profile << "EOF"
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
EOF
##使环境变量生效
source /etc/profile
##查看是否生效
echo $ZOOKEEPER_HOME
✨ 3.3 集群配置
1)创建数据存储及日志目录
mkdir -p /usr/local/zookeeper/data
mkdir -p /usr/local/zookeeper/log
2)zookeeper配置文件
cd /usr/local/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
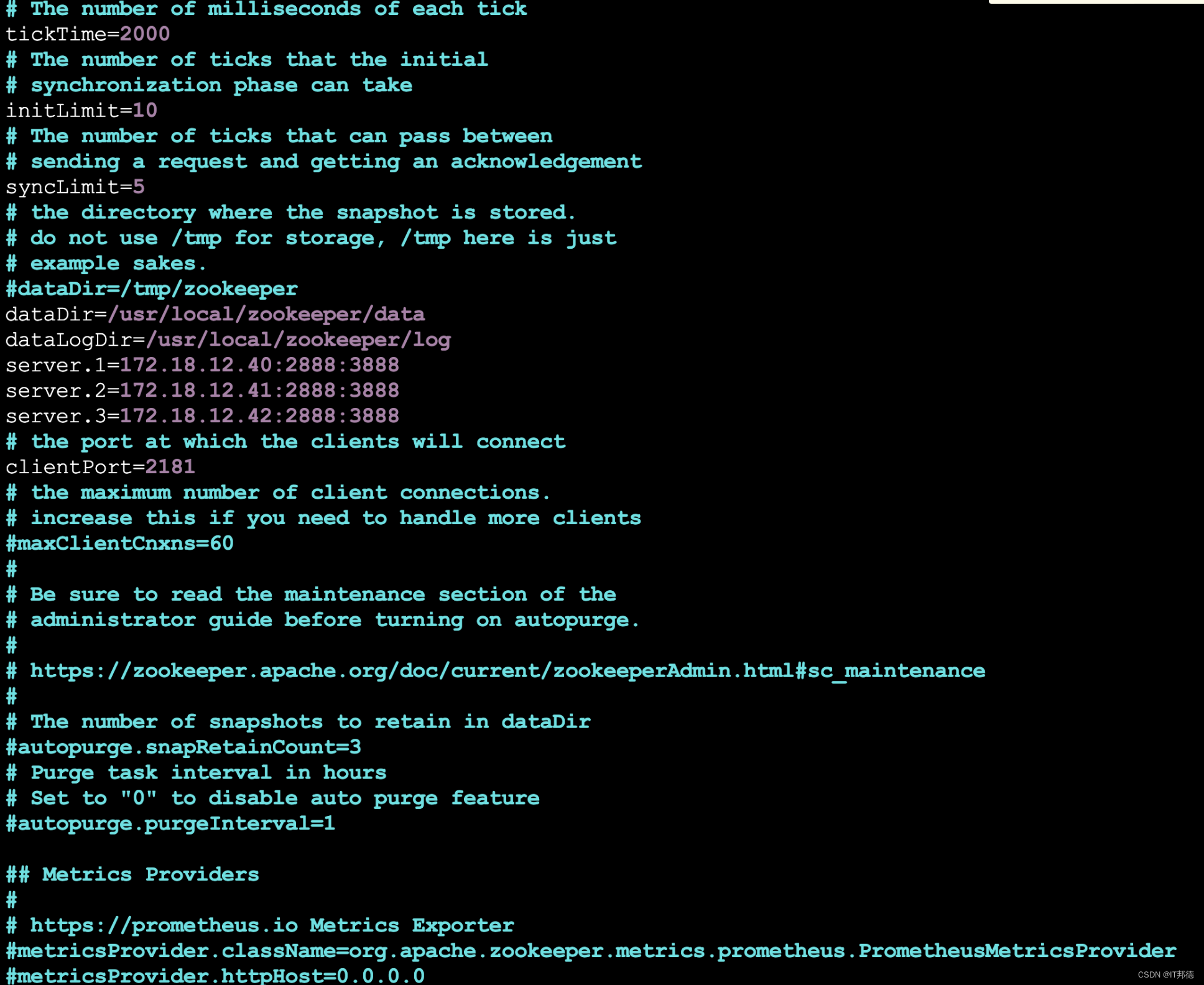
##修改以下内容
# 心跳时间
tickTime=2000
# follow连接leader的初始化连接时间,表示tickTime的倍数
initLimit=10
# syncLimit配置表示leader与follower之间发送消息,请求和应答时间长度。
如果followe在设置的时间内不能与leader进行通信,那么此follower将被丢弃,tickTime的倍数
syncLimit=5
# 客户端连接超时时间ms
maxClientCnxns=600
# 客户端连接端口,访问 zookeeper的端口
clientPort=2181
# 节点数据存储及日志目录,需要提前创建
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/log
server.1=172.18.12.40:2888:3888
server.2=172.18.12.41:2888:3888
server.3=172.18.12.42:2888:3888
3)每台机器配置节点id
##每台机器分别执行
在机器1上执行:
echo 1 >/usr/local/zookeeper/data/myid
在机器2上执行:
echo 2 >/usr/local/zookeeper/data/myid
在机器3上执行:
echo 3 >/usr/local/zookeeper/data/myid
✨ 4.4 zookeeper管理
1.手动启动
cd /usr/local/zookeeper/bin/
./zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/…/conf/zoo.cfg
Starting zookeeper … STARTED
##查看zookeeper启动状态
