Data Source 简介
Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来,Flink 就能够一直计算下去,这个 Data Sources 就是数据的来源地。
Flink 中你可以使用 StreamExecutionEnvironment.addSource(sourceFunction) 来为你的程序添加数据来源。
Flink 已经提供了若干实现好了的 source functions,当然你也可以通过实现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source。
Flink Data Source分类
Flink的数据源可以根据数据的来源和特性进行分类。以下是常见的Flink数据源分类:
集合数据源
集合数据源(Collection Data Source):集合数据源指的是将本地的集合或数组作为输入数据的数据源。在Flink中,可以使用fromCollection、fromElements等方法将Java或Scala中的集合数据转化为数据流进行处理。
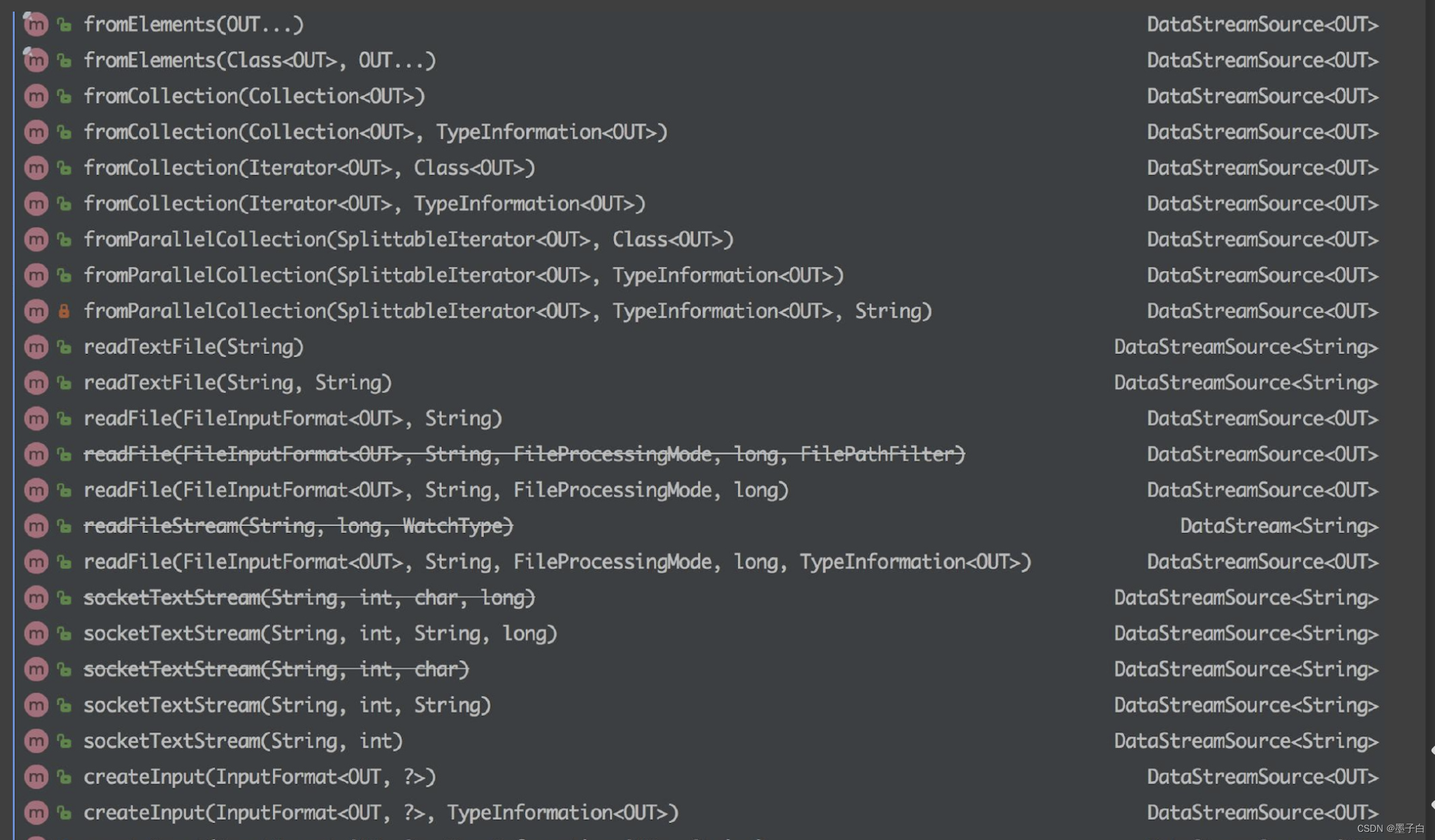
1、fromCollection(Collection) - 从 Java 的 Java.util.Collection 创建数据流。集合中的所有元素类型必须相同。
2、fromCollection(Iterator, Class) - 从一个迭代器中创建数据流。Class 指定了该迭代器返回元素的类型。
3、fromElements(T …) - 从给定的对象序列中创建数据流。所有对象类型必须相同。
4、fromParallelCollection(SplittableIterator, Class) - 从一个迭代器中创建并行数据流。Class 指定了该迭代器返回元素的类型。
5、generateSequence(from, to) - 创建一个生成指定区间范围内的数字序列的并行数据流。
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import java.util.Arrays;
import java.util.List;
public class CollectionDataSourceExample {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 创建一个包含整数的集合
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
// 将集合转化为Flink的DataSet
DataSet<Integer> dataset = env.fromCollection(data);
// 打印数据集中的元素
dataset.print();
}
}
关于使用集合数据源的注意事项:
-
数据规模:集合数据源适用于小规模数据集。确保你的数据集在内存中能够合理存放,不至于导致内存溢出。
-
内存消耗:集合数据源会将所有数据存储在内存中,因此需要谨慎处理大型数据集,避免对内存资源造成过大压力。
-
并行度设置:在集群环境下,可以通过设置并行度来充分利用集群资源,提高作业的执行效率。
-
调试和测试:集合数据源非常适合用于本地调试和测试,可以快速验证处理逻辑并观察输出结果。
使用集合数据源时需要注意这些方面,以确保作业能够稳定运行并获得良好的性能表现。
文件数据源
文件数据源(File Data Source):文件数据源用于从文件系统中读取数据,可以是本地文件系统或分布式文件系统(如HDFS)。Flink提供了readTextFile、readCsvFile等方法来支持常见文件格式的数据读取。
1、readTextFile(path) - 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回。
2、readFile(fileInputFormat, path) - 根据指定的文件输入格式读取文件(一次)。
3、readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和读取路径读取文件。根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
public class FileDataSourceExample {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 从文件创建数据集
String filePath = "path/to/your/file.txt";
DataSet<String> text = env.readTextFile(filePath);
// 打印文件中的内容
text.print();
}
}
关于使用文件数据源的注意事项:
-
文件路径:确保提供的文件路径是正确的,可以是本地文件系统路径,也可以是HDFS路径或其他支持的文件系统路径。
-
文件格式:Flink支持多种文件格式,包括文本文件、CSV文件、Parquet文件等。根据实际情况选择合适的文件格式进行读取。
