一、docker安装es
1、下载镜像
docker pull elasticsearch:7.9.0
下载完后,查看镜像
docker images

2、启动镜像
docker network create esnet
docker run -d --name es -p 9200:9200 -p 9300:9300 --network esnet -e "discovery.type=single-node" e71b9e9d21b6
查看日志
docker logs e71b9e9d21b6
3、访问9200端口。
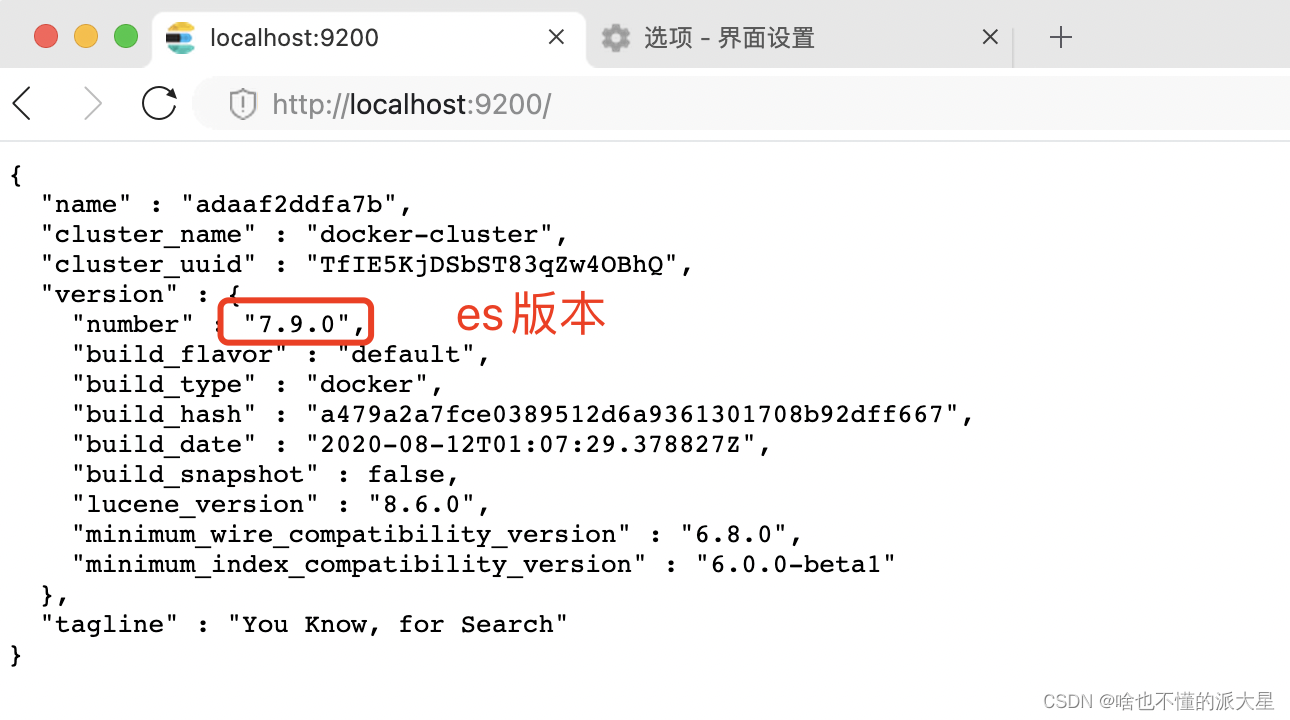
看到这个页面代表es安装成功,es安装完毕!
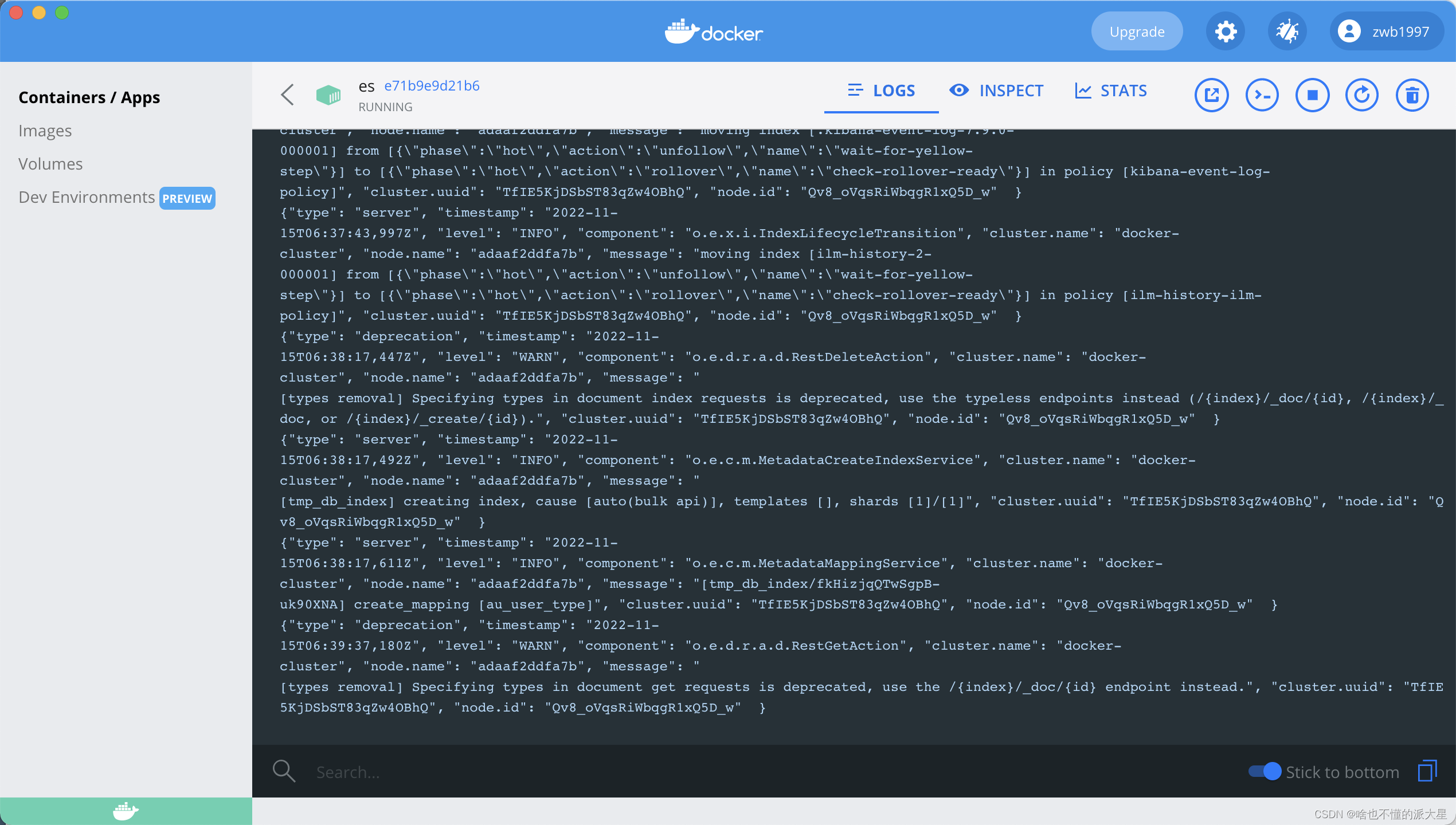
4、在docker可视化工具中查看镜像日志和进程信息。

5、安装IK分词器。
1、从github下载安装。
注意版本要与ES版本一致。
进入容器。
docker exec -it adaaf2ddfa7b bash
安装对应版本的ik分词器。
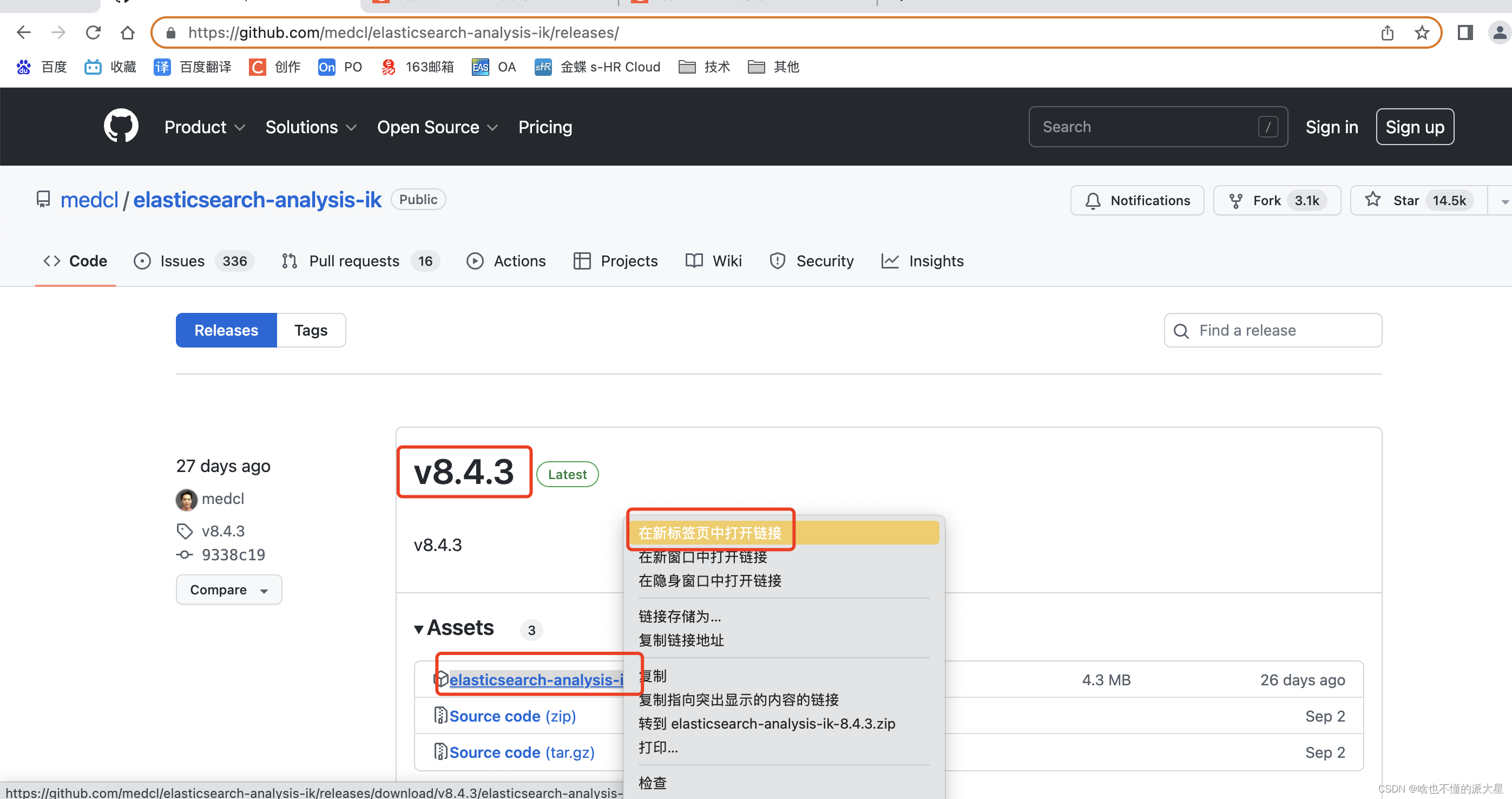
[root@adaaf2ddfa7b bin]# ./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.0/elasticsearch-analysis-ik-7.9.0.zip
重启es镜像即可。
docker restart adaaf2ddfa7b
在kibana中测试一下IK分词器。
POST _analyze
{
"analyzer": "ik_max_word",
"text": ["张三丰","数据库","手机壳"]
}
POST _analyze
{
"analyzer": "standard",
"text": ["张三丰","数据库","手机壳"]
}
POST _analyze
{
"analyzer": "keyword",
"text": ["张三丰","数据库","手机壳"]
}
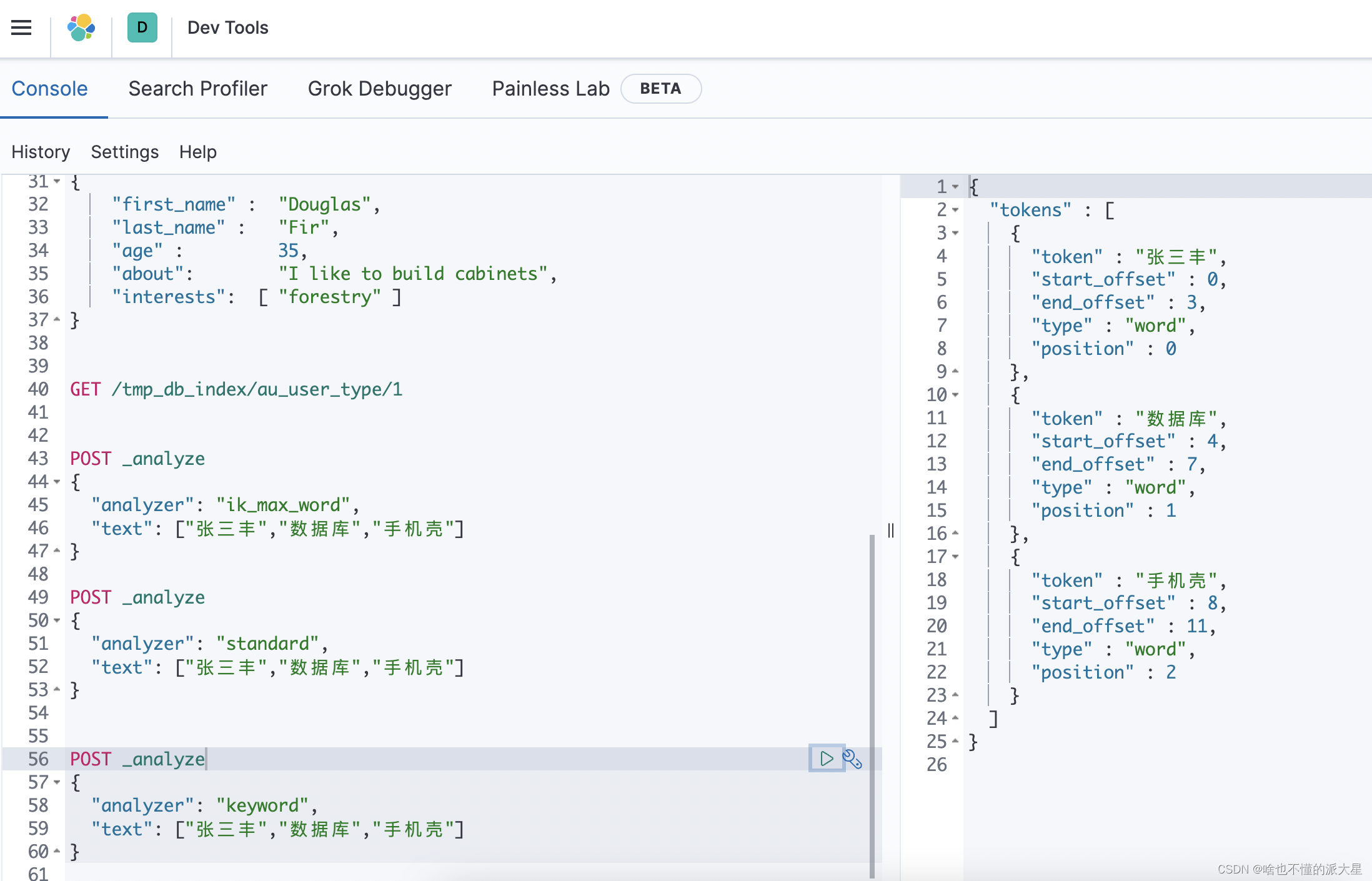
ik_max_word智能分词效果
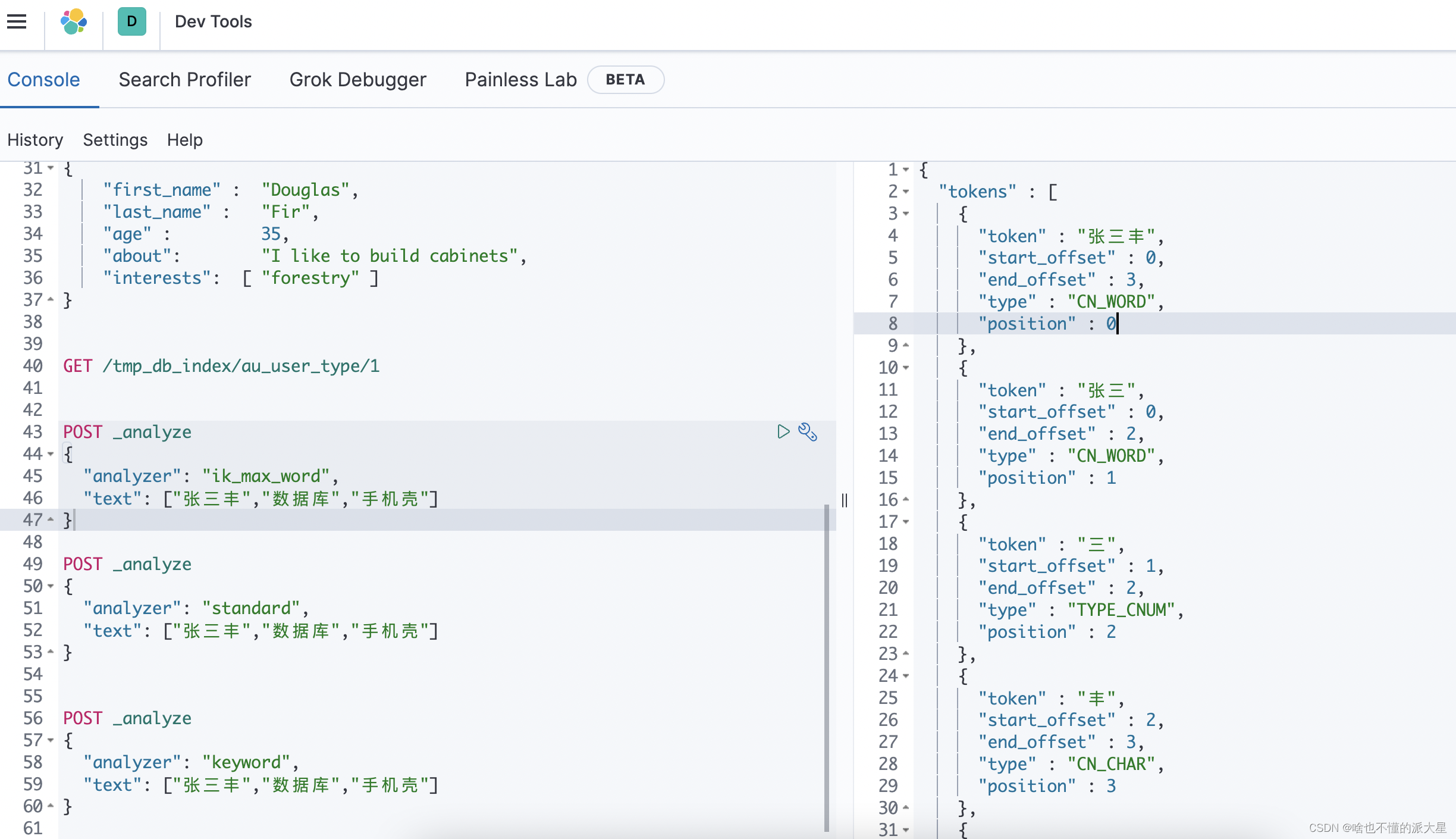
standard效果 会拆分成一个个字
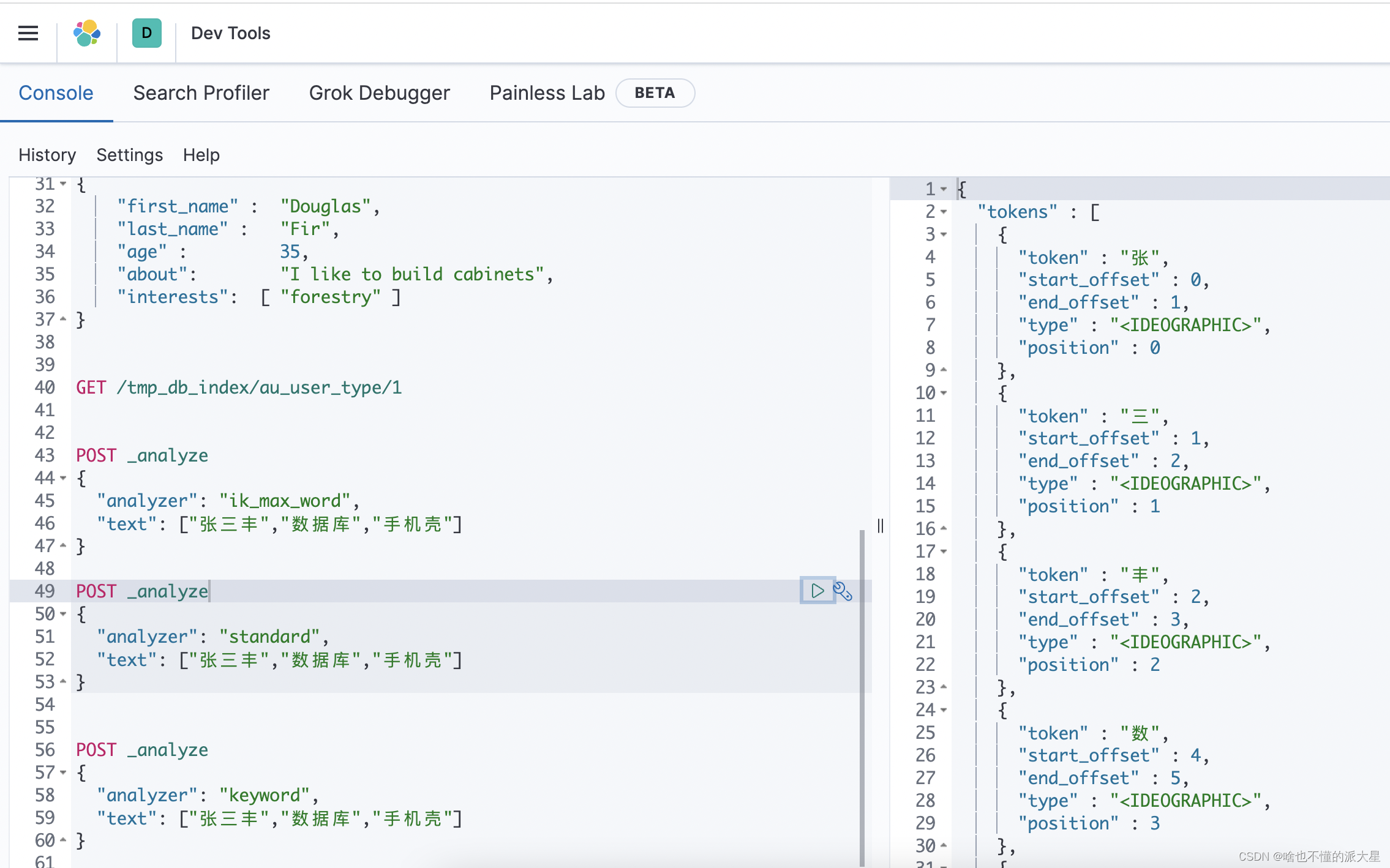
keyword效果
二、mac中安装Kibana
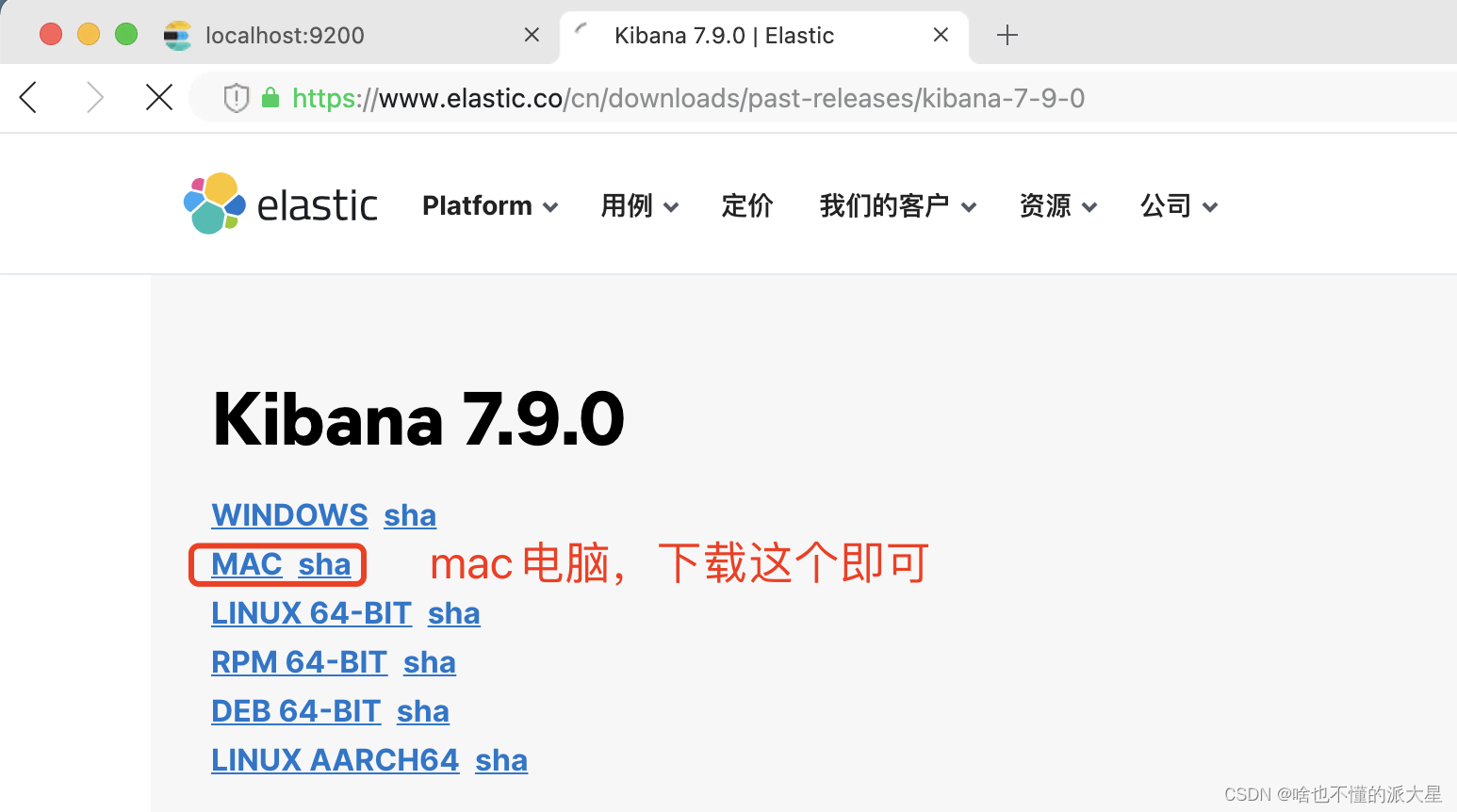
1、下载跟es版本一样的kibana。
官方地址:https://www.elastic.co/cn/downloads/past-releases/kibana-7-9-0
如其他的版本,只需更改链接中的数值。
下载完后解压文件。
2、修改配置文件,添加es的地址。
配置文件路径在config下,kibana.xml。
添加以下配置:

3、运行bin目录下的kibana即可。
bin/kibana

4、访问kibana。
localhost:5601,出现以下页面代表安装成功。
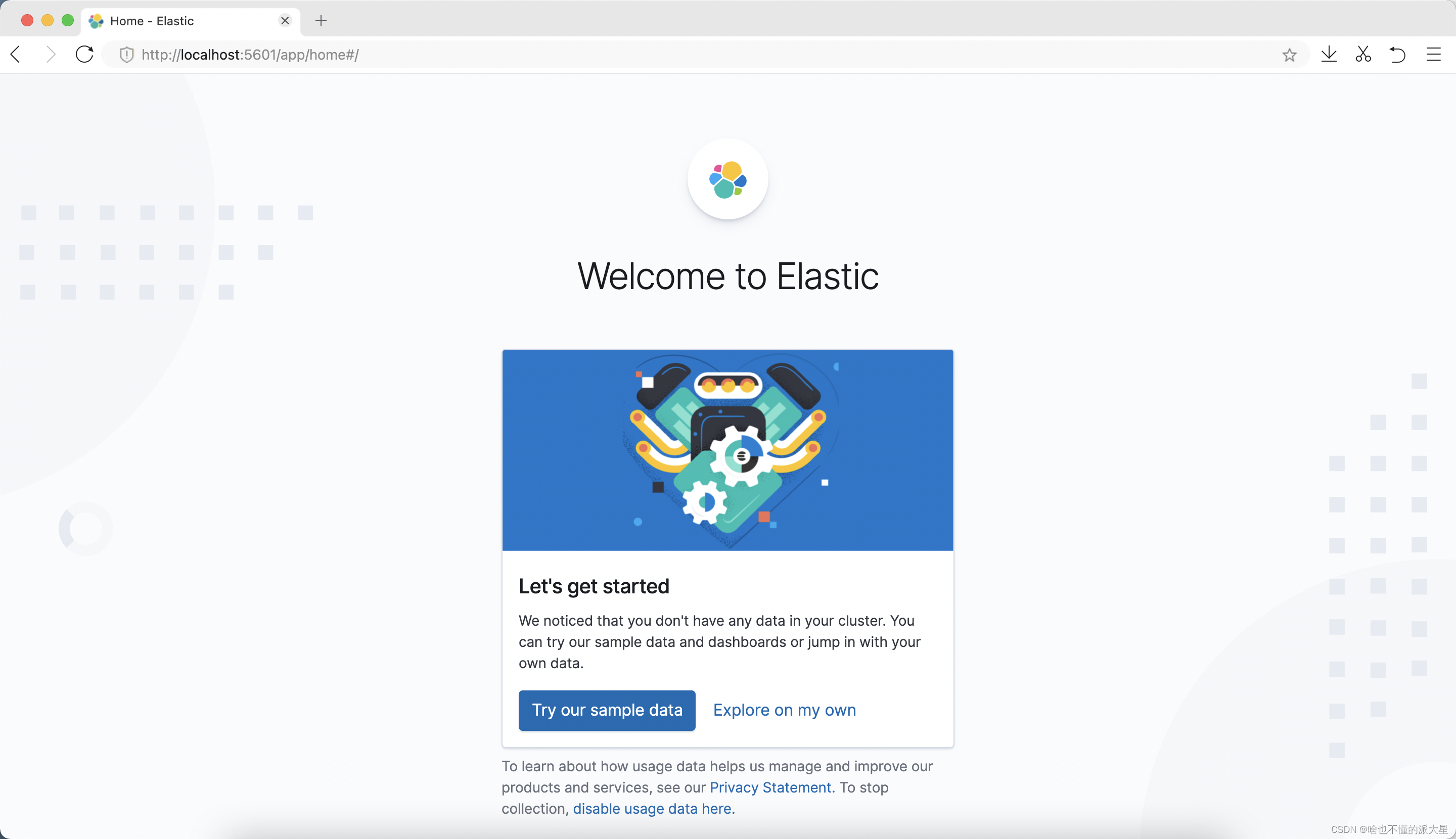
看到这个页面基本上就是安装成功啦!不得不吐槽,界面越来越丑了,哈哈。
5、测试一下。
可以在dev tools里调用es啦。
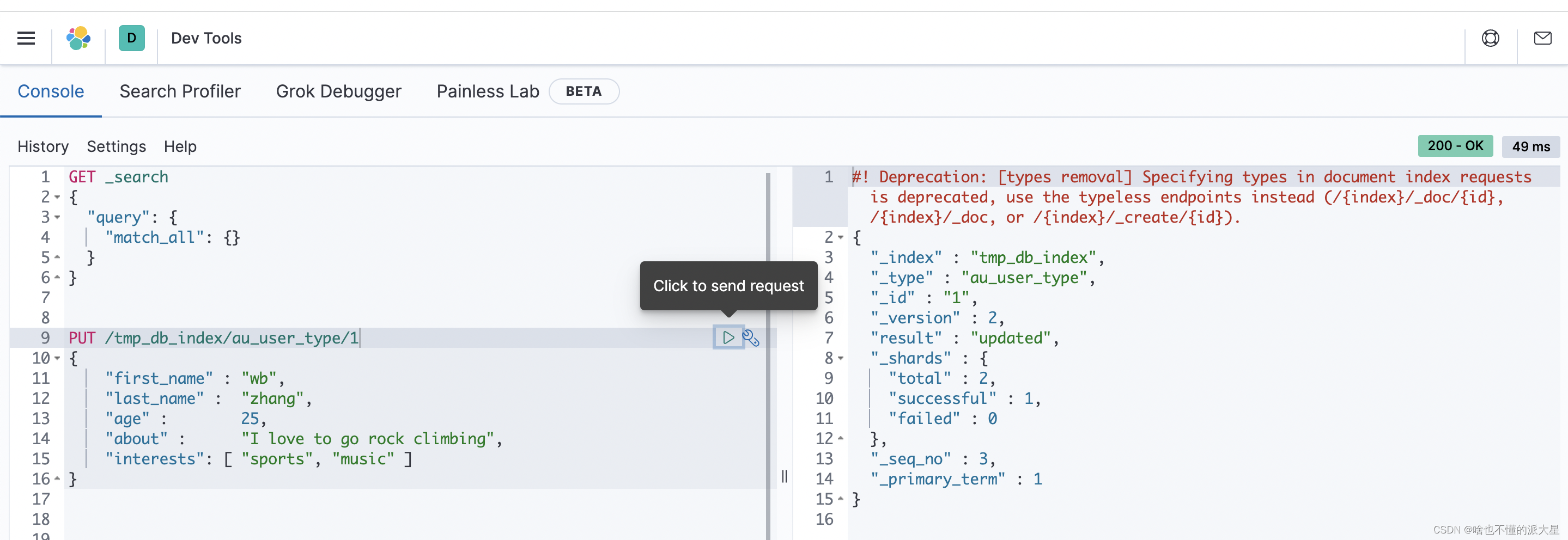
直接发送PUT请求,创建一个索引并插入一个文档,测试成功。
三、es学习笔记。
1、概述。
ES使用java语言并基于lucene编写的搜索引擎框架,提供了分布式的全文搜索功能,提供了基于restful风格的web接口,只需要发送一个web请求,根据请求方式不同,携带不同的参数执行。
Lucene本身就是一个搜索框架的底层。ES主要是突出他的横向扩展能力,分布式的。
1、Slor在查询死数据的时候更快一些,但是如果数据是实时变化的是咯人效率下降,ES没有影响。
2、solr搭建 集群需要 zookeeper,而es本身就支持集群的搭建 不需要第三方的额外介入。
3、slor社区、文档丰富,出现的早,ES较少。
4、ES对云计算和大数据支持的更好。
ES的数据结构
一个 Elasticsearch 集群可以包含多个索引 ,相应的每个索引可以包含多个类型 。 这些不同的类型存储着多个文档 ,每个文档又有多个属性 。
ES会对数据进行分片,1亿条数据,比如分成两个分片,各5000万条数据。
如前所述,一个索引 类似于传统关系数据库中的一个数据库 ,是一个存储关系型文档的地方。
索引 (index) 的复数词为 indices 或 indexes 。
索引(动词):
索引一个文档 就是存储一个文档到一个 索引 (名词)中以便被检索和查询。这非常类似于 SQL 语句中的 INSERT 关键词,除了文档已存在时,新文档会替换旧文档情况之外。
