前言
今天学习 Flink 的一些原理性的东西,比较偏概念,但是十分重要。有人觉得上来框框敲代码才能学到东西,那是狗屁不通的道理(虽然我以前也这么认为)。个人认为,学习 JavaEE那些框架,你上来就敲代码确实也可以,没有太多难理解的东西;但是对于大数据、分布式包括我们学的很多计算机原理、计算机网络这种理论性强的学科,了解原理是十分有必要的,代码终将容易忘记,但是原理只要你能理解,它就不会从你的大脑里失去。就像喜欢的女孩子一样,你能懂她理解她,那她就离不开你,可是如果你在你们每次的交往过程都只顾自己的感受,用你学的地摊文化去逗她开心,那么我想她并不会觉得你是一个有趣的人。但是知道学习的方法再去懂女孩子可不是一件容易的事情啊!知识是死的,它就在那,你学知识就是你的。可人不一样,人不是物,人的认知广,就像你喜欢的人,她不是每天就和你一个交往,她可能和好人学会了好的品行、和坏人学会了坏的品行,从环境受影响又有了别的特质,所以你想了解她并不是一件容易的事情哇。而且还有一条,人家给不给你这个了解的机会还另说呢。就像我现在,之前无话不谈的人,因为各种复杂的事情影响下,她再不主动找我,我又不想厚着脸贴人家。知识它越捂越热,但是人直接的心要是离开了,就很难挽回了。害,我应该还没到那个阶段吧,到时候我自己问问。
人与人之间情断义绝,并不需要什么具体的理由。就算表面上有,也很可能只是心已经离开的结果,事后才编造出的借口而已。因为倘若心没有离开,当将会导致关系破裂的事态发生时,理应有人努力去挽救。如果没有,说明其实关係早已破裂。 -《解忧杂货店》
下次尽量别前言内容比内容都多,尽量尽量。
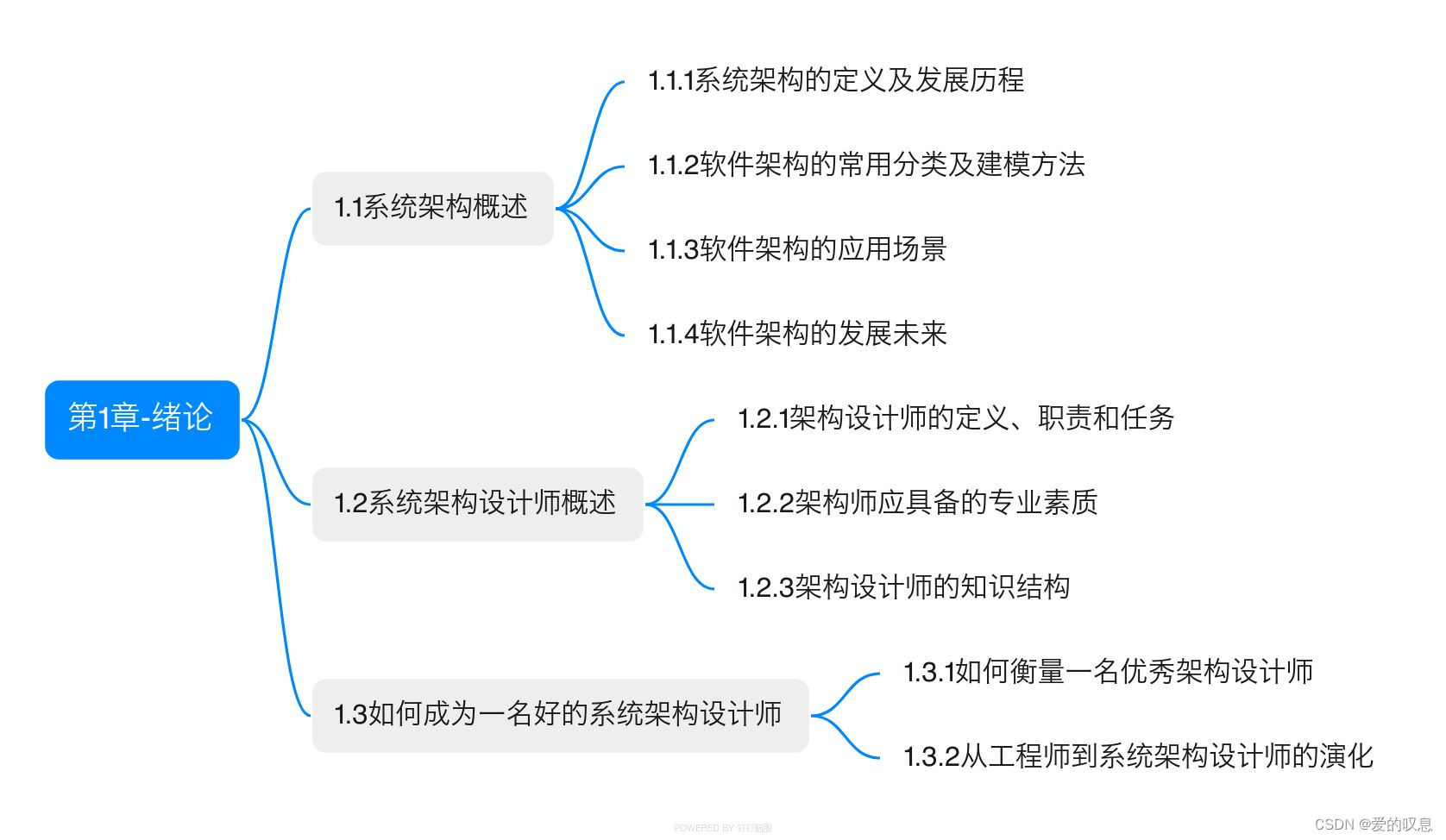
核心组件
1、JobManager
控制 Flink 应用程序执行、任务管理和调度的核心。每一个 Flink 应用程序由唯一的 JobManager 管理控制。
JobManager有三大组件:
JobMaster
- JobMaster 是 JobManager 中最核心的组件,负责处理单独的作业(一个 JobMaster 对应一个 Job,因为一个 Flink 应用程序可能有多个作业,所以就可以有多个 JobMaster)。
