原文链接:https://arxiv.org/pdf/2310.08370.pdf
1. 引言
过去的3D场景理解预训练方法多采用2D图像领域中的想法,可大致分为基于对比的方法和基于MAE的方法。
基于对比的方法通过对比损失,在特征空间中将相似的3D点拉进而将不相似的点分开;但正负样本选择的敏感性和增加的延迟使其应用受限。掩膜自编码(MAE)则因为点云数据的稀疏性和不规则性而遇到挑战。
本文提出一种新的3D表达学习预训练方案UniPAD,避免正负样本的分配并隐式地提供连续监督信号以学习3D几何结构。整体框架如下图所示,以掩蔽点云或图像为输入,目标是通过3D可微神经渲染,在2D深度图像上重建丢失的几何。对于掩蔽的激光雷达点云,首先使用3D编码器提取层次特征,并进行体素化。然后使用可微体渲染方法重建完整的几何表达。多视图图像特征则通过LSS的方法转化为3D体素。为保持高效,本文提出存储高效的射线采样策略,以大幅减少训练代价和存储消耗。这一采样策略同样能提高性能。
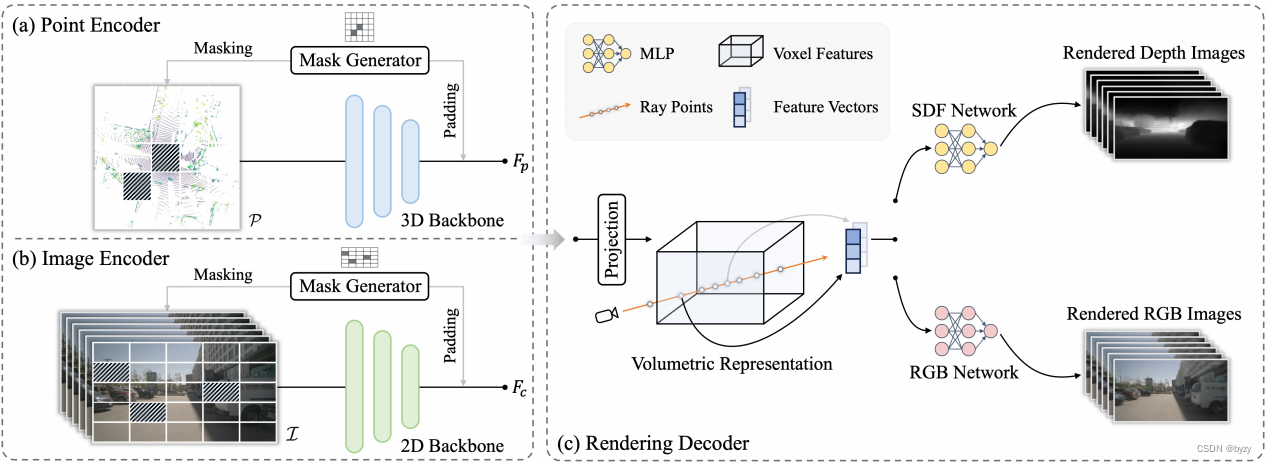
3. 方法
如上图所示,本文的模型分为两部分:特定模态的编码器和体渲染解码器。编码器与MAE类似,对输入使用掩蔽策略以学习有效表达。解码器则使用现成的神经渲染方法,并引入存储高效的射线采样策略。通过最小化渲染的2D投影与输入之间的差异,模型可学习输入数据几何或外观特性的连续表达。
3.1 特定模态的编码器
首先将输入的激光雷达点云 P P P或多视图图像 I I I通过掩膜生成器进行掩蔽,并将可见区域输入到模态特定编码器中。对于点云,使用如VoxelNet的编码器得到层次特征 F p F_p Fp;对于图像,则使用CNN结构的编码器得到特征 F c F_c Fc。此外,还使用FPN聚合多尺度特征。
掩膜生成器:作为数据增广的手段,掩膜生成器选择性地丢弃输入的一部分。本文使用逐块掩蔽来隐藏输入点云或图像的某些区域。首先根据输出的特征图大小生成掩膜,并上采样到输入的原始大小。对于点云,直接丢弃掩蔽区域内的信息;对于图像,使用稀疏卷积替代传统卷积,并只在可见区域计算。编码器的输出会在掩蔽区域进行零填充,并与可视特征组合得到密集特征图。
3.2 统一的3D体素表达
为保证预训练模型对各模态都适用,需要找到合适的统一表达。本文选择3D体素空间以保留尽可能多的信息。对于图像,首先在激光雷达坐标系下定义体素坐标
X
p
∈
R
X
×
Y
×
Z
×
3
X_p\in\mathbb{R}^{X\times Y\times Z\times 3}
Xp∈RX×Y×Z×3,然后将
X
p
X_p
Xp投影到多视图图像上,索引得到对应的2D特征。该过程可表示为:
V
=
G
(
T
c
2
i
T
l
2
c
X
p
,
F
c
)
V=G(T_{c2i}T_{l2c}X_p,F_c)
V=G(Tc2iTl2cXp,Fc)
其中
V
V
V为得到的体素特征,
T
c
2
i
T_{c2i}
Tc2i与
T
l
2
c
T_{l2c}
Tl2c分别为相机坐标系到图像坐标系以及激光雷达坐标系到相机坐标系的变换矩阵,
G
G
G表示双线性插值。对于3D点云,保留编码器输出的体素高度信息。最后使用包含
L
L
L层卷积的投影层增强体素表达。
3.3 神经渲染解码器
可微渲染:使用神经渲染将几何或纹理信息整合到学到的体素特征中。首先从图像或点云中采样射线 { r i } i = 1 K \{r_i\}_{i=1}^K {ri}i=1K,并为每一射线渲染深度或色彩。
本文将场景表示为有符号距离函数(SDF)场,以表达高质量的几何细节。SDF代表了每个查询点到最近表面的距离,从而隐式地描绘了3D几何。给定相机射线
r
i
r_i
ri,相机原点为
o
o
o,视线方向为
d
i
d_i
di,沿射线采样
D
D
D个点
{
p
j
=
o
+
t
j
d
i
∣
j
=
1
,
⋯
,
D
,
t
j
<
t
j
+
1
}
\{p_j=o+t_jd_i|j=1,\cdots,D,t_j<t_{j+1}\}
{pj=o+tjdi∣j=1,⋯,D,tj<tj+1},其中
t
j
t_j
tj为沿射线的深度。对每个采样点
p
j
p_j
pj,特征嵌入
f
j
f_j
fj可通过三线性插值从体素特征中得到。然后通过浅层MLP
ϕ
S
D
F
\phi_{SDF}
ϕSDF得到SDF值
s
i
=
ϕ
S
D
F
(
p
j
,
f
j
)
s_i=\phi_{SDF}(p_j,f_j)
si=ϕSDF(pj,fj)。对于颜色值,使用表面法线
n
j
n_j
nj(即SDF值在
p
j
p_j
pj处的梯度)与
ϕ
S
D
F
\phi_{SDF}
ϕSDF输出的几何特征向量
h
i
h_i
hi确定。则颜色表达可记为
c
j
=
ϕ
R
G
B
(
p
j
,
f
j
,
d
j
,
n
j
,
h
j
)
c_j=\phi_{RGB}(p_j,f_j,d_j,n_j,h_j)
cj=ϕRGB(pj,fj,dj,nj,hj),其中
ϕ
R
G
B
\phi_{RGB}
ϕRGB为MLP。最后,沿射线整合各点的预测颜色和采样深度:
Y
^
i
R
G
B
=
∑
j
=
1
D
w
j
c
j
,
Y
^
i
d
e
p
t
h
=
∑
j
=
1
D
w
j
t
j
\hat{Y}_i^{RGB}=\sum_{j=1}^Dw_jc_j,\hat{Y}_i^{depth}=\sum_{j=1}^Dw_jt_j
Y^iRGB=j=1∑Dwjcj,Y^idepth=j=1∑Dwjtj
其中
w
j
w_j
wj为遮挡感知的权重,由
w
j
=
T
j
α
j
w_j=T_j\alpha_j
wj=Tjαj给出,其中
T
j
=
∏
k
=
1
j
−
1
(
1
−
α
k
)
T_j=\prod_{k=1}^{j-1}(1-\alpha_k)
Tj=∏k=1j−1(1−αk)为累积透明度,
α
j
\alpha_j
αj为不透明度:
α
j
=
max
(
σ
s
(
s
j
)
−
σ
s
(
s
j
+
1
)
σ
s
(
s
j
)
,
0
)
\alpha_j=\max(\frac{\sigma_s(s_j)-\sigma_s(s_{j+1})}{\sigma_s(s_j)},0)
αj=max(σs(sj)σs(sj)−σs(sj+1),0)
其中
σ
s
(
x
)
=
(
1
+
e
−
s
x
)
−
1
\sigma_s(x)=(1+e^{-sx})^{-1}
σs(x)=(1+e−sx)−1为由参数
s
s
s调制的Sigmoid函数。
存储友好的射线采样:为 S S S个多视图图像渲染 S × H × W S\times H\times W S×H×W个射线对算力有挑战。
本文提出3种存储友好的射线采样策略来仅渲染上述射线的子集:膨胀采样、随机采样和深度感知采样。膨胀采样以间距 I I I遍历图像,采样的射线数量为 S × H × W I 2 \frac{S\times H\times W}{I^2} I2S×H×W;随机采样从所有像素中随机选择 K K K个射线。但膨胀采样和随机采样都没有考虑3D环境中固有的先验信息:例如路面上的实例比背景天空提供更多的信息。因此,深度感知采样根据激光雷达信息采样射线,将激光雷达点投影到图像上,获取深度小于阈值 τ \tau τ的像素集合,然后从该集合中采样射线。通过关注场景内最相关的区域,不仅减少了计算,还能提高性能。
预训练损失:总体损失包含色彩损失和深度损失:
L
=
λ
R
G
B
K
∑
i
=
1
K
∣
Y
^
i
R
G
B
−
Y
i
R
G
B
∣
+
λ
d
e
p
t
h
K
+
∑
i
=
1
K
+
∣
Y
^
i
d
e
p
t
h
−
Y
i
d
e
p
t
h
∣
L=\frac{\lambda_{RGB}}{K}\sum_{i=1}^K|\hat{Y}^{RGB}_i-Y^{RGB}_i|+\frac{\lambda_{depth}}{K^+}\sum_{i=1}^{K+}|\hat{Y}^{depth}_i-Y^{depth}_i|
L=KλRGBi=1∑K∣Y^iRGB−YiRGB∣+K+λdepthi=1∑K+∣Y^idepth−Yidepth∣
其中
K
+
K^+
K+为可获取深度的射线集合。
4. 实验
4.3 与SotA方法比较
3D目标检测:与UVTR相比,经过UniPAD预训练的模型在各模态下均能有更高的性能。
3D语义分割:与SpUNet相比,经过UniPAD预训练的模型在激光雷达点云分割任务中有更高的性能。
4.4 与预训练方法比较
基于图像的预训练:目前基于图像的预训练方法包括(1)深度估计器(预训练深度估计网络);(2)检测器(预训练2D检测的图像主干);(3)3D检测器(预训练3D检测的图像主干)。与上述有监督预训练方案相比,UniPAD中基于渲染的任务有更强的知识迁移能力。
基于点的预训练:目前基于点的自监督预训练方法包括:(1)基于占用的(预训练占用预测的点云主干);(2)基于MAE的(使用chamfer距离重建掩蔽点云);(3)基于对比的(使用点与像素的对比将2D知识整合到3D中)。实验表明UniPAD能有最高的NDS性能,但mAP比(3)略低(尽管如此,UniPAD无需复杂的正负样本分配)。
4.5 不同主干的有效性
不同视图变换:使用不同的视图变换器预训练,均能带来性能提升,表明本文方法的泛化能力。
不同模态:不同模态下的UVTR使用UniPAD预训练均有性能提升。
扩大主干网络:使用不同大小的主干网络预训练,性能均有一致的提升。
4.6 消融研究
掩蔽比例:本文使用的图像掩蔽比例比过去基于MAE的方法更低,这是因为从体素中渲染图像比图像到图像的重建更有挑战性。
渲染设计:SDF与RGB解码器的深度越大,性能越好;这是因为深网络能充分整合几何或外表特征。但宽度对性能的影响很小。使用精心设计的渲染方法(射线点采样的方法与积累的方式)也能促进渲染。
存储友好的射线采样:与膨胀采样和随机采样相比,深度感知采样能有略高的性能。这是因为该方法关注场景中的物体,对下游任务有帮助。
特征投影:在预训练或微调时移除特征投影层、或是在预训练与微调时使用相同的投影层参数,均会导致性能下降。这是因为渲染和识别任务之间存在差异,投影层可以使提取的特征倾向于对于的任务。
预训练组件:将预训练的FPN与视图变换权重替换为随机初始化权重会导致性能略微下降。