版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
大数据系列文章目录
官方网址:https://flink.apache.org/
学习资料:https://flink-learning.org.cn/

目录
- Flink中的重要角⾊
- Flink数据流编程模型
- Libraries支持
- Flink集群搭建
- Local 本地模式(开发测试)
- Standalone - 伪分布环境(开发测试)
- Standalone – 完全分布式集群环境(开发测试)
- Standalone – 完全分布式之高可用HA模式(生产可用)
- yarn集群环境(生产可用)
- Flink on Yarn的运行机制
- Flink on Yarn 的两种使用方式
- 注意
Flink中的重要角⾊
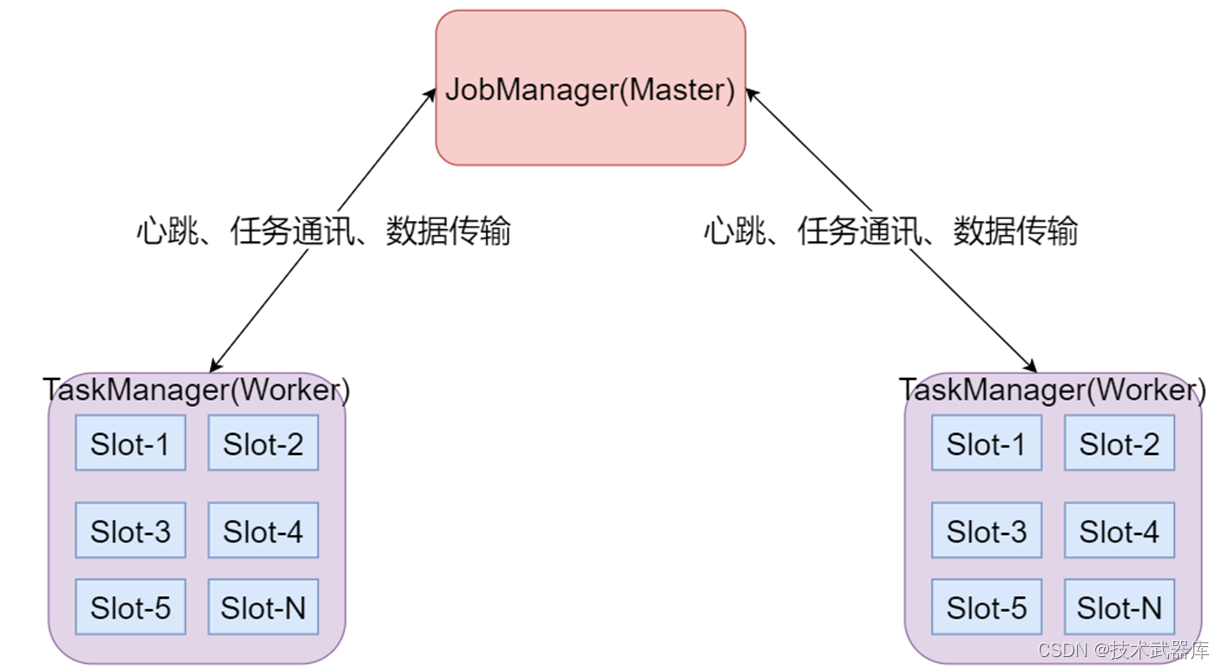
- JobManager处理器
也称之为Master,用于协调分布式执行,它们用来调度task,协调检查点,协调失败时恢复等。Flink运行时至少存在一个master处理器,如果配置高可用模式则会存在多个master处理器,它们其中有一个是leader,而其他的都是standby。 - TaskManager处理器
也称之为Worker,用于执行一个dataflow的task(或者特殊的subtask)、数据缓冲和data stream的交换,Flink运行时至少会存在一个worker处理器。 - Slot 任务执行槽位
物理概念,一个TM(TaskManager)内会划分出多个Slot,1个Slot内最多可以运行1个Task(Subtask)或一组由Task(Subtask)组成的任务链。
多个Slot之间会共享平分当前TM的内存空间,Slot是对一个TM的资源进行固定分配的工具,每个Slot在TM启动后,可以获得固定的资源,比如1个TM是一个JVM进程,如果有6个Slot,那么这6个Slot平分这一个JVM进程的资源,但是因为在同一个进程内,所以线程之间共享TCP连接、内存数据等,效率更高(Slot之间交流方便) - Task
任务,每一个Flink的Job会根据情况(并行度、算子类型)将一个整体的Job划分为多个Task - Subtask
子任务,一个Task可以由多个Subtask组成,一个Task有多少个Subtask取决于这个Task的并行度也就是,每一个Subtask就是当前Task任务并行的一个线程,如,当前Task并行度为8,那么这个Task会有8个Subtask(8个线程并行执行这个Task) - 并行度
并行度就是一个Task可以分成多少个Subtask并行执行的一个参数
这个参数是动态的,可以在任务执行前进行分配,而非Slot分配,TM启动就固定了
一个Task可以获得的最大并行度取决于整个Flink环境的可用Slot数量,也就是如果有8个Slot,那么最大并行度也就是8,设置的再大也没有意义
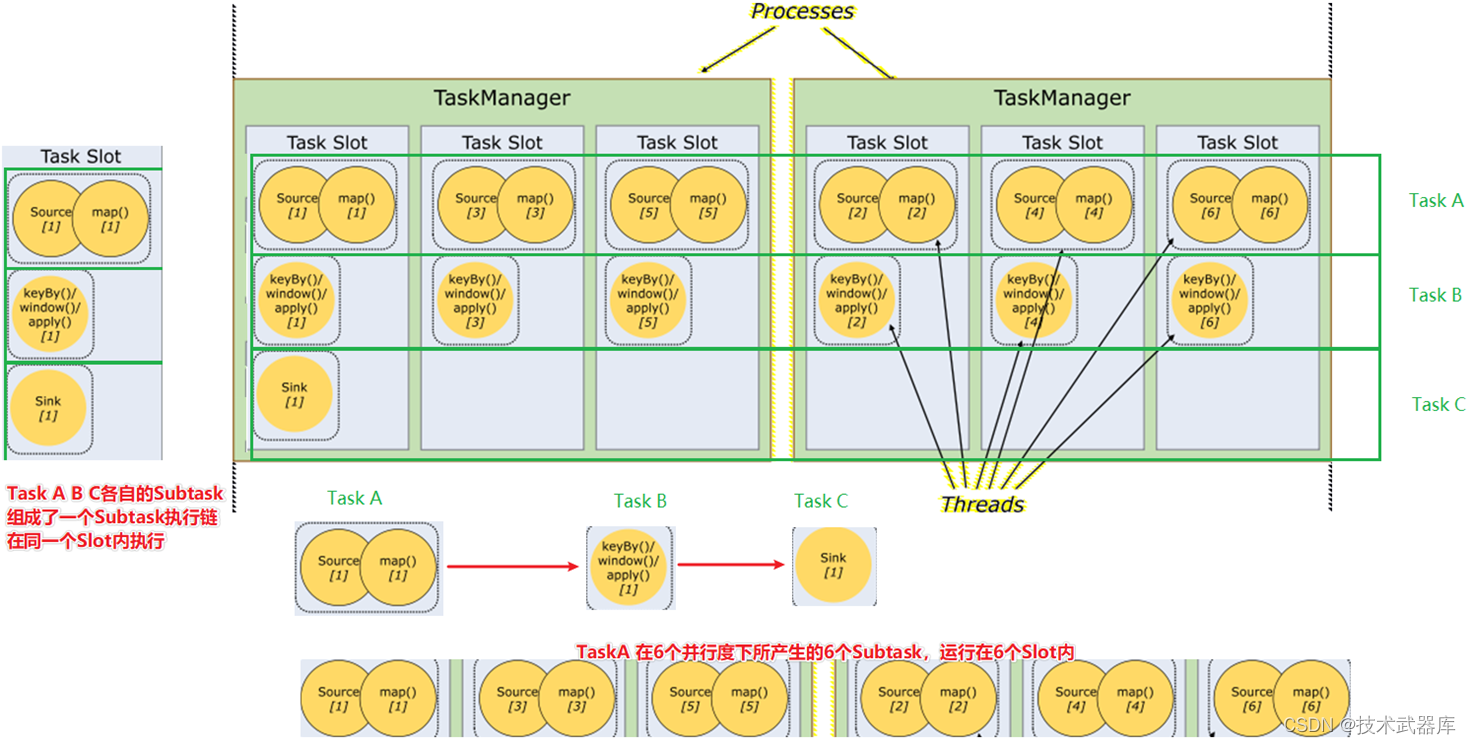
如下图:
- 一个Job分为了3个Task来运行,分别是TaskA TaskB TaskC
- 其中TaskA设置为了6个并行度,也就是TaskA可以有6个Subtask,如图可见,TaskA的6个Subtask各自在一个Slot内执行
- 其中在Slot的时候说过,Slot可以运行由Task(或Subtask)组成的任务链,如图可见,最左边的Slot运行了TaskA TaskB TaskC 3个Task各自的1个Subtask组成的一个Subtask执行链
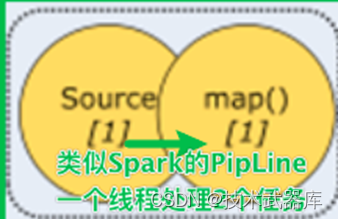
并行度是一个动态的概念,可以在多个地方设置并行度:
- 配置文件默认并行度:conf/flink-conf.yaml的parallelism.default
- 启动Flink任务,动态提交参数:比如:bin/flink run -p 3
- 在代码中设置全局并行度:env.setParallelism(3);
- 针对每个算子进行单独设置:sum(1).setParallelism(3)
优先级:算子 > 代码全局 > 命令行参数 > 配置文件
Flink数据流编程模型
Flink 提供了不同的抽象级别以开发流式或批处理应用。

- 最顶层:SQL/Table API 提供了操作关系表、执行SQL语句分析的API库,供我们方便的开发SQL相关程序
- 中层:流和批处理API层,提供了一系列流和批处理的API和算子供我们对数据进行处理和分析
- 最底层:运行时层,提供了对Flink底层关键技术的操纵,如对Event(消息)、state(状态)、time(时间)、window(窗口)等进行精细化控制的操作API
Libraries支持
- 支持机器学习(FlinkML)
- 支持图分析(Gelly)
- 支持关系数据处理(Table)
- 支持复杂事件处理(CEP)
Flink集群搭建
Flink支持多种安装模式。
- local(本地)——本地模式
- standalone——独立模式,Flink自带集群,开发测试环境使用
- yarn——计算资源统一由Hadoop YARN管理,生产环境测试
下面来说说下各个模式的使用场景及特点
Local 本地模式(开发测试)
本地模式一般在写代码的时候,用以测试Flink代码
原理是通过1个JVM进程,在其内部通过多个线程模拟出各个角色来得到完整的Flink执行环境
可以通过:
- IDEA中启动Flink程序来获得Local模式的执行
- 在Flink中启动:start-scala-shell.sh local来启动一个Local的执行环境
Standalone - 伪分布环境(开发测试)
和Local模式不同的是,Standalone模式中Flink的各个角色都是独立的进程。
架构图
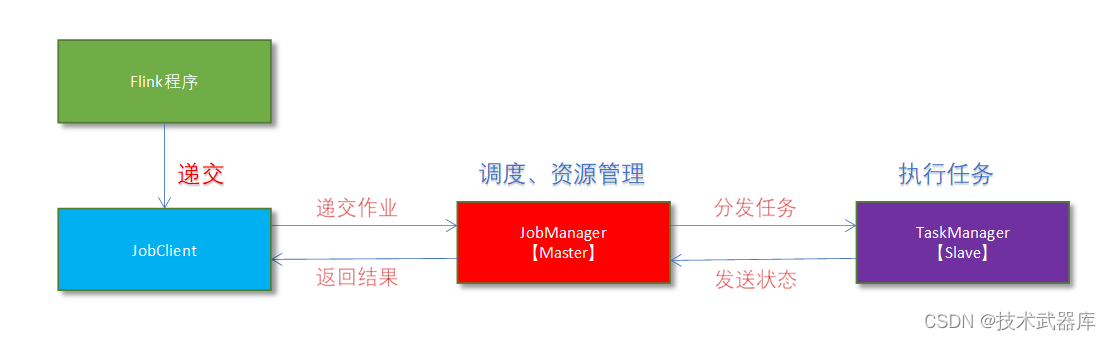
- Flink程序需要提交给JobClient
- JobClient将作业提交给JobManager
- JobManager负责协调资源分配和作业执行。 资源分配完成后,任务将提交给相应的TaskManager
- TaskManager启动一个线程以开始执行。TaskManager会向JobManager报告状态更改。例如开始执行,正在进行或已完成。
- 作业执行完成后,结果将发送回客户端(JobClient)
Standalone – 完全分布式集群环境(开发测试)
架构图
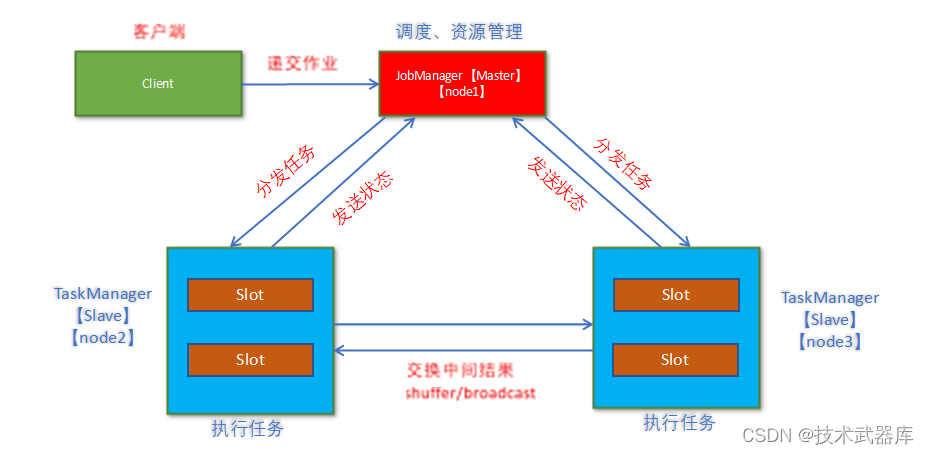
- client客户端提交任务给JobManager
- JobManager负责Flink集群计算资源管理,并分发任务给TaskManager执行
- TaskManager定期向JobManager汇报状态
- flink的TM就是运行在不同节点上的JVM进程(process),这个进程会拥有一定量的资源。比如内存,cpu,网络,磁盘等。flink将进程的内存进行了划分到多个slot中.图中有2个TaskManager,每个TM有2个slot的,每个slot占有1/2的内存。
Standalone – 完全分布式之高可用HA模式(生产可用)
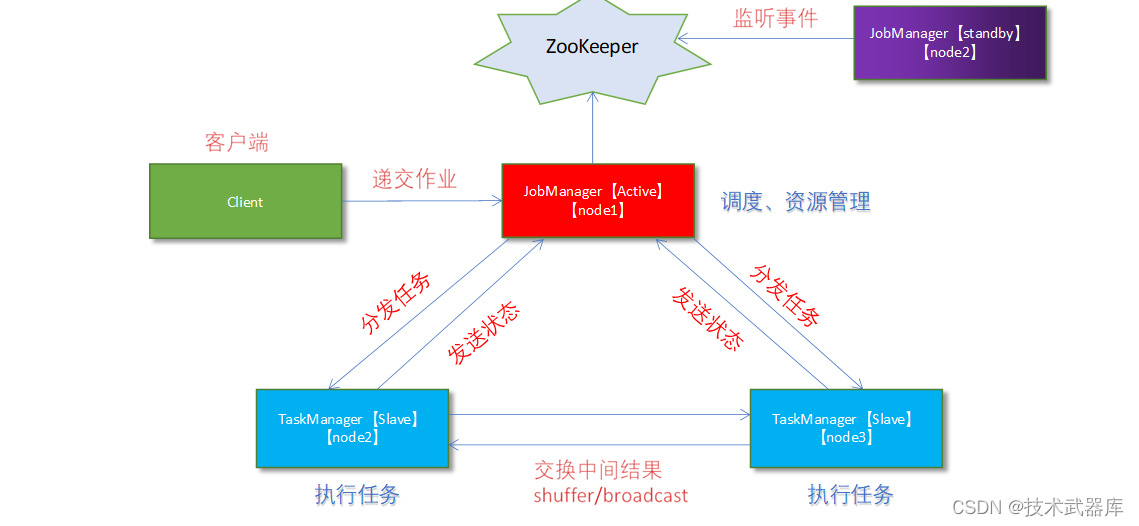
从上述架构图中,可发现JobManager存在单点故障,一旦JobManager出现意外,整个集群无法工作。所以,为了确保集群的高可用,需要搭建Flink的HA。(如果是部署在YARN上,部署YARN的HA),我们这里演示如何搭建Standalone 模式HA。
HA架构图
yarn集群环境(生产可用)
Local模式是通过一个JVM进程中,通过线程模拟出各个Flink角色来得到Flink环境
Standalone模式中,各个角色是独立的进程存在
YARN模式就是,Flink的各个角色,均运行在多个YARN的容器内,其整体上是一个YARN的任务
在一个企业中,为了最大化的利用集群资源,一般都会在一个集群中同时运行多种类型的 Workload。因此 Flink 也支持在 Yarn 上面运行;
flink on yarn的前提是:hdfs、yarn均启动
Flink on Yarn的运行机制
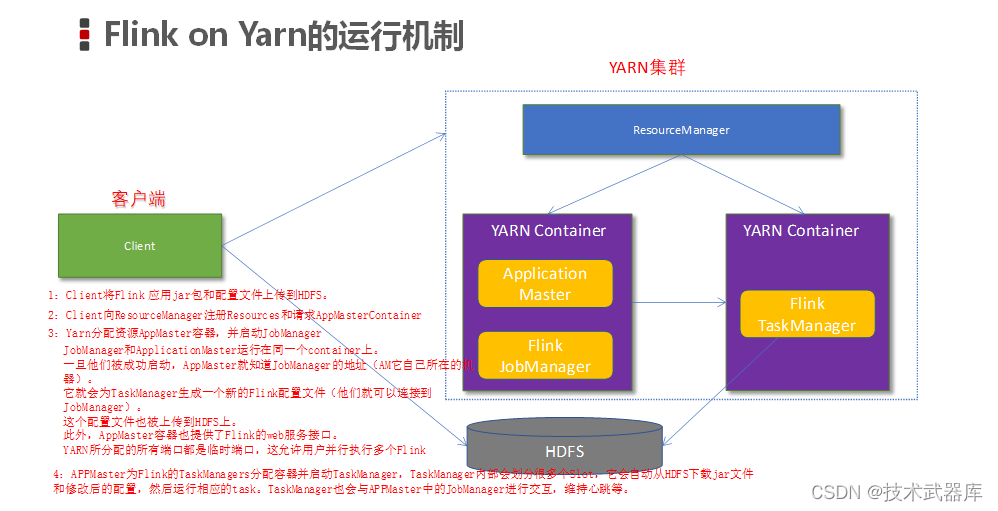
从图中可以看出,Yarn的客户端需要获取hadoop的配置信息,连接Yarn的ResourceManager。所以要有设置有 YARN_CONF_DIR或者HADOOP_CONF_DIR或者HADOOP_CONF_PATH,只要设置了其中一个环境变量,就会被读取。如果读取上述的变量失败了,那么将会选择hadoop_home的环境变量,都区成功将会尝试加载$HADOOP_HOME/etc/hadoop的配置文件。
- 当启动一个Flink Yarn会话时,客户端首先会检查本次请求的资源是否足够。资源足够将会上传包含HDFS配置信息和Flink的jar包到HDFS。
- 随后客户端会向Yarn发起请求,启动applicationMaster,随后NodeManager将会加载有配置信息和jar包,一旦完成,ApplicationMaster(AM)便启动。
- 当JobManager and AM 成功启动时,他们都属于同一个container,从而AM就能检索到JobManager的地址。此时会生成新的Flink配置信息以便TaskManagers能够连接到JobManager。同时,AM也提供Flink的WEB接口。用户可并行执行多个Flink会话。
- 随后,AM将会开始为分发从HDFS中下载的jar以及配置文件的container给TaskMangers.完成后Fink就完全启动并等待接收提交的job。
Flink on Yarn 的两种使用方式
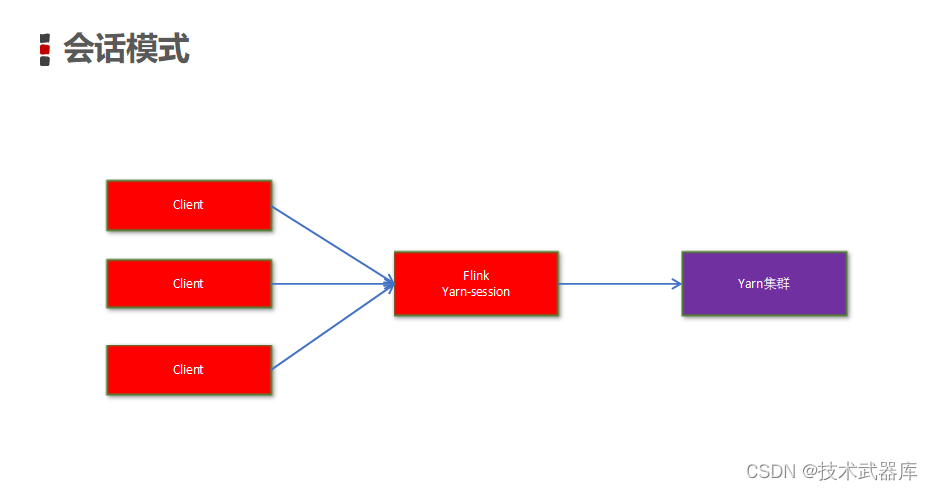
yarn-session提供两种模式
- 会话模式
使用Flink中的yarn-session(yarn客户端),会启动两个必要服务 JobManager 和 TaskManagers客户端通过yarn-session提交作业yarn-session会一直启动,不停地接收客户端提交的作业
有大量的小作业,适合使用这种方式
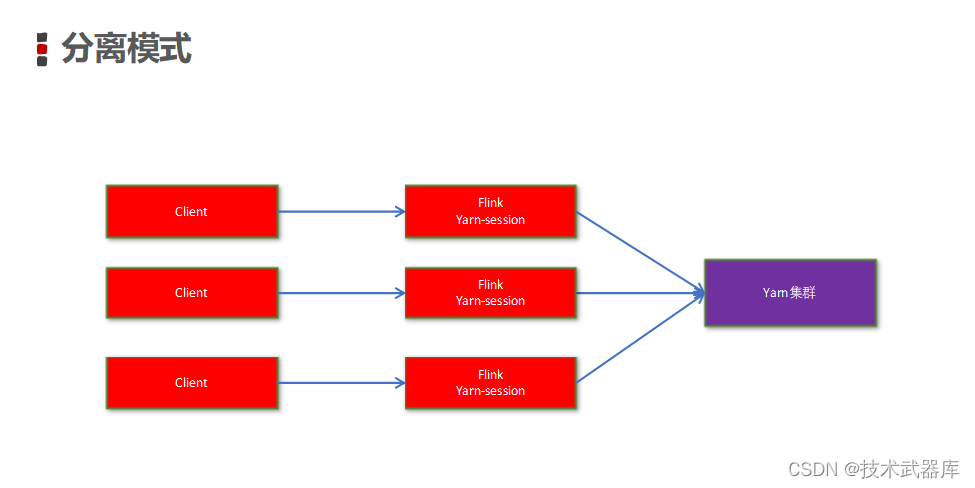
- 分离模式
直接提交任务给YARN
大作业,适合使用这种方式
注意
如果使用的是flink on yarn方式,想切换回standalone模式的话,需要删除文件:【/tmp/.yarn-properties-root】
因为默认查找当前yarn集群中已有的yarn-session信息中的jobmanager
如果是分离模式运行的YARN JOB后,其运行完成会自动删除这个文件
但是会话模式的话,如果是kill掉任务,其不会执行自动删除这个文件的步骤,所以需要我们手动删除这个文件。
![[ web基础知识点 ] 解决端口被占用的问题(关闭连接)(杀死进程)](https://img-blog.csdnimg.cn/2d10bb9864bc47a1ab331c79cc7560d2.png)