目录
1.概念
2.模拟实现
2.1框架
2.2哈希桶结构
2.3相关功能
Modify
--Insert
--Erase
--Find
2.4非整型数据入哈希桶
1.仿函数
2.BKDR哈希
1.概念
具有相同地址的key值归于同一集合中,这个集合称为一个桶,各个桶的元素通过单链表链接
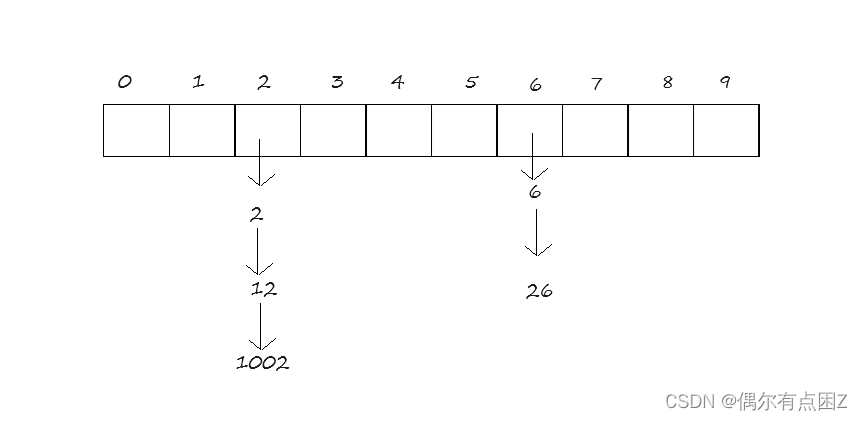
2.模拟实现
2.1框架
a.写出哈希桶的结构: hash_node + hash_table 节点 + 指针数组
b.思路: 增删查改的实现 + 扩容
c.使用除留余数法获得在哈希表中的位置~~>将非整型数据转换为整型数据~~>提供仿函数
2.2哈希桶结构
哈希桶本质是一个指针数组,里面存放的是指针,指向一个链表~~>使用vector来存放 + n(负载因子)
namespace HashBucket
{
//1.节点
template<class T>
struct HashNode
{
HashNode<T>* _next;
T _data;
//构造函数
HashNode(const T& data)
:_next(nullptr)
,_data(data)
{}
};
//2.哈希表
template<class T>
class HashTable
{
typedef HashNode<T> Node;
public:
//接口
private:
vector<Node>* _tables;
size_t n = 0; //有效数据个数
};
}2.3相关功能
Modify
--Insert
思路:
1.判断是否需要扩容
a.扩容~~>将原来的数据移动到新开辟的空间
b.不扩容~~>直接头插
2.头插
a.计算这个值在哈希表中的位置
b.单链表的头插
c.更新hash_table
--将旧数据移动到新开辟的空间
方式1:复用insert~~>额外开辟新节点 + 释放旧的空间
方式2:直接挪动
a.开辟新空间(创建新表)
b.遍历原链表~~>取节点下来头插(保存下一个节点 + 重新计算hashi + 头插)
c.交换新旧表
--单链表的头插:
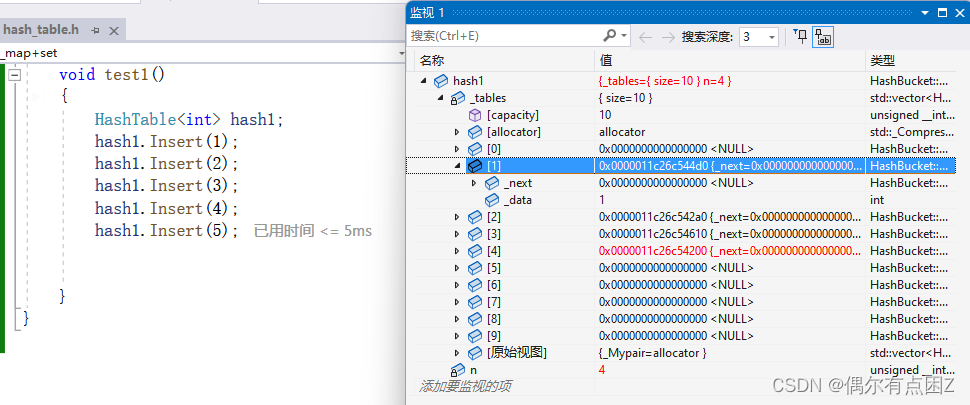
代码:
