导读
本文整理自 2023 年 9 月 5 日 QCon 全球软件开发大会 2023 · 北京站 —— 向量数据库分论坛的同名主题演讲《BES 在大规模向量数据库场景的探索和实践》。
全文5989字,预计阅读时间15分钟。
向量数据库是一种专门用于存储和查询向量数据的数据库系统。通过 Embedding 技术,可以将图像、声音、文本等数据的特征提取出来,用向量的形式表达。而向量之间的距离,表达了原始数据之间特征的相似程度。因此,可以将原始数据等特征向量存储到向量数据库,然后通过向量检索的技术,找到相似的原始数据,例如进行以图搜图的应用等。
一、向量数据库应用简介
在大模型出现之前,向量检索这项技术就已经发展成熟。随着深度学习技术的发展,向量数据库也广泛应用于图片、音频、视频的搜索和推荐场景,以及语义检索、文本问答、人脸识别等场景。
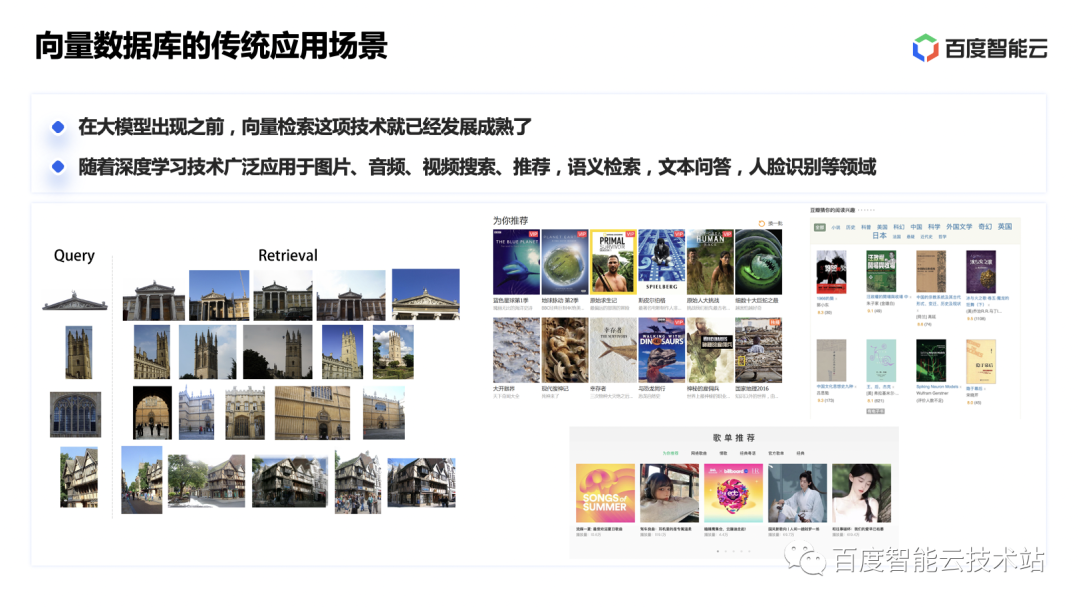
大模型的出现改变了人机交互方式,带来了人工智能技术的新革命,并催生了大量的 AI 原生应用。
不过目前还处于发展的初期阶段,在实际应用上还存在很多问题。
首先是知识能力不够强,大模型虽然能回答通用性问题,但面对垂直领域,由于训练数据有限,回答的专业性仍有提升空间。而且大模型还有幻觉问题,回答会歪曲事实。
另外大模型训练周期和成本都很高,所以没办法频繁的训练,这就导致难以获得实时的数据,只能回答一些时效性不太强的通用问题;
除了知识方面,大模型也很难保证隐私数据安全。比如我为大模型提供了一些关于我自己的私人数据,当这个大模型为其他人提供服务的时候,这些隐私信息很有可能作为答案被说出来。
那么如何增强大模型的知识能力,同时也保护私有数据的安全性呢?
