一 引子
小试身手
首先我们来看一道题
Integer i1 = 127;
Integer i2 = 127;
System.out.println(i1 == i2);
//这种调用底层实际是执行的Integer.valueOf(127),里面用到了IntegerCache对象池
//值大于127时,不会从对象池中取对象
Integer i3 = 128;
Integer i4 = 128;
System.out.println(i3 == i4);
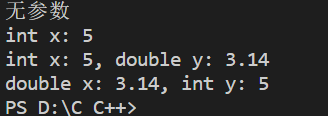
这道题是笔试题中常见的一道题。答案相信大部分人都知道,第3行输出true,第9行输出false。
本着知其然,知其所以然的精神我们进一步探究得知:第1,2,7,8行实际执行的是Integer.valueOf()。这个方法出于减少对象创建次数和节省内存的考虑,会对数值为-128~127之间的Integer对象进行缓存,如果valueOf()方法传入的参数在这个范围之内,就直接返回缓存中的对象。
乘胜追击
上面的理论大家可能都知道,但是这个理论是不是和“鬼”一样,大家只听过,没见过呢?下面我来和大家一起,揭开它的神秘面纱。
首先可能大家会问,第1,2,7,8行实际执行的是Integer.valueOf(),这个你是怎么知道的呢?是不是也是从书上看来的。能不能证明给我们看看?
javap -v 命令
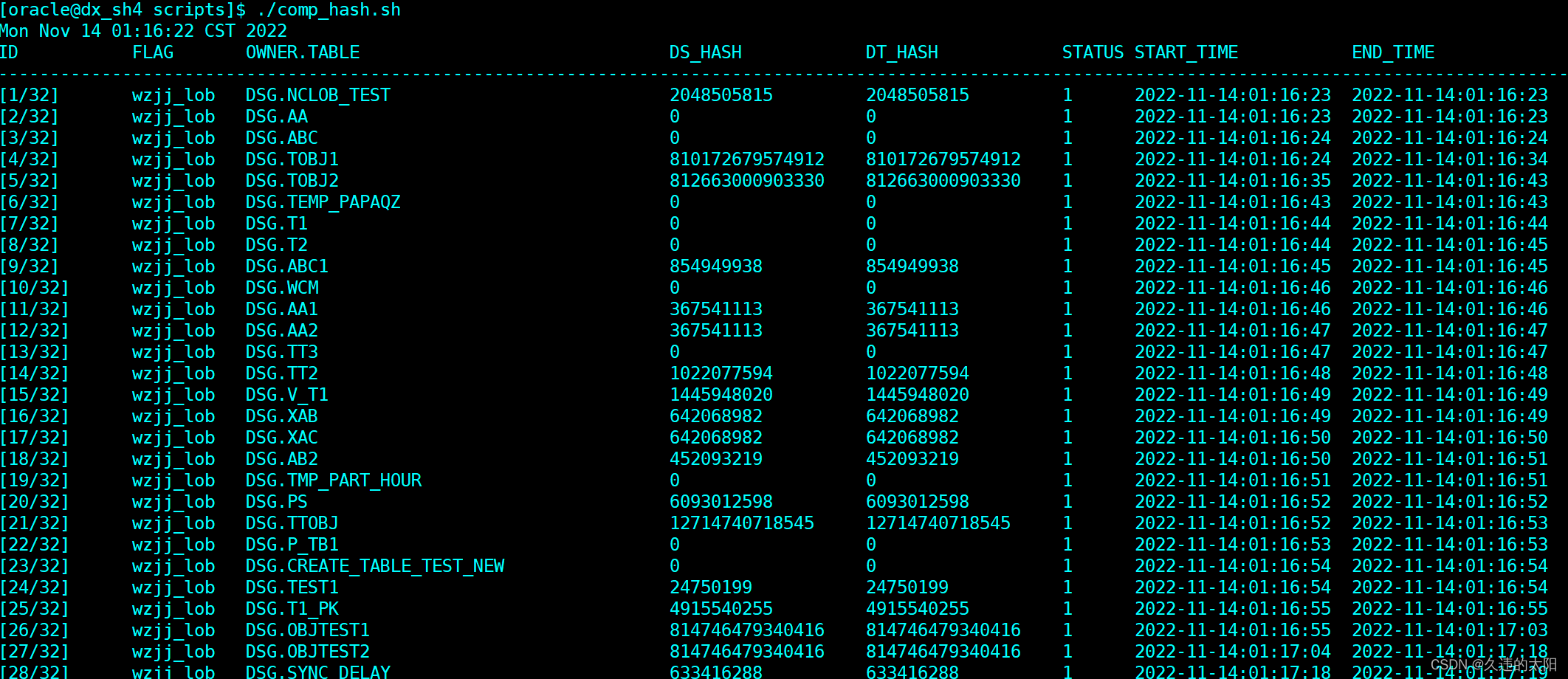
当然可以,我们都知道java文件在运行的时候会被编译为字节码文件,要想解答上面疑惑我们只需要查看字节码就可以了。找到class文件,一个简单的 javap -v 命令就可以搞定。

字节码我们看过了,但是还是没有看到缓存。下一步我们在来看下源码。

在来看下以下片段。这个一个static代码块,在项目启动的时候就从low到high依次加入到Integer数组中也就是所谓的缓存中。

二 包装类的常量池(对象池)
Java中有6种基本类型的包装类型实现了常量池技术,分别是:Byte,Short,Integer,Long,Character,Boolean,其中Byte,Short,Integer,Long,Character这5种整型的包装类只是在对应值小于等于127时才可使用对象池。 另外两种浮点数类型的包装类型没有实现。之所以这样设计是基于使用频率的考虑。
Byte a1 = 1;
Byte a2 = 1;
System.out.println(a1 == a2);
Short b1 = 2;
Short b2 = 2;
System.out.println(b1 == b2);
Character c1 = 'a';
Character c2 = 'a';
System.out.println(c1 == c2);
Long d1 = 11L;
Long d2 = 11L;
System.out.println(d1 == d2);
Boolean e1 = false;
Boolean e2 = false;
System.out.println(e1 == e2);
Float f1 = 1.0f;
Float f2 = 1.0f;
System.out.println(f1 == f2);//false
Double g1 = 1.0;
Double g2 = 1.0;
System.out.println(g1 == g2);//false
上面这段代码,除了最后两个为false,其余均为true。需要注意使用new关键词生成的对象不会使用常量池。这里就不需要做过多解释了。下面进入今天的重点内容。
Integer i1 = 40;
Integer i2 = 40;
Integer i3 = 0;
Integer i4 = new Integer(40);
Integer i5 = new Integer(40);
Integer i6 = new Integer(0);
System.out.println(i1 == i2); //true
System.out.println(i1 == i4); //false
System.out.println(i4 == i5); //false
//自动拆箱:
// 在进行“+”运算时,Integer类型自动拆箱为int,
// “==”运算时Integer无法与int,所以也拆箱为int。
//所以最终变成了int 与int 比较
System.out.println(i1 == i2 + i3); //true
System.out.println(i4 == i5 + i6); //true
System.out.println(40 == i5 + i6); //true
分析:自动拆箱。在进行“+”运算时,Integer类型自动拆箱为int, “==”运算时Integer无法与int,所以也拆箱为int。所以最终变成了int 与int 比较。在字节码中我们可以看到Integer.intValue。

三 常量池的概念以及分类
1 常量池的概念
很多同学都知道常量池的概念,但是你是否对class文件常量池,运行时常量池,字符串常量池傻傻分不清楚呢?我们通过下面这张图来直观感受一下。

2 Class文件常量池
首先我们来看下class文件常量池。Class文件中除了有类的版本、 字段、 方法、 接口等描述信息外, 还有一项信息是常量池表(Constant Pool Table) , 用于存放编译期生成的各种字面量与符号引用, 这部分内容将在类加载后存放到方法区的运行时常量池中。
这里的常量池表就是Class文件常量池。
常量池表(Constant Pool Table)
我们使用javap命令查看Test1的class文件。
Classfile /D:/PPT/constant-pool/target/classes/com/pool/Test1.class
Last modified 2021-12-26; size 384 bytes
MD5 checksum 5a9a4b4f205a38c85fa7634109358b46
Compiled from "Test1.java"
public class com.pool.Test1
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #5.#17 // java/lang/Object."<init>":()V
#2 = Methodref #18.#19 // java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
#3 = Fieldref #4.#20 // com/pool/Test1.i1:Ljava/lang/Integer;
#4 = Class #21 // com/pool/Test1
#5 = Class #22 // java/lang/Object
#6 = Utf8 i1
#7 = Utf8 Ljava/lang/Integer;
#8 = Utf8 <init>
#9 = Utf8 ()V
#10 = Utf8 Code
#11 = Utf8 LineNumberTable
#12 = Utf8 LocalVariableTable
#13 = Utf8 this
#14 = Utf8 Lcom/pool/Test1;
#15 = Utf8 SourceFile
#16 = Utf8 Test1.java
#17 = NameAndType #8:#9 // "<init>":()V
#18 = Class #23 // java/lang/Integer
#19 = NameAndType #24:#25 // valueOf:(I)Ljava/lang/Integer;
#20 = NameAndType #6:#7 // i1:Ljava/lang/Integer;
#21 = Utf8 com/pool/Test1
#22 = Utf8 java/lang/Object
#23 = Utf8 java/lang/Integer
#24 = Utf8 valueOf
#25 = Utf8 (I)Ljava/lang/Integer;
{
java.lang.Integer i1;
descriptor: Ljava/lang/Integer;
flags:
public com.pool.Test1();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: bipush 127
7: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;
10: putfield #3 // Field i1:Ljava/lang/Integer;
13: return
LineNumberTable:
line 11: 0
line 12: 4
LocalVariableTable:
Start Length Slot Name Signature
0 14 0 this Lcom/pool/Test1;
}
我们再来理解下这句话:Class文件中除了有类的版本、 字段、 方法、 接口等描述信息外, 还有一项信息是常量池表(Constant Pool Table)。
字节码中第6,7行即为类的版本。 第35至58行为字段、方法、接口等描述。第9行Constant pool至34行,即为常量池表。
我们也可以换一种"非人类视角"来查看class文件。使用文本编辑器打开class文件,调整为16进制查看。如果文本编辑器默认不支持,需要自己安装一下插件。(此部分仅作了解,可以跳过)

第一眼看上去是一堆乱码,但是如果你知道了规律就会发现有章可循。通过对照下图我们就可以阅读class文件了。
- 魔数:cafe babe。每个Class文件的头4个字节被称为魔数(Magic Number) , 它的唯一作用是确定这个文件是否为一个能被虚拟机接受的Class文件。
- 次版本号(MinorVersion):0 。 第5和第6个字节是次版本号(MinorVersion)。
- 主版本号(Major Version):0034 转为10进制为52,即为JDK8 。 第7和第8个字节是主版本号(Major Version)
- 常量池容量计数值(constant_pool_count)
- 常量池(constant_pool)

要想阅读常量池的内容,就需要使用常量池项目类型表,感兴趣的同学推荐阅读下《深入理解Java虚拟机》“6.3 Class类文件的结构”,这里就不在深入解析了。

通过上面的常量池项目类型我们可以知道,class文件常量池中主要存放两大类常量: 字面量(Literal) 和符号引用(Symbolic References) 。
字面量(Literal)
字面量比较接近于Java语言层面的常量概念, 如文本字符串、 被声明为final的常量值等。
字面量只可以右值出现,所谓右值是指等号右边的值,如:int a=1 这里的a为左值,1为右值。在这个例子中1就是字面量。
符号引用(Symbolic References)
符号引用则属于编译原理方面的概念, 主要包括下面几类常量:
- 被模块导出或者开放的包(Package)·
- 类和接口的全限定名(Fully Qualified Name)·
- 字段的名称和描述符(Descriptor)·
- 方法的名称和描述符·
- 方法句柄和方法类型(Method Handle、 Method Type、 Invoke Dynamic)·
- 动态调用点和动态常量(Dynamically-Computed Call Site、 Dynamically-Computed Constant
下面我们通过一个实例来帮助大家理解字面量和符号引用。
package com.pool;
public class Test2 {
public static void main(String[] args) {
Integer i1 = 127;
Integer i2 = 127;
System.out.println(i1 == i2);//输出true
//这种调用底层实际是执行的Integer.valueOf(127),里面用到了IntegerCache对象池
//值大于127时,不会从对象池中aaa取对象
Integer i3 = 128;
Integer i4 = 128;
System.out.println(i3 == i4);//输出false
}
}
字面量: 等号右边的 127,128即为字面量。
符号引用:
-
类的全限定名 com.pool.Test2
-
字段的名称 i1,i2,i3,i4
-
方法的名称 main()
3 运行时常量池(Runtime Constant Pool)
运行时常量池(Runtime Constant Pool) 是方法区的一部分。 Class文件常量池里的内容将在类加载后存放到方法区的运行时常量池中,并将符号引用解析为直接引用。
我们看到类文件的信息存储在class静态文件中,在程序运行时会由类加载器加载到运行时常量池中,并在解析阶段,将符号引用转换为直接引用,指向真正的内存地址。
这里可以理解为 class文件信息为一份超市的购物清单,上面写着苹果,橘子等。 等你到了超市,超市的导购在你的购物清单上加上了货物的地址信息。 苹果 -> A货架5排3列,橘子->B货架3排5列。
4 字符串常量池(String Table)
字符串常量池里的内容是在类加载、验证、准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中。 在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个哈希表。这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。

四 字符串常量池深度解析
1 字符串常量池的设计思想
字符串常量池的设计思想和基本类型的包装类型常量池设计思想是一样的。
1.在内存中为字符串开辟一块空间,作为字符串常量池,类似于缓存。
2.创建字符串时,首先查询字符串常量池是否存在该字符串。
3.如果存在返回引用实例,不存在则实例化该字符串并放入常量池中。
字符串常量池位置
JDK1.7及以后

JDK1.6及以前

在JDK 6或更早之前的HotSpot虚拟机中, 常量池都是分配在永久代中, 我们可以通过-XX: PermSize和-XX: MaxPermSize限制永久代的大小, 即可间接限制其中常量池的容量。
/**
* VM Args: -XX:PermSize=6M -XX:MaxPermSize=6M
* @author zzm
*/
public class RuntimeConstantPoolOOM {
public static void main(String[] args) {
// 使用Set保持着常量池引用, 避免Full GC回收常量池行为
Set<String> set = new HashSet<String>();
// 在short范围内足以让6MB的PermSize产生OOM了
short i = 0;
while (true) {
set.add(String.valueOf(i++).intern());
}
}
}
运行结果:
Exception in thread "main" java.lang.OutOfMemoryError: PermGen space
自JDK 7起,原本存放在永久代的字符串常量池被移至Java堆之中。使用-Xmx参数限制最大堆到6MB就能够看到以下异常:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
当年
使用永久代来实现方法区的决定并不是一个好主意,这种设计导致了Java应用更容易遇到内存溢出的问题(永久代有-XX:MaxPermSize的上限,即使不设置也有默认大小,而J9和JRockit只要没有触碰到进程可用内存的上限,例如32位系统中的4GB限制,就不会出问题),而且有极少数方法(例如String::intern())会因永久代的原因而导致不同虚拟机下有不同的表现。当Oracle收购BEA获得了JRockit的所有权后,准备把JRockit中的优秀功能,譬如Java Mission Control管理工具,移植到HotSpot虚拟机时,但因为两者对方法区实现的差异而面临诸多困难。考虑到HotSpot未来的发展,在JDK 6的时候HotSpot开发团队就有放弃永久代,逐步改为采用本地内存(Native Memory)来实现方法区的计划了[1],到了JDK 7的HotSpot,已经把原本放在永久代的字符串常量池、静态变量等移出,而到了JDK 8,终于完全废弃了永久代的概念,改用与JRockit、J9一样在本地内存中实现的元空间(Metaspace)来代替,把JDK 7中永久代还剩余的内容(主要是类型信息)全部移到元空间中。 --《深入理解Java虚拟机》
2 字符串常量池的创建
字符串的创建有3种方式:
使用字面量直接赋值
String s="hello";
使用字面量赋值,只会直接分配到字符串常量池中。如果字符串常量池中存在则直接返回,如果不存在则先创建,然后返回。
这里需要注意字符串常量池中存储的是引用值而不是实例对象,具体的实例对象存储在堆中。

example-1:
String s0="hello";
String s1="hello";
System.out.println( s0==s1 ); //true
example-2:
String s1="hello";
String s2="he" + "llo";
System.out.println( s1==s2 ); //true
分析:s2=字符串常量(字面量)+字符串常量(字面量),所以s2一定也是字面量。
编译期优化:如果在编译期就能确定为字面量,则编译器在编译时会进行优化。
如下代码编译成字节码是一样的

example-3:
String a = "a1";
String b = "a" + 1;
System.out.println(a == b); // true
String c = "atrue";
String d = "a" + "true";
System.out.println(a == b); // true
String e = "a3.4";
String f = "a" + 3.4;
System.out.println(a == b); // true
字节码如下:

example-4:
String a = "hello";
final String bb = "llo";
String b = "he" + bb;
System.out.println(a == b); // true
分析:被声明为final的常量值为字面量。所以可以在编译期优化。

example-5:
public static final String A; // 常量A
public static final String B; // 常量B
static {
A = "he";
B = "llo";
}
private static void example11() {
String s1 = A + B;
String s2 = "hello";
System.out.println(s1 == s2); //false
}
分析:先来先看下字面量的定义,并对比example-4。这里明明也是声明为final的常量为什么结果不一样。原因很简单,因为A,B没有在编译期赋值,只要到了运行时才会正在被创建。编译期无法进行优化
使用new String()创建
String s1 = new String("hello");
这种方式创建字符串可以理解成两步:
1.“hello"为字面量,所以首先按照字面量的方式在常量池中创建"hello”。
2.使用new指令,会在堆中开辟一块空间,然后再将堆的地址返回到栈上保存。

example-6:
String s0="hello";
String s1=new String("hello");
String s2="he" + new String("llo");
System.out.println( s0==s1 ); // false
System.out.println( s0==s2 ); // false
System.out.println( s1==s2 ); // false
分析:编译期无法优化:用new String() 创建的字符串不是常量,不能在编译期就确定,不会放入常量池中,会在堆上分配空间。
example-7:
String a = "ab";
final String bb = getBB();
String b = "a" + bb;
System.out.println(a == b); // false
private static String getBB()
{
return "b";
}
分析:编译期无法优化
example-8:
String s = "he" + "llo"; //编译时优化为: "hello";
String a = "he";
String b = "llo";
String s1 = a + b;
System.out.println(s == s1);//false
分析:注意这里 s1 = a+b ,a和b都不是字面量,而是符号引用,在编译期无法优化。
对于上面三个例子,我们来观察下字节码

可以看出来JVM指令码中实际是通过StringBuilder.append来实现的“+”操作,然后调用toString()。再来看下StringBuilder类的toString源码,底层还是一个new String操作。

所以对于String s1 = a + b;(符号引用相加)可以理解为如下代码,等同于new String()的效果。
StringBuilder temp = new StringBuilder();
temp.append(a).append(b);
String s1 = temp.toString();
使用intern方法创建
String::intern()是一个本地方法,它的作用是如果字符串常量池中已经包含一个等于此String对象的字符串,则返回代表池中这个字符串的String对象的引用;否则,会将此String对象包含的字符串添加到常量池中,并且返回此String对象的引用。(jdk1.6版本需要将 s1 复制到字符串常量池里)
注意
比如:String s2 = s1.intern()
拆分为两块来看:
- s1.intern()
如果常量池中不包含s1对象的字符串,则把该字符串添加到常量池;如果包含,则不做操作。- String s2 =
如果该方法的返回值有变量接收,如上面的s2,它始终会得到代表池中这个字符串的引用
1.字符串常量池中已经包含一个等于此String对象的字符串
example-9:
//s0指向常量池
String s0 = "hello";
//s1指向堆中
String s1 = new String("hello");
//s2指向常量池
String s2 = s1.intern();
System.out.println(s0 == s2); //ture
System.out.println(s1 == s2); //false

2.字符串常量池中没有包含一个等于此String对象的字符串
example-10:
String s1 = new String("he") + new String("llo");
String s2 = s1.intern();
System.out.println(s1 == s2);
1.JDK1.6中,调用 intern() 方法,当字符串常量池中不存在时,会在永久代上创建一个实例,并存入常量池中。所以在JDK1.6中答案为false,创建了6个对象
解析
String s1 = new String(“he”) + new String(“llo”);
String s2 = s1.intern();
- 在常量池创建字面量“he”
- 在堆中创建new String(“he”)
- 同1,2创建“llo”
- 在堆上创建“hello”,“+”实际是通过StringBuilder.append().toString()实现,源码里最终使用了new String()。
但是这里需要注意此处没有字面量出现,所以不会在常量池中创建对象- 将“hello”的地址返回给s1
- s1.intern()在jdk1.6拷贝字符串的实例到永久代了

2.从JDK7开始常量池移入了堆中,因此JDK 7(以及部分其他虚拟机,例如JRockit)的intern()方法实现就不需要再拷贝字符串的实例到永久代了,既然字符串常量池已经移到Java堆中,那只需要在常量池里记录一下首次出现的实例引用即可。所以在JDK1.7中答案为true,创建了5个对象
String s1 = new String(“he”) + new String(“llo”);
String s2 = s1.intern();
- 在常量池创建字面量“he”
- 在堆中创建new String(“he”)
- 同1,2创建“llo”
- 在堆上创建“hello”,“+”实际是通过StringBuilder.append().toString()实现,源码里最终使用了new String()。
但是这里需要注意此处没有字面量出现,所以不会在常量池中创建对象- 将“hello”的地址返回给s1
- s1.intern()和之前的版本不同jdk1.7修改为直接指向堆上的实例,然后返回给S2

example-11:
String s1 = new String("he") + new String("llo");
String s2 = "hello";
System.out.println(s1 == s2); //false
example-12:
String s1 = new String("he") + new String("llo");
s1.intern();
String s2 = "hello";
System.out.println(s1 == s2);//true
分析:因为常量池中没有“hello”,S1.intern会将堆中的对象放入到常量池

我们在第2行加一句String s3 = new String(“hello”);
example-13:
String s1 = new String("he") + new String("llo");
String s3 = new String("hello");
s1.intern();
String s2 = "hello";
System.out.println(s1 == s2); //false
System.out.println(s1 == s3); //false
System.out.println(s2 == s3); //false
分析:因为第2行 new String()的原因,所以在常量池中创建了对象。 s1.intern检查到常量池中已有“hello”不再创建,相当于s1.intern()没有任何影响。而s2拿到的是常量池中的对象。所以都不相等。

把上面的第2行,第3行交换下位置,再看看
example-14:
String s1 = new String("he") + new String("llo");
s1.intern();
String s3 = new String("hello");
String s2 = "hello";
System.out.println(s1 == s2);//true
System.out.println(s1 == s3);//false
System.out.println(s2 == s3);//false

特例:
example-15:
String str1 = new StringBuilder("he").append("llo").toString();
System.out.println(str1 == str1.intern()); //true
String str2 = new StringBuilder("ja").append("va").toString();
System.out.println(str2 == str2.intern()); //false
String str3 = new StringBuilder("in").append("t").toString();
System.out.println(str3 == str3.intern()); //false
String str4 = new StringBuilder("dou").append("ble").toString();
System.out.println(str4 == str4.intern()); //false
分析:发现规律了吗? 部分java关键字在JVM初始化的时候已经放入了常量池。
五 总结
-
基本类型的包装类的常量池:
-
Java中有6种基本类型的包装类型实现了常量池技术,分别是Byte,Short,Integer,Long,Character,Boolean,其中Byte,Short,Integer,Long,Character这5种整型的包装类只是在对应值小于等于127时才可使用对象池。另外两种浮点数类型的包装类型没有实现。
-
包装类型在进行运算时可能会自动拆箱
-
-
三种常量池:
-
Class文件常量池(字面量,符号引用),其中字面量的概念需要重点掌握。
-
运行时常量池
-
字符串常量池
-
-
字符串常量池
-
字符串常量池位置,jdk不同版本中的变化。
-
字符串常量池的创建
- 使用字面量直接赋值
- 使用new String()创建
- 使用intern方法创建
-