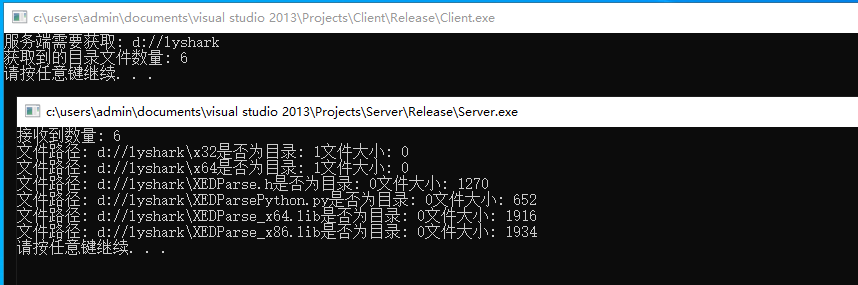
EEGNet: 神经网络应用于脑电信号
- 中文题目
- 论文下载:
- 算法程序下载:
- 摘要
- 1 项目介绍
- 2 EEGNet网络原理
- 2.1EEGNet原理架构
- 2.2FBCCA 算法
- 2.3自适应FBCCA算法
- 3EEGNet网络实现
- 4结果
中文题目
论文下载:
DOI:
算法程序下载:
地址
摘要
脑机接口(BCI)使用神经活动作为控制信号,实现与计算机的直接通信。这种神经信号通常是从各种研究透彻的脑电图(EEG)信号中挑选出来的。卷积神经网络(CNN)主要用来自动特征提取和分类,其在计算机视觉和语音识别领域中的使用已经很广泛。CNN已成功应用于基于EEG的BCI;但是,CNN主要应用于单个BCI范式,在其他范式中的使用比较少,论文作者提出是否可以设计一个CNN架构来准确分类来自不同BCI范式的EEG信号,同时尽可能地紧凑(定义为模型中的参数数量)。该论文介绍了EEGNet,这是一种用于基于EEG的BCI的紧凑型卷积神经网络。论文介绍了使用深度和可分离卷积来构建特定于EEG的模型,该模型封装了脑机接口中常见的EEG特征提取概念。论文通过四种BCI范式(P300视觉诱发电位、错误相关负性反应(ERN)、运动相关皮层电位(MRCP)和感觉运动节律(SMR)),将EEGNet在主体内和跨主体分类方面与目前最先进的方法进行了比较。结果显示,在训练数据有限的情况下,EEGNet比参考算法具有更强的泛化能力和更高的性能。同时论文也证明了EEGNet可以有效地推广到ERP和基于振荡的BCI。
1 项目介绍
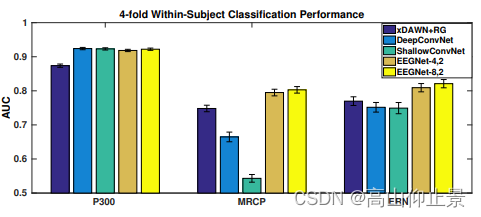
实验结果如下图,P300数据集的所有CNN模型之间的差异非常小,但是MRCP数据集却存在显著的差异,两个EEGNet模型的性能都优于所有其他模型。对于ERN数据集来说,两个EEGNet模型的性能都优于其他所有模型(p < 0.05)。
2 EEGNet网络原理
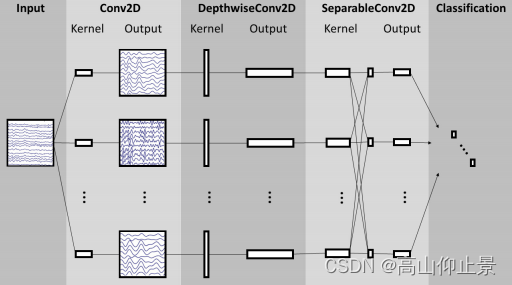
2.1EEGNet原理架构
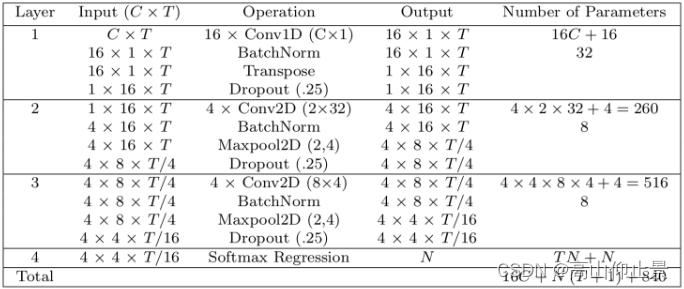
2.2FBCCA 算法
FBCCA在
2.3自适应FBCCA算法
从上述FBCCA算法可以看出,
3EEGNet网络实现
import numpy as np
from sklearn.metrics import roc_auc_score, precision_score, recall_score, accuracy_score
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
import torch.optim as optim
class EEGNet(nn.Module):
def __init__(self):
super(EEGNet, self).__init__()
self.T = 120
# Layer 1
self.conv1 = nn.Conv2d(1, 16, (1, 64), padding = 0)
self.batchnorm1 = nn.BatchNorm2d(16, False)
# Layer 2
self.padding1 = nn.ZeroPad2d((16, 17, 0, 1))
self.conv2 = nn.Conv2d(1, 4, (2, 32))
self.batchnorm2 = nn.BatchNorm2d(4, False)
self.pooling2 = nn.MaxPool2d(2, 4)
# Layer 3
self.padding2 = nn.ZeroPad2d((2, 1, 4, 3))
self.conv3 = nn.Conv2d(4, 4, (8, 4))
self.batchnorm3 = nn.BatchNorm2d(4, False)
self.pooling3 = nn.MaxPool2d((2, 4))
# 全连接层
# 此维度将取决于数据中每个样本的时间戳数。
# I have 120 timepoints.
self.fc1 = nn.Linear(4*2*7, 1)
def forward(self, x):
# Layer 1
x = F.elu(self.conv1(x))
x = self.batchnorm1(x)
x = F.dropout(x, 0.25)
x = x.permute(0, 3, 1, 2)
# Layer 2
x = self.padding1(x)
x = F.elu(self.conv2(x))
x = self.batchnorm2(x)
x = F.dropout(x, 0.25)
x = self.pooling2(x)
# Layer 3
x = self.padding2(x)
x = F.elu(self.conv3(x))
x = self.batchnorm3(x)
x = F.dropout(x, 0.25)
x = self.pooling3(x)
# 全连接层
x = x.view(-1, 4*2*7)
x = F.sigmoid(self.fc1(x))
return x
def evaluate(model, X, Y, params = ["acc"]):
results = []
batch_size = 100
predicted = []
for i in range(len(X)//batch_size):
s = i*batch_size
e = i*batch_size+batch_size
inputs = Variable(torch.from_numpy(X[s:e]))
pred = model(inputs)
predicted.append(pred.data.cpu().numpy())
inputs = Variable(torch.from_numpy(X))
predicted = model(inputs)
predicted = predicted.data.cpu().numpy()
"""
设置评估指标:
acc:准确率
auc:AUC 即 ROC 曲线对应的面积
recall:召回率
precision:精确率
fmeasure:F值
"""
for param in params:
if param == 'acc':
results.append(accuracy_score(Y, np.round(predicted)))
if param == "auc":
results.append(roc_auc_score(Y, predicted))
if param == "recall":
results.append(recall_score(Y, np.round(predicted)))
if param == "precision":
results.append(precision_score(Y, np.round(predicted)))
if param == "fmeasure":
precision = precision_score(Y, np.round(predicted))
recall = recall_score(Y, np.round(predicted))
results.append(2*precision*recall/ (precision+recall))
return results
# 定义网络
net = EEGNet()
# 定义二分类交叉熵 (Binary Cross Entropy)
criterion = nn.BCELoss()
# 定义Adam优化器
optimizer = optim.Adam(net.parameters())
"""
生成训练数据集,数据集有100个样本
训练数据X_train:为[0,1)之间的随机数;
标签数据y_train:为0或1
"""
X_train = np.random.rand(100, 1, 120, 64).astype('float32')
y_train = np.round(np.random.rand(100).astype('float32'))
"""
生成验证数据集,数据集有100个样本
验证数据X_val:为[0,1)之间的随机数;
标签数据y_val:为0或1
"""
X_val = np.random.rand(100, 1, 120, 64).astype('float32')
y_val = np.round(np.random.rand(100).astype('float32'))
"""
生成测试数据集,数据集有100个样本
测试数据X_test:为[0,1)之间的随机数;
标签数据y_test:为0或1
"""
X_test = np.random.rand(100, 1, 120, 64).astype('float32')
y_test = np.round(np.random.rand(100).astype('float32'))
batch_size = 32
# 训练 循环
for epoch in range(10):
print("\nEpoch ", epoch)
running_loss = 0.0
for i in range(len(X_train)//batch_size-1):
s = i*batch_size
e = i*batch_size+batch_size
inputs = torch.from_numpy(X_train[s:e])
labels = torch.FloatTensor(np.array([y_train[s:e]]).T*1.0)
# wrap them in Variable
inputs, labels = Variable(inputs), Variable(labels)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 验证
params = ["acc", "auc", "fmeasure"]
print(params)
print("Training Loss ", running_loss)
print("Train - ", evaluate(net, X_train, y_train, params))
print("Validation - ", evaluate(net, X_val, y_val, params))
print("Test - ", evaluate(net, X_test, y_test, params))
定义评估指标:
acc:准确率
auc:AUC 即 ROC 曲线对应的面积
recall:召回率
precision:精确率
fmeasure:F值
4结果
在这项工作中,我们提出了EEGNet,一个小型的卷积神经网络,用于基于脑电图的BCI,它可以在有限的数据存在的情况下泛化不同的BCI范式,并产生可解释的特征。我们通过四个EEG数据集:P300视觉诱发电位、错误相关负波(ERN)、运动相关皮层电位(MRCP)和感觉运动节律(SMR),对EEGNet与基于ERP和振荡的BCIs的最先进方法进行了评估。据我们所知,这是第一次验证跨多个BCI数据集使用单一网络架构的工作,每个数据集都有自己的特征和数据集大小。我们的工作介绍了使用深度和可分离卷积脑电图信号分类,并表明它们可以用来构建一个脑电图特定的模型,其中包含众所周知的脑电图特征提取概念。最后,通过使用特征可视化和消融分析,我们表明可以从EEGNet模型中提取神经生理学可解释的特征。最后这一发现尤其重要,因为它是理解CNN模型结构的有效性和鲁棒性的关键组成部分,不仅对EEG,而且对一般的CNN结构也是如此。
CNN的学习能力部分来自于它们从原始数据中自动提取复杂特征表示的能力。然而,由于这些特征不是由人类工程师手工设计的,理解这些特征的含义在生成可解释的模型方面是一个重大挑战。当cnn被用于脑电图数据的分析时,这一点尤其正确,因为神经信号的特征往往是非平稳的,并被噪声伪影损坏。在本研究中,我们展示了三种不同的方法来可视化EEGNet学到的特性:
(1)分析P300数据集上的空间滤波器输出,平均试次结果;
(2)可视化SMR数据集上的卷积核权值,并将其与FBCSP学到的权值进行比较;
(3)对MRCP和SMR数据集进行单试次相关性分析。对于ERN数据集,我们比较了单试次特征相关性和平均ERP,发现相关特征与正确和错误反馈试次的正峰值一致,这在之前的文献中已经表明与分类器性能呈正相关。此外,我们进行了一项特征消融研究,以了解分类决策对P300数据集上特定特征存在与否的影响。在每一项分析中,我们都表明EEGNet能够提取与已知神经生理现象相对应的可解释特征。
总体而言,DeepConvNet和EEGNet在所有跨被试分析中的分类表现相似,而DeepConvNet在几乎所有被试内分析中的分类表现较低(P300除外)。对这种差异的一种可能解释是用于训练模型的训练数据的数量;在跨被试分析中,训练集的大小大约是被试内分析的10-15倍。这表明,与EEGNet相比,DeepConvNet的数据密集型更强,考虑到DeepConvNet的模型规模比EEGNet大两个数量级,这一结果并不令人惊讶(见表3)。我们相信,这与DeepConvNet的开发人员最初报告的发现是一致的。他们指出,需要训练数据增强策略来获得对SMR数据集的良好分类性能。与他们的工作相比,我们表明EEGNet在所有测试数据集上表现良好,而不需要数据扩充,这使得模型在实践中更容易使用。
总的来说,我们发现,在被试内和跨被试分析中,ShallowConvNet倾向于在ERP BCI数据集上比在振荡BCI数据集(SMR)上表现更差,而在DeepConvNet上观察到相反的行为。我们认为这是由于ShallowConvNet架构专门设计用于提取频带特征;在主要特征是信号幅度的情况下(如许多ERP BCIs中的情况),ShallowConvNet的性能往往会受到影响。而DeepConvNet则相反;由于其架构的设计不是为了提取频率特征,所以在频率功率为主要特征的情况下,其性能较低。相比之下,我们发现EEGNet与ShallowConvNet在鼻中隔黏膜下切除术后的分类和DeepConvNet在ERP分类一样好,这表明EEGNet足够强劲的学习各种各样的功能范围的BCI任务。
鉴于MRCP和SMR之间的神经反应相似,ShallowConvNet在被试内MRCP分类上的严重不足是意料之外的,但ShallowConvNet在SMR上表现良好。这种表现上的差异并不是因为使用了大量的训练数据,因为被试内MRCP分类大约有700个训练试次,平均分布在左右手指运动中,而SMR数据集只有192个训练试次,平均分布在四个类别中。此外,在其他数据集(P300和ERN)上,我们没有观察到ShallowConvNet性能的大偏差。事实上,尽管该数据集是本研究使用的所有数据集中最小的(总共只有170个训练试次),但ShallowConvNet在被试内ERN分类方面表现得相当好。确定这一现象的潜在来源将在未来的研究中进行探索。
脑电图深度学习模型一般采用三种输入方式,取决于他们的目标应用程序:(1)脑电图信号的所有可用的通道,(2)变换后的EEG信号(通常是一个时频分解)的所有可用的通道或(3)变换后的EEG信号通道的一个子集。属于(2)的模型通常会看到数据维数显著增加,因此需要更多的数据或更多的模型正则化(或两者都需要)来学习有效的特征表示。这引入了更多必须学习的超参数,增加了由于超参数错误描述而导致的模型性能的潜在可变性。属于(3)的模型通常需要关于要选择的通道的先验知识。我们认为属于(1)的模型,例如EEGNet和其他模型,在输入维度和通过提供所有可用通道来发现相关特性的灵活性之间提供了最好的权衡。当BCI技术发展到新的应用程序空间时,这一点尤其重要,因为这些未来BCI所需的特性可能事先不知道。
总之,我们提出的EEGNet鲁棒性很好,表现很好,在多个数据集上可获得一系列可解释性特征。