- 在作业提交时,JobMaster 先就收到要执行的应用(客户端发送来的: Jar包、数据流图(dataflow graph)和作业图(JobGraph))。
- JobMaster 会把作业图(JobGraph)转换成一个物理层面的数据流图,这个图被叫做 “执行图 ” (ExecutionGraph),它包含了所有可以并发执行的任务(可以并行执行多少任务,就分配给几个 TaskManager 的 TaskSlot 去)。JobManager 会向资源管理器(ResourceManager 注意:是Flink的资源管理器不是 YARN)发送请求,申请执行任务所需要的资源(如果资源不足,要么直接挂掉,要么就等待)。获得足够的资源后,就会将执行图(ExecutionGraph)发送给真正运行它们的 TaskManager 上。
- 在运行过程中,JobMaster 会负责所有需要中央协调的操作,比如检查点(checkpoint)的协调(定期做一个存盘,防止发生故障,状态丢失掉)。
ResourceManager
这里的 ResourceManager 指的是 Flink 自带的 ResourceManager ,当然也可以用 YARN 这样的资源管理平台来代替管理。
- 一个 Flink集群中,只有一个 ResourceManager ,所谓的资源,指的就是我们的 任务槽(TaskSlot) 。TaskSlot 是能够执行并行任务的最小单位,它包含了机器用来执行计算的一组 CPU 和 内存资源。每个并行的任务都会分配到一个任务槽上去执行。
- 在有 YARN 做资源提供平台的情况下,当新的作业申请资源时,ResourceManager 会将有空闲槽位的 TaskManager 分配给 JobMaster。如果 ResourceManager 没有足够的任务槽,它还可以向资源提供平台发起会话,请求提供启动 TaskManager 进程的容器。另外,ResourceManager 还负责停掉空闲的 TaskManager,释放计算资源。
Dispatcher
- Dispatcher 主要负责提供一个 REST 接口,用来提交应用,并且负责为每一个新提交的作业启动一个新的 JobMaster 组件。Dispatcher 也会启动一个 Web UI,用来方便地展示和监控作业执行的信息。Dispatcher 在架构中并不是必需的,在不同的部署模式下可能会被忽略掉(比如和一些资源管理平台集成起来之后,因为资源管理平台可以接受作业的提交)。