倒排索引:
将一段词语进行分词,并且将分出的词语统一放到一个分词库中,在搜索时根据关键字去分词库中检索,找到匹配的内容。
关系型数据库通过增加一个索引比如一个 B树(B-tree)索引 到指定的列上,以便提升数据检索速度。Elasticsearch 和 Lucene 使用了一个叫做倒排索引的结构来达到相同的目的。
默认的,一个文档中的每一个属性都是 被索引 的(有一个倒排索引)和可搜索的。一个没有倒排索引的属性是不能被搜索到的。
一个类型下可以有多个文档,相当于db中多行数据;一个列多个属性,相当于db中表中行的列字段。
可以理解成如下的对应关系:
- 数据库-----索引
- 数据表-----类型
- 一条记录-----一个文档
- 字段------属性
在ES中可以创建多个索引,每个索引默认被分成5片存储。每个分片都会存在至少一个备份分片,备份分片默认不会帮助检索数据,当Es检索压力过大时,备份分片才会帮忙检索数据,备份的分片必须放在不同的服务器中。
一个索引下可以有多个类型 版本:
- ES5.X 一个索引对应多个类型
- ES6.X 一个索引对应1个类型
- ES7.X 索引下没有类型 类型被移除了
2、操作ES的restful语法
GET:
- http://ip:port/index 查询索引信息
- http://ip:port/index/type/doc_id 查询指定的文档信息
POST:
- http://ip:port/index/type/_search 查询文档,可以在请求体中添加json字符串来代表查询条件
- http://ip:port/index/type/doc_id/_update 修改文档,在请求体中添加json字符串来代表修改的信息
PUT:
- http://ip:port/index 创建一个索引,需要在请求体中指定索引的信息
- http://ip:port/index/type/_mappings 代表创建索引时,指定索引文档存储属性的信息
DELETE :
-
http://ip:port/index 删库跑路
-
http://ip:port/index/type/doc_id 删除指定的文档
3、创建索引和索引的常用操作。
#创建一个索引
PUT /nts_db_index
{
""settings"": {
""number_of_shards"": 5,
""number_of_replicas"": 1
}
}
#分片数 默认是5
#备份数量模式1
GET /nts_db_index
# 会直接创建一个索引
PUT /tmp_db_index/au_user_type/1
{
""first_name"" : ""wb"",
""last_name"" : ""zhang"",
""age"" : 25,
""about"" : ""I love to go rock climbing"",
""interests"": [ ""sports"", ""music"" ]
}
PUT /tmp_db_index/au_user_type/2
{
""first_name"" : ""Jane"",
""last_name"" : ""Smith"",
""age"" : 32,
""about"" : ""I like to collect rock albums"",
""interests"": [ ""music"" ]
}
PUT /tmp_db_index/au_user_type/3
{
""first_name"" : ""Douglas"",
""last_name"" : ""Fir"",
""age"" : 35,
""about"": ""I like to build cabinets"",
""interests"": [ ""forestry"" ]
}
#查询索引信息 分片数 被分数 别名 属性类型等
GET /tmp_db_index
#查询 全部
GET /tmp_db_index/au_user_type/_search
#根据id=1查询
GET /tmp_db_index/au_user_type/1
#删除索引
DELETE /tmp_db_index"
{
""nts_db_index"" : {
""aliases"" : { }, 别名
""mappings"" : { }, 数据的结构
""settings"" : {
""index"" : {
""creation_date"" : ""1613207857440"",
""number_of_shards"" : ""5"", 分片数
""number_of_replicas"" : ""1"", 备份数
""uuid"" : ""w_bLH--GQI6EcrJL3THDzw"",
""version"" : {
""created"" : ""6050499""
},
""provided_name"" : ""nts_db_index""
}
}
}
