一.前言
之前学校让我们写控制台饿了么项目,当时进度没有到数据库,所以用的文本文件txt,来模拟数据库的实现,其实本质上就是一个文件读写,但是简单文件读写并不能包含我们想要的功能,例如条件查询,分页查询等功能,所以我处于好奇,手写了一个简易txt文本数据库框架
二.txt文件准备
我们先准备几个txt文本文件,来看看他的格式
1.shops.txt商家表
Id 商家名称 商家评分 商家地址 商家简介 商家电话
1001 李家包子 5 牧野区102号 非常美味 123212312
1002 杨铭宇黄焖鸡米饭 4 河师大对面 太好吃了 21312311
1003 王星瑶黄焖鸡米饭 4 河师大对面 太好吃了 21312311
1004 赵家粥铺 4 河师大对面 太好吃了 21312311
1005 蜜雪冰城 4 河师大对面 太好吃了 21312311
1006 台湾卤肉饭 4 河师大对面 太好吃了 21312311
1007 地锅鸡 4 河师大对面 太好吃了 21312311
1008 美味小吃 4 河师大对面 太好吃了 21312311
1009 兰州牛肉拉面 4 河师大对面 太好吃了 21312311
1010 肯德基 4 河师大对面 太好吃了 21312311
1011 德克士 4 河师大对面 太好吃了 21312311
1012 麦当劳 4 河师大对面 太好吃了 21312311
1013 杨铭宇黄焖鸡米饭 4 河师大对面 太好吃了 21312311
1014 杨铭宇黄焖鸡米饭 4 河师大对面 太好吃了 21312311
1015 杨铭宇黄焖鸡米饭 4 河师大对面 太好吃了 21312311
1016 杨铭宇黄焖鸡米饭 4 河师大对面 太好吃了 213123112.dishes.txt菜品表
dID shopID 菜品名 介绍 销量 份数 价格
101 1002 蔡徐坤 不好吃 11 10 12.3
102 1001 包子 无 312 12 12.5
103 1001 大包子 无 312 31 12.50
104 1001 小包子 无 312 31 12.50
105 1001 中包子 无 312 31 12.50
106 1001 肉包子 无 312 31 12.50
107 1001 肉包子 无 312 31 12.50
108 1001 肉包子 无 312 31 12.50
109 1001 肉包子 无 312 31 12.50
110 1001 肉包子 无 312 31 12.50
111 1001 肉包子 无 312 31 12.50
112 1002 蔡徐坤 不好吃 112 10 12.3 3.users.txt用户表
ID 用户名 密码 年龄 电话 地址
1001 jjh123 123456 22 1241241234 天堂小区三号楼12层左手户
1002 jfsf 123456 12 1241241234 垃圾小区三号楼12层左手户
681373 zhangsan 123456 123 3123134 地域小区三号楼12层左手户
899803 lisi 12345 18 13123123111 河南省新乡市牧野区河师大对面
663714 lisi123 12345 20 13212331231 河师大对面 4.orders.txt订单表
ID shopId dishId userId name count singlePrice allPrice address desc time
001 1001 102 1001 包子 2 12.50 25.00 天堂小区三号楼12层左手户 尽量快一点 2023-10-06T14:43:42.982695700
622975 1001 102 0 包子 1 12.5 12.5 天堂小区三号楼12层左手户 多加糖 2023-10-06T14:43:42.982695700
708911 1001 102 0 包子 1 12.5 12.5 0 无 2023-10-06T19:45:08.918948500
955207 1001 102 0 包子 2 12.5 25.0 天堂小区三号楼12层左手户 无 2023-10-25T17:59:15.207836800
570959 1001 102 0 包子 10 12.5 125.0 天堂小区三号楼12层左手户 快点送达 2023-10-25T18:26:10.996829600
543529 1001 102 0 包子 2 12.5 25.0 河南省新乡市牧野区河师大对面 多放辣 2023-10-29T11:35:43.542230100
711960 1001 102 0 包子 2 12.5 25.0 河师大对面 多放辣椒 2023-10-29T11:55:11.967471800 我们让他的格式看起来尽可能和MySQL中的差不多,然后我们来实现这些查询功能
三.条件构造器
我们知道mybatisplus中有一个条件构造器,querywrapper,你可以构建各种条件,然后来查询
我们来模仿这个条件构造器,来实现我们自己的构造器
(1)QueryBody
public class QueryBody {
private String key;
private String value;
public QueryBody() {
}
public QueryBody(String key, String value) {
this.key = key;
this.value = value;
}
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
@Override
public String toString() {
return "QueryBody{" +
"key='" + key + '\'' +
", value='" + value + '\'' +
'}';
}
}其实就是一个key和对应的value,然后我们在来构建条件
(2)QueryWrapper
/**
* 查询条件
*/
public class QueryWrapper {
/**
* 参数集合
*/
private List<QueryBody> queryArgs = new ArrayList<>();
public QueryWrapper(){}
/**
* 相等条件
*/
public QueryWrapper eq(String key,String arg){
QueryBody queryBody = new QueryBody(key,arg);