2、TaskManager
每一个 TaskManager 可以看做是一个 JVM 进程。
- 真正的工作者,在一个 Flink 集群中通常有多个 TaskManager 运行,每一个 TaskManager 都包含了一定数量的任务槽(task slots)。Task Slot 的数量限制了 TaskManager 能够并行处理的任务数量。
- 启动之后,TaskManager 回向 RsourceManager 注册自己的 TaskSlot (汇报自己有多少可用的资源),收到 RsourceManager 的指令后,TaskManager 就会将一个或多个 TaskSlot 提供给 JobMaster 去调用。JobMaster 就可以向 TaskSlot 分配任务(Tasks)去执行了。
- 在执行过程中,TaskManager 可以缓冲数据,还可以跟其他运行同一应用的 TaskManager交换数据。
Flink 作业提交流程
1、抽象视角
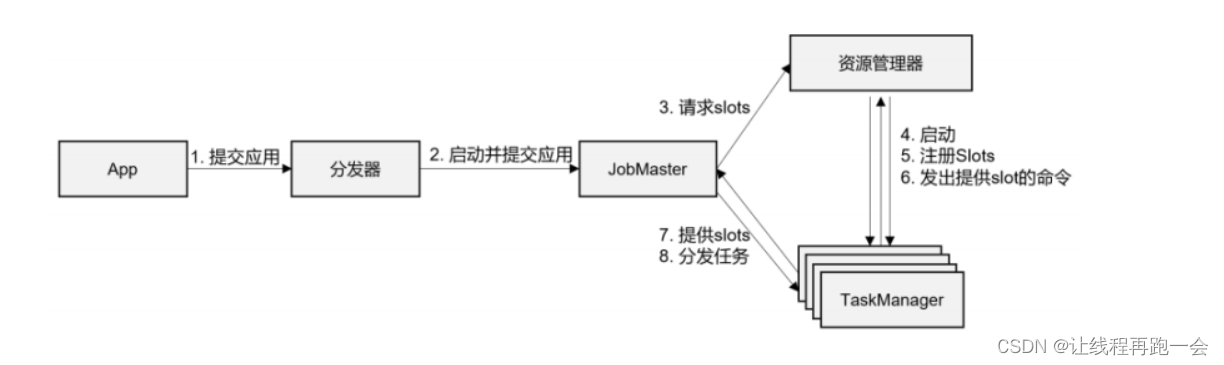
(1) 一般情况下,由客户端(App)通过分发器提供的 REST 接口,将作业提交给JobManager(提交给 JobManager 的作业已经被处理过了,代码已经被解析成了作业)。
(2)由分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
(3)JobMaster 将 JobGraph 解析为可执行的 ExecutionGraph,得到所需的资源数量,然后向资源管理器(Flink自带的ResourceManager或者YARN)请求资源(taskslots)。
(4)资源管理器判断当前是否由足够的可用资源;如果没有,启动新的 TaskManager。
(5)TaskManager 启动之后,向 ResourceManager 注册自己的可用任务槽(slots)。
(6)资源管理器通知 TaskManager 为新的作业提供 slots。
(7)TaskManager 连接到对应的 JobMaster,提供 slots。