}
kibana的索引查询页面
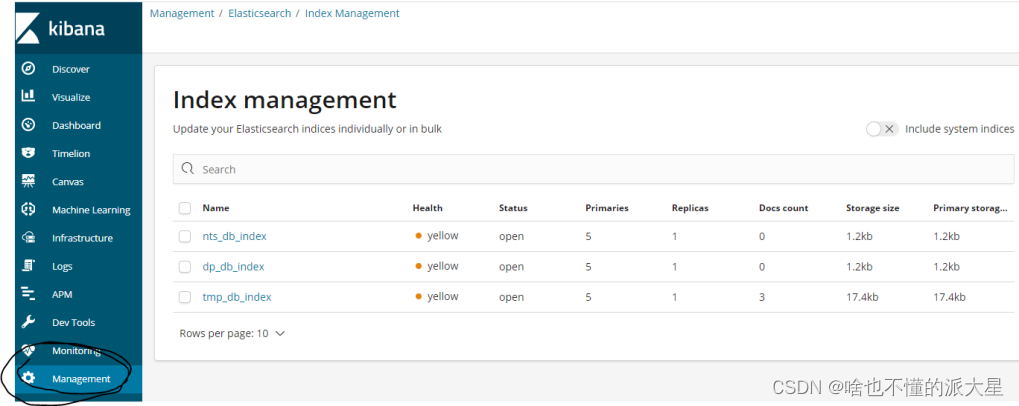
4、属性类型
string类型
- text:一般用于全文检索 将当前属性进行分词
- keyword:当前属性不会被分词
数值类型
- long
- integer
- short
- byte
- double
- float
- half_float 精度比float小一半
- scaled_float 根据一个long和scaled来表示一个浮点型 long-345 scaled-100 -->3.45
时间类型
- date类型 针对具体格式的时间 yyyy-mm-dd hh-ms-ss long毫秒数
布尔类型
- true
- false
二进制类型
- binary类型暂时只支持Base6 encoding string
范围类型
- long_range 存储一个范围 无需指定具体内容 指定 gt lt gte lte
- integer_range 以下均同上
- double_range
- float_range
- dat_range
- ip_range
位置类型
- 经纬度 geo_point
ip类型
- ipv4
- ipv6
5、创建索引 指定属性的数据结构
PUT /book
{
""settings"": {
""number_of_shards"": 5,
""number_of_replicas"": 1
},
""mappings"": {
""noval"":{
""properties"":{
""name"":{
""type"":""text"",
""analyzer"":""ik_max_word"",
""index"":true,
""store"":false
},
""auther"":{
""type"":""keyword""
},
""count"":{
""type"":""long""
},
""on-time"":{
""type"":""date"",
""format"":""yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis""
},
""desc"":{
""type"":""text"",
""analyzer"":""ik_max_word""
}
}
}
}
}
注释:
#创建索引,指定数据类型
PUT /book
{
""settings"": {
