UniADhttps://github.com/OpenDriveLab/UniAD是面向行车规划集感知(目标检测与跟踪)、建图(不是像SLAM那样对环境重建的建图,而是实时全景分割图像里的道路、隔离带等行车需关注的相关物体)、和轨迹规划和占用预测等多任务模块于一体的统一大模型。官网上的安装说明是按作者使用的较低版本的CUDA11.1.1和pytorch1.9.1来的,对应的mmcv也是较低版本的1.4版,我们工作服务器上的nvidia ngc docker环境里使用的这些支持工具软件早已是较高版本的,于是想在我们自己的环境里把UniAD跑起来,安装过程中遇到一些坑,最终都一一解决了,也实测过了,UniAD完全可以正常跑在CUDA11.6+pytorch1.12.0+mmcv1.6+mmseg0.24.0+mmdet2.24+mmdet3d1.0.0rc4组成的环境下。
安装和解决问题的步骤如下:
1.拉取使用CUDA11.6的NVIDIA NGC docker镜像并创建容器作为UniAD的运行环境
2.安装pytorch和torchvision:
pip install torch==1.12.0+cu116 torchvision==0.13.0+cu116 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu116
3.检查CUDA_HOME环境变量是否已设置,如果没有,则设置一下:
export CUDA_HOME=/usr/local/cuda
4.受CUDA和pytorch版本限制,mmcv需要安装比1.4高版本的1.6.0(关于openmmlab的mm序列框架包的安装版本对应关系参见: )
pip install mmcv-full==1.6.0 -f https://download.openmmlab.com/mmcv/dist/cu116/torch1.12.0/index.html
按照下面的对应关系:
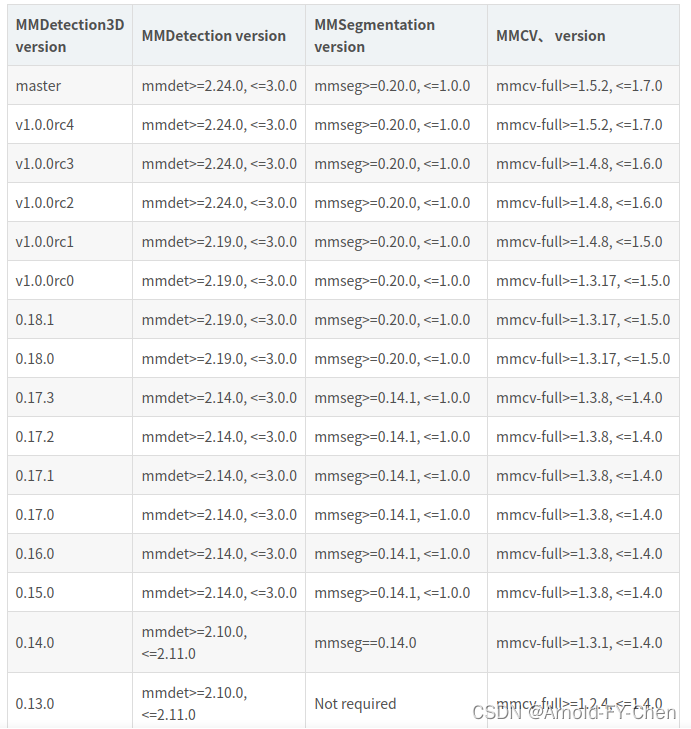
分别安装mmdet2.24.0和mmseg0.24.0
pip install mmdet==2.24.0
pip install mmsegmentation==0.24.0
下载mmdetection3d源码然后切换到v1.0.0rc4版:
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v1.0.0rc4
安装支持包并从源码编译和安装mmdet3d:
pip install scipy==1.7.3
pip install scikit-image==0.20.0
#将requirements/runtime.txt里修改一下numba的版本:
numba==0.53.1
#numba==0.53.0
pip install -v -e .
