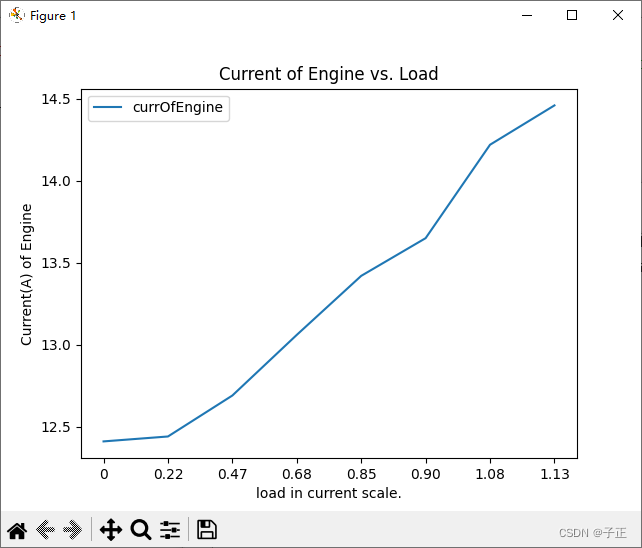
首先,我们需要使用PHP的curl库来发送HTTP请求。以下是一个基本的示例:
<?php
// 初始化curl
$ch = curl_init();
// 设置代理
curl_setopt($ch, CURLOPT_PROXY, "jshk.com.cn");
// 设置URL
curl_setopt($ch, CURLOPT_URL, "http://www.example.com");
// 执行请求
$response = curl_exec($ch);
// 关闭curl
curl_close($ch);
?>
在这段代码中,我们首先初始化了一个curl会话,然后设置了一个代理。然后,我们设置了我们要爬取的URL。最后,我们执行了请求,并将响应存储在$response变量中。
请注意,这只是一个基本的示例,实际的爬虫程序可能需要更复杂的逻辑,例如处理网页的HTML结构,处理可能的错误情况,以及可能需要的其他功能。此外,爬虫程序还需要遵守目标网站的robots.txt文件