生成模型具有巨大的潜力,不仅有助于通过合成数据集安全地共享医疗数据,还可以执行一系列逆向应用,如异常检测、图像到图像翻译、去噪和MRI重建。然而,由于这些模型的复杂性,它们的实现和再现性可能很困难。

对于我这种代码能力薄弱的研究者,需要有医学数据相关的现成代码借鉴参考,才能做实验。这时候,必须要大赞一下MONAI平台啦。提供了各种相关的模型和demo。
MONAI提供了一种通用的方式实现了这些模型,表明它们的结果可以扩展到2D或3D场景,包括具有不同模态(如CT、MRI和X射线数据)和不同解剖区域的医学图像。
以下是MONAI生成模型论文(arXiv:2307.15208)里面的内容,学习它可以了解MONAI在生成模型方面提供了些什么功能。以及在医学图像上,生成模型可以做些什么事!
生成式人工智能(Generative AI)是一系列旨在学习数据集的潜在模式和结构,并生成可能属于原始数据集的新数据点的人工智能技术和模型。尽管高维成像数据的数据分布非常复杂,但如今我们有各种强大的深度生成模型,例如扩散模型、自回归 transformer、生成对抗网络(GANs)和变分自编码器(VAEs),它们已经证明可以有效地学习和表示这些错综复杂的数据分布。
生成合成数据的能力一直是医学成像中生成模型的主要目标之一,因为它提供了在保护患者隐私的同时分享数据的可行解决方案。数据提供者可以在其自己的数据上训练模型,并以保护隐私的方式分享结果,而不是直接分享患者数据。最近的医学成像研究表明了生成高质量医学图像的前景能力。此外,使用包括合成数据的数据集训练进行下游任务的机器学习模型已经取得了与仅使用真实数据训练的模型相似甚至更优越的性能
除了生成合成数据之外,生成模型在医学成像中还有广泛的其他应用。其中之一是异常检测,生成模型可用于识别医学图像中的异常。这一任务对于诊断疾病和检测潜在健康风险尤为有用。另一个应用是图像到图像的翻译(风格迁移),生成模型可以被训练用于将一种模态的图像转换为另一种。例如,这些模型可以用于将CT扫描转换为MRI扫描,将标签映射转换为MRI图像,或将MRI扫描转换为异常图。此外,生成模型还可以用于图像增强,它们可以学习提高医学图像的质量而不丢失重要的临床信息。这包括图像去噪、去除图像伪影、增强图像分辨率等。最后,生成模型还可以用于图像重建,包括MRI和CT重建,它们可以从欠采样或噪声数据中重建高质量图像。这对医学成像具有重要意义,能够加快人体成像速度。总的来说,生成模型在医学成像中的潜在应用非常广泛,它们的使用可能会继续增长。
然而,这一领域伴随着挑战,包括各种质量评估指标的使用以及模型的复杂性。这些问题可能会阻碍模型的进展和实施。但是,MONAI Generative Models开源平台可以帮助我们更好的进行生成模型的开发和部署。
为了展示MONAI平台的强大功能,我们讨论了五个实验,在这些实验中我们在医学成像环境中使用了不同的模态(CT、MRI和X射线数据),涵盖了诸如异常检测、图像翻译和超分辨率等主题。我们的平台通过应用于不同的模态和身体部位,在2D和3D场景中展现了其多功能性,为推动医学成像提供了创新的途径。
使用MONAI进行异常检测
我们的平台促进了生成模型在医学影像领域的多种下游任务中的应用。在这里,我们展示了它们在对3D成像数据进行异常检测中的应用。我们采用了使用VQ-VAE + Transformers获取图像似然度的技术,正如[15,39]中所描述的那样。模型在公开可用的3D医学十项全能数据集上进行训练和评估,其中BRATs数据被选为内部分布数据集,而所有其他类别被视为异常分布数据,所有图像都被调整为128x128x128。模型的参数设置与[15]中描述的相同。平台的VQVAETransformerInferer类提供了便利的方法,用于从潜在模型中获取似然度。十项全能数据集中各类别的异常检测的AUC分数如表中所示。

使用MONAI进行图像转换
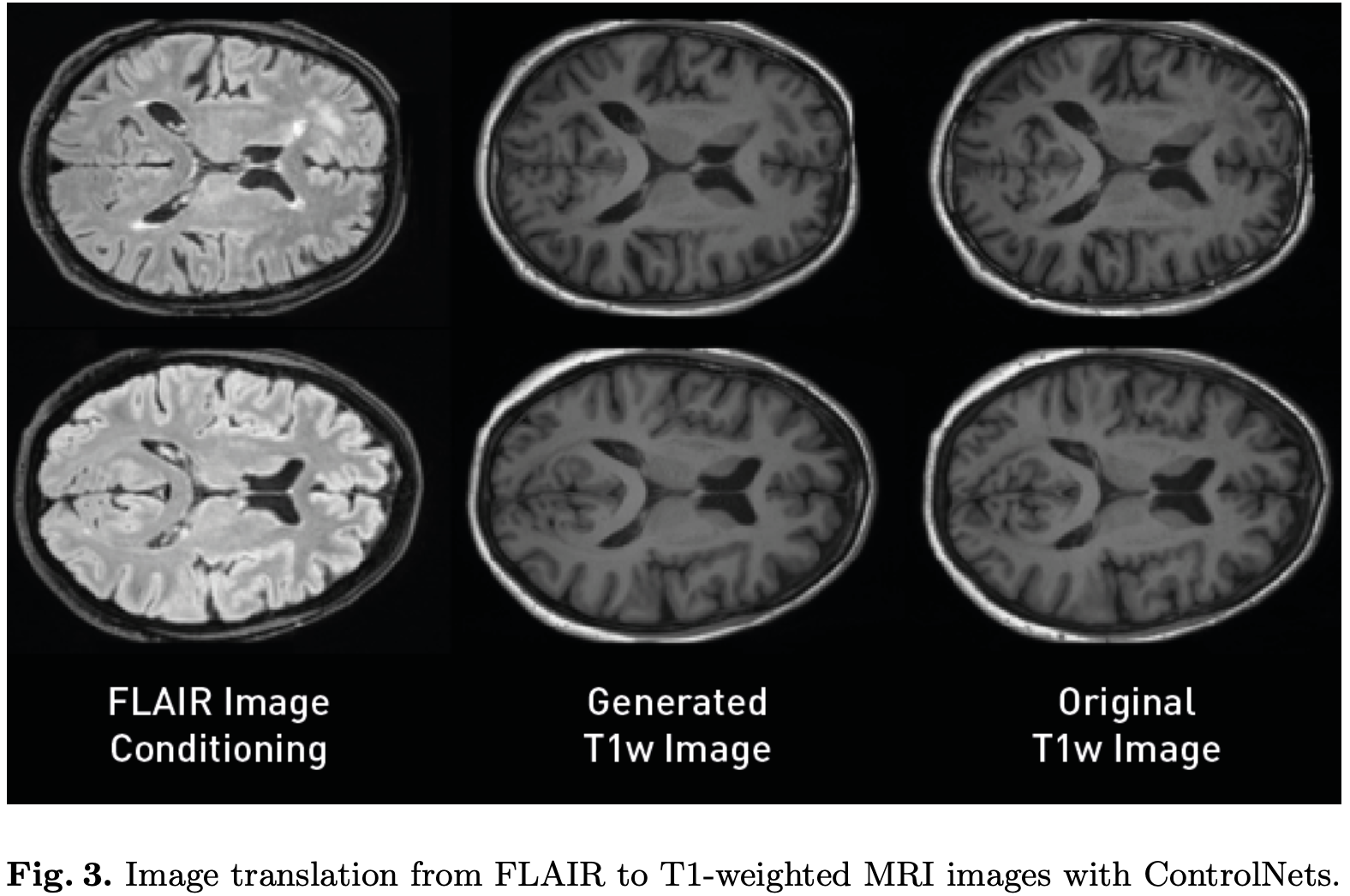
正如之前提到的,我们旨在支持的另一种应用类型是图像到图像(image-to-image)的任务。这个实验将展示ControlNets在图像翻译任务中的表现。ControlNets是一种神经网络,它显著增强了扩散模型的可控性和定制性。它们类似于轻量级的适配器,可以控制预训练网络的行为。在这个实验中,我们使用在英国生物库2D数据集上训练的模型(实验I)来训练一个ControlNet,能够将2D FLAIR切片转换成扩散模型生成的T1加权图像。为了评估模型的性能,我们使用了合成2D图像和真实T1加权图像之间的平均绝对误差、峰值信噪比和MS-SSIM。我们的模型能够在条件FLAIR图像上以高保真度生成T1加权图像,获得了PSNR=26.2458 ± 1.0092,MAE=0.02632 ± 0.0036和MS-SSIM=0.9526 ± 0.0111的性能。
使用MONAI生成超分辨率图像
生成模型已经在广泛的任务中证明了其高效性,包括超分辨率。这个任务不仅有助于提高低分辨率图像的质量,还可以通过级联模型实现图像生成。级联方法涉及训练一个生成模型来生成低分辨率图像,然后是一个专注于实现期望高分辨率的次要模型。这种方法对于3D模型特别有优势,可以用更小的内存占用进行训练。
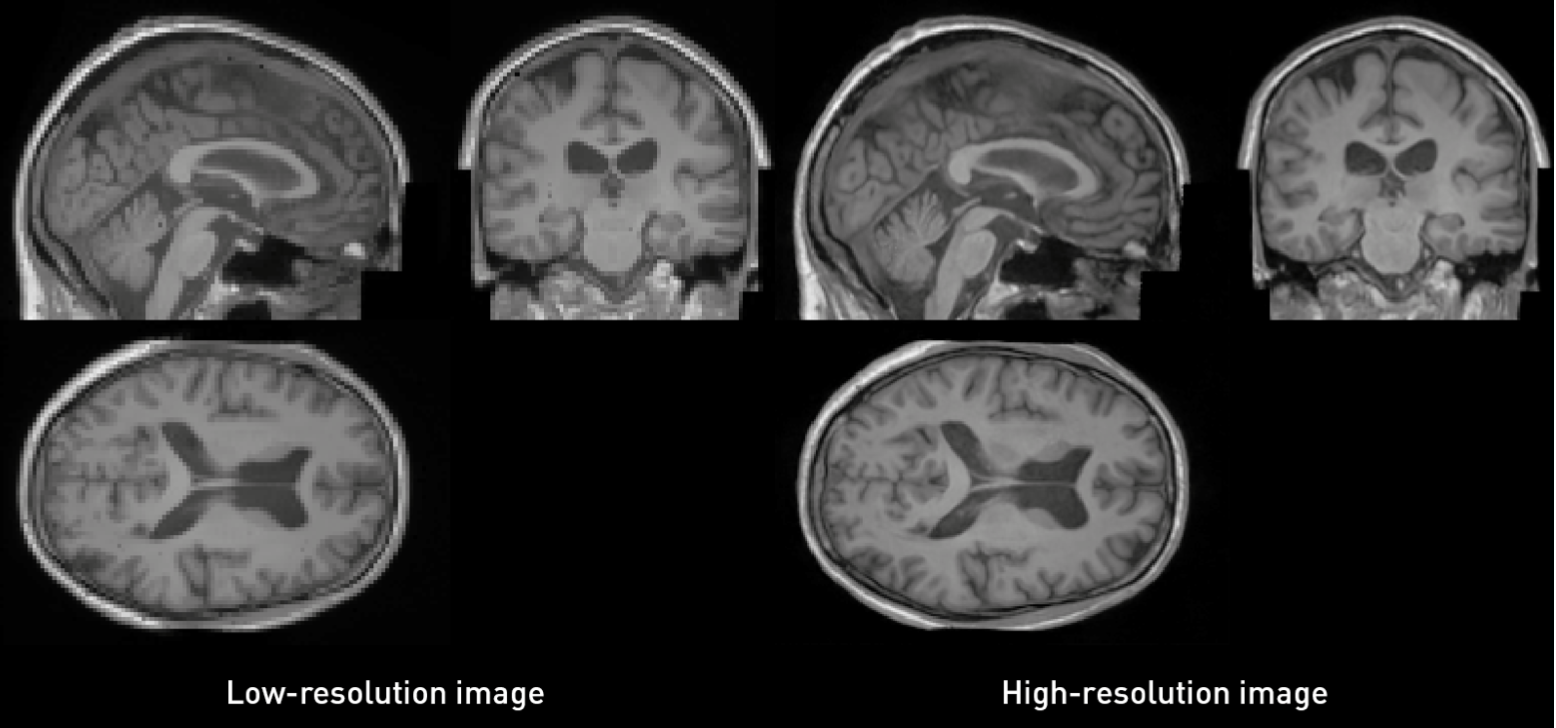
在我们的研究中,我们探索了使用Stable Diffusion 2.0 Upscaler方法的生成模型在超分辨率方面的应用。利用英国生物库的3D数据,我们最初在分辨率为2 mm³(80 × 112 × 80体素)的数据集版本上训练了一个潜在扩散模型(Latent Diffusion Model, LDM)。为了进一步增强结果,我们对32 × 32 × 32体素的数据块训练了另一个LDM。
为了整合超分辨率技术,我们将低分辨率图像连接作为扩散模型的输入,并添加了高斯噪声。扩散模型基于噪声水平进行条件设定,从而实现更好的性能。通过迭代地将超分辨率技术应用于生成图像的图块,我们在图像质量和分辨率方面取得了显著的改进。
我们的研究展示了生成模型在超分辨率任务中的有效性,特别是对于3D模型。低分辨率模型经过对下采样的测试集进行评估,得到了FID=0.0009、多样性的MS-SSIM=0.7818以及自编码器重构的MS-SSIM=0.9970。我们使用conditioned upscaler model模型生成了高分辨率的合成图像,噪声水平为1。将它们与高分辨率测试集进行比较,我们观察到FID为0.0024,MS-SSIM为0.9141,这种级联方法在保持更高保真度和类似多样性方面的表现。这一改进得益于本实验网络中参数数量的增加,同时使用相同的计算资源对其进行训练。另一方面,图像生成需要更多时间,使用单阶段方法生成一张图像大约需要22秒,而使用级联方法则需要约13分钟(使用NVIDIA TITAN RTX和200个时间步的DDIMScheduler)。
这些代码可以去 monai 案例代码里面查看学习。
我也是刚学习GAN,diffusion这块。这些demo以后有时间跑了再跟大家分享。其实我也不是第一次接触GAN,去年做了一个异常检测项目(无监督脑肿瘤分割,已发表在CIBM),就用过GAN了,但是打那之后,我就发4再也不碰GAN了(太!难!训!),但是今年又看了一些cycleGAN,starGAN的论文,又心动了💓。

写这篇文章的目的很单纯,看看哪些大佬在做这块,带带弟弟吧。建个裙裙👗专门讨论生成模型,先加V再拉你哦。
文章持续更新,可以关注微公【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持以实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连