如下图右侧内容所示,通过在提问的时候带上气象局发布的天气预警新闻,可以帮助大模型准确地回答我们的问题。
这种通过外置的数据资料和工具来增强大模型能力的技术体系,称为提示词工程。
从以上讨论可以看出,提示词工程对大模型应用有重要的意义。下面,将为大家详细介绍如何构建提示词工程。

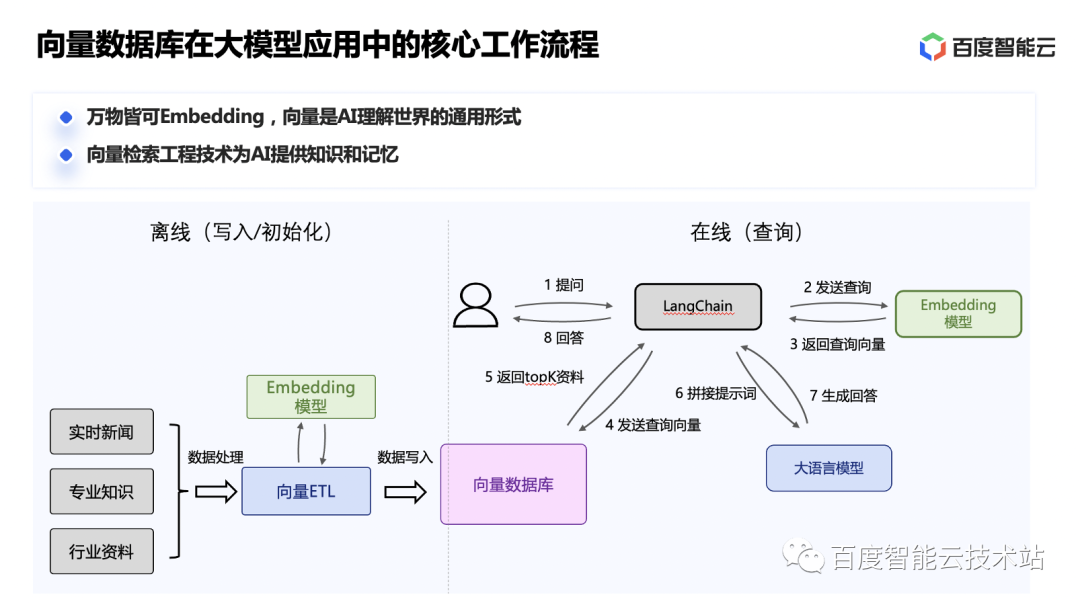
我们来看一个大模型应用的核心工作流程。
通过定期将外部的实时新闻、专业知识、行业资料等数据 Embedding 为向量形式,存储到向量数据库,可以增量构建一个大模型的外部知识库。在用户提问的时候,可以先从知识库获取相关性最高的内容,然后拼接提示词来增强大模型的回答能力。
这样可以在不重新训练大模型的情况下,引入外部的实时数据和知识,增强大模型的回答能力,并减少大模型回答偏离事实的情况。通过向量数据库构建外部知识库,还可以有效的保障行业数据的隐私安全性。
此外,将用户的会话历史存储到向量知识库,在后续的对话过程中还可以提取出相关性较高的历史会话,从而解决大语言模型的 token 数量限制导致大模型缺少长期记忆的问题。
二、百度智能云 BES 的工程实践
Elasticsearch 是一个基于 Apache Lucene 的分布式的搜索与分析引擎,在搜索引擎数据库领域排名第一,是全球最受欢迎的开源解决方案,支持多种数据类型,包括结构化和非结构化数据,并且接口简单易用,文档齐全,在业界有大量的实践案例。
百度智能云 Elasticsearch(BES) 是基于开源 Elasticsearch 构建的成熟的公有云产品,拥有云上的资源保障和运维能力。BES 在 2015 年发布,是公有云厂商中最先提供的 ES 托管服务。2018 年我们引入了百度 NLP 分词插件,并支持基于对象存储 BOS 进行快照和恢复。2020 年我们支持了基于对象存储 BOS 的冷热分离架构等能力,并提供了向量检索的能力,在百度内部广泛使用,有着充分的工程积累。2023 年,我们针对向量检索的场景,从向量引擎、套餐资源等各方面进行了优化,以便满足大模型的场景需求。

