文章目录
- Web应用简介
- 什么是Web框架?
- 什么是Web?
- 应用程序的两种模式
- Web应用程序的优缺点
- 手写Web框架
- HTTP协议的相关知识
- 1.四大特性
- 2.请求数据格式
- 3.响应数据格式
- 手写框架
- 使用wsgiref模块
- 基于wsgiref模块搭建Web框架(最初版)
- 基于wsgiref模块搭建Web框架(第二版)
- 基于wsgiref模块搭建Web框架(最终版)
- Python主流Web框架
- 1.Django:重量级框架
- 2.Flask:轻量级框架
- 3.Tornado:异步非阻塞框架
- 4.fastapi框架
前言:
我们之前学习了数据库、前端、Python基础等三大部分,但是他们三块的内容没有串在一起,也就没办法开发出一个完成的web项目出来,因此,我们通过Django框架把这三者融合在一起,以后我们就可以很方便的开发出各种各样的项目。
在了解Django之前,我们可以先了解web框架,了解它的好处是什么呢?在一步步搭建它的过程中,我们会逐步明白到Django是如何写的,以及如果处理页面接收与反馈给页面数据的。当然 这样讲可能有点抽象,那么我们先来了解一下吧!
Web应用简介
什么是Web框架?
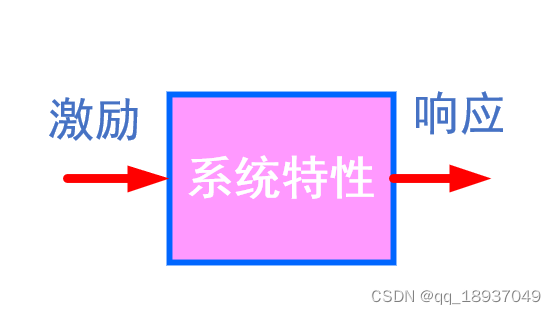
Web框架是用来进行Web应用开发的一个软件架构,主要用于动态网络开发。开发者在基于Web框架实现自己的业务逻辑。Web框架实现了很多功能,为实现业务逻辑提供了一套通用方法。
框架的意思就是别人提前写好的框架(就是一堆目录和文件),我们只需要按照人家的要求在固定的位置写代码即可
什么是Web?
Web应用程序时一种可以通过Web访问的应用程序,用户只需要有浏览器即可,无需再安装其他软件
应用程序的两种模式
应用程序有两种模式C/S、B/S两种模式
C/S模式是客户端----->服务端程序,也就是说这类程序一般独立运行。
B/S模式是浏览器端----->服务端应用程序,这类应用程序一般借助IE等浏览器来运行。
而Web应用程序一般是B/S模式
Web应用程序的优缺点
优点:
- 只需要一个适用的浏览器即可,无需安装其他应用软件
- 节省用户的硬盘空间资源
- 它们无需更新,因为所有新的特性都在服务端上执行,从而自动传达到客户端
- 跨平台使用。例如:Windows、Mac、Linux等。
缺点:
- 严重依赖服务端的正常运行,一旦服务端出现问题、宕机,会直接影响客户端正常访问
手写Web框架
Web应用程序时B/S架构的,所以我们需要自己写一个服务端,这里的Web服务端是我们使用socket套接字来实现的,以浏览器作为客户端,朝我们搭建的服务端发送数据,已经我们的服务端给浏览器返回数据的过程。
因为这里是用浏览器做客户端,就涉及到了HTTP协议的相关知识
HTTP协议的相关知识
1.四大特性
- 基于请求和响应
- 基于TCP协议之上的应用层协议
- 无状态
- 短连接
2.请求数据格式
- 请求首行(请求方式、协议、版本号、路径)
- 请求头
- 换行(\r\n\r\n)
- 请求体(Get请求方式是没有请求体的,Post请求方式才有请求体)
3.响应数据格式
- 响应首行(响应状态码)
- 响应头
- 换行(\r\n\r\n)
- 响应体(一般情况下就是浏览器要展示给用户看的数据)
具体HTTP协议的相关知识可以去看我这篇博客里面的“HTTP超文本传输协议节点处即可”HTTP协议相关知识
手写框架
'''手写框架'''
import socket # 导入socket套接字模块
# 生成一个socket对象,并设置协议和类型(括号内不写默认是基于TCP协议)
server = socket.socket(family=socket.AF_INET,type=socket.SOCK_STREAM)
'我这里是补全的TCP协议的,也可以选择UDP'
# 绑定ip和端口号给服务端
server.bind(('127.0.0.1', 8000))
# 建立监听 半连接池
server.listen(5)
while True:
# 等待客户端的连接
sock, addr = server.accept()
# 接收客户端发送的请求数据
data = sock.recv(1024) # 单次最大字节数 接收的是bytes类型
# print(data.decode('utf-8')) # 解码接收的请求数据
'''
当我们在浏览器输入127.0.0.1:8000/index时
通过打印请求数据我们看到了请求方式
(Get 朝服务端索要数据 Post 朝服务端提交数据)
GET /index HTTP/1.1
Host: 127.0.0.1:8000
这样我们可以通过切分字符串并以索引的方式获取到想要的数据
'''
# 从请求数据中看到可以直接按照空格切分字符串
str_data = data.decode('utf-8').split(' ')[1]
# print(str_data)
# 回应客户端请求数据
'''因为是浏览器客户端所以需要遵循HTTP协议的需求'''
# TCP流式传输协议,短时间内可以分多次接收多个数据
sock.send(b'HTTP/1.1 200 ok \r\n\r\n')
'''
然后我们需要根据网址后缀的不同请求不同的内容
如:127.0.0.1:8000/index等
所以我们得回到接收的请求数据位置处筛选出我们想要的数据
'''
'''然后通过判断来进行根据后缀回应不同的数据'''
if str_data == '/index':
sock.send(b'from index')
elif str_data == '/home':
sock.send(b'from home')
elif str_data == '/html':
with open(r'../Myhtml.html', 'rb') as f: # rb模式 二进制
sock.send(f.read())
else:
sock.send(b'404 Error')
但是这种Web框架的代码缺陷有点多
- socket代码重复编写
- 针对请求数据格式的处理复杂且重复
- 针对不同网址后缀的匹配逻辑过于简单
- 没有解决高并发问题
那么该怎么优化以上存在的问题呢?
使用wsgiref模块
基于wsgiref模块搭建Web框架(最初版)
wsgiref模块是内置模块,很多Web框架底层使用的模块
来看看使用wsgiref模块怎么做吧
from wsgiref.simple_server import make_server # 导入模块
def run(request,respose):
"""
:param request: 客户端的请求数据
:param respose: 给客户端进行响应的数据
:return: 返回给客户端的真实数据
"""
respose('200 ok', []) # 返回响应状态给客户端
print(request) # 这个参数是wsgiref帮助我们封装的一个大字典,字典中携带的客户端的请求数据
return [b'hello world!'] # 返回给客户单的真实数据
if __name__ == '__main__':
'''
我们可以通过查看源码的方式看到make_server中需要的几个参数
host, port, app, server_class=WSGIServer, handler_class=WSGIRequestHandler
'''
server = make_server('127.0.0.1', 8000, app=run) # 分别代表:ip地址、端口号、由那个程序来处理请求
'''
1.它会实时监听127.0.0.1:8000这个地址,只要由客户端来连接这个地址,它就可以做出响应
2.app=run:它的意思是,当由客户端请求过来的时候,会把该请求交给run函数来处理,但是这个地方不要加括号
3.django中这里写的是函数名,当请求来的时候,会调用这个函数,函数叫括号
4.如果是flask框架,当请求来的时候,也会把请求交给这个对象处理,只不过变成了对象()---实例化----调用__call__方法执行
(__call__方法里面写的就是flask框架的源码入口位置)
'''
server.serve_forever() # 将服务器持续开启

而用户请求的数据:打印出来的是一个字典的形式的

基于wsgiref模块搭建Web框架(第二版)
那么此时,我们可以在浏览器发送请求时,稍作变动
比如:让用户访问127.0.0.1:8000/index,那么页面要出现index后缀我们该怎么实现。
首先服务端要获取url后面的/index,才能进行处理。
from wsgiref.simple_server import make_server # 导入模块
def run(request,respose):
"""
:param request: 客户端的请求数据
:param respose: 给客户端进行响应的数据
:return: 返回给客户端的真实数据
"""
respose('200 ok', []) # 返回响应状态给客户端
print(request) # 这个参数是wsgiref帮助我们封装的一个大字典,字典中携带的客户端的请求数据
# 获取大字典中的ip和端口号后面的后缀
current_path = request.get('PATH_INFO')
'进行判断请求数据的后缀回应不同的数据'
if current_path == '/index':
return [b'from index']
if current_path == '/home':
with open(r'Myhtml.html','rb')as f:
return f.read()
else:
return [b'404 Error']
# return [b'hello world!'] # 返回给客户单的真实数据
if __name__ == '__main__':
server = make_server('127.0.0.1', 8000, app=run) # 分别代表:ip地址、端口号、由那个程序来处理请求
server.serve_forever() # 将服务器持续开启

从这里就已经实现了当时使用基于TCP协议的socket套接字的服务端的功能,并且优化掉了代码重复写、请求数据格式的处理的缺陷。但是还没有解决针对不同网址后缀的匹配逻辑过于简单问题。并且按照上面的思路是不是一个页面堆满了if语句,所以我们需要将用户访问、已经处理响应用户的步骤进行拆分。那么我们可以通过代码的封装优化。
基于wsgiref模块搭建Web框架(最终版)
代码的封装优化
解决问题:
1.网址后缀的匹配问题
2.每个后缀匹配成功后执行的代码有多有少
面条版 函数版 模块版
3.将分支的代码封装成一个个函数
4.将网址后缀与函数名做对应关系
5.获取网址后缀循环匹配
6.如果想新增功能只需要先写函数在 添加一个对应关系即可
7.根据不同的功能拆分不同的py文件
views.py 存储核心业务逻辑(功能函数)
urls.py 存储网址后缀与函数名对应关系
templates目录 存储html页面文件(模块文件)
start.py/run.py 启动文件、入口文件
8.为了使函数体代码中业务逻辑有更多的数据可用
将request大字典转手传给这个函数(可用不用但是不能没有)
先展示封装代码在一个页面中
from wsgiref.simple_server import make_server # 导入模块
def index():
return 'from index'
def home():
return 'from home'
'定义一个元组用来存储想要书写的后缀对应的页面'
urls = (
('/index', index),
('/home', home)
)
def run(request,respose):
"""
:param request: 客户端的请求数据
:param respose: 给客户端进行响应的数据
:return: 返回给客户端的真实数据
"""
respose('200 ok', []) # 返回响应状态给客户端
print(request) # 这个参数是wsgiref帮助我们封装的一个大字典,字典中携带的客户端的请求数据
# 获取大字典中的ip和端口号后面的后缀
current_path = request.get('PATH_INFO')
# '''进行判断请求数据的后缀回应不同的数据'''
# if current_path == '/index':
# # return [b'from index']
# res = index()
# return [res.encode('utf-8')]
# elif current_path == '/home':
# with open(r'Myhtml.html','rb')as f:
# return f.read()
# else:
# return [b'404 Error']
'''循环这个元组来判断是否存在后缀'''
func = None # 定义一个空变量来存放
for url in urls: # ('/index', index),
if current_path == url[0]:
func = url[1] # 后缀对应的函数名
break # 一旦匹配到了内容就立刻结束for循环
'''判断当后缀存在时执行'''
if func:
res = func()
return [res.encode('utf-8')]
else:
return [b'404 Error']
if __name__ == '__main__':
server = make_server('127.0.0.1', 8000, app=run) # 分别代表:ip地址、端口号、由那个程序来处理请求
server.serve_forever() # 将服务器持续开启
到此发现如果后续需要添加更多的功能,还是会有很多重复,所以我们需要根据py文件中的功能不同划分不同的py文件
文件拆分
我们需要先建立一个文件夹,存放三个文件以及一个文件夹(用于存放模版文件html)
urls:用于表示用户输入的url应哪一个函数
'''
根据用户输入的url,返回该url对应的处理函数
'''
from views import *
urls = (
('/index', index),
('/home', home),
('/demo', demo)
)
views:用于处理用户的请求与响应用户数据
'''
接收用户请求、在对应函数可以进行一番处理然后响应给用户数据。
'''
def index():
return 'from index'
def home():
return 'from home'
def demo():
with open(r'templates/dj.html', 'r', encoding='utf-8') as f:
return f.read()
我们的Web框架的入口程序
from wsgiref.simple_server import make_server
from urls import urls
def run(request,response):
"""
:param request: 客户端的请求数据
:param respose: 给客户端进行响应的数据
:return: 返回给客户端的真实数据
"""
response('200 ok',[]) # 返回响应状态给客户端
# 获取大字典中的ip和端口号后面的后缀
current_path = request.get('PATH_INFO')
func = None # 定义一个空变量,用于接受处理用户请求的函数返回的数据
'''循环这个元组来判断是否存在后缀'''
for url in urls:
# 判断用户输入的页面后缀地址,是否在我们定义的处理列表中
if current_path == url[0]:
func = url[1] # 后缀对应的函数名
break # 一旦匹配到了内容就立刻结束for循环
'''判断当后缀存在时执行'''
if func:
res = func()
return [res.encode('utf-8')]
else:
return [b'404 Error'] # 当上述判断不执行时,执行else条件,返回404 error
if __name__ == '__main__':
server = make_server('127.0.0.1', 8000, run)
server.serve_forever() # 服务器持续开启
还有最后一个是templates文件夹存放模版文件,也就是html文件

Python主流Web框架
1.Django:重量级框架
Django是基于Python的免费和开放源代码Web框架,它遵循模型-模版-视图(MTV)体系结构模式。它封装的功能非常丰富并且非常多,所以它是重量级框架,Django的文档最完善、是市面最主流框架、市场占有率最高。但如果需要实现的功能很少的项目就会显得略微笨重。
2.Flask:轻量级框架
Flask是Python编写的一种轻量级(微)的Web开发框架,只提供Web框架的核心功能,较其他类型的框架更为的自由、灵活,更加适合高度定制化的Web项目。Flask在功能上面没有欠缺,Flask的第三方开源组件比较丰富,因此Flask对开发人员的水平有了一定的要求。使用Flask开发较为依赖于第三方组件
3.Tornado:异步非阻塞框架
Tornado是一种Web服务器软件的开源版本。Tornado和主流Web服务器框架(包括大多数Python的框架)有着明显的区别:它是非阻塞式的服务器,而且速度相当快。得利于其非阻塞的方式和对epoll的运用,Tornado每秒可以处理数以千计的连接,因此Tornado是实时Web服务的一个理想框架。但很多功能都需要开发者自己去编写,因此学习这个框架成本有点高。
4.fastapi框架
它主要用来写一些接口,制作不出来页面,它只负责写业务逻辑