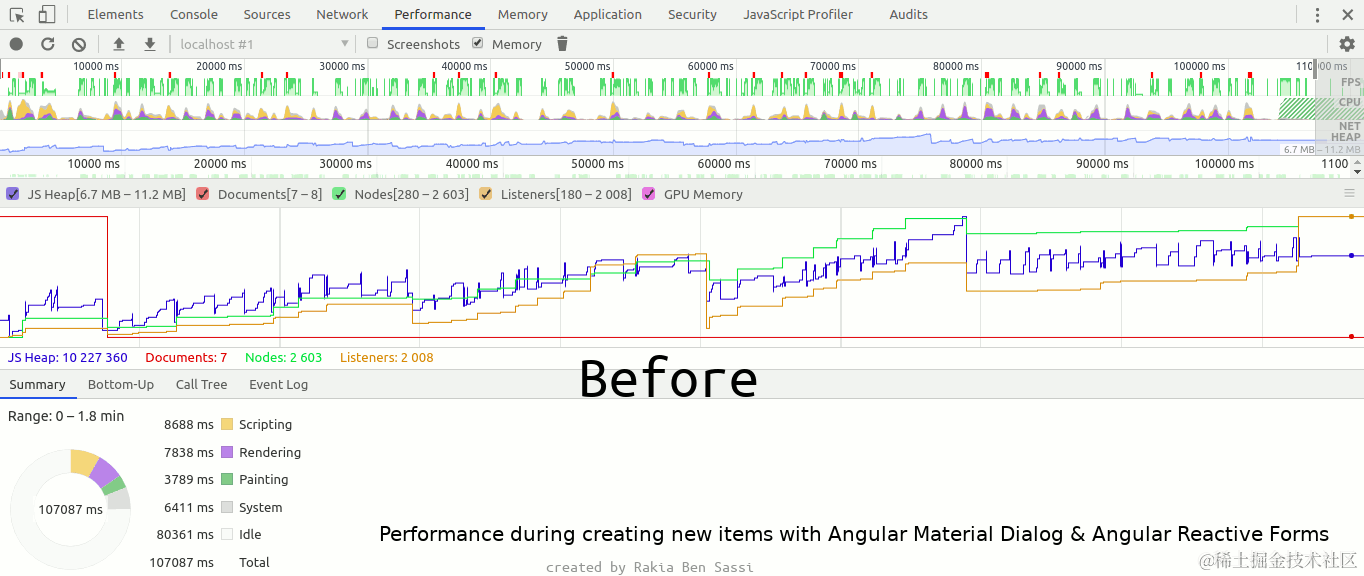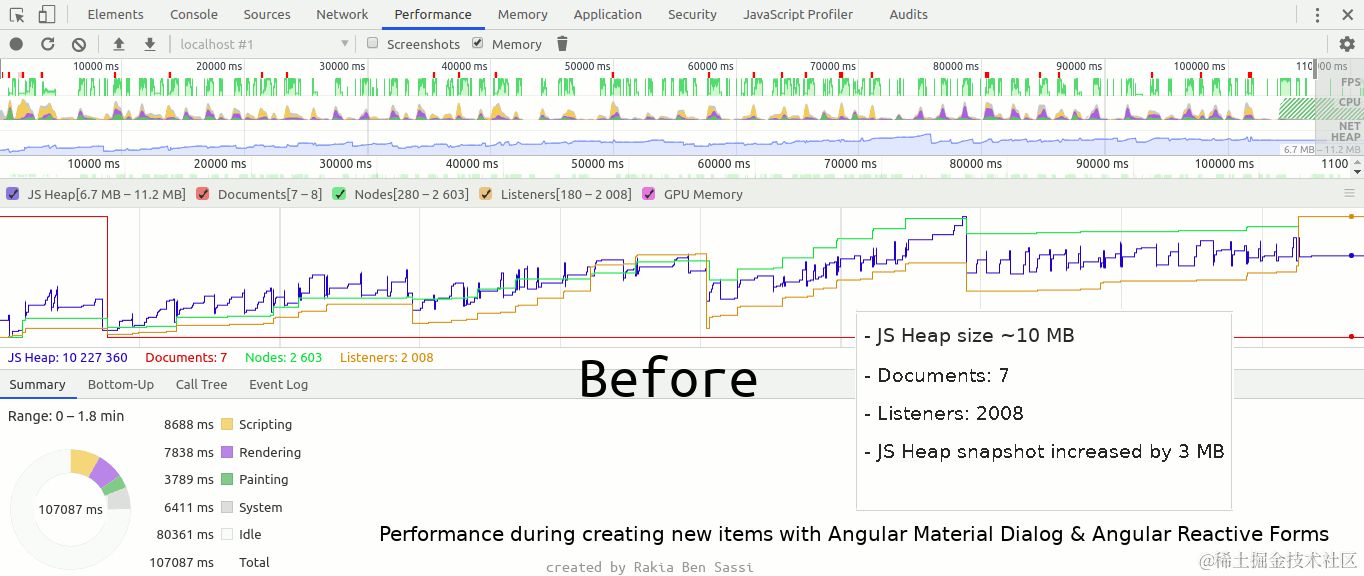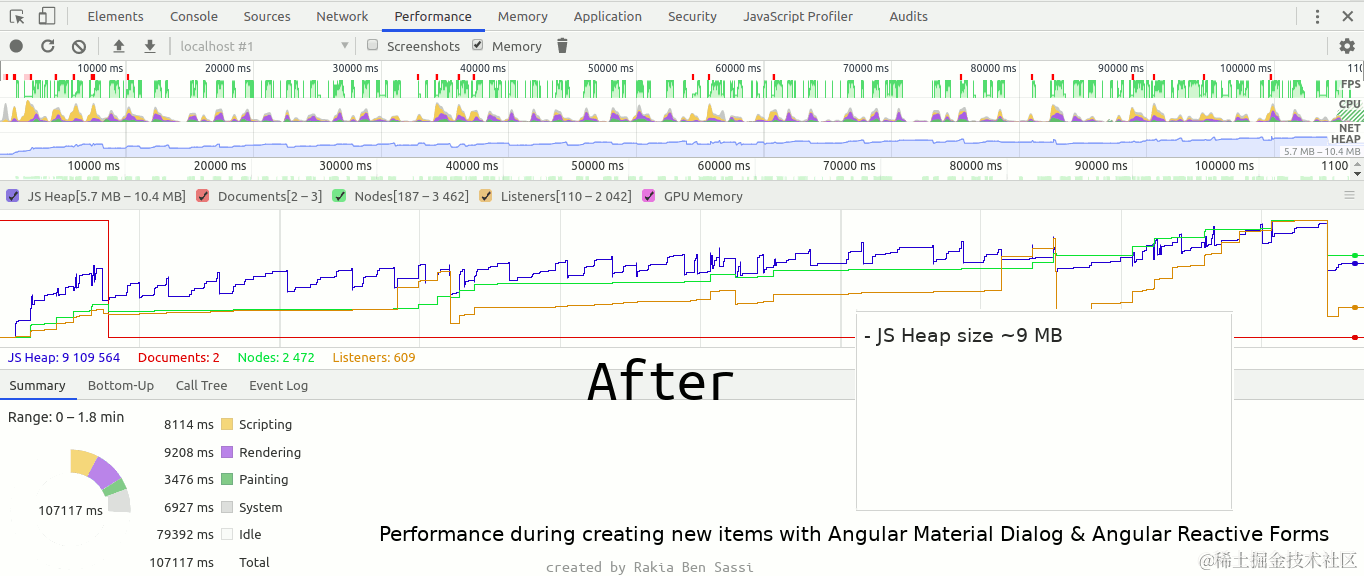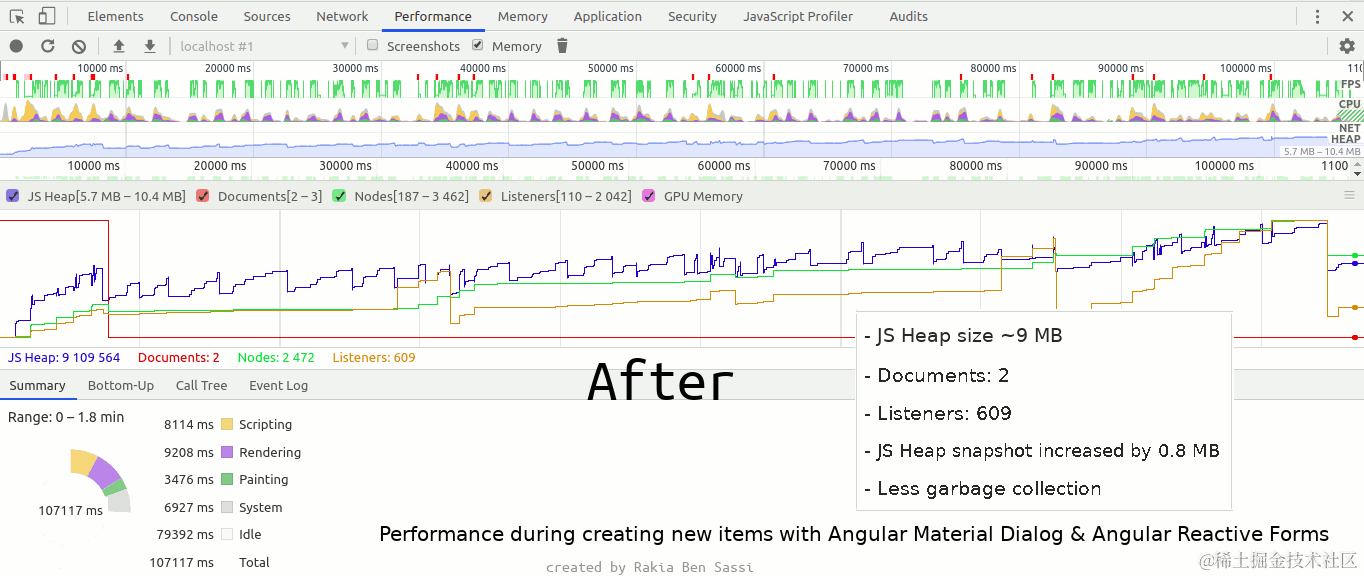
detectron2建议ubuntu进行环境搭建,Windows大概率报错
一 环境搭建
创建虚拟环境
conda create -n detectron2 python=3.8 -y
conda activate detectron2
后面下载源代码建议存到git中再git clone
git clone https://github.com/facebookresearch/detectron2.git
python -m pip install -e detectron2
二 数据集构建
首先有两个文件夹,一个为图像,一个为标注完的voc的xml文件夹
后先划分数据集,创建以下格式
-- imageSets
---Main
----test.txt
----train.txt
----trainval.txt
----val.txt
运行以下代码进行划分
import os
import random
def main():
trainval_percent = 0.2
train_percent = 0.8
xmlfilepath = 'D:\\lunwen\\data\\data\\xml' # xml文件位置
txtsavepath = r'D:\\lunwen\\data\\data\\image' # 图像位置
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
## 以下为对应的txt文件进行修改
ftrainval = open('D:\\lunwen\\data\data\\ImageSets\\Main\\trainval.txt', 'w')
ftest = open('D:\\lunwen\\data\data\\ImageSets\\Main\\test.txt', 'w')
ftrain = open('D:\\lunwen\\data\data\\ImageSets\\Main\\train.txt', 'w')
fval = open('D:\\lunwen\\data\data\\ImageSets\\Main\\val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
if __name__=='__main__':
main();
划分完后对应的txt文件都有数据,后面将进行文件提取,提取出对应的训练/测试数据集及其xml文件
源目录下创建以下文件夹
-train_JPEGImages
-train_annotations
-val_JPEGImages
-val_annotations
import os
import shutil
class CopyXml():
def __init__(self):
# 你的xml格式的annotation的路径
self.xmlpath = r'D:\lunwen\data\data\xml'
self.jpgpath = r'D:\lunwen\data\data\image'
# 你训练集/测试集xml和jpg存放的路径
self.newxmlpath = r'D:\lunwen\data\data\val_annotations'
self.newjpgpath = r'D:\lunwen\data\data\val_JPEGImages'
def startcopy(self):
filelist = os.listdir(self.xmlpath) # file list in this directory
# print(len(filelist))
test_list = loadFileList()
# print(len(test_list))
for f in filelist:
xmldir = os.path.join(self.xmlpath, f)
(shotname, extension) = os.path.splitext(f)
jpgdir = os.path.join(self.jpgpath, shotname+'.jpg')
if str(shotname) in test_list:
# print('success')
shutil.copyfile(str(xmldir), os.path.join(self.newxmlpath, f))
shutil.copyfile(str(jpgdir), os.path.join(self.newjpgpath, shotname+'.jpg'))
# load the list of train/test file list
def loadFileList():
filelist = []
## 选取你上一步弄好的txt文件进行提取
f = open("D:\\lunwen\\data\\data\\ImageSets\\Main\\val.txt", "r")
# f = open("VOC2007/ImageSets/Main/train.txt", "r")
lines = f.readlines()
for line in lines:
# 去掉文件中每行的结尾字符
line = line.strip('\r\n') # to remove the '\n' for test.txt, '\r\n' for tainval.txt
line = str(line)
filelist.append(line)
f.close()
# print(filelist)
return filelist
if __name__ == '__main__':
demo = CopyXml()
demo.startcopy()
成功后对应文件夹下将会有对应txt下的图片及xml
后面便是voc转coco格式了,代码如下
# coding:utf-8
import sys
import os
import json
import xml.etree.ElementTree as ET
START_BOUNDING_BOX_ID = 1
# 注意下面的dict存储的是实际检测的类别,需要根据自己的实际数据进行修改
# 这里以自己的数据集person和hat两个类别为例,如果是VOC数据集那就是20个类别
# 注意类别名称和xml文件中的标注名称一致
PRE_DEFINE_CATEGORIES = {"Normal": 0, "No_wear": 1,"Playing_phone":2,"Smoking":3,"Sleeping":4,
"Playing_phone_smoking":5,"No_wear_playing_phone":6,"No_wear_smoking":7,"No_wear_sleeping":8,
"No_wear_playing_phone_smoking":9}
# 注意按照自己的数据集名称修改编号和名称
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
filename = os.path.splitext(filename)[0]
return (filename)
except:
raise NotImplementedError('Filename %s is supposed to be an integer.' % (filename))
def convert(xml_dir, json_file):
xmlFiles = os.listdir(xml_dir)
json_dict = {"images": [], "type": "instances", "annotations": [],
"categories": []}
categories = PRE_DEFINE_CATEGORIES
bnd_id = START_BOUNDING_BOX_ID
num = 0
for line in xmlFiles:
# print("Processing %s"%(line))
num += 1
if num % 50 == 0:
print("processing ", num, "; file ", line)
xml_f = os.path.join(xml_dir, line)
tree = ET.parse(xml_f)
root = tree.getroot()
# The filename must be a number
filename = line[:-4]
image_id = get_filename_as_int(filename)
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
# image = {'file_name': filename, 'height': height, 'width': width,
# 'id':image_id}
image = {'file_name': (filename + '.jpg'), 'height': height, 'width': width,
'id': image_id}
json_dict['images'].append(image)
# Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category not in categories:
new_id = len(categories)
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(get_and_check(bndbox, 'xmin', 1).text) - 1
ymin = int(get_and_check(bndbox, 'ymin', 1).text) - 1
xmax = int(get_and_check(bndbox, 'xmax', 1).text)
ymax = int(get_and_check(bndbox, 'ymax', 1).text)
assert (xmax > xmin)
assert (ymax > ymin)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
if __name__ == '__main__':
folder_list = ["train_annotations"]
# 注意更改base_dir为本地实际图像和标注文件路径
base_dir = "D:\\lunwen\\data\\data\\"
# 修改为自己的路径
for i in range(1):
folderName = folder_list[i]
xml_dir = base_dir + folderName
json_dir = base_dir + folderName + "/instances_" + folderName + ".json"
print("deal: ", folderName)
print("xml dir: ", xml_dir)
print("json file: ", json_dir)
convert(xml_dir, json_dir)
最后生成

在detectron2下datasets中创建coco文件夹,将对应数据放入
coco
----train2017 ####手动创建
----val2017 ####手动创建
----annotations ####手动创建
--------instances_train2017.json ####脚本生成
--------instances_val2017.json ####脚本生成
三 模型训练
因为pytorch训练自己的数据集,涉及到数据集的注册,元数据集注册和加载,过程比较麻烦,这里我参考官方样本,写了一个脚本trainsample.py放置于model_train文件夹下。
import os
import cv2
import logging
from collections import OrderedDict
import detectron2.utils.comm as comm
from detectron2.utils.visualizer import Visualizer
from detectron2.checkpoint import DetectionCheckpointer
from detectron2.config import get_cfg
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.data.datasets.coco import load_coco_json
from detectron2.engine import DefaultTrainer, default_argument_parser, default_setup, launch
from detectron2.evaluation import COCOEvaluator, verify_results
from detectron2.modeling import GeneralizedRCNNWithTTA
# 数据集路径
DATASET_ROOT = './datasets/coco'
ANN_ROOT = os.path.join(DATASET_ROOT, 'annotations')
TRAIN_PATH = os.path.join(DATASET_ROOT, 'train2017')
VAL_PATH = os.path.join(DATASET_ROOT, 'val2017')
TRAIN_JSON = os.path.join(ANN_ROOT, 'instances_train2017.json')
# VAL_JSON = os.path.join(ANN_ROOT, 'val.json')
VAL_JSON = os.path.join(ANN_ROOT, 'instances_val2017.json')
CLASS_NAMES = ['Normal','No_wear','Playing_phone','Smoking','Sleeping','Playing_phone_smoking','No_wear_playing_phone'
,'No_wear_smoking','No_wear_sleeping','No_wear_playing_phone_smoking']
# 数据集类别元数据
DATASET_CATEGORIES = [
# {"name": "background", "id": 0, "isthing": 1, "color": [220, 20, 60]},
{"name": "Normal", "id": 0, "isthing": 1, "color": [255, 0, 0]}, # 红色
{"name": "No_wear", "id": 1, "isthing": 1, "color": [0, 255, 0]}, # 绿色
{"name": "Playing_phone", "id": 2, "isthing": 1, "color": [0, 0, 255]}, # 蓝色
{"name": "Smoking", "id": 3, "isthing": 1, "color": [255, 255, 0]}, # 黄色
{"name": "Sleeping", "id": 4, "isthing": 1, "color": [255, 0, 255]}, # 紫色
{"name": "Playing_phone_smoking", "id": 5, "isthing": 1, "color": [0, 255, 255]}, # 青色
{"name": "No_wear_playing_phone", "id": 6, "isthing": 1, "color": [128, 0, 128]}, # 深紫色
{"name": "No_wear_smoking", "id": 7, "isthing": 1, "color": [128, 128, 0]}, # 深黄色
{"name": "No_wear_sleeping", "id": 8, "isthing": 1, "color": [0, 128, 128]}, # 深青色
{"name": "No_wear_playing_phone_smoking", "id": 9, "isthing": 1, "color": [128, 128, 128]}
]
# 数据集的子集
PREDEFINED_SPLITS_DATASET = {
"train_2019": (TRAIN_PATH, TRAIN_JSON),
"val_2019": (VAL_PATH, VAL_JSON),
}
def register_dataset():
"""
purpose: register all splits of dataset with PREDEFINED_SPLITS_DATASET
"""
for key, (image_root, json_file) in PREDEFINED_SPLITS_DATASET.items():
register_dataset_instances(name=key,
metadate=get_dataset_instances_meta(),
json_file=json_file,
image_root=image_root)
def get_dataset_instances_meta():
"""
purpose: get metadata of dataset from DATASET_CATEGORIES
return: dict[metadata]
"""
thing_ids = [k["id"] for k in DATASET_CATEGORIES if k["isthing"] == 1]
thing_colors = [k["color"] for k in DATASET_CATEGORIES if k["isthing"] == 1]
# assert len(thing_ids) == 2, len(thing_ids)
thing_dataset_id_to_contiguous_id = {k: i for i, k in enumerate(thing_ids)}
thing_classes = [k["name"] for k in DATASET_CATEGORIES if k["isthing"] == 1]
ret = {
"thing_dataset_id_to_contiguous_id": thing_dataset_id_to_contiguous_id,
"thing_classes": thing_classes,
"thing_colors": thing_colors,
}
return ret
def register_dataset_instances(name, metadate, json_file, image_root):
"""
purpose: register dataset to DatasetCatalog,
register metadata to MetadataCatalog and set attribute
"""
DatasetCatalog.register(name, lambda: load_coco_json(json_file, image_root, name))
MetadataCatalog.get(name).set(json_file=json_file,
image_root=image_root,
evaluator_type="coco",
**metadate)
# 注册数据集和元数据
def plain_register_dataset():
DatasetCatalog.register("train_2019", lambda: load_coco_json(TRAIN_JSON, TRAIN_PATH, "train_2019"))
MetadataCatalog.get("train_2019").set(thing_classes=CLASS_NAMES,
json_file=TRAIN_JSON,
image_root=TRAIN_PATH)
DatasetCatalog.register("val_2019", lambda: load_coco_json(VAL_JSON, VAL_PATH, "val_2019"))
MetadataCatalog.get("val_2019").set(thing_classes=CLASS_NAMES,
json_file=VAL_JSON,
image_root=VAL_PATH)
# 查看数据集标注
def checkout_dataset_annotation(name="train_2019"):
dataset_dicts = load_coco_json(TRAIN_JSON, TRAIN_PATH, name)
for d in dataset_dicts:
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=MetadataCatalog.get(name), scale=1.5)
vis = visualizer.draw_dataset_dict(d)
cv2.imshow('show', vis.get_image()[:, :, ::-1])
cv2.waitKey(0)
register_dataset()
checkout_dataset_annotation()
slowfast源码中采取的模型架构为

在config中找到对应的yaml文件,并在trainsample.py进行设定
后运行
$ python3 model_train/trainsample.py
四 问题
1.缺少cv2模块
pip install opencv-python
2.PIL中缺少模块
`LINEAR` is deprecated and will be removed in Pillow 10 (2023-07-01). Use BILINEAR or Resampling.BILINEAR instead.
版本更新
pip install pillow==9.5.0