BES 的架构由管控平台和 BES 集群实例两部分组成。管控平台是全局层面来进行统一的集群管理,监控报警,以及集群扩缩容、冷热分离调度的平台。BES 集群实例则是一套构件在云主机和云磁盘上面的 Elasticsearch 集群服务,前面通过 BLB 四层代理做节点负载均衡。磁盘上的数据可以通过策略定期下沉存储到对象存储 BOS 上,降低存储成本。
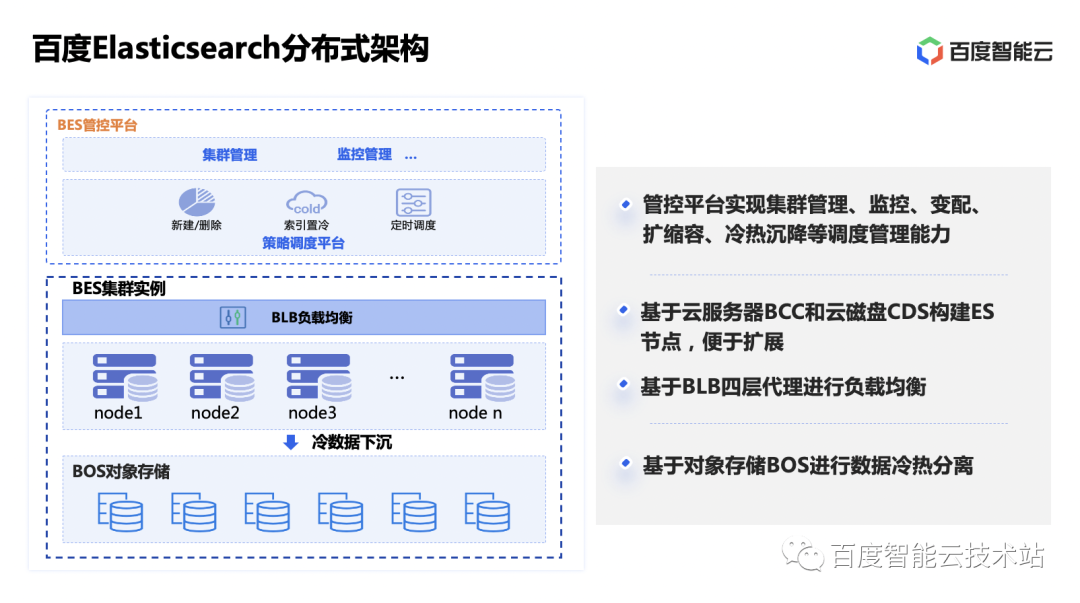
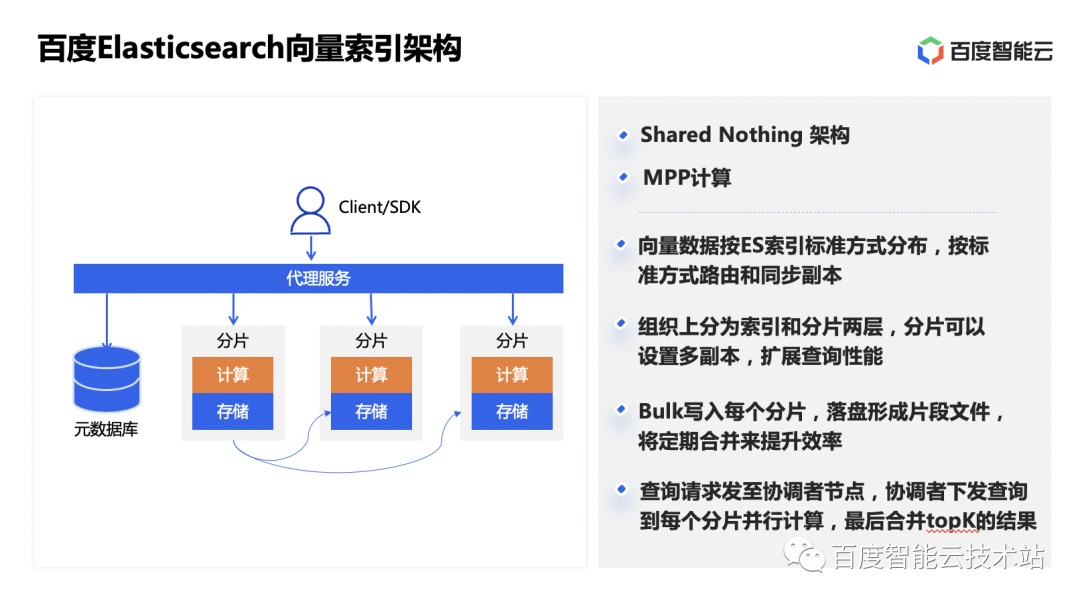
BES 的索引架构,整体上采用的是 Shared Nothing + MPP 计算的架构,复用了 ES 的数据流,数据按照索引和分片进行组织,分片可以设置多副本,会通过 ES 的标准方式进行分布和路由。这样在执行向量检索的时候,会在有数据分布的节点上进行本地计算,通过多节点并行计算提高查询效率。可以通过增加副本数量配合扩容,提高可以参与查询的节点数量和资源,从而提高服务整体的查询 QPS。
向量数据使用 ES 标准的方式进行管理,因此使用上和标量数据的区别不大,向量数据可以和标量数据一起写入,并复用 ES 对标量数据的检索和处理能力。用户可以通过 ES 的 Bulk 接口批量写入数据,在数据写入每个分片以后,落盘会形成一些片段文件,然后即可提供检索能力。ES 会在后台定时调度进行分片的合并,来提升检索的效率。在查询的时候,查询请求发送到任意一个节点上,这个节点即成为协调节点,会下发查询到每个分片进行并行计算,然后合并得到 TopK 到结果并返回。
在 BES 中使用向量也非常简单,下面我们看一个使用示例。首先需要定义索引的Mapping,指定一些向量相关的参数,这一步相当于建表。然后就可以通过 ES 的 Bulk 接口写入数据,实际场景中一般是先通过 Embedding 能力将原始数据向量化,然后批量写入。然后可以通过我们定义的跟 ES 风格接近的语法进行向量检索。