安装好了支持环境,然后下载和安装UniAD:
git clone https://github.com/OpenDriveLab/UniAD.git
cd UniAD
#修改一下requirements.txt里的numpy版本然后安装相关支持包:
#numpy==1.20.0
numpy==1.22.0
pip install -r requirements.txt
#下载相关预训练权重文件
mkdir ckpts && cd ckpts
wget https://github.com/zhiqi-li/storage/releases/download/v1.0/bevformer_r101_dcn_24ep.pth
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/uniad_base_track_map.pth
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0.1/uniad_base_e2e.pth
加入NuScenes数据集已经下载好并解压存放到 ./data/下了,那么执行
./tools/uniad_dist_eval.sh ./projects/configs/stage1_track_map/base_track_map.py ./ckpts/uniad_base_track_map.pth 8
运行一下试试看,最后一个参数是GPU个数,我的工作环境和作者的工作环境一样都是8张A100卡,所以照着做,如果卡少,修改这个参数,例如使用1,也是可以跑的,只是比较慢。
第一次运行上面命令可能会遇到下面的问题:
1. partially initialized module 'cv2' has no attribute '_registerMatType' (most likely due to a circular import)
这是因为环境里的opencv-python版本太高了,版本不兼容引起的,我的是4.8.1.78,查了一下网上,需要降到4.5,执行下面的命令重新安装opencv-python4.5即可:
pip install opencv-python==4.5.4.58
2. ImportError: libGL.so.1: cannot open shared object file: No such file or directory
安装libgl即可:
sudo apt-get update && sudo apt-get install libgl1
3. AssertionError: MMCV==1.6.0 is used but incompatible. Please install mmcv>=(1, 3, 13, 0, 0, 0), <=(1, 5, 0, 0, 0, 0)
Traceback (most recent call last):
File "tools/create_data.py", line 4, in <module>
from data_converter import uniad_nuscenes_converter as nuscenes_converter
File "/workspace/workspace_fychen/UniAD/tools/data_converter/uniad_nuscenes_converter.py", line 13, in <module>
from mmdet3d.core.bbox.box_np_ops import points_cam2img
File "/workspace/workspace_fychen/mmdetection3d/mmdet3d/__init__.py", line 5, in <module>
import mmseg
File "/opt/conda/lib/python3.8/site-packages/mmseg/__init__.py", line 58, in <module>
assert (mmcv_min_version <= mmcv_version <= mmcv_max_version), \
AssertionError: MMCV==1.6.0 is used but incompatible. Please install mmcv>=(1, 3, 13, 0, 0, 0), <=(1, 5, 0, 0, 0, 0).这错误是python3.8/site-packages/mmseg/__init__.py抛出来的,说明mmseg和mmcv1.6.0版本不兼容,它要求安装mmcv的1.3-1.5版,说明mmseg自身版本低了,原因是开始安装的mmsegmenation版本低了,改安装mmseg0.24.0即可。其它功能框架包遇到版本问题做类似处理。
4.KeyError: 'DiceCost is already registered in Match Cost'
Traceback (most recent call last):
File "./tools/test.py", line 16, in <module>
from projects.mmdet3d_plugin.datasets.builder import build_dataloader
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/__init__.py", line 3, in <module>
from .core.bbox.match_costs import BBox3DL1Cost, DiceCost
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/core/bbox/match_costs/__init__.py", line 2, in <module>
from .match_cost import BBox3DL1Cost, DiceCost
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/core/bbox/match_costs/match_cost.py", line 32, in <module>
Traceback (most recent call last):
class DiceCost(object):
File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/registry.py", line 337, in _register
File "./tools/test.py", line 16, in <module>
from projects.mmdet3d_plugin.datasets.builder import build_dataloader
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/__init__.py", line 3, in <module>
from .core.bbox.match_costs import BBox3DL1Cost, DiceCost
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/core/bbox/match_costs/__init__.py", line 2, in <module>
from .match_cost import BBox3DL1Cost, DiceCost
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/core/bbox/match_costs/match_cost.py", line 32, in <module>
class DiceCost(object):
File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/registry.py", line 337, in _register
self._register_module(module=module, module_name=name, force=force)self._register_module(module=module, module_name=name, force=force)
File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/misc.py", line 340, in new_func
File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/misc.py", line 340, in new_func
output = old_func(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/registry.py", line 272, in _register_module
raise KeyError(f'{name} is already registered '
KeyError: 'DiceCost is already registered in Match Cost''这种类注册重复了的问题是因为UniAD的mmdet3d_plugin和我安装的mmdetection的文件python3.8/site-packages/mmdet/core/bbox/match_costs/match_cost.py里有同名的DiceCost类(UniAD作者使用的mmdetection版本较低应该没有这个问题),读mmcv里面python3.8/site-packages/mmcv/utils/registry.py的注册代码可以知道这个问题可以设置参数force=True来解决:
@deprecated_api_warning(name_dict=dict(module_class='module'))
def _register_module(self, module, module_name=None, force=False):
if not inspect.isclass(module) and not inspect.isfunction(module):
raise TypeError('module must be a class or a function, '
f'but got {type(module)}')
if module_name is None:
module_name = module.__name__
if isinstance(module_name, str):
module_name = [module_name]
for name in module_name:
if not force and name in self._module_dict:
raise KeyError(f'{name} is already registered '
f'in {self.name}')
self._module_dict[name] = module为了保证UniAD代码能正确运行,允许UniAD的DiceCost类强制注册即可,也就是修改UniAD/projects/mmdet3d_plugin/core/bbox/match_costs/match_cost.py里DiceCost类的装饰器语句,增加force=True参数:
@MATCH_COST.register_module(force=True)
class DiceCost(object):
5.TypeError: cannot pickle 'dict_keys' object
File "./tools/test.py", line 261, in <module>
main()
File "./tools/test.py", line 231, in main
outputs = custom_multi_gpu_test(model, data_loader, args.tmpdir,
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/apis/test.py", line 88, in custom_multi_gpu_test
for i, data in enumerate(data_loader):
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 438, in __iter__
return self._get_iterator()
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 384, in _get_iterator
return _MultiProcessingDataLoaderIter(self)
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1048, in __init__
w.start()
File "/opt/conda/lib/python3.8/multiprocessing/process.py", line 121, in start
self._popen = self._Popen(self)
File "/opt/conda/lib/python3.8/multiprocessing/context.py", line 224, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "/opt/conda/lib/python3.8/multiprocessing/context.py", line 284, in _Popen
return Popen(process_obj)
File "/opt/conda/lib/python3.8/multiprocessing/popen_spawn_posix.py", line 32, in __init__
super().__init__(process_obj)
File "/opt/conda/lib/python3.8/multiprocessing/popen_fork.py", line 19, in __init__
self._launch(process_obj)
File "/opt/conda/lib/python3.8/multiprocessing/popen_spawn_posix.py", line 47, in _launch
reduction.dump(process_obj, fp)
File "/opt/conda/lib/python3.8/multiprocessing/reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
TypeError: cannot pickle 'dict_keys' object解决办法参见 如何定位TypeError: cannot pickle dict_keys object错误原因及解决NuScenes数据集在多进程并发训练或测试时出现的这个错误-CSDN博客
6.protobuf报错 TypeError: Descriptors cannot not be created directly
Traceback (most recent call last):
File "./tools/test.py", line 16, in <module>
from projects.mmdet3d_plugin.datasets.builder import build_dataloader
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/__init__.py", line 5, in <module>
from .datasets.pipelines import (
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/datasets/pipelines/__init__.py", line 6, in <module>
from .occflow_label import GenerateOccFlowLabels
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/datasets/pipelines/occflow_label.py", line 5, in <module>
from projects.mmdet3d_plugin.uniad.dense_heads.occ_head_plugin import calculate_birds_eye_view_parameters
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/__init__.py", line 2, in <module>
from .dense_heads import *
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/dense_heads/__init__.py", line 4, in <module>
from .occ_head import OccHead
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/dense_heads/occ_head.py", line 16, in <module>
from .occ_head_plugin import MLP, BevFeatureSlicer, SimpleConv2d, CVT_Decoder, Bottleneck, UpsamplingAdd, \
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/dense_heads/occ_head_plugin/__init__.py", line 1, in <module>
from .metrics import *
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/uniad/dense_heads/occ_head_plugin/metrics.py", line 10, in <module>
from pytorch_lightning.metrics.metric import Metric
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/__init__.py", line 29, in <module>
from pytorch_lightning.callbacks import Callback # noqa: E402
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/callbacks/__init__.py", line 25, in <module>
from pytorch_lightning.callbacks.swa import StochasticWeightAveraging
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/callbacks/swa.py", line 26, in <module>
from pytorch_lightning.trainer.optimizers import _get_default_scheduler_config
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/__init__.py", line 18, in <module>
from pytorch_lightning.trainer.trainer import Trainer
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 30, in <module>
from pytorch_lightning.loggers import LightningLoggerBase
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/loggers/__init__.py", line 18, in <module>
from pytorch_lightning.loggers.tensorboard import TensorBoardLogger
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/loggers/tensorboard.py", line 25, in <module>
from torch.utils.tensorboard import SummaryWriter
File "/opt/conda/lib/python3.8/site-packages/torch/utils/tensorboard/__init__.py", line 12, in <module>
from .writer import FileWriter, SummaryWriter # noqa: F401
File "/opt/conda/lib/python3.8/site-packages/torch/utils/tensorboard/writer.py", line 9, in <module>
from tensorboard.compat.proto.event_pb2 import SessionLog
File "/opt/conda/lib/python3.8/site-packages/tensorboard/compat/proto/event_pb2.py", line 17, in <module>
from tensorboard.compat.proto import summary_pb2 as tensorboard_dot_compat_dot_proto_dot_summary__pb2
File "/opt/conda/lib/python3.8/site-packages/tensorboard/compat/proto/summary_pb2.py", line 17, in <module>
from tensorboard.compat.proto import tensor_pb2 as tensorboard_dot_compat_dot_proto_dot_tensor__pb2
File "/opt/conda/lib/python3.8/site-packages/tensorboard/compat/proto/tensor_pb2.py", line 16, in <module>
from tensorboard.compat.proto import resource_handle_pb2 as tensorboard_dot_compat_dot_proto_dot_resource__handle__pb2
File "/opt/conda/lib/python3.8/site-packages/tensorboard/compat/proto/resource_handle_pb2.py", line 16, in <module>
from tensorboard.compat.proto import tensor_shape_pb2 as tensorboard_dot_compat_dot_proto_dot_tensor__shape__pb2
File "/opt/conda/lib/python3.8/site-packages/tensorboard/compat/proto/tensor_shape_pb2.py", line 36, in <module>
_descriptor.FieldDescriptor(
File "/opt/conda/lib/python3.8/site-packages/google/protobuf/descriptor.py", line 561, in __new__
_message.Message._CheckCalledFromGeneratedFile()
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).我的protobuf版本4.24.4太高了,降为3.20后就可以了:
pip install protobuf==3.20
7. TypeError: expected str, bytes or os.PathLike object, not _io.BufferedReader
Traceback (most recent call last):
File "/opt/conda/lib/python3.8/site-packages/mmcv/utils/registry.py", line 69, in build_from_cfg