sh zkServer.sh status
[root@kafka1 bin]# sh zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/…/conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
##验证zookeeper
启动成功后可以随便选择一个节点尝试连接另一个节点验证
sh zkCli.sh -server 172.18.12.41:2181
成功进入后显示:
[zk: 172.18.12.41:2181(CONNECTED) 0]
📣 4.kafka集群部署
https://kafka.apache.org/downloads
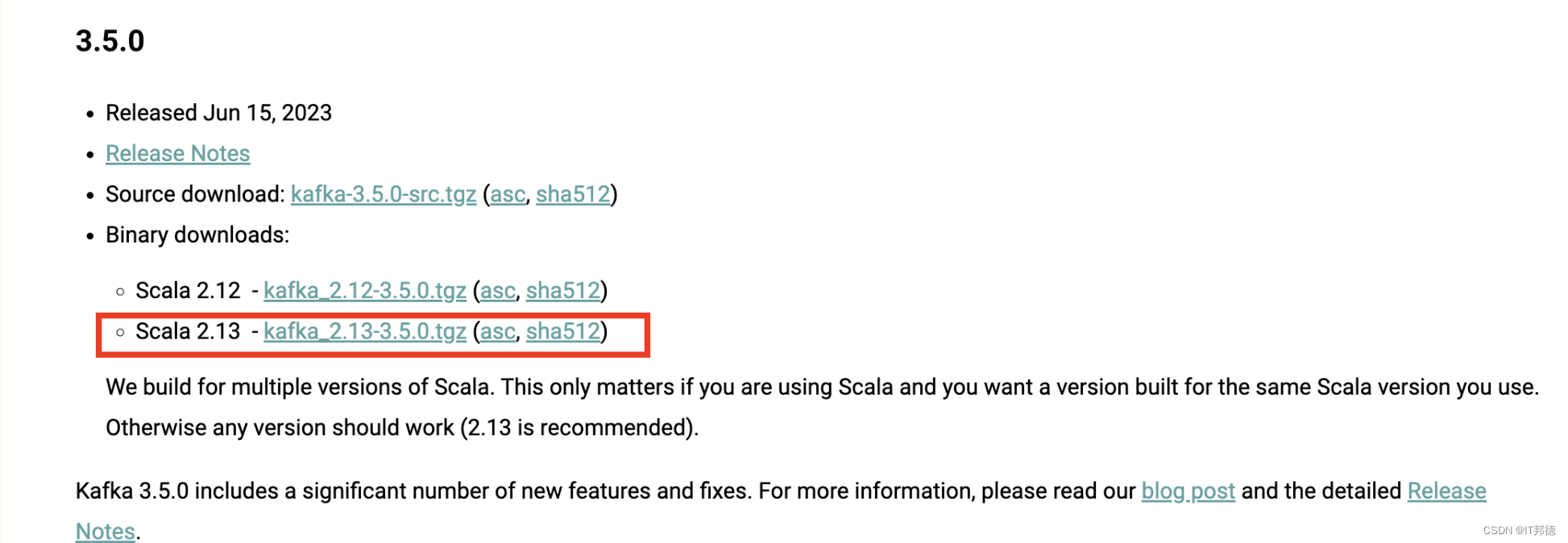
1.解压安装
mkdir -p /usr/local/kafka
#kafka数据目录
mkdir -p /data/kafka/kafka-logs
tar -zxf /opt/kafka_2.13-3.5.1.tgz -C /usr/local/kafka
[root@Kafka1 ~]# ll /usr/local/kafka/kafka_2.13-3.5.1
total 64
drwxr-xr-x 3 root root 4096 Jul 15 00:53 bin
drwxr-xr-x 3 root root 4096 Jul 15 00:53 config
drwxr-xr-x 2 root root 4096 Nov 4 12:03 libs
-rw-rw-r-- 1 root root 14722 Jul 15 00:50 LICENSE
drwxr-xr-x 2 root root 4096 Jul 15 00:53 licenses
-rw-rw-r-- 1 root root 28184 Jul 15 00:50 NOTICE
drwxr-xr-x 2 root root 4096 Jul 15 00:53 site-docs
2.Kafka配置
[root@Kafka1 ~]# cd /usr/local/kafka/kafka_2.13-3.5.1
--编辑配置文件,节点1修改
/usr/local/kafka/kafka_2.13-3.5.1/config/server.properties
vi /etc/profile
#KAFKA_HOME
export KAFKA_HOME=/usr/local/kafka/kafka_2.13-3.5.1
export PATH=$PATH:$KAFKA_HOME/bin
