大模型是通用人工智能的底座,但大模型训练对算力平台的依赖非常大。大模型算力平台是指支撑大模型训练和推理部署的算力基础设施,包括业界最新的加速卡、高速互联网络、高性能分布式存储系统、液冷系统和高效易用的大模型研发工具和框架。在算力平台的部署过程中,大模型研发机构常常需要面对一系列的问题:大模型算力平台是什么样的?如何快速构建大模型算力平台?如何确保算力平台稳定可靠?如何提升部署效率?如何提升算力平台的性能……这些问题能否顺利解决,直接关系到大模型研发和应用落地的速度。
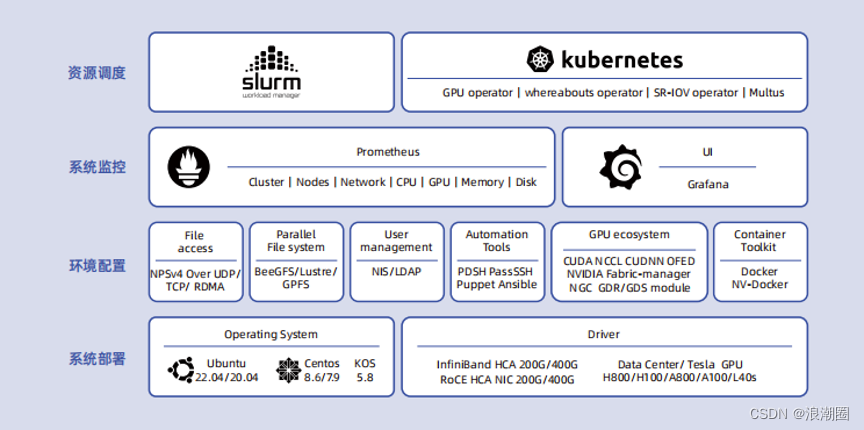
为了帮助用户加速大模型的技术创新与应用落地,浪潮信息发布了大模型智算软件栈OGAI(Open GenAI Infra)。OGAI由5层架构组成,从L0到L4分别对应于基础设施层的智算中心OS产品、系统环境层的PODsys产品、调度平台层的AIStation产品、模型工具层的YLink产品和多模纳管层的MModel产品。其中L1层PODsys是一个为客户提供智算集群系统环境部署方案的开源项目,具备基础设施环境安装、环境部署、用户管理、系统监控和资源调度等能力。用户只需执行两条简单的命令,即可完成大模型算力平台的部署,将大模型算力平台部署效率提升11倍,帮助用户顺利迈出大模型研发的第一步。(下载地址:The PODsys Project)
大模型算力平台部署难题亟待求解
大模型参数量和训练数据复杂性快速增加,对AI算力平台的建设提出了新的要求,即需要从数据中心规模化算力部署的角度,统筹考虑大模型分布式训练对计算、网络和存储的需求特点,并集成平台软件、结合应用实践,充分关注数据传输、任务调度、并行优化、资源利用率等,设计和构建高性能、高速互联、存算平衡的可扩展集群系统,以满足AI大模型的训练需求。
强大的大模型算力平台不仅需要高性能的CPU、GPU、存储、网络等硬件设备,还需要考虑不同硬件和软件之间的兼容性和版本选择,确保驱动和工具的适配性和稳定性。当算力平台的规模从十几台服务器扩展到几百台,平台部署难度会呈指数级上升。
首先,算力平台部署需要的相关驱动程序、软件包往往高达数十个,正确安装、部署并优化这些驱动程序与软件,需要专业的运维工程师和大量调试时间,严重影响部署效率。其次,为了确保算力平台的高性能和稳定运行,需要验证不同硬件环境下的软件适配,优化BIOS、操作系统、底层驱动、文件系统和网络等多项指标,找到最优的选择,这一工作同样费时费力。此外,算力平台的资源状态处于时刻的变动中,如果不进行合理的资源调度与管理,很容易影响平台的资源利用率。
PODsys让大模型算力平台部署“易如反掌”
PODsys专注于大模型算力平台部署场景,提供包括基础设施环境安装、环境部署、用户管理、系统监控和资源调度在内的完整工具链,旨在打造一个开源、高效、兼容、易用的智算集群系统方案。
PODsys整合了大模型算力平台部署所需的数十个驱动、软件等安装包以及对应的依赖和兼容关系,并提供了一系列的简化部署的脚本工具。使用这些工具只需要简单2个步骤,PODsys即可帮助用户快速部署大模型算力平台。
步骤1:使用docker run命令快速启动PODsys系统。
PODsys系统集成了大模型算力平台部署所需的操作系统、GPU驱动、网卡驱动、通信加速库等数十个驱动程序、软件和安装包,并提供了一系列脚本工具来简化部署,让用户可以快速安装、配置和更新集群环境。PODsys大量选用了业界广泛使用的主流开源系统、工具、框架和软件,来保障整个部署方案的开放性、兼容性和稳定性。
步骤2:使用install_client命令快速部署大模型算力平台的并行软件环境。
PODsys将单机部署方式改成集群部署方式,可将部署效率提升11倍以上。在管理节点运行一句简单的命令(install_client.sh),即可完成大模型算力平台的环境配置,集成了高速文件系统接口、自动化运维工具、NVDIA CUDA编程框架、NCCL高性能通信库,支持NGC 加速平台等功能。并能实现多用户、多租户管理集群。
PODsys提供了全面的系统监控和管理,帮助用户实时监控集群的状态和性能指标。通过可视化的界面,用户可以查看集群资源的使用情况、作业的执行情况和性能瓶颈,从而及时调整集群配置和优化作业性能,来保证算力平台的高性能和稳定运行。

此外,PODsys具备高效的资源调度和作业管理功能,可以根据用户的需求自动调度和管理作业,确保集群的资源利用率和作业的执行效率。
伴随着大模型的快速应用,算力平台的鲁棒性、易用性、部署效率成为用户关注的首要问题。针对商业用户,PODsys还提供专业的算力平台性能调优服务。
总之,PODsys提供了一套完整的工具链,将大模型平台部署变得像系统安装一样简单,让用户省时、省力地部署大模型算力平台,助力大模型创新走好第一步。