bool Insert(const T& data) { //1.扩容检查 if (n == _tables.size()) { size_t newsize = _tables.size() == 0 ? 10 : 2 & _tables.size(); vector<Node*> newtables(newsize, nullptr); //创建新表 //将原来的数据挪动到新表 for (auto& cur : _tables) { while (cur) { //保存下一个节点 Node* next = cur->_next; //重新计算在哈希桶中的位置 size_t hashi = (cur->_data) % newtables.size(); //放进新桶 cur->_next = newtables[hashi]; newtables[hashi] = cur; cur = next; } } //交换 _tables.swap(newtables); } //2.头插数据 Node* newnode = new Node(data); //创建节点 size_t hashi = data % _tables.size();//计算在在个哈希桶 newnode->_next = _tables[hashi]; _tables[hashi] = newnode; ++n; return true; }效果:

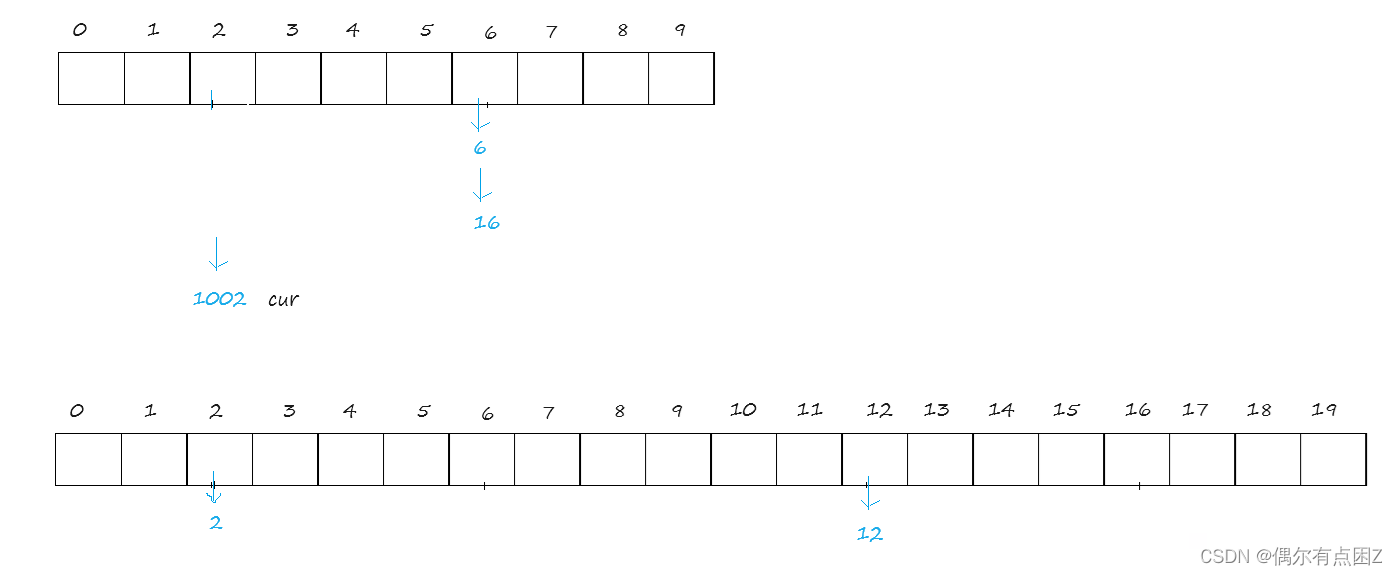

--Erase
思路:
1.计算data在哪个哈希桶
2.删除节点
a.头删~~>更新头
b.非头删除~~>找pre链接next
代码:
bool Erase(const T& data) { //1.计算在哪个哈希桶 size_t hashi = data % _tables.size(); //2.删除节点 Node* pre = nullptr, * cur = _tables[hashi]; while (cur) { //记录下一个节点 Node* next = cur->_next; if (cur->_data == data) { //头删 if (pre == nullptr) { delete cur; cur = nullptr; _tables[hashi] = next; return true; } //非头删 else { pre->_next = next; delete cur; cur = nullptr; return true; } } //没找到继续往后找 pre = cur; cur = cur->_next; } return false; }效果