(8)JobMaster 将需要执行的任务分发给 TaskManager。
(9)TaskManager 执行任务,互相之间可以交换数据。
2、独立模式(Standalone)
独立模式,就是不借助外部资源管理框架的模式。在独立模式(Standalone)下,只有会话模式和应用模式两种部署方式(单作业模式在Flink中是无法直接运行的,需要借助外部资源管理框架如YARN等)。
会话模式和应用模式的流程是相似的:TaskManager 都需要手动启动,所以当 ResourceManager 收到 JobMaster 的请求时,会直接要求 TaskManager 提供资源。而 JobMaster 的启动时间点,会话模式是预先启动(集群先启动再等待作业的提交),应用模式则是在作业提交时启动(而且应用模式下,代码是在 JobManager 中运行的,所以客户端只提交代码,真正的作业图是由JobManager执行代码后生成的)。
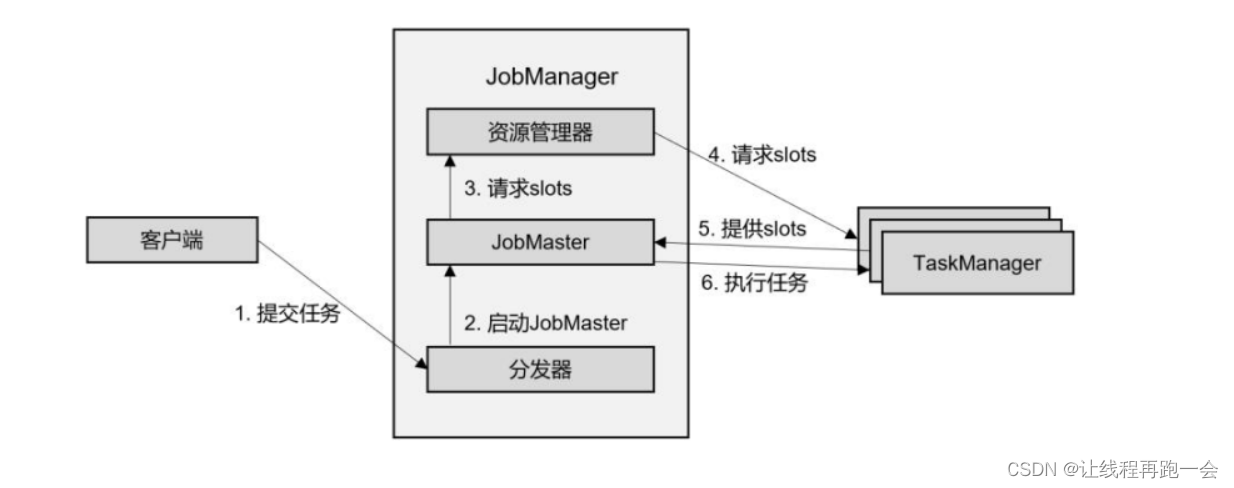
主要注意如果资源不足的情况下,会话模式是无法再去启动 TaskManager 的,因为集群是提前启动好的,资源数量是固定的。
3、YARN 模式
3.1、会话模式(yarn-session)
在会话模式下,我们需要先启动一个 YARN session,这个会话会创建一个 Flink 集群。

这里只启动了 JobManager,而 TaskManager 可以根据需要动态地启动。在 JobManager 内部,由于还没有提交作业,所以只有 ResourceManager 和 Dispatcher 在运行(JobMaster 并没有启动,因为我们知道,一个JobMaster 对应一个作业,而一个作业流图中可能包含多个作业,就绪需要启动多个 JobMaster)。

(1)客户端通过 REST 接口,将作业(代码已经被客户端运行,已经生成了作业图和数据流图)提交给分发器。
(2)分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
(3)JobMaster 向资源管理器请求资源(taskslots)。
(4)资源管理器向 YARN 的资源管理器请求 container 资源。
(5)YARN 启动新的 TaskManager 容器。
(6)TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
(7)资源管理器通知 TaskManager 为新的作业提供 slots。
(8)TaskManager 连接到对应的 JobMaster,提供 slots。
(9)JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,整个流程除了请求资源时要“上报”YARN 的资源管理器(因为Flink 的资源管理器是没有资源的,所以需要和 YARN 去申请),其他的和上面的抽象流程几乎完全一样。
3.2、单作业模式(per-job)
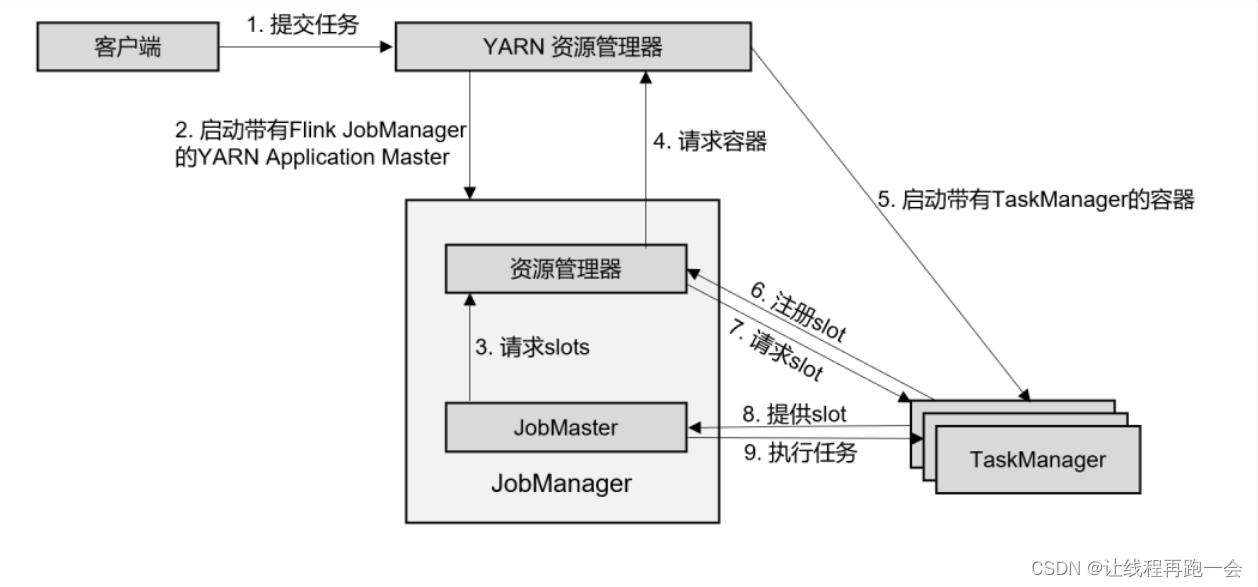
(1)客户端将作业提交给 YARN 的资源管理器,这一步中会同时将 Flink 的 Jar 包和配置上传到 HDFS,以便后续启动 Flink 相关组件的容器。
(2)YARN 的资源管理器分配 Container 资源,启动 Flink JobManager,并将作业提交给JobMaster。这里省略了 Dispatcher 组件。
(3)JobMaster 向资源管理器请求资源(slots)。
(4)资源管理器向 YARN 的资源管理器请求 container 资源。
(5)YARN 启动新的 TaskManager 容器。
(6)TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
(7)资源管理器通知 TaskManager 为新的作业提供 slots。
(8)TaskManager 连接到对应的 JobMaster,提供 slots。
(9)JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,区别只在于 JobManager 的启动方式,JobManager 是由 YARN 来启动的;而 JobMaster是由YARN的ApplicationMaster创建的;在YARN模式下,Flink的JobManager会作为YARN的一个ApplicationMaster运行,并由YARN的ResourceManager管理和调度。