-
并行度设置:在集群环境下,可以通过设置并行度来充分利用集群资源,提高文件读取的并行处理能力。
-
文件分区:对于大型文件,可以考虑文件分区和并行读取,以加速数据的加载和处理过程。
-
文件读取性能:尽量避免频繁的小文件读取操作,因为这会增加文件系统的负担并降低整体性能。
使用文件数据源时需要注意以上方面,以确保能够有效地读取文件数据,并且提高作业的执行效率。
Socket数据源
Socket数据源(Socket Data Source):Socket数据源允许通过网络套接字接收数据,通常用于测试和演示目的。Flink可以使用socketTextStream方法从TCP socket接收数据流。
socketTextStream(String hostname, int port) - 从 socket 读取。元素可以用分隔符切分。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SocketDataSourceExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从socket创建数据流
String hostname = "localhost";
int port = 9999;
env.socketTextStream(hostname, port)
.print();
// 执行作业
env.execute("Socket Data Source Example");
}
}
关于使用Socket数据源的注意事项:
-
主机和端口:确保指定的主机和端口是正确的,并且能够与数据源通信。
-
网络延迟:由于Socket数据源涉及网络通信,因此可能受到网络延迟的影响。需要考虑网络性能对作业整体性能的影响。
-
并行度设置:可以通过设置并行度来充分利用集群资源,提高数据流处理的并行能力。
-
数据格式:需要确保从Socket接收到的数据能够被正确解析和处理,例如按行读取文本数据等。
-
容错机制:在使用Socket数据源时,需要考虑作业的容错机制,以确保在发生故障或数据丢失时能够正确处理和恢复。
使用Socket数据源时需要注意以上方面,以确保能够有效地接收数据并提高作业的执行效率。
自定义数据源
自定义数据源(Custom Data Source):除了上述内置的数据源外,Flink还支持自定义数据源。用户可以实现自己的SourceFunction接口来定义特定的数据生成逻辑,例如从消息队列、数据库、传感器等实时数据源中读取数据。
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
public class CustomDataSource extends RichParallelSourceFunction<String> {
private boolean running = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (running) {
// 生成数据
String data = generateData();
// 发射数据
ctx.collect(data);
// 控制数据生成频率
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running = false;
}
private String generateData() {
// 实现自定义的数据生成逻辑
return "some data";
}
}
在这个示例中,我们创建了一个名为CustomDataSource的类,它继承自RichParallelSourceFunction并指定了数据类型为String。在run方法中,我们使用一个循环来生成数据并通过collect方法将数据发射出去。在cancel方法中,我们设置了一个标志位来控制数据源的运行状态。
关于使用自定义数据源的注意事项:
-
并行度设置:根据数据源的性质和数据量合理地设置并行度,以充分利用集群资源。
-
数据生成频率:确保数据生成的频率和速度能够适应作业的处理能力,避免数据源产生过快导致作业无法及时处理。
-
容错机制:在自定义数据源中,需要考虑作业的容错机制,例如在发生故障时如何正确处理和恢复。
-
数据格式:确保从自定义数据源产生的数据能够被正确解析和处理,符合作业的输入要求。
-
资源管理:需要确保自定义数据源的资源占用和生命周期管理,避免资源泄露或过度占用资源。
使用自定义数据源时需要考虑以上方面,并确保能够有效地产生数据并提高作业的执行效率。
Apache Kafka数据源
Apache Kafka数据源(Kafka Data Source):作为流数据处理框架,Flink对Kafka提供了良好的集成支持。可以使用addSource方法结合Flink的Kafka Connector来从Kafka主题中读取数据。
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class KafkaDataSourceExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Kafka配置