在向量索引的实现方面,我们选择通过自研插件来实现向量相关的能力。核心引擎我们通过 C++ 实现,在 ES 中通过 JNI 调用。
选择自研插件,一是希望基于 C++ 实现来获得更贴近底层的极限性能,并且方便进行 SIMD 等优化来加速计算;二是能改写底层存储格式的实现,也是方便做到更极致的性能;三是能更灵活地控制检索逻辑,改写执行计划来实现比较复杂的查询。
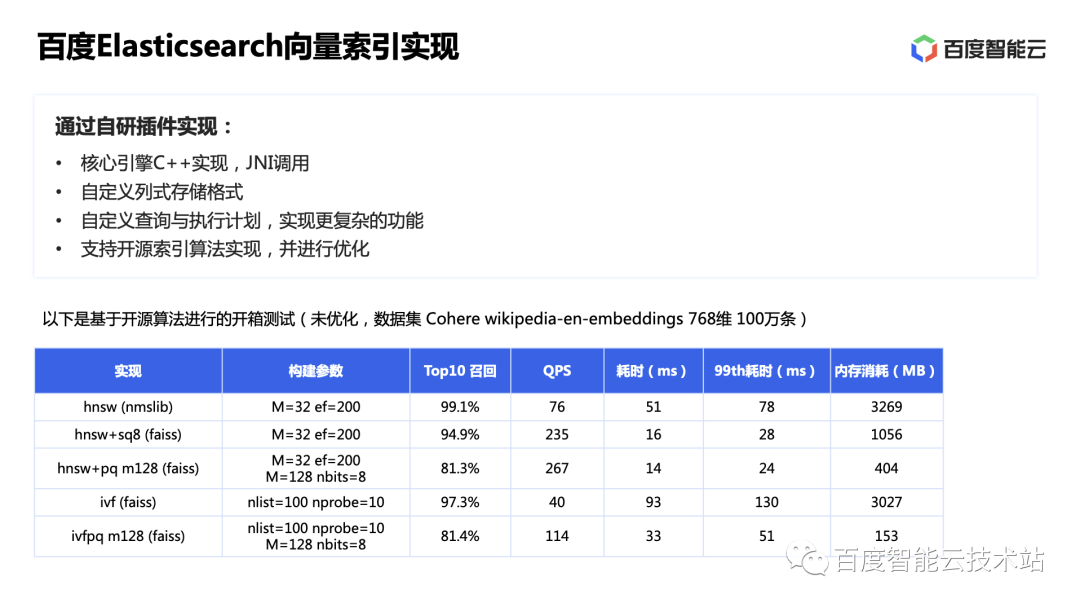
这里核心的向量检索引擎部分,我们选择基于社区优秀的向量库实现做二次开发。我们对比了下 nmslib 和 faiss 各自在 ES 上的开箱性能(基于 8cu 虚机进行测试,写入数据产生的 segments 未合并,数据集 SIFT-1M 128 维),可以看出 HNSW 召回率较高、整体比较耗内存,而 nmslib 的实现更胜一筹。
通过改造向量检索引擎的实现,我们在 HNSW 的索引类型上,对 level 0 的向量数据存储复用了我们自定义的 Lucene 列式存储数据,并通过 mmap 加载。这样一方面减少了数据的冗余度,减少了资源的浪费;另一方面,通过 mmap 方式加载数据,在内存不足的时候,会将部分页换出内存,在需要读取的时候再加载到内存中,某种程度上也支持了内存 + 磁盘混合的存储介质。
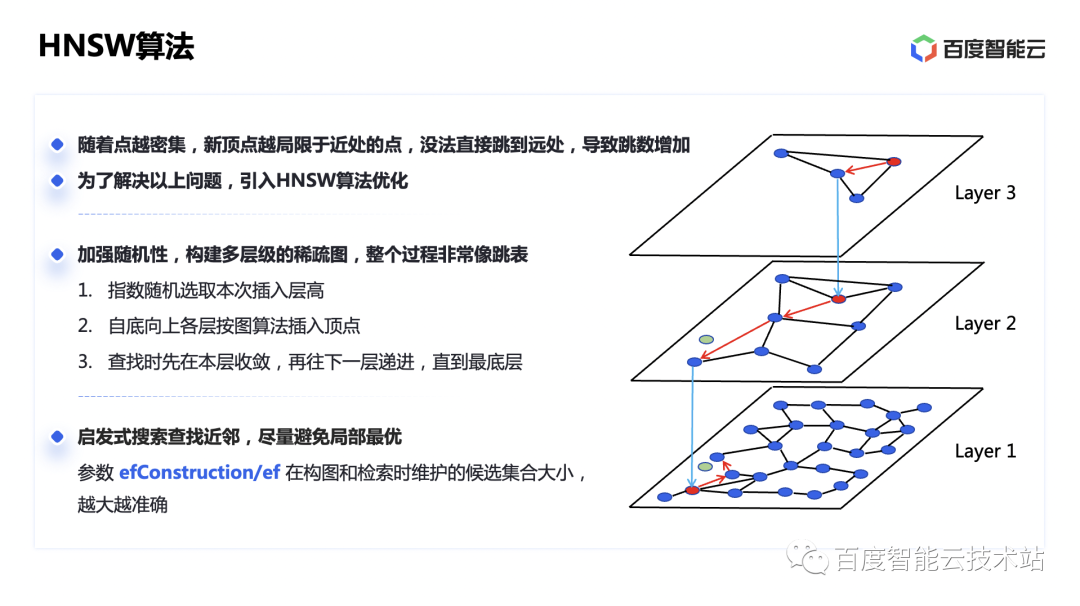
在展开具体优化之前,我们先回顾一下当前比较主流的图算法原理。
图算法是一种比较新的近似向量检索思路,它基于可导航小世界理论,具体是指在一个充分连接的图里,通过六跳就可以连通两个点。按向量间的距离关系构造一个这样类似于真实世界的「小世界」网络,也就可以通过贪心算法,按距离建立联系一跳一跳逼近目标的向量定点。
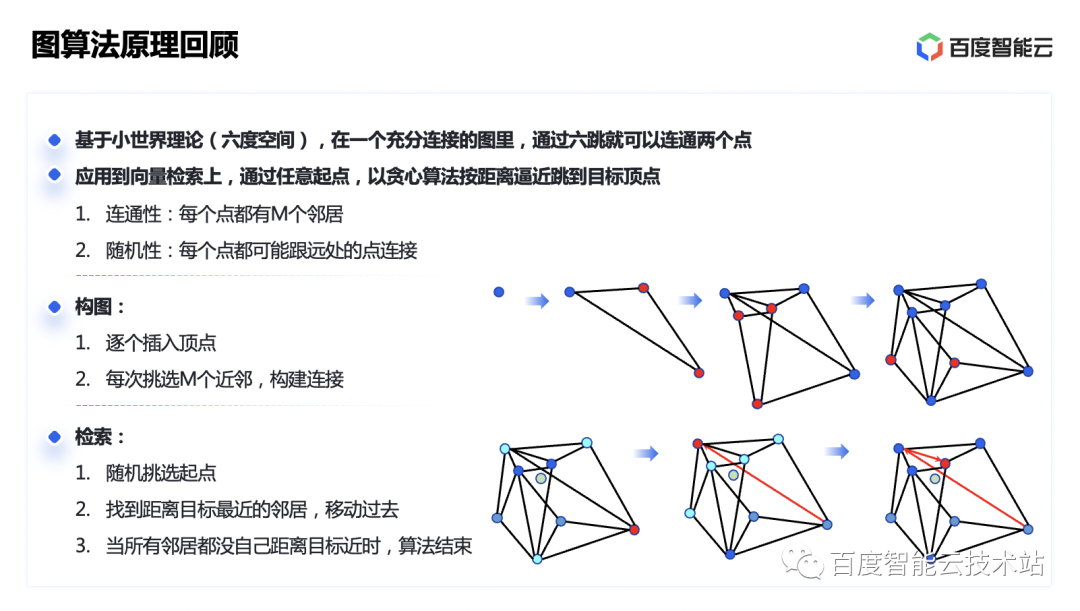
随着小世界里的点不断插入,根据前面讲的挑选近邻点构建边的思路,新插入的点会越来越局限于一个小圈子,这样的话跟一个很远的点建立联系就需要非常多的跳数了。
为了解决这个问题,业界提出了 HNSW 算法,即采用类似链表查找算法里的跳表的思路。我们建立不同层级的图,往上指数递减定点数量来形成稀疏图,这样越稀疏的图自然就越能连接远方。
虽然 HNSW 索引的查询响应快,召回率也比较高,但是也存在构图速度慢,CPU、内存开销大等缺点。HNSW 构图过程,每插入一个点需要检索计算,插入大量的点也是一笔很大的计算开销,因此导入数据会很慢,导致前台阻塞。
因此我们将向量索引构建改造成后台异步构建的机制,数据写入落盘之后就可以直接返回;然后后台通过 ES 的合并策略或者用户的定时或主动触发的方式来触发在后台构建 HNSW 索引,通过流式构建的方式,降低构图过程的内存消耗。并且使用独立线程池构建,以免对前台查询请求造成影响。
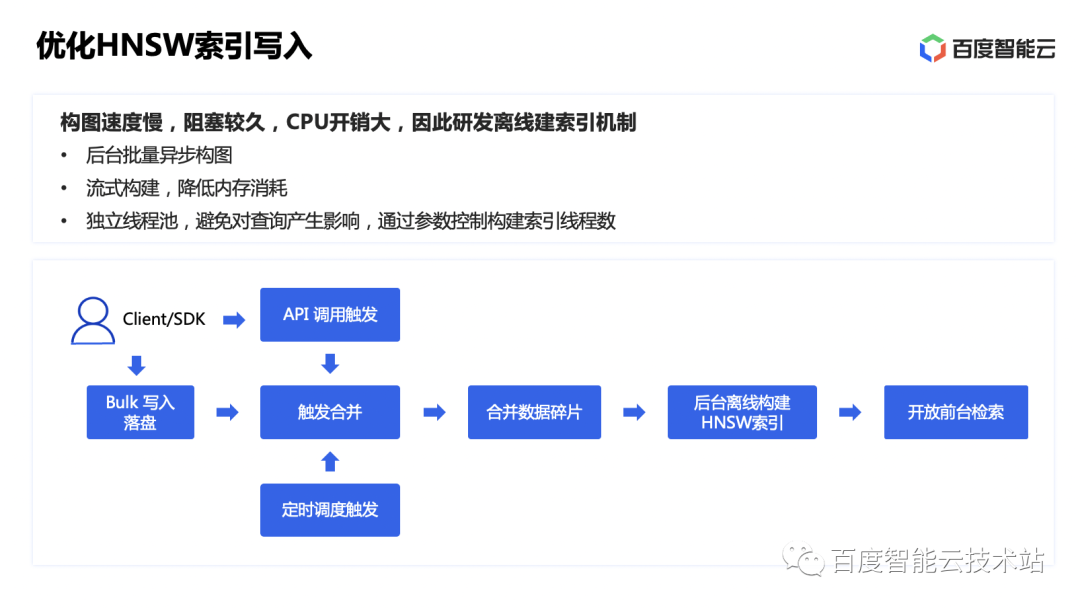
同时,我们也对 ES 的片段合并策略进行了优化。
ES 默认的合并策略,会根据一些条件,例如一次合并参与的片段数量、合并要产生的新片段的大小等,来选择参与合并的片段的集合,然后计算不同组合的分数,来选择最优的片段组合进行合并。一般会经过多轮合并的方式,来达到一个资源消耗和查询效率的平衡状态。不过因为向量索引的构建成本往往比 ES 的原生数据类型成本更高,所以我们调整了向量索引的合并策略,将多轮合并改为一次合并,减少片段合并的过程开销。
此外,我们也支持在写入数据之前,将目标索引的自动构建关闭,在批量写入数据并合并片段之后,再通过 API 一次性完成向量索引构建,比较适合批量灌库的场景使用。

此外,BES 也支持多种向量索引类型和距离计算算法。对于需要训练生成的向量索引,我们也提供了流程支持。例如 IVF 系列索引,在此让我们先回顾下 IVF 算法的原理。
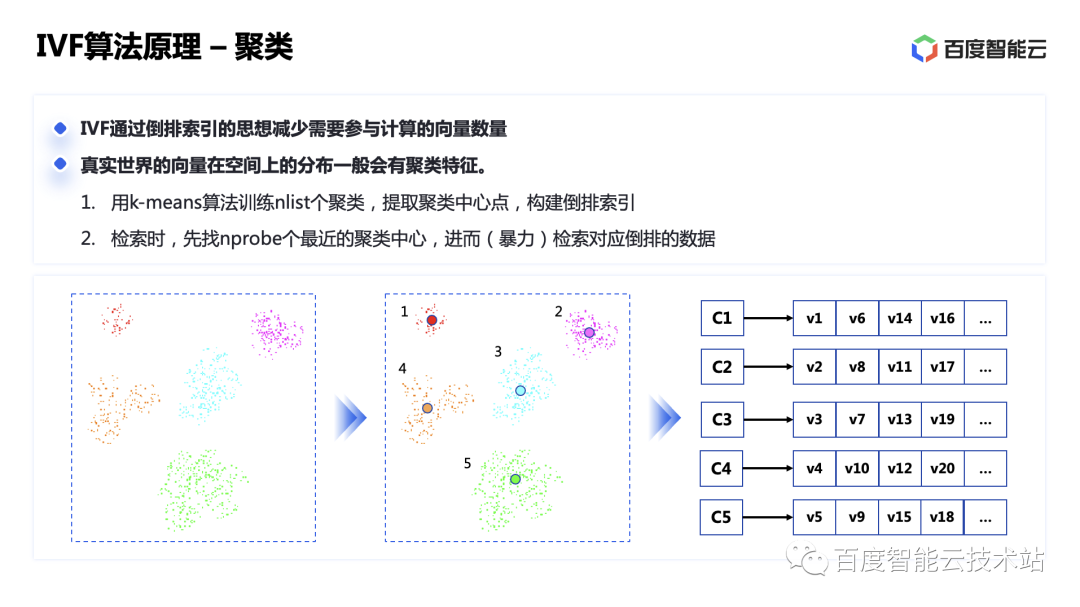