queryArgs.add(queryBody);
return this;
}
public List<QueryBody> getQueryArgs() {
return queryArgs;
}这里为了简单我只实现了等值条件查询eq(),
注意:我们返回的是this,这个对象本身,这样就可以实现链式编程了
四.分页结果类PageBody
/**
* 对分页的封装
*/
public class PageBody {
/**
* 总条数
*/
private int total;
/**
* 当前的页数
*/
private int currntPage;
/**
* 当前每页的尺寸
*/
private int size;
/**
* 总页数
*/
private int pageSize;
/**
* 结果集
*/
private List<Object> results;
public PageBody() {
}
public PageBody(int total, int currntPage, int size, int pageSize, List<Object> results) {
this.total = total;
this.currntPage = currntPage;
this.size = size;
this.pageSize = pageSize;
this.results = results;
}
public int getTotal() {
return total;
}
public void setTotal(int total) {
this.total = total;
//设置总页数
if(size!=0){
this.pageSize = total / size +1;
}
}
public int getCurrntPage() {
return currntPage;
}
public void setCurrntPage(int currntPage) {
this.currntPage = currntPage;
}
public int getSize() {
return size;
}
public void setSize(int size) {
this.size = size;
}
public int getPageSize() {
return pageSize;
}
// public void setPageSize(int pageSize) {
// this.pageSize = pageSize;
// }
public List<Object> getResults() {
return results;
}
public void setResults(List<Object> results) {
this.results = results;
}
@Override
public String toString() {
return "PageBody{" +
"total=" + total +
", currntPage=" + currntPage +
", size=" + size +
", pageSize=" + pageSize +
", results=" + results +
'}';
}
public void setPageSize(int pageSize) {
this.pageSize = pageSize;
}
}
大致上和mybatispllus的page对象差不多
五.FileUtils工具类
该框架其实就是一个工具类,实现了大量的方法
/**
* 文件工具类
* @author JJH
*/
public class FileUtils {
......
}我们把每个方法截取出来一个一个分析
返回属性get方法的工具方法
private static String getXxx(String name){
return "get" + name.substring(0,1).toUpperCase()
+ name.substring(1);
}1.根据文件路径将文件内容返回为集合
/**
* 根据文件路径将文件内容返回为集合
* @param path 文件路径
* @param clazz 要返回对象的类型
* @return 对象集合
*/
public static List<Object> fileToList(String path, Class<?> clazz) {
List<Object> list = new ArrayList<>();
BufferedReader br = null;
try {
br = new BufferedReader(new FileReader(path));
//读掉第一行数据(表头)
br.readLine();
String row;
while ((row=br.readLine()) != null) {
//先把对象创建出来
Object obj = clazz.newInstance();
//获取每一个元素
String[] s = row.split(" ");
//获取属性集合
Field[] fields = clazz.getDeclaredFields();
for (int i=0;i<fields.length;i++) {
//获取属性的类型
Class<?> type = fields[i].getType();
String name = fields[i].getName();
String setXxx="set"+name.substring(0,1).toUpperCase()+name.substring(1);
//获取set方法
Method setMethod = clazz.getDeclaredMethod(setXxx,type);
//把参数类型转换一下
String s1 = s[i];
Object arg = TypeUtils.getInstanceByType(s1, type);
//调用set方法给属性赋值
setMethod.invoke(obj,arg);
}
//装入集合中
list.add(obj);
}
return list;
} catch (IOException | InvocationTargetException | NoSuchMethodException | InstantiationException |
