最近在和大佬朋友们交流的时候,发现时间序列领域有一个很有潜力的新方向:大模型+时间序列。
大模型可以处理不同类型的时间序列数据,例如文本、图像、音频等,也可以适应不同的时间序列数据的变化和异常情况,有助于提高时间序列预测的准确性和稳定性。另外,大模型还可以通过文本形式提供解释性的时间序列预测结果,从而帮助我们更好地理解时间序列数据的模式和趋势。
为了方便想发论文的同学,我今天就来分享该领域的15篇必读论文,这些文章主要涉及2大方向,一是用大模型处理时间序列,二是训练时间序列领域的大模型。
论文原文及模型代码都整理好了,需要的同学看文末
大模型处理时间序列
通用领域
1.Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
通过重新编程大型语言模型进行时间序列预测
简述:Time-LLM是一种重新编程大型语言模型(LLM)以进行通用时间序列预测的方法,通过将输入的时间序列与文本原型重新编程并使用Prompt-as-Prefix(PaP)来增强LLM对时间序列数据的推理能力。

2.OFA:One Fits All:Power General Time Series Analysis by Pretrained LM
通过预训练语言模型实现强大的一般性分析
简述:本文介绍了一种名为Frozen Pretrained Transformer(FPT)的通用时间序列分析方法,利用预训练的语言或图像模型来解决时间序列分析任务中的缺乏大量数据的问题。

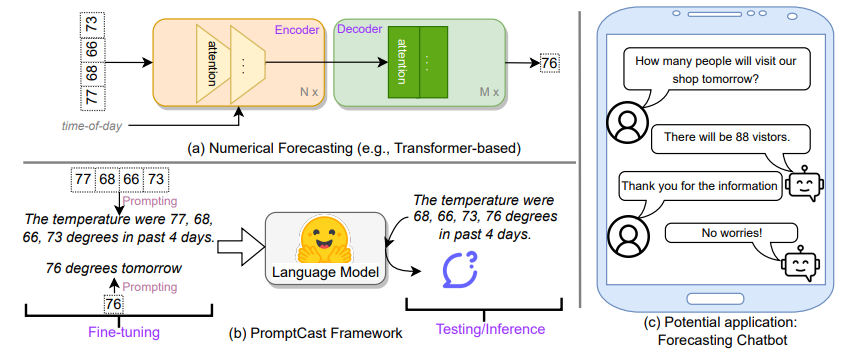
3.PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting
一种新的基于提示的时间序列预测学习范式
简述:本文提出了一种名为PromptCast的基于提示的时间序列预测方法,将数值输入和输出转化为提示,以句子到句子的方式进行预测任务,并引入大型数据集PISA进行评估。该方法具有可行性和有效性,并在零样本设置下表现出更好的泛化能力。
4.TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
用于时间序列预测的基于提示的生成式预训练Transformer模型
简述:本文提出了一种新型框架TEMPO,利用时间序列任务的两个重要归纳偏置来预训练模型,并在多个时间序列基准数据集上表现出优于现有方法的性能。

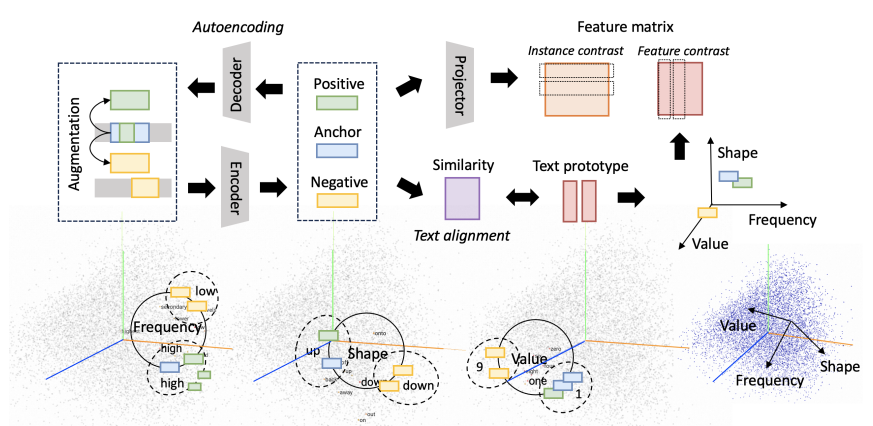
5.TEST: Text Prototype Aligned Embedding to Activate LLM's Ability for Time Series
TEST: 文本原型对齐嵌入以激活LLM的时间序列能力
简述:本文提出了TEST的方法,首先将TS进行标记化,然后构建一个编码器,通过实例、特征和文本原型对齐对比来嵌入它们,接着创建提示让LLM更加开放地接受嵌入,并最终实现TS任务。在8个不同结构和规模的LLM上的实验证明了该方法的可行性。
6.LLM4TS: Two-Stage Fine-Tuning for Time-Series Forecasting with Pre-Trained LLMs
基于预训练llms的时间序列预测的两阶段微调
简述:本文提出了LLM4TS方法,利用预训练的大型语言模型(LLM)增强时间序列预测。通过两阶段微调过程和参数高效微调技术,增强了LLM处理时间序列数据的能力,并在长期预测方面取得了最先进的结果。