IVF 即倒排索引,倒排索引是一个搜索引擎的术语,指的从文档网页里提取关键词,来建立倒排检索结构,通过关键词找到原始文档。那么对向量数据来说,关键词是什么呢?真实世界的向量在空间分布上一般会扎堆分布,具备聚类特征。请看下图。
通过 k-means 算法将向量的聚类中心提取出来,那这个向量所处的聚类中心就是这个向量的关键词,用这个来建立倒排索引,就可以像搜索引擎一样,先命中聚类中心,再暴力搜索聚类中心下面的各个向量,这样相比全局搜索能过滤大量的数据。如果觉得找一个聚类中心不够准确,也可以多找几个,找的越多,结果越准。
对于 IVF 这一类的向量索引,BES 的构建流程是,先写入训练数据,然后调用 API 训练模型。这一步会根据训练数据进行聚类,计算得到每个聚类的中心。在模型训练好以后,再新建索引写入实际数据,基于训练好的模型构建向量索引。具体向量索引的构建和合并机制,还是和前面描述的一样。

有很多场景提出先按标量条件过滤数据再进行向量检索的需求,例如为向量数据打上标签,要保证检索出来的向量能匹配上标签。
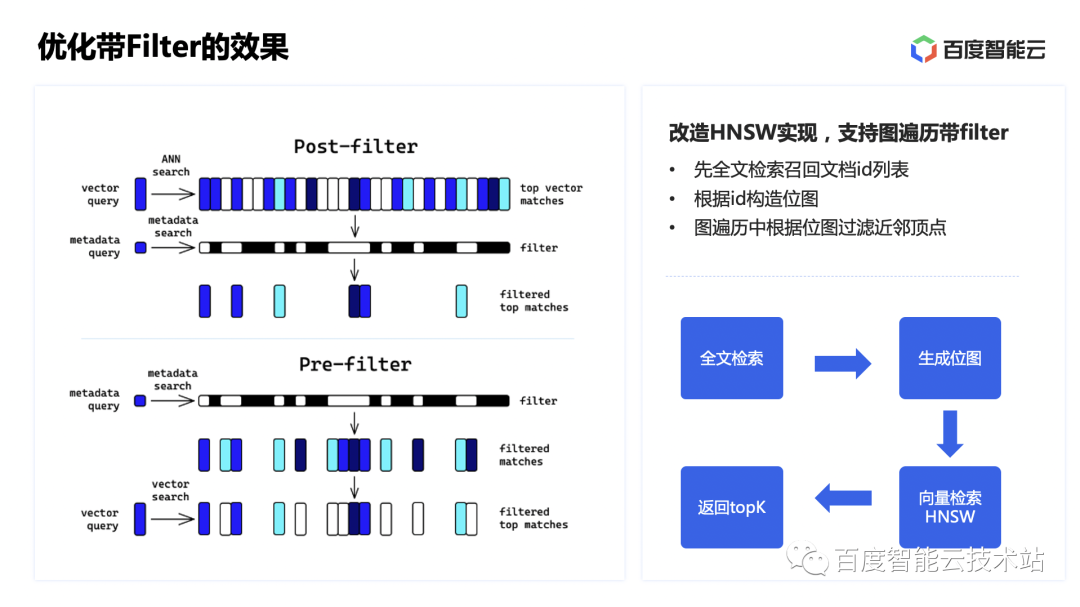
支持这样的需求,可以通过 post-filter 和 pre-filter 两种方式,post-filter 是指先进行 ANN 的检索,然后基于检索结果执行 filter,得到最终的结果,不过可能会导致结果集的大小显著小于 K。而 pre-filter 是指,先对数据进行过滤,然后基于过滤结果进行最近邻检索。这种方式一般可以确保得到 K 个结果。
因此我们改造了原有的 HNSW 实现,让算法在遍历图挑选近邻的过程中,只考虑符合 filter 条件的向量。具体流程是,先基于 ES 的标量数据索引执行 filter,得到召回文档的 id 列表;然后根据id列表构造位图,并将位图数据通过 JNI 调用传递到向量引擎,在 HNSW 检索的过程中,根据位图过滤近邻顶点,从而得到符合 filter 条件的向量列表。
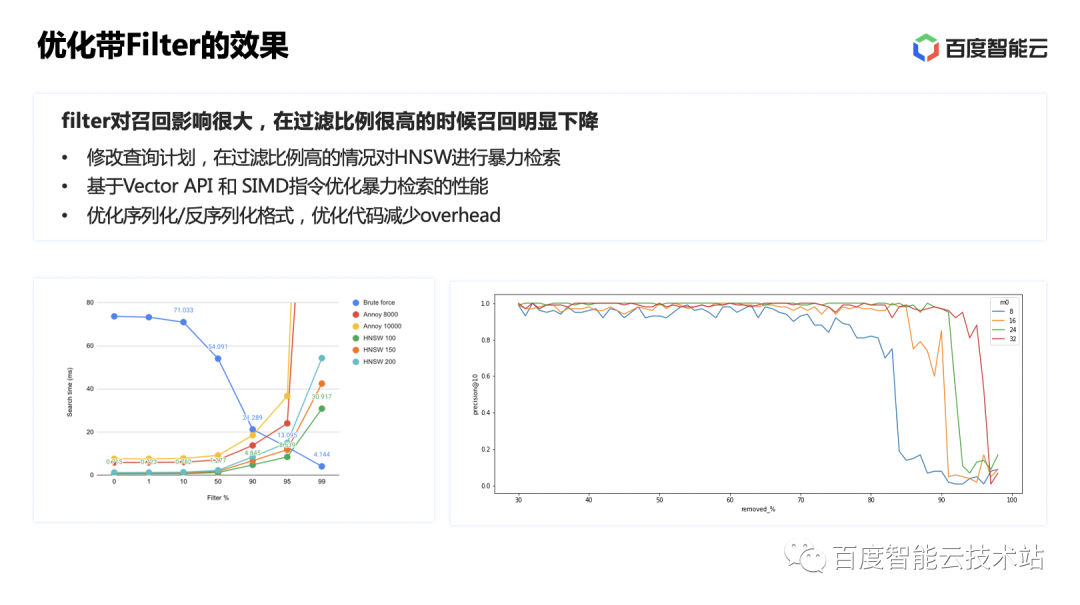
实际测试的时候,发现性能和召回不是很理想。通过测试数据和研究一些资料发现,在过滤比例升高时,因为顶点被过滤导致能连通的路径变少,直接影响了 HNSW 算法的收敛速度,以及很容易走进死胡同导致召回率低。资料表明,过滤比达到 90% 以上是,性能和召回率会急剧下降。
因此这里我们选择改写执行计划,将标量过滤和暴力检索算法结合,在过滤比例达到 90% 以上的时候,对于 filter 的结果数据进行暴力检索,可以取得令人满意的效果。同时,还通过 SIMD 指令加速暴力检索效率。
BES 后续的发展规划,主要集中在以下几方面。
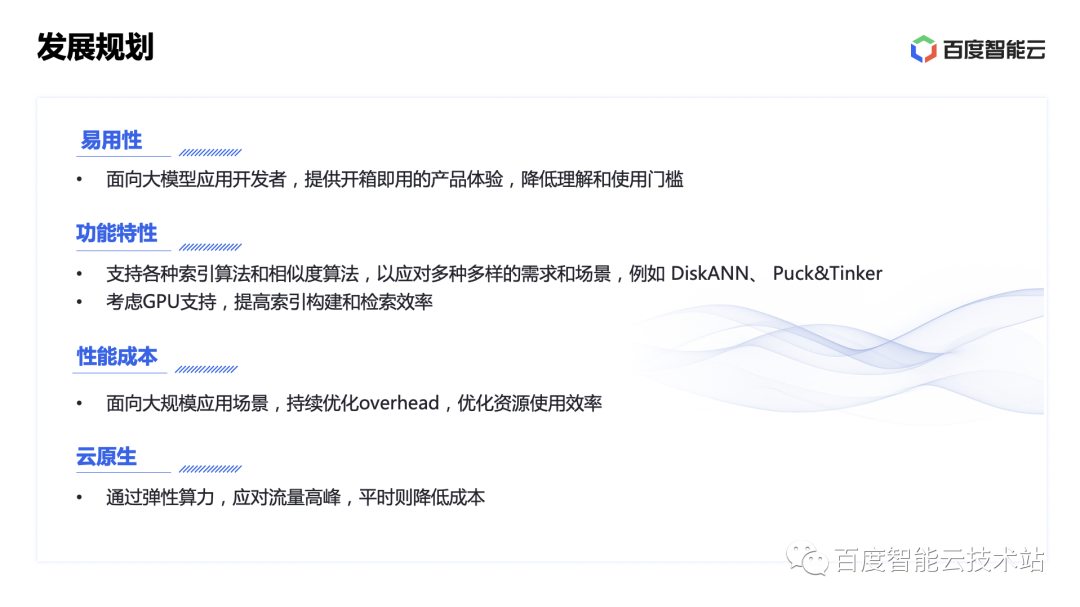
首先是易用性,因为向量数据库主要面向大模型应用开发者,所以希望能够提供开箱即用的产品体验,降低用户理解和使用的门槛。目前 BES 自研的向量引擎在使用上需要用户对 ES 有一定的熟悉,例如能够使用 ES 的 DSL 表达查询逻辑。如果能够提供更加通用易上手的使用方式,例如支持通过 SQL 进行 knn 检索,对用户将更加友好。
其次是功能特性,这里需要支持更多索引算法和相似度算法,例如 DiskAnn、百度自研的 Puck&Tinker 算法等,以应对多种多样的需求和场景。并考虑支持异构计算能力,提高索引构建和检索效率。
性能成本方面,面向大规模应用的场景,还需要更深入的优化,减少系统的 overhead,优化资源的使用效率。例如,ES 是基于 JVM 运行的,向量引擎由 C++ 开发,通过 JNI 调用执行。那怎么才能更加灵活的管理全局的内存资源,才能适应不同客户的 workload,又能将资源的利用率尽可能地提高,这个将是我们后续的一个主要优化方向。
最后,BES 目前是托管集群的形态,需要用户根据自己的业务量级评估集群资源,选择合理地套餐,这给用户带来了一定的使用成本,如何能够让资源更加动态、弹性,帮助用户降低使用门槛,降低成本,也是我们的优化方向。
