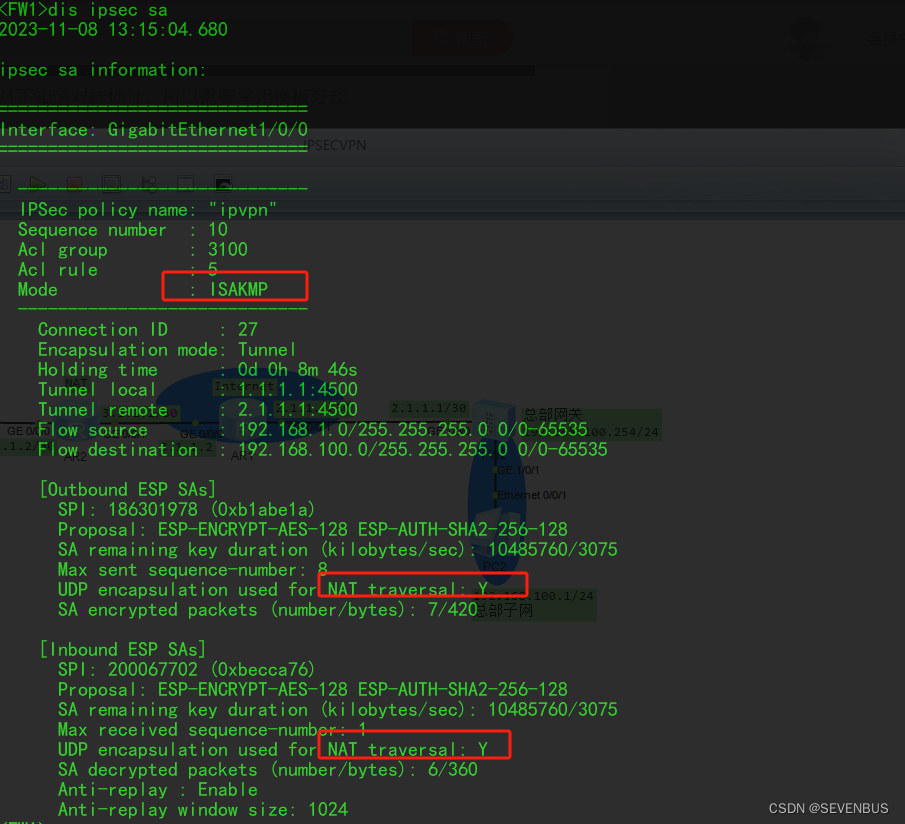
- 我们把LLM的基本训练步骤分为两步,预训练和对齐;预训练我们非常熟悉,是bert-finetuning时代的基本原理,只不过LLM一般遵循自回归的逻辑,因此使用GPT模型的预训练方式:CLM(具备因果关系的MLM);预训练帮助我们在海量语料下,通过自监督的方式确定了模型的基本参数,使得模型存储了大量世界知识和逻辑。
- 而为了使预训练模型能够完成chat功能,我们还有第二步:对齐,这也是LLM“显示出智能”的重要一环,对齐又可以分为三步,分别是:SFT,RM和RLHF。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1185603.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!