当第 2 步作业提交给JobMaster,之后的流程就与会话模式完全一样了。
Flink 运行时的重要概念
1、数据流图(DataFlow)
所有的 Flink 程序都是可以由三部分组成的:Source、Transformation 和 Sink 。
其中,Source 负责读取数据,Transformation 负责利用各种算子对数据进行加工处理,而 Sink 负责数据的输出。
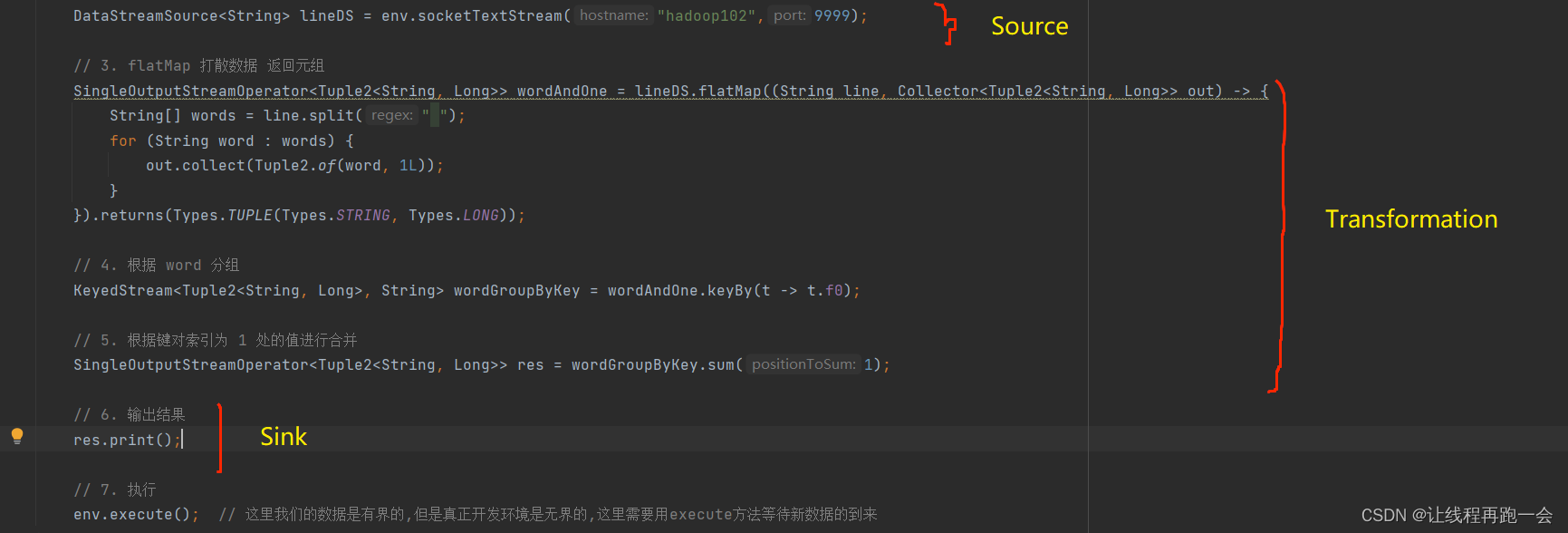
比如上面代码中,Transformation 对应的操作就有:flatMap 和 sum。而 keyBy 并不能算是一个算子(operator),因为 keyBy 的返回值并不是一个 xxxOperator 的类型。
- 在程序运行时,Flink 上运行的应用程序会被映射成“逻辑数据流”(dataflow)
- 每一个 dataflow 以一个或多个 sources 开始,以一个或多个 sinks 结束。dataflow 类似于任意的有向无环图(DAG)
- 在大部分情况下,程序中的转换运算(transformation)跟 dataflow 中的算子(operator)是一一对应的关系
我们以 Standalone 模式启动我们的 Flink 集群(standalone模式提供的 Web UI 是我们 master 的8081端口,也就是hadoop102:8081),提交我们上面的代码。

我们可以看到,keyBy 和 sum 操作被看做一个算子操作(Keyed Aggregation)。
2、并行度(parallelism)
并行度针对的我们的某一个算子的操作而言的,所以不同的操作往往并行度并不相同,比如我们上面数据流图中 source 的并行度就是 1 而 flatMap 、keyed Aggregation 和 sink 操作的并行度都是 2。
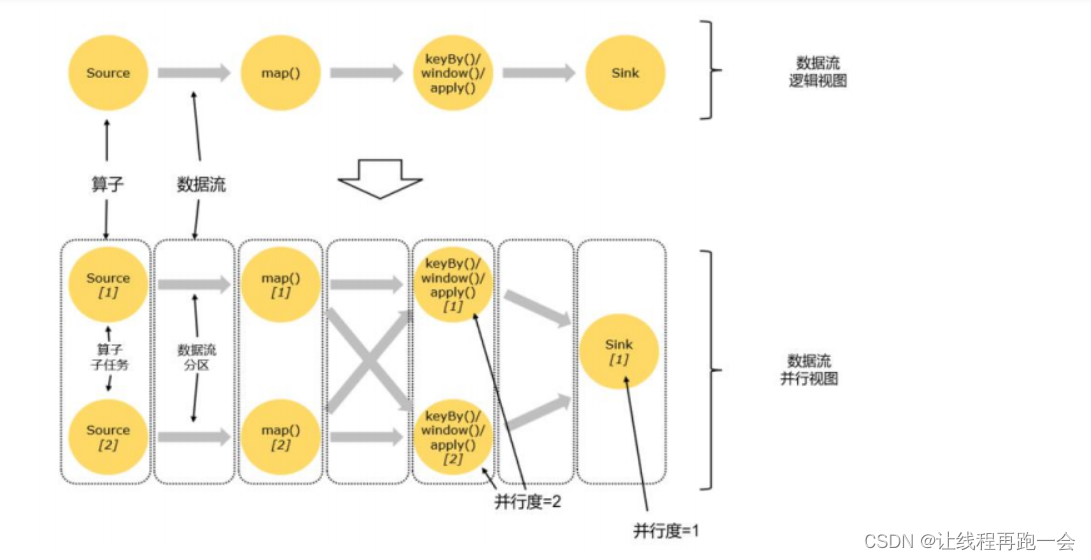
- 每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些算子任务在不同的线程(一个TaskManager 可以看做一个JVM进程)、不同的物理机或者不同的容器中完全独立低运行。