#分片数
""number_of_shards"": 5,
#备份数
""number_of_replicas"": 1
},
#指定数据类型
""mappings"": {
#类型 Type
""novel"":{
#文档存储的field
""properties"":{
#field属性名
""name"":{
#类型
""type"":""text"",
#指定分词器
""analyzer"":""ik_max_word"",
#指定当前的field可以被作为查询的条件
""index"":true,
#是否需要额外存储
""store"":false
},
""author"":{
""type"":""keyword""
},
""count"":{
""type"":""long""
},
""on-sale"":{
""type"":""date"",
#指定时间类型的格式化方式
""format"": ""yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis""
},
""descr"":{
""type"":""text"",
""analyzer"":""ik_max_word""
}
}
}
}
}
6、文档的操作
添加文档 自动生成id
POST /book/noval
{
""name"":""我和我的祖国"",
""auther"":""张文"",
""count"":100000,
""on-time"" : ""2021-02-14 14:20:06"",
""desc"":""我和我的祖国,一刻也不能分割,无论我走到哪里,都留下一首赞歌!""
}
添加文档 手动指定id
POST /book/noval/1
{
""name"":""我和我的家乡"",
""auther"":""杜卓"",
""count"":2222222,
""on-time"" : ""2021-2-14 14:22:55"",
""desc"":""我和我的家乡大枣庄,真漂亮啊真漂亮,我爱吃辣子鸡和莲蓬啊!""
}
修改文档 覆盖式修改
POST /book/noval/1
{
""name"":""我和我的家乡"",
""auther"":""杜卓1"",
""count"":22220000,
""on-time"" : ""2021-2-14 14:22:55"",
""desc"":""我和我的家乡大枣庄,真漂亮啊真漂亮,我爱吃辣子鸡和莲蓬啊!""
}
修改文档 基于doc的方式
POST /book/noval/1/_update
{
""doc"": {
""count"":6666666
}
}
根据id删除文档
DELETE /book/noval/DEU1n3cBhRoCqt_4gtk7
查询操作,GET 或者 POST(带条件的)都可以
7、ES查询语法
查询 相当于mysql的limit 分页
from size (默认 0 20)
GET /sms-logs-index/sms-logs-type/_search
{
""from"": 0,
""size"": 4
}
7.1 term查询
代表的是完全匹配,搜索之前不会对搜索关键字进行分词,对你的关键字去分词库中匹配内容
# term查询
GET /sms-logs-index/sms-logs-type/_search
{
""from"": 0,
""size"": 4,
""query"": {
""term"": {
""province"": {
""value"": ""上海""
}
}
}
}
# 如果用"上"匹配则匹配不上
# 相当于 where province = "上海"
7.2 terms查询
与term查询一样 都不对查询的关键字进行分词 直接去分词库里面匹配 找到相应的文档内容
terms是针对一个字段包含多个值的时候使用
GET /sms-logs-index/sms-logs-type/_search
{
""query"": {
""terms"": {
""province"": [
""上海"",
""北京""
]
}
}
}
# 相当于where province = "上海" or province = "北京"
GET /sms-logs-index/sms-logs-type/_search
{
""query"": {
""term"": {
""smsContent"": [
""孩子""
]
}
}
}
# terms也可以 不仅仅是关键字 普通的文本分词以后也可以
7.3 match查询
match查询属于高层查询,会根据查询的字段类型不同采取不同的查询方式
查询的是日期或数值类型,会基于查询字符串内容转为日期或者数值对待 。
如果查询的内容不是一个不能被分词的内容(keyword),match查询不会对指定的内容进行分词。
如果查询的内容是一个不能被分词的内容(text),match查询会对指定的内容进行分词,去分词库中匹配指定的内容。
match查询底层就是多个term查询封装到了一起。
7.3.1 match_all 查询
查询全部内容,不指定任何查询条件 默认只查询出来10条 可以加size限制"
GET /sms-logs-index/sms-logs-type/_search
{
""query"": {
""match_all"": {}
}
}
7.3.2 match 查询
指定一个属性作为筛选的条件
GET /sms-logs-index/sms-logs-type/_search
{
""query"": {
""match"": {
""smsContent"": ""一个没有实力的男人""
}
}
# ik分词后:一个,一,个,没有,实力,男人
7.3.3 布尔 match 查询
and 或者 or
GET /sms-logs-index/sms-logs-type/_search
{
""query"": {
""match"": {
""smsContent"": {
""query"": ""孩子 中年"",
""operator"": ""and""
}
}
}
}
# and 内容既包含孩子也包含中年
# or 内容包含孩子或者中年
7.3.4 multi_match查询
针对多个属性进行检索,多个field对应一个内容
match是一个属性
GET /sms-logs-index/sms-logs-type/_search
{
""query"": {
""multi_match"": {
""query"": ""北京"",
""fields"": [""province"",""corpName""]
}
}
}
7.4、其他查询
7.4.1 id查询
查询id是8的文档
GET /sms-logs-index/sms-logs-type/8
7.4.2 ids查询
根据多个id查询 类似in
GET /sms-logs-index/sms-logs-type/_search
{
""query"": {
""ids"": {
""values"": [""1"",""2"",""8""]
}
}
}
7.4.2 前缀查询prefix
可以通过一个关键字去指定一个属性的前缀,去匹配文档,类似sql中的 like ‘海尔%’
GET /sms-logs-index/sms-logs-type/_search
{
""query"": {
""prefix"": {
""corpName"": {
""value"": ""海尔""
}
}
}
}
对比下match查询
#以海尔开头的,而match则匹配不上
GET /sms-logs-index/sms-logs-type/_search
{
""query"": {
""match"": {
""corpName"": ""海尔""
}
}
}
7.4.3 fuzzy查询 模糊查询
根据输入字符的大概去匹配 错别字
不太稳定
数据量大的话不支持 可以加参数,保证前面几个字符是不能出错的
GET /sms-logs-index/sms-logs-type/_search
{
""query"": {
""fuzzy"": {
""corpName"": {
""value"": ""海尔电气""
}
}
}
}
GET /sms-logs-index/sms-logs-type/_search
{
""query"": {
""fuzzy"": {
""corpName"": {
""value"": ""格力汽扯"",
""prefix_length"": 3
}
}
}
}
7.4.4 wildcard查询 通配符 占位符
和like一个套路,使用通配符*和占位符?
POST /sms-logs-index/sms-logs-type/_search
{
""query"": {
""wildcard"": {
""corpName"": {
""value"": ""*力*""
}
}
}
}
POST /sms-logs-index/sms-logs-type/_search
{
""query"": {
""wildcard"": {
""corpName"": {
""value"": ""海尔????""
}
}
}
}
7.4.5 range查询 只针对数值类型范围查询
对某一个fiId进行大于或小于的范围指定
POST /sms-logs-index/sms-logs-type/_search
{
""query"": {
""range"": {
""replyTotal"": {
""gte"": 3,
""lte"": 15
}
}
}
}
gte ≥
lte ≤
gt >
lt <
7.4.6 regexp查询 正则匹配
通过编写的正则表达式来匹配文档
POST /sms-logs-index/sms-logs-type/_search
{
""query"": {
""regexp"": {
""mobile"": ""138[0-9]{8}""
}
}
}
7.4.7 深分页 scroll
效率高 放到内存中 但使用场景为不是实时的数据
ES对from+size是有限制的,数量不超过1w
from+size原理
1、将查询关键字分词
2、将词汇去分词库中检索,得到多个文档id
3、去各个分片中拉取指定的数据,耗时较长
4、将数据根据score分数排序
5、根据from的值将数据舍弃一部分
6、返回数据
scroll原理
1、将查询关键字分词
2、将词汇去分词库中检索 得到多个文档id
3、将文档id放到ES的一个上下文中
4、将指定的size去es中检索指定的数据 拿完文档的id,会从上下文中移除
5、如果找下一页内容,直接去es的上下文中找
不适合做实时的数据查询
# 指定生存时间为1分钟
# 默认是id排序 也可指定
POST /sms-logs-index/sms-logs-type/_search?scroll=1m
{
""query"": {
""match_all"": {}
},
""size"": 3
}
#加排序
POST /sms-logs-index/sms-logs-type/_search?scroll=1m
{
""query"": {
""match_all"": {}
},
""size"": 3,
""sort"": [
{
""fee"": {
""order"": ""desc""
}
}
]
}
# 查询下一页数据
POST /_search/scroll
{
""scroll_id"":
""DnF1ZXJ5VGhlbkZldGNoAwAAAAAAAAX4Fk4yWlZWaFNTUmR1bzB4V1VfU1ZQcFEAAAAAAAAF-RZOMlpWVmhTU1JkdW8weFdVX1NWUHBRAAAAAAAABfoWTjJaVlZoU1NSZHVvMHhXVV9TVlBwUQ=="",
""scroll"":""1m""
}
7.4.8 复合查询 bool
bool查询 复合过滤器,将多个查询条件组合在一起
- must 所有的条件 组合在一起 and
- must_not 将条件 全部不能匹配 not
- should 所有的条件 组合一起 or
#bool 省份是北京或者上海 公司不是阿里开头的 内容包含孩子和中年的数据
POST /sms-logs-index/sms-logs-type/_search
{
""query"": {
""bool"": {
""should"": [
{
""term"": {
""province"": {
""value"": ""北京""
}
}
},{
""term"": {
""province"": {
""value"": ""上海""
}
}
}
],
""must_not"": [
{
""wildcard"": {
""corpName"": {
""value"": ""阿里*""
}
}
}
],
""must"": [
{
""match"": {
""smsContent"": ""孩子""
}
},
{""match"": {
""smsContent"": ""中年""
}}
]
}
}
}
7.4.9 bootsting查询 score 分数排序
可以帮助我们去影响查询后的score 从而影响排序
score分数:
1、搜索的关键字在文档中出现的频率越高,分数越高
2、文档内容越短 分数越高
3、搜索的关键字分词以后匹配到的内容越多 分数越高
positive 只有匹配上positive的内容才会返回到结果集中
negative 如果匹配上positive和negative,会降低文档的score
negative_boost 指定系数 必须小于1
#boosting
POST /sms-logs-index/sms-logs-type/_search
{
""query"": {
""boosting"": {
""positive"": {
""match"": {
""smsContent"": ""有实力的男人""
}
},
""negative"": {
""match"": {
""smsContent"": ""中年人""
}
},
""negative_boost"": 0.5
}
}
}
7.4.10 filter查询 数据做缓存
query查询是根据查询条件去计算文档匹配到的分数,并且根据分数进行排序,不会做缓存
filter查询是根据条件去查询文档,不计算分数,而且会对经常被过滤的数据进行缓存,查出来的数据分数都是0
POST /sms-logs-index/sms-logs-type/_search
{
""query"": {
""bool"": {
""filter"": [
{