IllegalAccessException e) {
throw new RuntimeException(e);
} finally {
try {
assert br != null;
br.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}主要使用了反射,传入文件的路径和要返回集合中对象的类型,这样就可以根据反射来获取属性然后给属性赋值了
2.将集合保存到文件中去
/**
* 将集合保存到文件中去
* @param list 要保存的结合
* @param path 文件路径
* @param clazz 对象的类型
* @return 是否保存成功
* @param
*/
public static boolean ListToFile(List<Object> list, String path, Class<?> clazz){
BufferedWriter bw = null;
try {
//第二个参数是允许追加写入
bw = new BufferedWriter(new FileWriter(path,true));
StringBuilder sb = new StringBuilder();
for (Object obj : list) {
//先获取对象的属性
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
//将第一个字母转化为大写
String name = field.getName();
String getXxx = "get"+name.substring(0, 1).toUpperCase()
+ name.substring(1);
//调用get方法获取属性值
Method getMethod = clazz.getDeclaredMethod(getXxx);
String str = getMethod.invoke(obj).toString();
sb.append(str).append(" ");
}
sb.append("\n");
}
bw.write(sb.toString());
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
assert bw != null;
bw.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return true;
}3.返回文件的行数
/**
* 返回文件的行数
* @param path 文件路径
* @return 行数
* @throws IOException
*/
public static int getFileRow(String path) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(path));
int sum =0;
while (true){
String str = br.readLine();
if(str!=null){
sum++;
}else {
break;
}
}
return sum-1; //第一行不算
}4.模拟分页查询
/**
* 模拟分页查询
* @param page 页数
* @param size 尺寸
* @param path 文件路径
* @param clazz 返回集合中对象的类型
* @return 对象集合
*/
public static List<Object> pageList(int page,int size,String path, Class<?> clazz) {
/*
计算开始位置,第一行不算,所以是从第二行开始
2-11为第一页了,
12-22为第二页
23-33为第三页
start = 2 + (page-1)*size
当我们最后一页不满的时候,如果要把这一页剩余的部分
查出来,直接查询会报错误,我们需要判断最后一页还有多少
余量,让我们最后一次循环次数等于这个余量,不要让它越界
*/
List<Object> list = new ArrayList<>();
try {
//先获取总的条数,第一行不算
int total = getFileRow(path) - 1;
//计算一下最后一页有多少剩余(求余)
int leastSize = total % size;
BufferedReader br = new BufferedReader(new FileReader(path));
//先让它读到start
int start = 2 + (page - 1) * size;
for (int i = 1; i < start; i++) {
br.readLine();
}
//判断一下循环的次数,看看是满的,还是最后一页剩余的
int num = total - (page-1) * size;
int loop ; //循环次数
if(leastSize==0||num>=10){
loop = size;
}else {
loop = leastSize-1;
}
//然后让它读size次,默认为10
for (int i = 0; i < loop; i++) {
String row = br.readLine();
//先把对象创建出来
Object obj = clazz.newInstance();
//获取每一个元素
String[] s = row.split(" ");
//获取属性集合
Field[] fields = clazz.getDeclaredFields();
for (int j = 0; j < fields.length; j++) {
//获取属性的类型
Class<?> type = fields[j].getType();
String name = fields[j].getName();
String setXxx = "set" + name.substring(0, 1).toUpperCase() + name.substring(1);
//获取set方法
Method setMethod = clazz.getDeclaredMethod(setXxx, type);
//把参数类型转换一下
String s1 = s[j];
Object arg = TypeUtils.getInstanceByType(s1, type);
//调用set方法给属性赋值
setMethod.invoke(obj, arg);
}
//装入集合中
list.add(obj);
}
}catch (Exception e){
e.printStackTrace();
}
return list;
}5. 根据相等条件分页查询
/**
* 根据相等条件分页查询
* @param page 页数
* @param size 尺寸
* @param path 文件路径
* @param clazz 集合对象类型
* @param wrapper 条件构造器
* @return 对象集合
*/
public static List<Object> pageQueryList(int page, int size, String path, Class<?> clazz, QueryWrapper wrapper){
//把条件构造器中的条件拿出来
List<QueryBody> querybodys = wrapper.getQueryArgs();
List<Object> list = new ArrayList<>();
List<Object> resList = new ArrayList<>();
try {
BufferedReader br = new BufferedReader(new FileReader(path));
br.readLine(); // 先把第一行读了
int rows = getFileRow(path);
for(int i=0;i<rows-1;i++){
String str = br.readLine();
//先把对象创建出来
Object obj = clazz.newInstance();
//获取每一个元素
String[] s = str.split(" ");
//获取属性集合
Field[] fields = clazz.getDeclaredFields();
for (int j = 0; j < fields.length; j++) {
//获取属性的类型
Class<?> type = fields[j].getType();
String name = fields[j].getName();
String setXxx = "set" + name.substring(0, 1).toUpperCase() + name.substring(1);
//获取set方法
Method setMethod = clazz.getDeclaredMethod(setXxx, type);
//把参数类型转换一下
String s1 = s[j];
Object arg = TypeUtils.getInstanceByType(s1, type);
//调用set方法给属性赋值
setMethod.invoke(obj, arg);
}
//装入集合中
list.add(obj);
}
}catch (Exception e){
e.printStackTrace();
}
// list.forEach(System.out::println);
//以上是拿到了所有的元素,下面我们来对元素先进行一个筛选
try {
for (QueryBody querybody : querybodys) {
//对每个条件进行过滤
String key = querybody.getKey();
String value = querybody.getValue();
//每次先清空
resList.removeAll(resList);
for (Object obj:list) {
String getXxx = getXxx(key);
//调用get方法来获取属性值
Method getMethod = clazz.getDeclaredMethod(getXxx);
String res = getMethod.invoke(obj).toString();
//比对条件是否相等
if(res.equals(value)){
resList.add(obj);
}
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
// resList.forEach(System.out::println);
// 如果不传page和size,默认就全查
if(Objects.isNull(page)&&Objects.isNull(size)){
return resList;
}
ArrayList<Object> pageList = new ArrayList<>();
//分页查询
/**
* 0-9 第一页
* 10-19 第二页
* 20-21 第三页
* 还是得先判断一下最后一页的剩余问题
*
*/
int start = (page-1)*size;
for(int i = 0;i<resList.size();i++){
if(i==start){
if(resList.size()<=size){
size = resList.size();
}else {
//多于一页,算一下余量
int mod = resList.size()%size;
if(mod>0){
//计算当前页面
int currentPage = start/size+1 ;
//算一下之前的总数据量是否
if(mod+(currentPage*size-1) < currentPage*size){
size = mod;
}
}
}
for(int j = start; j < (start+size); j++){
pageList.add(resList.get(j));
//pageList.forEach(System.out::println);
}
break;
}
}
// pageList.forEach(System.out::println);
return pageList;
}6.分页查询的默认全查形式,方法重载
/**
* 分页查询的默认全查形式,方法重载
* @param path 文件路径
* @param clazz 对象类型
* @param wrapper 条件构造器
* @return 对象集合
*/
public static List<Object> pageQueryList(String path, Class<?> clazz, QueryWrapper wrapper){
//把条件构造器中的条件拿出来
List<QueryBody> querybodys = wrapper.getQueryArgs();
List<Object> list = new ArrayList<>();
List<Object> resList = new ArrayList<>();
try {
BufferedReader br = new BufferedReader(new FileReader(path));
br.readLine(); // 先把第一行读了
String row;
while ((row=br.readLine())!=null){
//先把对象创建出来
Object obj = clazz.newInstance();
//获取每一个元素
String[] s = row.split(" ");
//获取属性集合
Field[] fields = clazz.getDeclaredFields();
for (int j = 0; j < fields.length; j++) {
//获取属性的类型
Class<?> type = fields[j].getType();
String name = fields[j].getName();
String setXxx = "set" + name.substring(0, 1).toUpperCase() + name.substring(1);
//获取set方法
Method setMethod = clazz.getDeclaredMethod(setXxx, type);
//把参数类型转换一下
String s1 = s[j];
Object arg = TypeUtils.getInstanceByType(s1, type);
//调用set方法给属性赋值
setMethod.invoke(obj, arg);
}
//装入集合中
list.add(obj);
}
}catch (Exception e){
e.printStackTrace();
}
//以上是拿到了所有的元素,下面我们来对元素先进行一个筛选
try {
for (QueryBody querybody : querybodys) {
//对每个条件进行过滤
String key = querybody.getKey();
String value = querybody.getValue();
// System.out.println(key+":"+value);
//每次先清空
resList.removeAll(resList);
for (Object obj:list) {
String getXxx = getXxx(key);
//调用get方法来获取属性值
Method getMethod = clazz.getDeclaredMethod(getXxx);
Object res = getMethod.invoke(obj);
//比对条件是否相等
if(res.toString().equals(value)){
resList.add(obj);
}
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
return resList;
}7.根据主键修改改行数据
/**
* 根据主键修改改行数据
* @param
* @param
*/
public static boolean updateOne(String path, Object obj) {
Class<?> aClass = obj.getClass();
StringBuilder updateRow = new StringBuilder();
Method getMethod = null;
String str = null;
String id = null;
Field[] fields = aClass.getDeclaredFields();
for (int i = 0;i<fields.length;i++) {
try {
getMethod = aClass.getDeclaredMethod(getXxx(fields[i].getName()));
str = getMethod.invoke(obj).toString();
updateRow.append(str).append(" ");
} catch (Exception e) {
throw new RuntimeException(e);
}
if(i==0){
id = str;
}
}
StringBuilder sb = new StringBuilder();
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(Files.newInputStream(Paths.get(path))));
//先把表头添加上
String head = reader.readLine();
sb.append(head).append("\r\n");
int rows = getFileRow(path);
for (int i = 0; i <rows ; i++) {
String row = reader.readLine();
String Id = row.split(" ")[0];
if(id.equals(Id)) {
sb.append(updateRow).append("\r\n");
}else {
sb.append(row).append("\r\n");
}
}
//再把文件写回去
BufferedWriter writer = new BufferedWriter(new FileWriter(path));
writer.write(sb.toString());
reader.close();
writer.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
return true;
}六.测试数据
我们来测试一下查询效果

可以看到,这时默认的全部查询方式,
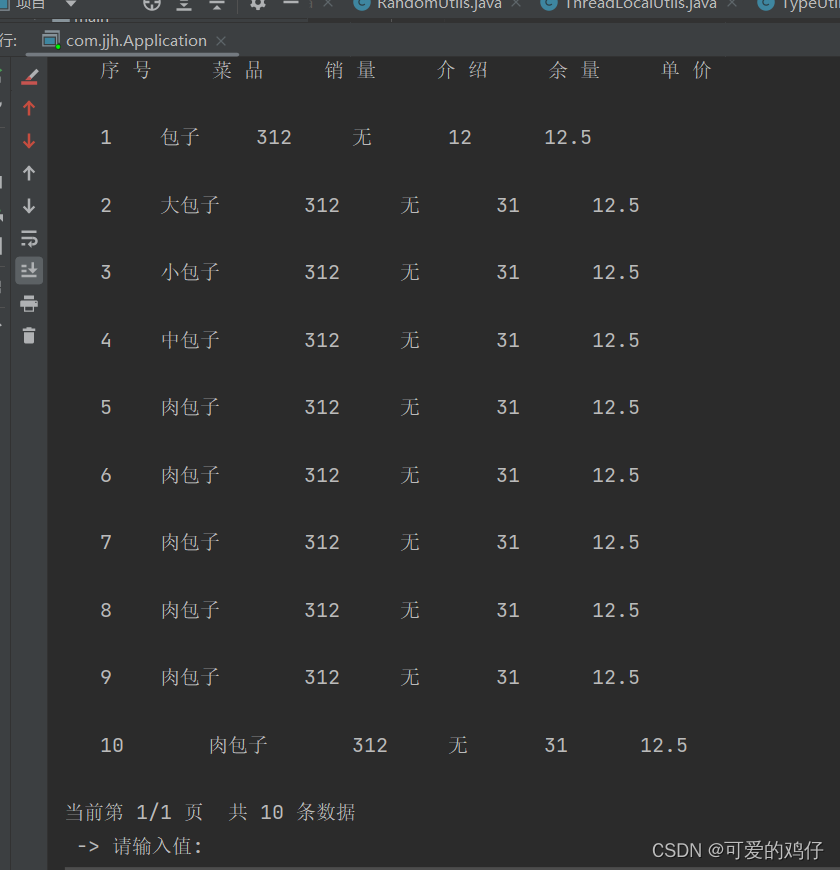
可以看到,这是等值条件查询,查询到了包子店铺的菜品,
综上所述,我们实现了自己的txt文本数据库简易框架,当然还有很多功能不完善,下次希望可以模拟sql语句来实现查询,或者模拟一下事务的实现