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "flink-consumer-group");
// 创建Kafka数据流
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("my-topic", new SimpleStringSchema(), properties);
DataStream<String> kafkaDataStream = env.addSource(kafkaConsumer);
kafkaDataStream.print();
// 执行作业
env.execute("Kafka Data Source Example");
}
}
在这个示例中,我们首先创建了一个StreamExecutionEnvironment对象,然后设置Kafka的连接配置,包括bootstrap servers和consumer group id等。接下来,我们创建了一个FlinkKafkaConsumer对象,指定了要消费的topic以及数据的序列化方式,并将其添加到流处理环境中。最后,我们通过调用print方法来打印数据流中的内容,并通过execute方法启动作业并执行。
关于使用Kafka数据源的注意事项:
-
Kafka配置:确保指定的Kafka配置正确,并能够与Kafka集群进行通信。
-
序列化方式:根据实际情况选择合适的数据序列化方式,例如SimpleStringSchema、JSON、Avro等。
-
并行度设置:可以通过设置并行度来充分利用集群资源,提高数据流处理的并行能力。
-
数据消费策略:需要考虑消费数据的策略,如是否从最新/最旧的数据开始消费,以及如何处理消费过程中的偏移量。
-
容错机制:在使用Kafka数据源时,需要考虑作业的容错机制,以确保在发生故障或数据丢失时能够正确处理和恢复。
使用Kafka数据源时需要注意以上方面,以确保能够有效地消费Kafka中的数据并提高作业的执行效率。
Apache Pulsar数据源
Apache Pulsar数据源(Pulsar Data Source):类似于Kafka,Flink也集成了对Pulsar的支持,可以直接从Pulsar主题中读取数据。
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.pulsar.FlinkPulsarSource;
import org.apache.pulsar.client.api.Schema;
import org.apache.pulsar.client.api.PulsarClientException;
public class PulsarDataSourceExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
String serviceUrl = "pulsar://localhost:6650";
String topic = "my-topic";
FlinkPulsarSource<String> pulsarSource = new FlinkPulsarSource<>(
serviceUrl,
topic,
Schema.STRING
);
DataStream<String> pulsarDataStream = env.addSource(pulsarSource);
pulsarDataStream.print();
env.execute("Pulsar Data Source Example");
}
}
在这个示例中,我们首先创建了一个StreamExecutionEnvironment对象,然后指定了Pulsar的连接信息和要消费的topic。接下来,我们创建了一个FlinkPulsarSource对象,并指定了Pulsar的serviceUrl、topic以及数据的Schema,并将其添加到流处理环境中。最后,我们通过调用print方法来打印数据流中的内容,并通过execute方法启动作业并执行。
关于使用Pulsar数据源的注意事项:
-
Pulsar连接配置:确保指定的Pulsar连接信息正确,并能够与Pulsar集群进行通信。
-
Schema设置:根据实际情况选择合适的数据Schema,例如STRING、JSON、AVRO等。
-
并行度设置:可以通过设置并行度来充分利用集群资源,提高数据流处理的并行能力。
-
数据消费策略:需要考虑消费数据的策略,如是否从最新/最旧的数据开始消费,以及如何处理消费过程中的偏移量。
-
容错机制:在使用Pulsar数据源时,需要考虑作业的容错机制,以确保在发生故障或数据丢失时能够正确处理和恢复。
使用Pulsar数据源时需要注意以上方面,以确保能够有效地消费Pulsar中的数据并提高作业的执行效率。
这些不同类型的数据源为Flink应用程序提供了灵活的数据接入方式,使得Flink可以轻松地处理不同来源和格式的数据。根据具体的业务需求和场景特点,可以选择合适的数据源类型来构建流处理和批处理应用程序。
更多消息资讯,请访问昂焱数据(https://www.ayshuju.com)