--非头删:
--头删


--Find
思路:
如果哈希表没有元素,直接返回
1.计算在哪个哈希桶
2.遍历这个哈希桶,看有没有这个值
代码:
Node* Find(const T& data) { //如果这个哈希表为空, 直接返回 if (_tables.size() == 0)return nullptr; //1.计算在哪个哈希桶 size_t hashi = data % _tables.size(); //2.遍历这个桶,找data Node* cur = _tables[hashi]; while (cur) { if (cur->_data == data) return cur; cur = cur->_next; } //遍历完都没有找到 return nullptr; }效果:
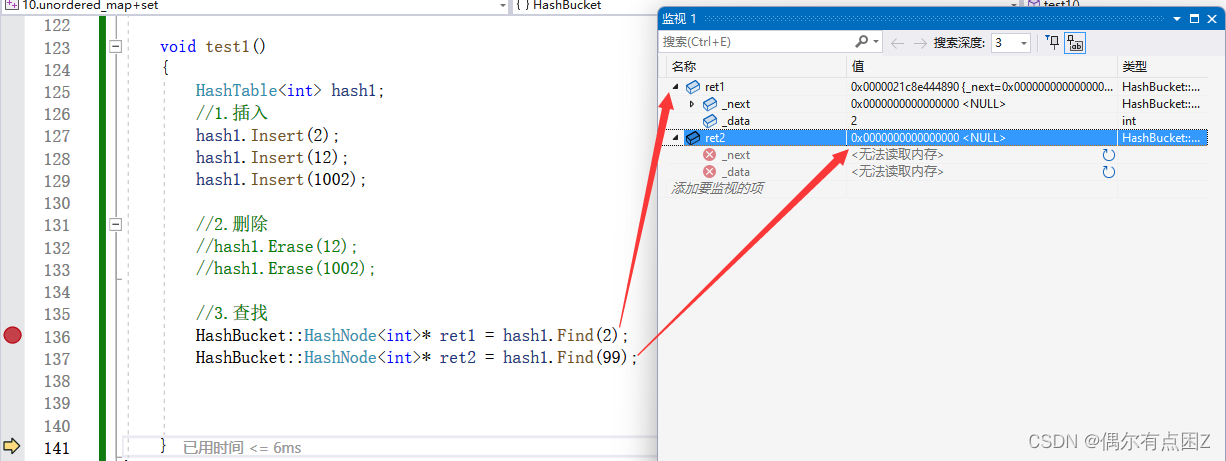
2.4非整型数据入哈希桶
由于哈希桶是采用除留余数法 ~~> 算在哪个哈希桶 ~~> 必须是整型数据
1.仿函数
使用仿函数将非整型数据转换为整型
代码:
//仿函数 template<class T> struct HashFunc { size_t operator()(const T& data) { return data; } };
2.BKDR哈希
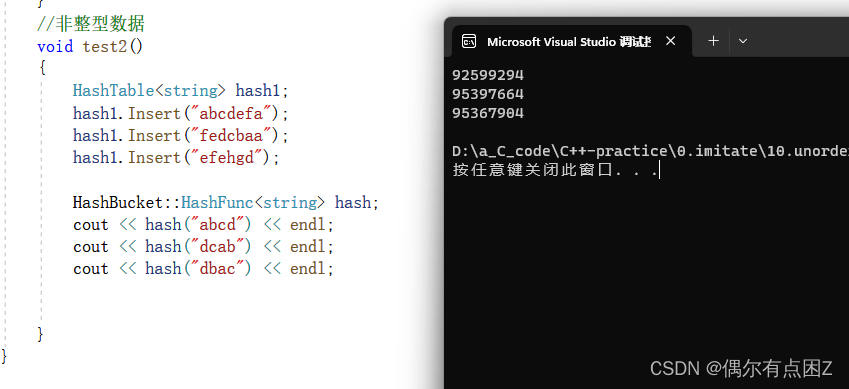
若数据类型是string, "abc" 与"cba"通过相同的哈希函数计算出来的hashi,会相同
~~>引入BKDR哈希, 每次算一个字符的时候, hash *= 31 ~~>让计算出来的hashi尽可能不同
代码:
//模板特化 template<> struct HashFunc<string> { size_t operator()(const string& s) { size_t hash = 0; for (auto ch : s) { hash += ch; hash *= 31; } return hash; } };效果: