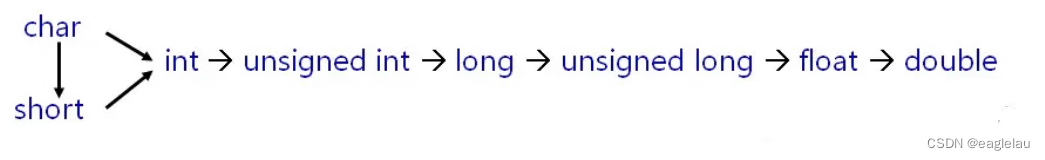在 C/C++ 中,不同的数据类型之间可以相互转换。无需用户指明如何转换的称为自动类型转换(隐式类型转换),需要用户显式地指明如何转换的称为强制类型转换。
不管是自动类型转换还是强制类型转换,前提必须是编译器知道如何转换,例如,将小数转换为整数会抹掉小数点后面的数字(由宽变窄),将 int * 转换为 float * 只是简单地复制指针的值,这些规则都是编译器内置的,我们并没有告诉编译器。
C++ 允许我们自定义类型转换规则,用户可以将其它类型转换为当前类类型,也可以将当前类类型转换为其它类型。这种自定义的类型转换规则只能以类的成员函数的形式出现,换句话说,这种转换规则只适用于自定义类。
转换构造函数:
将其它类型转换为当前类类型需要借助转换构造函数(Conversion constructor)。转换构造函数也是一种构造函数,它遵循构造函数的一般规则。转换构造函数只有一个参数。
#include <iostream>
using namespace std;
// 复数类
class Complex{
public:
Complex(): m_real(0.0), m_imag(0.0){ }
Complex(double real, double imag): m_real(real), m_imag(imag){ }
Complex(double real): m_real(real), m_imag(0.0){ } // 转换构造函数
public:
friend ostream & operator<<(ostream &out, Complex &c); // 友元函数
private:
double m_real; // 实部
double m_imag; // 虚部
};
// 重载 >> 运算符
ostream & operator<<(ostream &out, Complex &c){
out << c.m_real <<" + "<< c.m_imag <<"i";;
return out;
}
int main(){
Complex a(10.0, 20.0);
cout<<a<<endl;
a = 25.5; // 调用转换构造函数
cout<<a<<endl;
return 0;
}运行结果:
10 + 20i
25.5 + 0i
Complex(double real) 就是转换构造函数,它的作用是将 double 类型的参数 real 转换成 Complex 类的对象,并将 real 作为复数的实部,将 0 作为复数的虚部。这样一来,a = 25.5 整体上的效果相当于:a.Complex(25.5); 将赋值的过程转换成了函数调用的过程。
在进行数学运算、赋值、拷贝等操作时,如果遇到类型不兼容、需要将 double 类型转换为 Complex 类型时,编译器会检索当前的类是否定义了转换构造函数,如果没有定义的话就转换失败,如果定义了的话就调用转换构造函数。
转换构造函数也是构造函数的一种,它除了可以用来将其它类型转换为当前类类型,还可以用来初始化对象,这是构造函数本来的意义。
需要注意的是,为了获得目标类型,编译器会“不择手段”,会综合使用内置的转换规则和用户自定义的转换规则,并且会进行多级类型转换,例如:
- 编译器会根据内置规则先将 int 转换为 double,再根据用户自定义规则将 double 转换为 Complex(int --> double --> Complex);
- 编译器会根据内置规则先将 char 转换为 int,再将 int 转换为 double,最后根据用户自定义规则将 double 转换为 Complex(char --> int --> double --> Complex)。
int main(){
Complex c1 = 100; // int --> double --> Complex
cout<<c1<<endl;
c1 = 'A'; // char --> int --> double --> Complex
cout<<c1<<endl;
c1 = true; // bool --> int --> double --> Complex
cout<<c1<<endl;
Complex c2(25.8, 0.7);
// 假设已经重载了 + 运算符
c1 = c2 + 'H' + true + 15; // 将 char、bool、int 都转换为 Complex 类型再运算
cout<<c1<<endl;
return 0;
}运行结果:
100 + 0i
65 + 0i
1 + 0i
113.8 + 0.7i
可以利用构造函数的默认参数实现构造函数个数精简。
#include <iostream>
using namespace std;
// 复数类
class Complex{
public:
Complex(double real = 0.0, double imag = 0.0): m_real(real), m_imag(imag){ }
public:
friend ostream & operator<<(ostream &out, Complex &c); // 友元函数
private:
double m_real; // 实部
double m_imag; // 虚部
};
//重载>>运算符
ostream & operator<<(ostream &out, Complex &c){
out << c.m_real <<" + "<< c.m_imag <<"i";;
return out;
}
int main(){
Complex a(10.0, 20.0); // 向构造函数传递 2 个实参,不使用默认参数
Complex b(89.5); // 向构造函数传递 1 个实参,使用 1 个默认参数
Complex c; // 不向构造函数传递实参,使用全部默认参数
a = 25.5; // 调用转换构造函数(向构造函数传递 1 个实参,使用 1 个默认参数)
return 0;
}精简后的构造函数包含了两个默认参数,在调用它时可以省略部分或者全部实参,也就是可以向它传递 0 个、1 个、2 个实参。转换构造函数就是包含了一个参数的构造函数,恰好能够和其他两个普通的构造函数“融合”在一起。
类型转换函数:
转换构造函数能够将其它类型转换为当前类类型(例如将 double 类型转换为 Complex 类型),但是不能反过来将当前类类型转换为其它类型(例如将 Complex 类型转换为 double 类型)。
C++ 提供了类型转换函数(Type conversion function)来解决这个问题。类型转换函数的作用就是将当前类类型转换为其它类型,它只能以成员函数的形式出现,也就是只能出现在类中。
类型转换函数的语法格式为:
operator 目标类型 type() {
return 目标类型的数据 data;
}
operator 是 C++ 关键字,type 是要转换的目标类型,data 是要返回的 type 类型的数据。
因为要转换的目标类型是 type,所以返回值 data 也必须是 type 类型。既然已经知道了要返回 type 类型的数据,所以没有必要再像普通函数一样明确地给出返回值类型。这样做导致的结果是:类型转换函数看起来没有返回值类型,其实是隐式地指明了返回值类型。
类型转换函数也没有参数,因为要将当前类的对象转换为其它类型,所以参数不言而喻。实际上编译器会把当前对象的地址赋值给 this 指针,这样在函数体内就可以操作当前对象了。
#include <iostream>
using namespace std;
//复数类
class Complex{
public:
Complex(): m_real(0.0), m_imag(0.0){ }
Complex(double real, double imag): m_real(real), m_imag(imag){ }
public:
friend ostream & operator<<(ostream &out, Complex &c);
friend Complex operator+(const Complex &c1, const Complex &c2);
operator double() const { return m_real; } //类型转换函数
private:
double m_real; //实部
double m_imag; //虚部
};
//重载>>运算符
ostream & operator<<(ostream &out, Complex &c){
out << c.m_real <<" + "<< c.m_imag <<"i";;
return out;
}
//重载+运算符
Complex operator+(const Complex &c1, const Complex &c2){
Complex c;
c.m_real = c1.m_real + c2.m_real;
c.m_imag = c1.m_imag + c2.m_imag;
return c;
}
int main(){
Complex c1(24.6, 100);
double f = c1; // 相当于 double f = Complex::operator double(&c1);
cout<<"f = "<<f<<endl;
f = 12.5 + c1 + 6; // 相当于 f = 12.5 + Complex::operator double(&c1) + 6;
cout<<"f = "<<f<<endl;
int n = Complex(43.2, 9.3); // 先转换为 double,再转换为 int
cout<<"n = "<<n<<endl;
return 0;
}运行结果:
f = 24.6
f = 43.1
n = 43
本例中,类型转换函数非常简单,就是返回成员变量 m_real 的值,所以建议写成 inline 的形式。
类型转换函数和运算符的重载非常相似,都使用 operator 关键字,因此也把类型转换函数称为类型转换运算符。
类型转换函数特别说明:
- 目标类型 type 可以是内置类型、类类型以及由 typedef 定义的类型别名,任何可作为函数返回类型的类型(void 除外)都能够被支持。一般而言,不允许转换为数组或函数类型,转换为指针类型或引用类型是可以的。
- 类型转换函数只能定义为一个类的成员函数而不能定义为类的友元函数或普通函数 ,因为转换的主体是本类的对象。
- 类型转换函数一般不会更改被转换的对象,所以通常被定义为 const 成员。
- 类型转换函数可以被继承,可以是虚函数。
- 一个类虽然可以有多个类型转换函数(类似于函数重载),但是如果多个类型转换函数要转换的目标类型本身又可以相互转换(类型相近),那么有时候就会产生二义性。以 Complex 类为例,假设它有两个类型转换函数:
operator double() const { return m_real; } // 转换为double类型
operator int() const { return (int)m_real; } // 转换为int类型那么下面的写法就会引发二义性:
Complex c1(24.6, 100);
float f = 12.5 + c1;编译器可以调用 operator double() 将 c1 转换为 double 类型,也可以调用 operator int() 将 c1 转换为 int 类型,这两种类型都可以跟 12.5 进行加法运算,并且从 Complex 转换为 double 与从 Complex 转化为 int 是平级的,没有谁的优先级更高,所以这个时候编译器就不知道该调用哪个函数了,干脆抛出一个二义性错误,让用户解决。
- 无法抑制隐式的类型转换函数调用;
- 类型转换函数可能与转换构造函数起冲突(二义性)。
explicit 关键字:
首先,C++ 中的 explicit 关键字只能用于修饰只有一个参数的类构造函数(转换构造函数),它的作用是表明该构造函数是显式的,而非隐式的,跟它相对应的另一个关键字是 implicit,意思是隐式的,类构造函数默认情况下即声明为 implicit(隐式)。那么显式声明的构造函数和隐式声明的有什么区别呢?来看下面的例子:
class CxString {
public:
char *_pstr;
int _size;
CxString(int size) { // 没有使用 explicit 关键字, 即默认为隐式声明
_size = size; // string 的预设大小
_pstr = (char*)malloc(size + 1); // 分配 string 的内存
memset(_pstr, 0, size + 1);
}
CxString(const char *p) {
int size = strlen(p);
_pstr = (char*)malloc(size + 1); // 分配 string 的内存
strcpy(_pstr, p); // 复制字符串
_size = strlen(_pstr);
}
// 析构函数这里不讨论, 省略...
};
// 下面是调用:
CxString string1(24); // 这样是 OK 的, 为 CxString 预分配24字节的大小的内存
CxString string2 = 10; // 这样是 OK 的, 为 CxString 预分配10字节的大小的内存
CxString string3; // 这样是不行的, 因为没有默认构造函数, 错误为: “CxString”: 没有合适的默认构造函数可用
CxString string4("aaaa"); // 这样是 OK 的
CxString string5 = "bbb"; // 这样也是 OK 的, 调用的是 CxString(const char *p)
CxString string6 = 'c'; // 这样也是 OK 的, 其实调用的是 CxString(int size), 且 size 等于'c'的 ascii 码
string1 = 2; // 这样也是 OK 的, 为 CxString 预分配2字节的大小的内存
string2 = 3; // 这样也是 OK 的, 为 CxString 预分配3字节的大小的内存
上面的代码中, CxString string2 = 10;这句为什么是可以的呢?因为 C++ 把只有一个参数的构造函数当作转换构造函数来使用 -- 将对应数据类型转换为该类类型。
但是,上面的代码中的 _size 代表的是字符串内存分配的大小,那么调用的第二句 CxString string2 = 10; 和第六句 CxString string6 = 'c'; 就有了二义性,编译器会把 'char' 转换成 int 也就是 _size,并不是我们想要的结果。有什么办法阻止这种用法呢?答案就是使用 explicit 关键字。把上面的代码修改一下,如下:
class CxString {
public:
char *_pstr;
int _size;
explicit CxString(int size) { // 使用关键字 explicit 声明, 强制显式转换
_size = size;
// 代码同上, 省略...
}
CxString(const char *p) {
// 代码同上, 省略...
}
};
// 下面是调用:
CxString string1(24); // 这样是 OK 的
CxString string2 = 10; // 这样是不行的, 因为 explicit 关键字取消了隐式转换
CxString string3; // 这样是不行的, 因为没有默认构造函数
CxString string4("aaaa"); // 这样是 OK 的
CxString string5 = "bbb"; // 这样也是 OK 的, 调用的是 CxString(const char *p)
CxString string6 = 'c'; // 这样是不行的, 其实调用的是 CxString(int size), 且 _size 等于'c'的 ascii 码, 但 explicit 关键字取消了隐式转换
string1 = 2; // 这样也是不行的, 因为取消了隐式转换
string2 = 3; // 这样也是不行的, 因为取消了隐式转换
explicit 关键字的作用就是防止类构造函数的隐式自动转换(禁止隐式的调用转换构造函数,只能进行强制类型转换,即显式转换。),上面也已经说过了,explicit 关键字只对有一个参数的类构造函数有效,如果类构造函数参数大于或等于两个时,是不会产生隐式转换的,所以 explicit 关键字也就无效了。
但是,也有一个例外,就是当除了第一个参数以外的其他参数都有默认值的时候,explicit 关键字依然有效,此时,当调用构造函数时只传入一个参数,等效于只有一个参数的类构造函数,例子如下:
class CxString {
public:
int _age;
int _size;
// 使用关键字 explicit 声明
explicit CxString(int age, int size = 0) {
_age = age;
_size = size;
// 代码同上, 省略...
}
CxString(const char *p) {
// 代码同上, 省略...
}
};
// 下面是调用:
CxString string1(24); // 这样是 OK 的
CxString string2 = 10; // 这样是不行的, 因为 explicit 关键字取消了隐式转换
CxString string3; // 这样是不行的, 因为没有默认构造函数
string1 = 2; // 这样也是不行的, 因为取消了隐式转换
string2 = 3; // 这样也是不行的, 因为取消了隐式转换
string3 = string1; // 这样也是不行的, 因为取消了隐式转换, 除非类实现操作符 "=" 的重载
explicit 关键字用于禁止隐式类型转换。
C++ 隐式类型转换:
C++ 语言不会直接将两个不同类型的值相加,而是先根据类型转换规则设法将运算对象的类型统一后再求值。上述的类型转换是自动执行的,无须程序员的介入,有时甚至不需要程序员了解。因此,它们被称作隐式转换(implicit conversion)。
在下面这些情况下, 编译器会自动地转换运算对象的类型:
- 在大多数表达式中,比 int 类型小的整型值首先提升为较大的整数类型。
- 在条件中,非布尔值转换成布尔类型。
- 初始化过程中, 初始值转换成变量的类型。
- 在赋值语句中,右侧运算对象转换成左侧运算对象的类型。(和初始化类似)
- 如果算术运算或关系运算的运算对象有多种类型,需要转换成同一种类型。
- 函数调用时也会发生类型转换。
算术转换(arithmetic conversion),其含义是把一种算术类型转换成另外一种算术类型。
算术转换的规则定义了一套类型转换的层次,其中 运算符的运算对象将转换成最宽的类型
以上是《Primer C++》中的原话。我原以为最宽的类型指的是在机器中所占比特数最多的意思,但是后面还有一句话:
例如,如果一个运算对象的类型是 long double,那么不论另外一个运算对象的类型是什么 都会转换成long double。还有一种更普遍的情况,当表达式中既有浮点类型也有整数类型时,整数值将 转换成相应的浮点类型
我们知道各种不同算术类型在机器中所占的比特数:
| 32位 | 64位 | 是否变化 | |
|---|---|---|---|
| bool | 1 | ||
| char | 1 | 1 | 没有变化 |
| * 指针 | 4 | 8 | 变化 |
| short int | 2 | 2 | 没有变化 |
| int | 4 | 4 | 没有变化 |
| unsigned int | 4 | 4 | 没有变化 |
| float | 4 | 4 | 没有变化 |
| double | 8 | 8 | 没有变化 |
| long | 4 | 8 | 变化 |
| unsigned long | 4 | 8 | 变化 |
| long long | 8 | 8 | 没有变化 |
| string | 32 | ||
| void | 1 | 1 | 没有变化 |
除了 * 指针与 long 随操作系统字长变化而变化外。其它的都固定不变(32位和64相比)。
如果把宽度解释为比特数,显然当表达式中既有浮点类型也有整数类型时,不应该全部都转换成浮点类型(比如 long long 所占的比特数比 float 要多,不需要转换成浮点数)。因此这种解释是错误的。
所以这个宽度到底指什么?
整型提升:
整型提升(integral promotion)负责把小整数类型转换成较大的整数类型(同样的,这里小和大的含义也存疑,最后会总结)。在算术转换中的优先级最高。
对于 bool、char、signed char、unsigned char、short 和 unsigned short 等类型来说,只要它们所有可能的值都能存在 int 里,它们就会提升成 int 类型。否则,提升成 unsigned int 类型。就如我们所熟知的
- 布尔值 false 提升成0、true 提升成1。
- 较大的 char 类型(wchar_t、char16_t、char32_t)提升成 int、unsigned int、long、unsigned long、long long 和 unsigned long long 中最小的一种类型,前提是转换后的类型要能容纳原类型所有可能的值。
尽管 int 被称作“大类型”,但这用数据类型的比特数也能解释得通,并不能得到一些有用的信息。
除此之外,我想“转换后的类型要能容纳原类型所有可能的值”这样一个前提可以一定程度上说明C++ 在类型转换上的思路,即尽可能少的丢失原有类型的信息。
无符号类型的运算对象
如果某个运算符的运算对象类型不一致,这些运算对象将转换成同一种类型。但是如果某个运算对象的类型是无符号类型,那么转换的结果就要依赖于机器中各个整数类型的相对大小了。
像往常一样,首先执行整型提升。如果结果的类型匹配,无须进行进一步的转换。如果两个(提升后的)运算对象的类型要么都是带符号的、要么都是无符号的,则小类型的运算对象转换成较大的类型(同样不知道小和大的含义)。
如果一个运算对象是无符号类型、另外一个运算对象是带符号类型,而且其中的无符号类型不小于带符号类型,那么带符号的运算对象转换成无符号的。例如,假设两个类型分别是unsigned int和int,则int类型的运算对象转换成unsigned int类型。需要注意的是,如果int型的值恰好为负值,其结果将以"2.1.2节(第32页)"介绍的方法转换,并带来该节描述的所有"副作用"。
如果表达式里既有带符号类型又有无符号类型,当带符号类型取值为负时会出现 异常结果,这是因为 带符号数会自动地转换成无符号数。例如,在一个形如 a*b的式子中,如果a=-1,b=1,而且a和b都是int,则表达式的值显然为-1。然而,如果a是int,而b是unsigned,则结果须 视在当前机器上int所占位数而定。在我们的环境里,结果是4294967295。
剩下的一种情况是带符号类型大于无符号类型,此时转换的结果依赖于机器。如果无符号类型的所有值都能存在该带符号类型中,则无符号类型的运算对象转换成带符号类型。如果不能,那么带符号类型的运算对象转换成无符号类型。
例如,如果两个运算对象的类型分别是long和unsigned int,并且int和long的大小相同,则long类型的运算对象转换成unsigned int类型:如果long类型占用的空间比int更多,则unsigned int类型的运算对象转换成long类型。
(可以看到在假设中,int和long的相对大小是有变化的,所以类型的大小就更不可能指的是比特数。这里用了“占用的空间”这一说法,我们都知道数据类型在内存中占用的空间是固定的,那么这里占用的空间就应该有另一种解释。)<-这是我的错误想法,因为我后来想起来long在32位和64位机器中比特数会有变化。
结论:
思来想去,感觉数据类型的大小应该确实就是指内存中占用的空间大小。
而数据类型的宽度。给的例子里只有整型全部会转换成浮点型这样一个信息,以及尽可能少的丢失原有类型的信息这样一个思路。既然如此,真相最后就只有一个(眼镜反光),这个宽度指的是数据在屏幕上的宽度,而且整数和小数部分分开来算(我猜的)。
“当表达式中既有浮点类型也有整数类型时,整数值将转换成相应的浮点类型”整型的小数部分宽度都是0,比浮点数小,所以要转换成浮点数。
“较大的char类型(wchar_t、char16_t、char32_t)提升成int、unsigned int、long、unsigned long、long long 和 unsigned long long中 最小的一种类型,前提是转换后的类型要能容纳原类型所有可能的值”也可以解释,只要整数部分的宽度更大,那必然可以容纳所有的值。
按理说靠推理(猜)是不行的,但我在搜索引擎上实在找不到谁有解释这个宽度的,要从更底层的角度理解暂时水平也不够,以后学得多了可能会填坑吧,现在暂时就当是为了方便自己理解。
隐式类型转换图: