主要内容
在本文中,使用Python编程语言和库Keras和OpenCV建立CNN模型,成功地对交通标志分类器进行分类,准确率达96%。开发了一款交通标志识别应用程序,该应用程序具有图片识别和网络摄像头实时识别两种工作方式。
写作目的
近年来,计算机视觉是现代技术发展的一个方向。这个方向的主要任务是对照片或摄像机中的物体进行分类。在通常的问题中,使用基于案例的机器学习方法来解决。本文介绍了利用机器学习算法进行计算机视觉在交通标志识别中的应用。路标是一种外形固定的扁平人造物体。道路标志识别算法应用于两个实际问题。第一个任务是控制自动驾驶汽车。无人驾驶车辆控制系统的一个关键组成部分是物体识别。识别的对象主要是行人、其他车辆、交通灯和路标。第二个使用交通标志识别的任务是基于安装在汽车上的DVRs的数据自动绘制地图。接下来将详细介绍如果搭建能够识别交通标志的CNN网络。
模型训练
数据加载
Python Pandas包帮助我们处理数据集。我们首先将训练和测试数据集获取到Pandas DataFrames中。我们还将这些数据集组合起来,在两个数据集上一起运行某些操作。
count = 0
images = []
classNo = []
myList = os.listdir(path)
print("Total Classes Detected:",len(myList))
noOfClasses=len(myList)
print("Importing Classes.....")
for x in range (0,len(myList)):
myPicList = os.listdir(path+"/"+str(count))
for y in myPicList:
curImg = cv2.imread(path+"/"+str(count)+"/"+y)
curImg = cv2.resize(curImg, (30, 30))
images.append(curImg)
classNo.append(count)
print(count, end =" ")
count +=1
print(" ")
images = np.array(images)
classNo = np.array(classNo)
为了对已实现的系统进行适当的训练和评估,我们将数据集分为3组。数据集分割:20%测试集,20%验证数据集,剩余的数据用作训练数据集
# Split Data
X_train, X_test, y_train, y_test = train_test_split(images, classNo, test_size=testRatio)
X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train, test_size=validationRatio)
该数据集包含34799张图像,由43种类型的路标组成。这些包括基本的道路标志,如限速、停车标志、让路、优先道路、“禁止进入”、“行人”等。
# DISPLAY SOME SAMPLES IMAGES OF ALL THE CLASSES
num_of_samples = []
cols = 5
num_classes = noOfClasses
fig, axs = plt.subplots(nrows=num_classes, ncols=cols, figsize=(5, 300))
fig.tight_layout()
for i in range(cols):
for j,row in data.iterrows():
x_selected = X_train[y_train == j]
axs[j][i].imshow(x_selected[random.randint(0, len(x_selected)- 1), :, :], cmap=plt.get_cmap("gray"))
axs[j][i].axis("off")
if i == 2:
axs[j][i].set_title(str(j)+ "-"+row["Name"])
num_of_samples.append(len(x_selected))
数据分布

数据集中的类之间存在显著的不平衡。有些类的图像少于200张,而其他类的图像超过1000张。这意味着我们的模型可能偏向于过度代表的类别,特别是当它对自己的预测不自信时。为了解决这个问题,我们使用了现有的图像转换技术。
为了更好的分类,数据集中的所有图像都被转换为灰度图像
# PREPROCESSING THE IMAGES
def grayscale(img):
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
return img
def equalize(img):
img =cv2.equalizeHist(img)
return img
def preprocessing(img):
img = grayscale(img) # CONVERT TO GRAYSCALE
img = equalize(img) # STANDARDIZE THE LIGHTING IN AN IMAGE
img = img/255 # TO NORMALIZE VALUES BETWEEN 0 AND 1 INSTEAD OF 0 TO 255
return img
X_train=np.array(list(map(preprocessing,X_train))) # TO IRETATE AND PREPROCESS ALL IMAGES
X_validation=np.array(list(map(preprocessing,X_validation)))
X_test=np.array(list(map(preprocessing,X_test)))
Keras库创建一个神经网络
下面是创建模型结构的代码:
def myModel():
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu', input_shape=X_train.shape[1:]))
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(rate=0.5))
model.add(Dense(43, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
模型训练
下面来到了最关键的模型训练部分:
# TRAIN
model = myModel()
print(model.summary())
history = model.fit(X_train, y_train, batch_size=batch_size_val, epochs=epochs_val, validation_data=(X_validation,y_validation))
模型结果
模型保存:
# TRAIN
model = myModel()
print(model.summary())
history = model.fit(X_train, y_train, batch_size=batch_size_val, epochs=epochs_val, validation_data=(X_validation,y_validation))
上面的代码使用了6个卷积层和1个全连接层。首先,在模型中添加带有32个滤波器的卷积层。接下来,我们添加一个带有64个过滤器的卷积层。在每一层的后面,增加一个窗口大小为2 × 2的最大拉层。还添加了系数为0.25和0.5的Dropout层,以便网络不会再训练。在最后几行中,我们添加了一个稠密的稠密层,该层使用softmax激活函数在43个类中执行分类。
在最后一个epoch结束时,我们得到以下值:loss = 0.0523;准确度= 0.9832;Val_loss = 0.0200;Val_accuracy = 0.9943,这个结果看起来非常好。之后绘制我们的训练过程。
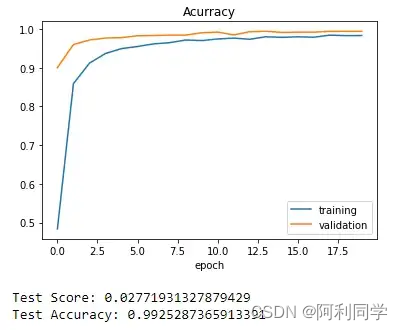
模型测试和模型保存
我们在测试数据集中测试了构建的模型,得到了96%的准确性。
使用内置函数model_name.save(),我们可以保存一个模型以供以后使用。该功能将模型保存在本地的.文件中,这样我们就不必一遍又一遍地重新训练模型而浪费大量的时间。
#testing accuracy on test dataset
from sklearn.metrics import accuracy_score
y_test = pd.read_csv('Test.csv')
labels = y_test["ClassId"].values
imgs = y_test["Path"].values
data=[]
for img in imgs:
image = Image.open(img)
image = image.resize((30,30))
data.append(np.array(image))
X_test=np.array(data)
X_test=np.array(list(map(preprocessing,X_test)))
predict_x=model.predict(X_test)
pred=np.argmax(predict_x,axis=1)
print(accuracy_score(labels, pred))
测试结果


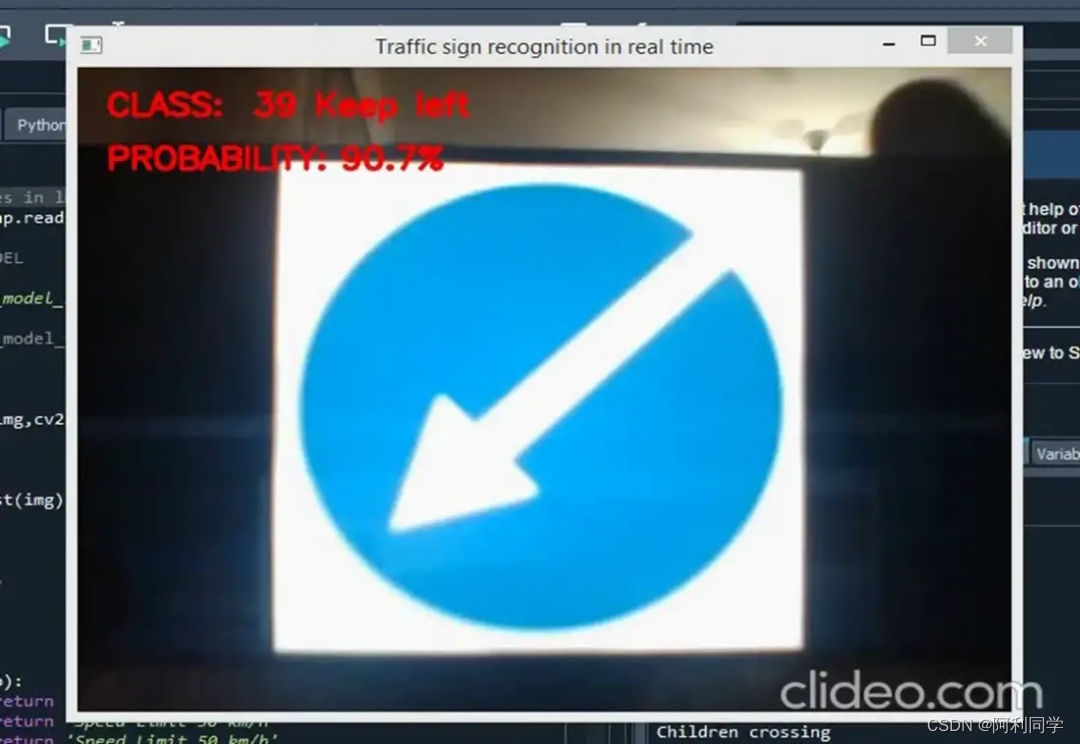
代码获取:
交通标识数据集和代码部分:代码和数据集



![[ web基础知识点 ] 解决端口被占用的问题(关闭连接)(杀死进程)](https://img-blog.csdnimg.cn/2d10bb9864bc47a1ab331c79cc7560d2.png)