""term"": {
""province"": ""北京""
}
},
{
""range"": {
""fee"": {
""gte"": 30,
""lte"": 80
}
}
}
]
}
}
}
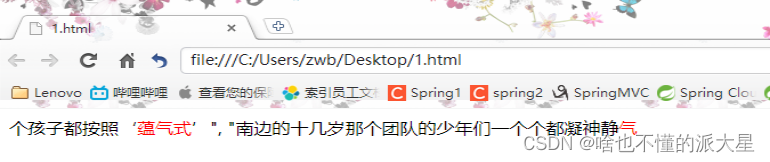
7.4.11 高亮查询 将查询关键字添加样式
高亮展示的数据,本身就是文档中的一个field,单独将field以高亮的形式返回
highlight属性 和query同级
pre_tag 指定前缀标签 如 <font color =““red””>
post_tag 指定后缀标签
fragment_zise 指定高亮数据展示多少个字符回来
POST /sms-logs-index/sms-logs-type/_search
{
""query"": {
""match"": {
""smsContent"": ""蕴气式""
}
},
""highlight"": {
""fields"": {
""smsContent"": {}
},
""pre_tags"": ""<font color ='red'>"",
""post_tags"": ""</font>"",
""fragment_size"" :10
}
}
7.4.12 聚合查询
和MySQL的聚合查询类似,ES的聚合查询更加强大,提供的统计方式多种多样
restful语法:
POST /index/type/_search
{
""aggs"":{
""(名字 随意哦)agg"":{
""agg_type"":{
""属性"":""值""
}
}
}
}
去重计数
省份去重 province_distinct
POST /sms-logs-index/sms-logs-type/_search
{
""aggs"": {
""province_distinct"": {
""cardinality"": {
""field"": ""province""
}
}
}
}
7.4.13 范围统计
统计一个范围内出现的文档个数。
比如一个field的值在0-100,100-200等出现的个数 分别统计
针对数值类型、时间类型、ip类型,对应的语法:range、date_dange、ip_range
数值类型 range
POST /sms-logs-index/sms-logs-type/_search
{
""aggs"": {
""agg"": {
""range"": {
""field"": ""fee"",
""ranges"": [
{
""to"": 30
},
{
""from"": 30,
""to"": 50
},{
""from"": 50
}
]
}
}
}
}
from是带等号的
时间类型 查询 date_range
POST /sms-logs-index/sms-logs-type/_search
{
""aggs"": {
""agg"": {
""date_range"": {
""field"": ""createDate"",
""format"": ""yyyy"",
""ranges"": [
{
""from"": ""2020"",
""to"": ""2022""
}
]
}
}
}
}
ip类型 ip_range
POST /sms-logs-index/sms-logs-type/_search
{
""aggs"": {
""agg"": {
""ip_range"": {
""field"": ""ipAddr"",
""ranges"": [
{
""to"": ""127.0.0.4""
},
{
""from"": ""127.0.0.4"",
""to"": ""127.0.0.8""
},{
""from"": ""127.0.0.8""
}
]
}
}
}
}
7.4.14 统计聚合查询 求某一列的聚合函数
求指定field的最大值 最小值 平均数 平方和等
POST /sms-logs-index/sms-logs-type/_search
{
""aggs"": {
""agg"": {
""extended_stats"": {
""field"": ""fee""
}
}
}
}
结果:
{
""count"" : 13,
""min"" : 18.0,
""max"" : 90.0,
""avg"" : 54.0,
""sum"" : 702.0,
""sum_of_squares"" : 44460.0,
""variance"" : 504.0,
""std_deviation"" : 22.44994432064365,
""std_deviation_bounds"" : {
""upper"" : 98.8998886412873,
""lower"" : 9.100111358712702
}
}
7.4.15 地图经纬度搜索
经纬度 geo_point
#创建地图索引
PUT /map
{
""settings"": {
""number_of_shards"": 5,
""number_of_replicas"": 1
},
""mappings"": {
""bj_map"":{
""properties"":{
""name"":{
""type"":""text""
},
""location"":{
""type"":""geo_point""
}
}
}
}
}
#地图索引插入数据
PUT /map/bj_map/1
{
""name"":""北京科技职业学院"",
""location"":{
""lon"": 116.257172,
""lat"": 40.123649
}
}
PUT /map/bj_map/2
{
""name"":""广洋公寓"",
""location"":{
""lon"": 116.267578,
""lat"": 40.132317
}
}" "PUT /map/bj_map/3
{
""name"":""飞腾家园"",
""location"":{
""lon"": 116.382617,
""lat"": 39.808707
}
}
PUT /map/bj_map/4
{
""name"":""模式口西里"",
""location"":{
""lon"": 116.156704,
""lat"": 39.940053
}
}
PUT /map/bj_map/5
{
""name"":""老山东里"",
""location"":{
""lon"": 116.231905,
""lat"": 39.91603
}
}"
地图检索方式
- geo_distance 直线距离检索方式
- geo_bounding_box 以两个点确定一个矩形 获取矩形内的位置
- geo_polygon 以多个点 确认一个多边形 获取多边形内的全部位置
geo_distance
POST /map/bj_map/_search
{
""query"": {
""geo_distance"":{
""location"":{ #指定位置
""lon"" : 116.372097,
""lat"" : 39.818302
},
""distance"": 2000, #半径
""distance_type"":""arc"" #圆形
}
}
}
结果:
# 新宫 直径2000米内的
{
""took"" : 6,
""timed_out"" : false,
""_shards"" : {
""total"" : 5,
""successful"" : 5,
""skipped"" : 0,
""failed"" : 0
},
""hits"" : {
""total"" : 1,
""max_score"" : 1.0,
""hits"" : [
{
""_index"" : ""map"",
""_type"" : ""bj_map"",
""_id"" : ""3"",
""_score"" : 1.0,
""_source"" : {
""name"" : ""飞腾家园"",
""location"" : {
""lon"" : 116.382617,
""lat"" : 39.808707"
geo_bounding_box
# 两个点确认一个矩形 指定左上角的坐标和右下角的坐标
POST /map/bj_map/_search
{
""query"": {
""geo_bounding_box"":{
""location"":{
""top_left"":{
""lon"" : 116.193999,
""lat"" : 39.99746
},
""bottom_right"":{
""lon"" : 116.421666,
""lat"" : 39.518215
}
}
}
}
}
结果:
{
{
""_index"" : ""map"",
""_type"" : ""bj_map"",
""_id"" : ""5"",
""_score"" : 1.0,
""_source"" : {
""name"" : ""老山东里"",
""location"" : {
""lon"" : 116.231905,
""lat"" : 39.91603
}
},
{
""_index"" : ""map"",
""_type"" : ""bj_map"",
""_id"" : ""3"",
""_score"" : 1.0,
""_source"" : {
""name"" : ""飞腾家园"",
""location"" : {
""lon"" : 116.382617,
""lat"" : 39.808707
}
}
geo_polygon
POST /map/bj_map/_search
{
""query"": {
""geo_polygon"":{
""location"":{
""points"":[
{
""lon"" : 116.218778,
""lat"" : 39.930794
},
{
""lon"" : 116.259525,
""lat"" : 9.930628
},
{
""lon"" : 116.197003,
""lat"" : 39.913696
},
{
""lon"" : 116.242134,
""lat"" : 39.913253
}
]
}
}
}
}
结果:
{
""_index"" : ""map"",
""_type"" : ""bj_map"",
""_id"" : ""5"",
""_score"" : 1.0,
""_source"" : {
""name"" : ""老山东里"",
""location"" : {
""lon"" : 116.231905,
""lat"" : 39.91603
}
}
7.4.16 delete-by-query 删除查询到的结果
根据term/match等查询方式去删除大量的文档
建议备份 大量数据不推荐
底层还是按照id一个一个删除
POST /sms-logs-index/sms-logs-type/_delete_by_query
{
""query"": {
""range"": {
""replyTotal"": {
""gte"": 3,
""lte"": 6
}
}
}
}
删除结果:
{
""took"" : 26,
""timed_out"" : false,
""total"" : 2,
""deleted"" : 2,
""batches"" : 1,
""version_conflicts"" : 0,
""noops"" : 0,
""retries"" : {
""bulk"" : 0,
""search"" : 0
},
""throttled_millis"" : 0,
""requests_per_second"" : -1.0,
""throttled_until_millis"" : 0,
""failures"" : [ ]
}







![[附源码]SSM计算机毕业设计“云味坊”购物网站JAVA](https://img-blog.csdnimg.cn/6e1d891bbc7f415a95be21b732fff5db.png)