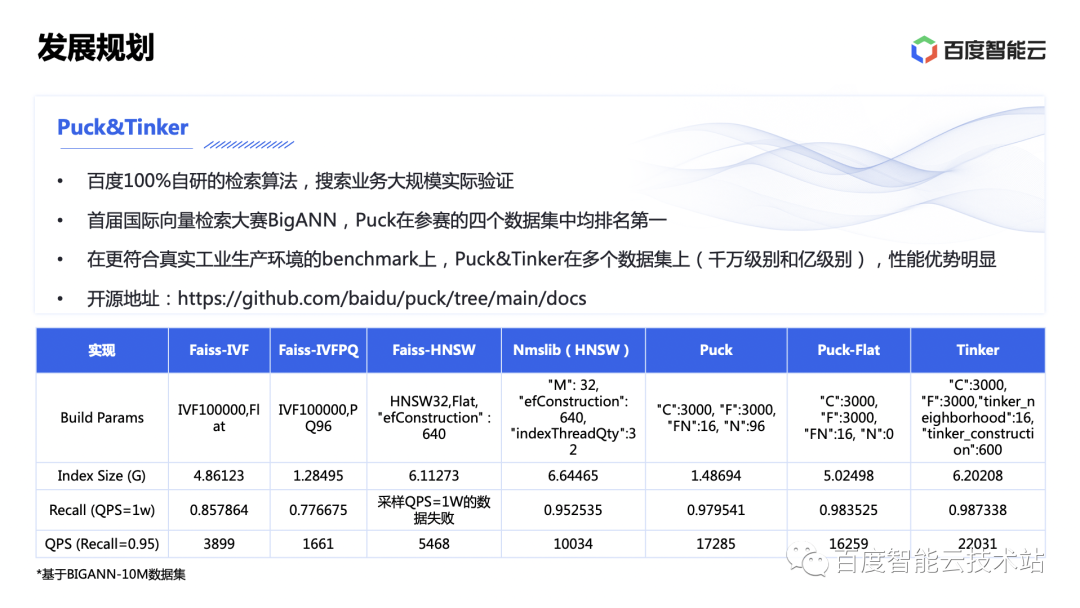
刚刚提到的 Puck&Tinker 算法,是百度 100% 自研的向量检索算法,经过了搜索业务的大规模实际验证。
在首届国际向量检索大赛 BigANN 上,Puck 在参赛的 4 个数据集中均排名第一。在 BIGANN-10M 的数据集上,在召回率相近的情况下,Puck 的性能达到了 HNSW 的 1.7 倍,而内存消耗只有 HNSW 的 21% 左右。Puck 已经开源,欢迎大家关注 https://github.com/baidu/puck/tree/main/docs。
三、案例分享
3.1 多模态数据检索
下面介绍下 BES 的实际应用案例。
首先是向量能力在视频网站多模态检索场景下的应用。具体场景是对视频切分成帧,对帧进行图像特征处理和时间建模,通过神经网络将帧序列转化为向量,写入 BES,构建物料向量库。然后在 BES 中通过向量检索,召回相似度最高的结果输入上游业务服务,支持视频打标、短带长、个性化推荐等场景。

3.2 千帆大模型平台
千帆大模型平台的知识库是一款专门面向大语言模型知识问答场景,旨在管理客户上传的知识并提供快速查询检索功能的产品。
基于百度智能云 BES,用户能够以高效的方式存储和检索大量的知识库文档,实现快速管理企业私域知识,构建知识问答应用的能力。并且可以保障客户的数据隐私安全。
这里有两种应用方式。方式一是独立部署大模型知识库,构建本地域内知识检索应用;方式二是在千帆平台直接绑定插件应用,支持问答、生成、任务三类应用。

以上是分享的全部内容。
点击阅读原文,了解更多产品信息
——— END ———
推荐阅读
文生图大型实践:揭秘百度搜索AIGC绘画工具的背后故事!
大模型在代码缺陷检测领域的应用实践
通过Python脚本支持OC代码重构实践(二):数据项提供模块接入数据通路的代码生成
对话InfoQ,聊聊百度开源高性能检索引擎 Puck
浅谈搜索展现层场景化技术-tanGo实践