- 一个特定的算子的子任务(subtask)被称之为其并行度。
任务并行
- 比如上面的图中,一共有4个任务:source、map、keyBy-window-aply 和 sink,它们 4 个是完全并行执行的。
如果数据量很大,我们的这些个任务显然是满足不了的,比如来100亿个数,这样不管是 source 读取的时候还是后面的 map 操作,尽管都是并行执行,但面对这么大的数据量还是能力有限的。
数据并行
- 同一个操作(同一个算子,比如 source、map、sink 等)可以复制多份(也就是并行子任务,比如上面复制了多个source),同时来进行数据的处理。
像我们 Spark 的话是按照阶段进行的,所以前后不同阶段的任务没法并行。
而我们也可以在算子的相关代码中进行设置(setParallelism方法)。
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).setParallelism(2).returns(Types.TUPLE(Types.STRING, Types.LONG));另外,我们也可以直接调用执行环境的 setParallelism()方法,全局设定并行度(并不提倡):
env.setParallelism(2);
相当于在 Web UI 端:
优先级:集群环境conf/flink-conf.yaml中paralleism.default=x 的值 < Web 端 < 全局并行度 < 代码中每个算子设置的并行度
还有一种 特殊的,比如之前我们用到的读取 socket 文本流的算子 socketTextStream,它本身就是非并行的 Source 算子,所以无论怎么设置,它在运行时的并行度都是 1,对应在数据流图上就只有一个并行子任务。
3、算子链
仔细观察上面Web UI 的这个计划图,可以看到,并不是每个算子单独作为一个任务。很明显,最后一步把两个任务合并成了一个大任务。
算子之间的数据传输
一个程序中,不同的算子可能有不同的并行度。
如上图所示,一个数据流在算子之间传输数据的形式可以是一对一(one-to-one)的直通 (forwarding)模式,也可以是打乱的重分区(redistributing,图中的交叉线)模式,具体是哪一种形式,取决于算子的种类。
内容太多了,明天更新