--编辑kafka1 的配置
broker.id=1
#listeners=PLAINTEXT://172.18.12.40:9092
advertised.listeners=PLAINTEXT://172.18.12.40:90927
# 连接zookeeper的集群地址
zookeeper.connect=172.18.12.40:2181,172.18.12.41:2181,172.18.12.42:2181
--编辑kafka2 的配置
broker.id=2
#listeners=PLAINTEXT://172.18.12.40:9092
advertised.listeners=PLAINTEXT://172.18.12.41:90927
# 连接zookeeper的集群地址
zookeeper.connect=172.18.12.40:2181,172.18.12.41:2181,172.18.12.42:2181
--编辑kafka3 的配置
broker.id=3
#listeners=PLAINTEXT://172.18.12.40:9092
advertised.listeners=PLAINTEXT://172.18.12.42:90927
# 连接zookeeper的集群地址
zookeeper.connect=172.18.12.40:2181,172.18.12.41:2181,172.18.12.42:2181
启动kafka服务
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
关闭kafka服务
kafka-server-stop.sh
📣 5.kafka 运维
✨ 5.1 kafka 命令
1.创建 topic
cd /usr/local/kafka/kafka_2.13-3.5.1
./bin/kafka-topics.sh --bootstrap-server broker_host:port --create --topic my_topic_name \
--partitions 20 --replication-factor 3 --config x=y
注 :此命令是在kafka部署目录中操作
kafka-topics.sh --bootstrap-server 172.18.12.40:9092 --create --topic my_topic_name
kafka-topics.sh --bootstrap-server 172.18.12.40:9092 --delete --topic my_topic_name