return obj_cls(**args)
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/datasets/nuscenes_e2e_dataset.py", line 78, in __init__
super().__init__(*args, **kwargs)
File "/workspace/workspace_fychen/mmdetection3d/mmdet3d/datasets/nuscenes_dataset.py", line 131, in __init__
super().__init__(
File "/workspace/workspace_fychen/mmdetection3d/mmdet3d/datasets/custom_3d.py", line 88, in __init__
self.data_infos = self.load_annotations(open(local_path, 'rb'))
File "/workspace/workspace_fychen/UniAD/projects/mmdet3d_plugin/datasets/nuscenes_e2e_dataset.py", line 152, in load_annotations
data = pickle.loads(self.file_client.get(ann_file))
File "/opt/conda/lib/python3.8/site-packages/mmcv/fileio/file_client.py", line 1014, in get
return self.client.get(filepath)
File "/opt/conda/lib/python3.8/site-packages/mmcv/fileio/file_client.py", line 535, in get
with open(filepath, 'rb') as f:
TypeError: expected str, bytes or os.PathLike object, not _io.BufferedReader问题原因出现在高版本的mmdetection3d/mmdet3d/datasets/custom_3d.py里考虑了支持local_path读取文件,传入load_annotations()的就是个io句柄了:
def __init__(self,
data_root,
ann_file,
pipeline=None,
classes=None,
modality=None,
box_type_3d='LiDAR',
filter_empty_gt=True,
test_mode=False,
file_client_args=dict(backend='disk')):
super().__init__()
self.data_root = data_root
self.ann_file = ann_file
self.test_mode = test_mode
self.modality = modality
self.filter_empty_gt = filter_empty_gt
self.box_type_3d, self.box_mode_3d = get_box_type(box_type_3d)
self.CLASSES = self.get_classes(classes)
self.file_client = mmcv.FileClient(**file_client_args)
self.cat2id = {name: i for i, name in enumerate(self.CLASSES)}
# load annotations
if not hasattr(self.file_client, 'get_local_path'):
with self.file_client.get_local_path(self.ann_file) as local_path:
self.data_infos = self.load_annotations(open(local_path, 'rb'))
else:
warnings.warn(
'The used MMCV version does not have get_local_path. '
f'We treat the {self.ann_file} as local paths and it '
'might cause errors if the path is not a local path. '
'Please use MMCV>= 1.3.16 if you meet errors.')
self.data_infos = self.load_annotations(self.ann_file)根源是UniAD的UniAD/projects/mmdet3d_plugin/datasets/nuscenes_e2e_dataset.py里
在实现load_annotations()时默认是只支持使用ann_file是字符串类型,所以这里强制修改一下mmdetection3d/mmdet3d/datasets/custom_3d.py改回使用self.data_infos = self.load_annotations(self.ann_file)即可。
8. RuntimeError: DataLoader worker (pid 33959) is killed by signal: Killed
前面的7个问题都解决后,如果NuScenes数据集是完整的且位置正确的话,运行下面的命令应该都可以运行:
./tools/uniad_dist_eval.sh ./projects/configs/stage1_track_map/base_track_map.py ./ckpts/uniad_base_track_map.pth 8
./tools/uniad_dist_eval.sh ./projects/configs/stage2_e2e/base_e2e.py ./ckpts/uniad_base_e2e.pth 8
但是可能会在循环读取数据时发生超时错误而导致dataloader所在进程被杀掉:
Traceback (most recent call last):
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1134, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/opt/conda/lib/python3.8/multiprocessing/queues.py", line 107, in get
if not self._poll(timeout):
File "/opt/conda/lib/python3.8/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/opt/conda/lib/python3.8/multiprocessing/connection.py", line 424, in _poll
r = wait([self], timeout)
File "/opt/conda/lib/python3.8/multiprocessing/connection.py", line 936, in wait
timeout = deadline - time.monotonic()
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 33959) is killed by signal: Killed.查了一下,发现原因是配置文件projects/configs/stage1_track_map/base_track_map.py和projects/configs/stage2_e2e/base_e2e.py里的workers_per_gpu=8的设置对我们的服务器来说太多了,改为2后,再运行上面的命令可以顺利执行完毕。







![[Vue warn]: Missing required prop: “action“](https://img-blog.csdnimg.cn/09f3f846baea4883b0e8b2172584398a.png)