7.Large Language Models Are Zero-Shot Time Series Forecasters
大型语言模型是零射击时间序列预测器
简述:论文发现大型语言模型(如GPT-3和LLaMA-2)可以零样本推断时间序列,其性能可能超过针对下游任务进行训练的专用时间序列模型。为了促进这种性能,作者提出了有效标记化时间序列数据和将离散分布转换为高度灵活的连续值密度的程序。

特定领域
1.(交通)Leveraging Language Foundation Models for Human Mobility Forecasting
利用语言基础模型进行人类移动预测
简述:本文提出了一种新颖的流程,利用语言基础模型进行时间序列模式挖掘,例如人类移动预测任务。作者设计了一个AuxMobLCast的方法,通过引入特定的提示将数值时间序列转换为句子,使现有的语言模型可以直接应用于预测任务。

2.(金融)Temporal Data Meets LLM -- Explainable Financial Time Series Forecasting
可解释的金融时间序列预测
简述:本文提出了一种新颖的研究方法,利用大型语言模型(LLMs)出色的知识和推理能力进行可解释的金融时间序列预测。展示了LLMs在解决金融时间序列预测中的跨序列推理和推断困难、融入多模态信号的障碍以及解释和说明模型结果的问题方面的潜力。
3.(金融)The Wall Street Neophyte: A Zero-Shot Analysis of ChatGPT Over MultiModal Stock Movement Prediction Challenges
ChatGPT在多模态股票走势预测挑战中的零射击分析
简述:本文对ChatGPT在多模态股票运动预测中的能力和局限性进行了广泛的零射击分析,结果表明ChatGPT在预测股票运动方面表现不佳,不仅落后于最先进的方法,还落后于使用价格特征的线性回归等传统方法。
4.(金融)Instruct-fingpt: Financial sentiment analysis by instruction tuning of general-purpose large language models
通过通用大型语言模型的指令调优进行金融情感分析
简述:本文介绍了一种简单而有效的指令调优方法,通过将一小部分有监督的金融情感分析数据转化为指令数据,并使用该方法微调通用大型语言模型,显著提高了金融情感分析的效果。

5.(医疗)Large Language Models are Few-Shot Health Learners
大型语言模型少样本健康学习
简述:本文证明,只需进行少数几次调整,大型语言模型就能够将各种生理和行为时间序列数据与文本联系起来,并在临床和健康领域对许多健康任务进行有意义的推断。

6.(医疗)Frozen language model helps ecg zero-shot learning
冻结语言模型帮助心电图零样本学习
简述:METS是一种利用自动生成的临床报告指导ECG SSL预训练的方法,通过最大化配对ECG和自动生成的报告之间的相似度,最小化ECG和其他报告之间的相似度,实现了在不使用任何注释数据的情况下进行零次分类。

时间序列领域大模型
1.TimeGPT-1
简述:本文介绍了TimeGPT,这是第一个用于时间序列的基础模型,能够为在训练期间未见过的各种数据集生成准确的预测。作者评估了预训练模型与已建立的统计、机器学习和深度学习方法之间的性能,证明TimeGPT零次推理在性能、效率和简单性方面表现出色。

2.Lag-Llama: Towards Foundation Models for Time Series Forecasting
迈向时间序列预测的基础模型
简述:为了建立时间序列预测的基础模型并研究它们的缩放行为,论文介绍了Lag-Llama的工作进展。 Lag-Llama是一种通用的单变量概率时间序列预测模型,在大量时间序列数据集上进行训练。该模型在未见过“分布外”时间序列数据集时表现出良好的零次预测能力,优于有监督的基线方法。

关注下方《学姐带你玩AI》🚀🚀🚀
回复“LLM时序”获取全部论文+源码
码字不易,欢迎大家点赞评论收藏!