--列出主题
kafka-topics.sh --list --bootstrap-server 172.18.12.40:9092
my_topic_name
参数 详解 :
--bootstrap-server : kafka集群地址
--create :执行创创建操作
--topic :topic名称
--partitions :topic 的分区数
--replication-factor topic 的副本
--config: 可选,创建 topic指定topic参数 配置
创建生产者生产数据
[root@kafka1 bin]# kafka-console-producer.sh --broker-list 172.18.12.40:9092,172.18.12.41:9092,172.18.12.42:9092 --topic my_topic_name
>这是一个测试
测试消费者是否可以消费数据
[root@kafka2 config]# kafka-console-consumer.sh --bootstrap-server 172.18.12.40:9092 --topic my_topic_name --from-beginning
这是一个测试
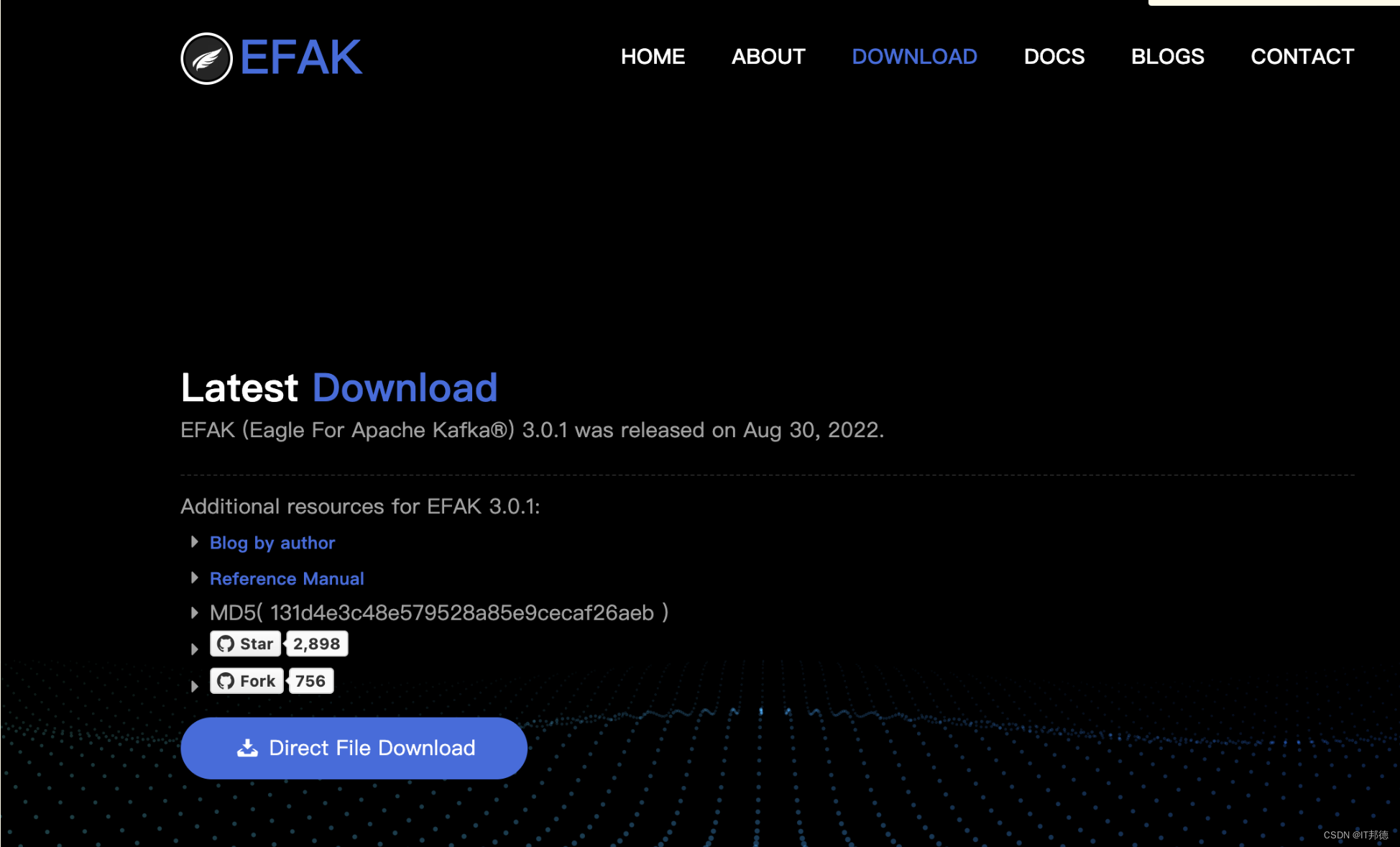
✨ 5.2 kafka-eagle部署
kafka-eagle现在更名为 EFAK
官网:https://www.kafka-eagle.org/
##解压缩包重命名目录
mkdir /opt/software
tar xf kafka-eagle-bin-3.0.1.tar.gz -C /opt/software/
cd /opt/software/kafka-eagle-bin-3.0.1
tar xf efak-web-3.0.1-bin.tar.gz
mv efak-web-3.0.1 kafka-eagle
##配置环境变量
vim /etc/profile
export KE_HOME= /opt/software/kafka-eagle-bin-3.0.1/kafka-eagle
PATH=$PATH:$KE_HOME/bin
##更新环境变量
source /etc/profile
##修改Kafka-Eagle配置文件
cd $KE_HOME/conf
vim system-config.properties
######################################
# multi zookeeper&kafka cluster list
# zookeeper和kafka集群配置
######################################
kafka.eagle.zk.cluster.alias=cluster
cluster.zk.list=172.18.12.40:2181,172.18.12.41:2181,172.18.12.42:2181
######################################
# kafka eagle webui port
# web页面访问端口号
######################################
kafka.eagle.webui.port=8048
######################################
# kafka jdbc driver address
# kafka默认使用sqlite数据库,Centos自带,注意配置下数据库存放路径就行
######################################
kafka.eagle.driver=org.sqlite.JDBC
#修改到对应路径下面,不然启动回报错
kafka.eagle.url=jdbc:sqlite:/opt/software/kafka-eagle/db/ke.db
kafka.eagle.username=root
kafka.eagle.password=www.kafka-eagle.org
######################################
# kafka mysql jdbc driver address
######################################
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=123456
##启动kafka-eagle
cd …/bin/
chmod +x ke.sh
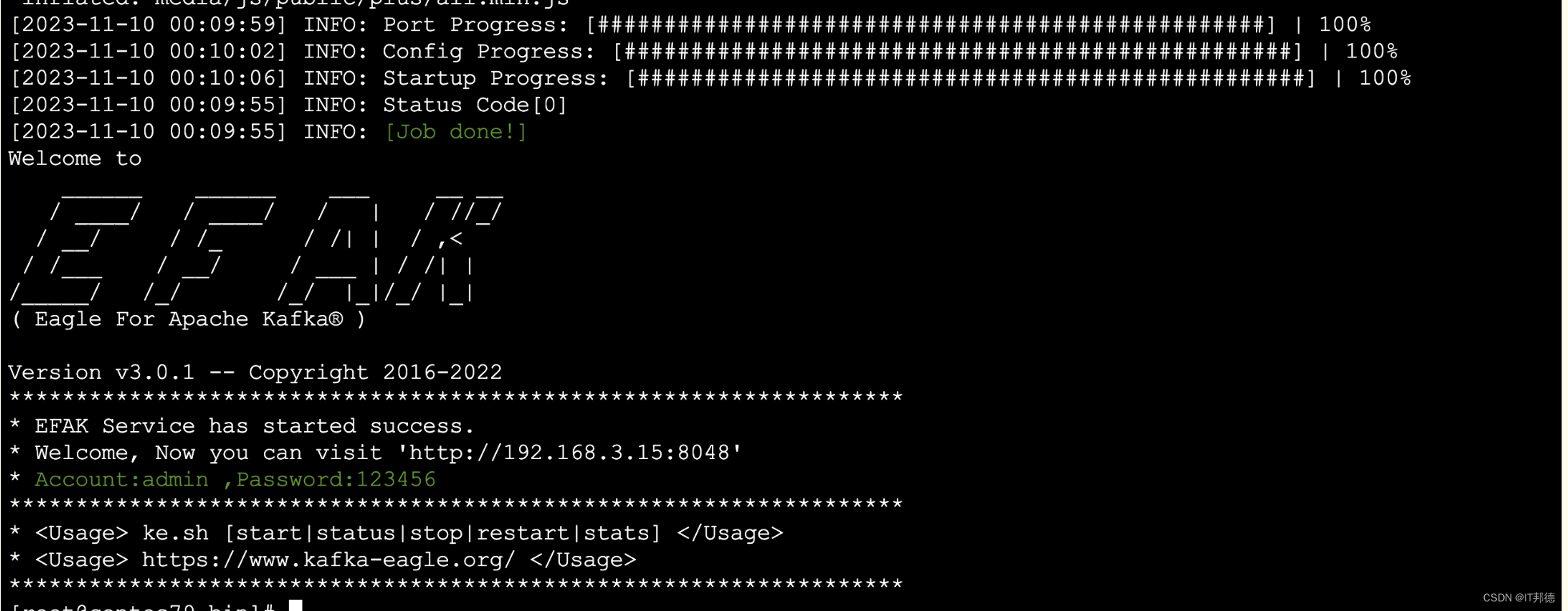
./ke.sh start
此处注意脚本
./ke.sh stop
mroe /opt/software/kafka-eagle-bin-3.0.1/kafka-eagle/logs/error.log
# 网址密码
* Kafka Eagle Service has started success.
* Welcome, Now you can visit 'http://192.168.3.15:8048/ke'
* Account:admin ,Password:123456