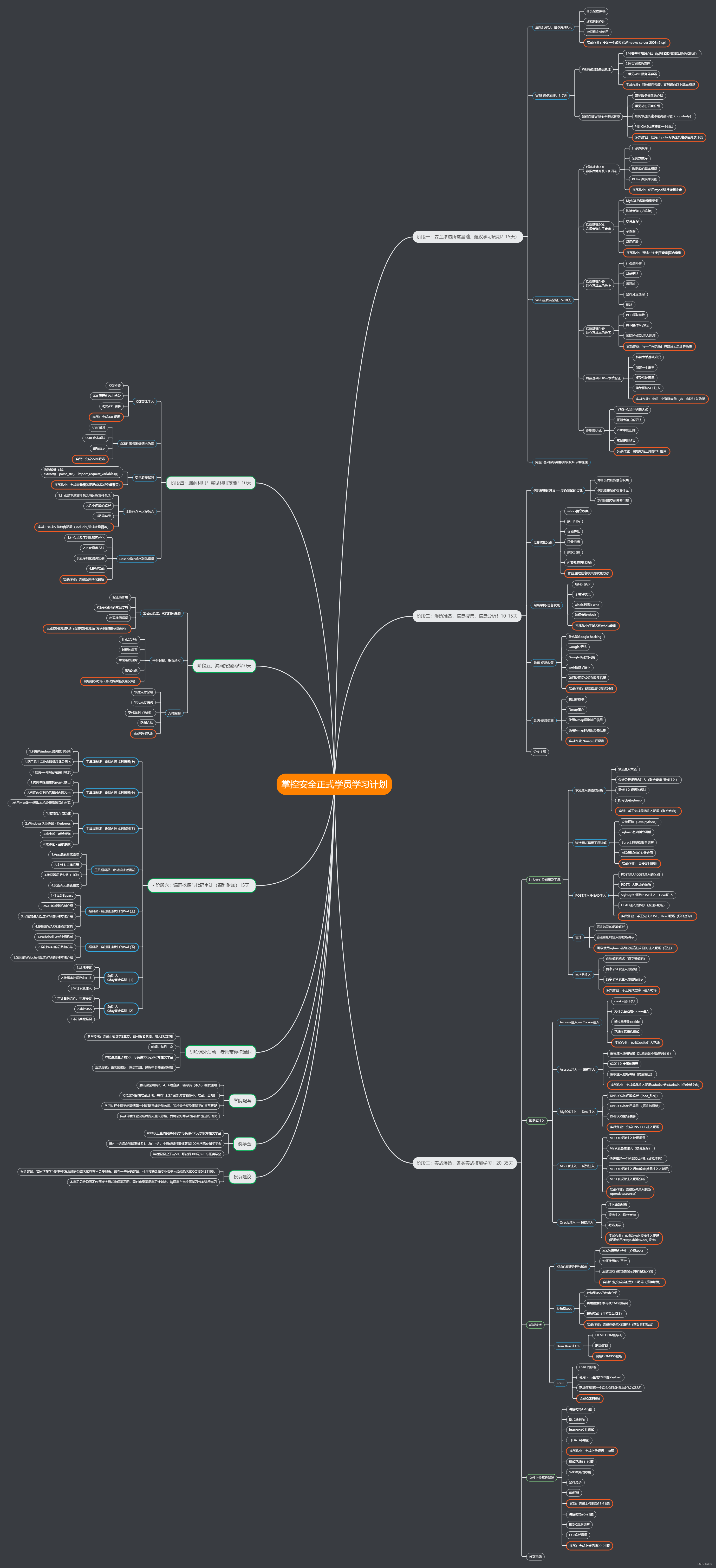
3.4 Unicode数据
啤酒是不分国界的饮料,与之相称的是,啤酒的名字中也使用了很多非ASCII字符。下面的 Awk 程序 charfreq 统计了输入中每个不同的 Unicode 代码点(code point)的出现次数。(代码点通常是一个字符,但有些字符是由多个代码点组成的)
# charfreq - count frequency of characters in input
awk '
{ n = split($0, ch, "")
for (i = 1; i <= n; i++)
tab[ch[i]]++
}
END {
for (i in tab)
print i "\t" tab[i]
} ' $* | sort -k2 -nr用空字符串作为域分隔符来拆分每行,把每个字符都存成数组 ch 的一个元素,然后用 tab 来计算这些字符数量;最后以倒序显示累加的数量。
这程序在啤酒数据(见3.2节)上跑得不快,在2015年的 MacBook Air上就花了250秒钟。下面这个版本快了两倍多,正好不超过105秒:
# charfreq2 - alternate version of charfreq
awk '
{ n = length($0)
for (i = 1; i <= n; i++)
tab[substr($0, i, 1)]++
}
END {
for (i in tab)
print i "\t" tab[i]
} ' $* | sort -k2 -nr这个版本没有使用 split,而是用 substr 每次提取一个字符。函数 substr(s, m, n) 返回字符串 s 从位置 m 开始(m从1开始)且长度为 n 的子串,若 m 和 n 表示的范围超过了字符串的范围,则返回空字符串。如果不指定 n,则子串一直延续到 s 的末尾。完整的细节见参考手册 A.2.1节。
Gawk,即Awk的GNU版本,再次遥遥领先:第一个版本跑了72秒,第二个版本跑了42秒。
其他语言怎么样?为了比较,我们写了一个简单的Python版本的 charfreq:
# charfreq - count frequency of characters in input
freq = {}
with open('../beer/reviews.csv', encoding='utf-8') as f:
for ch in f.read():
if ch == '\n':
continue
if ch in freq:
freq[ch] += 1
else:
freq[ch] = 1
for ch in freq:
print(ch, freq[ch])Python 版本花了45秒,和Gawk差不多,不过代价是还得写文件处理的代码。(本书作者不是Pythonistas,所以这个程序肯定是还能改进的)
除去每行末尾的换行符之外,啤酒评级文件中有 195 个不同的字符。出现最频繁的是空格,其次是可打印字符:
10586176
, 19094985
e 12308925
r 8311408
4 7269630
a 7014111
5 6993858
...还有不少来自欧洲语言的字符,比如德语的变音符号,以及一定量的日语和汉语字符:
ル 1
サ 1
ケ 1
ア 1山 1
葉 1
黑 229
最后一个字符是黑(hei, black),出现在一种被简单命名为“Black”(对应汉字为 黑)的烈性 Imperial stout 酒名中。
Mikkeller ApS,2, American Double / Imperial Stout, Black (黑), 17.5
3.5 基本图表
可视化是探索性数据分析的重要组成部分,而幸运的是有不少非常不错的绘制库,使制作图表变得相当轻松。对 Python 来说更是如此,它有 Matplotlib 和 Seaborn 等包,不过在 Unix 和 macOS 上用 Gnuplot 进行快速绘图也不错。当然 Excel 和其他电子表格程序也能创建不错的图表。这里我们只会对绘制数据给出最少量的建议,读者们应该自己做实验(来找到自己喜欢的方式)。
在ABV和评分之间存在关联吗?打分人更偏爱高酒精度啤酒吗?可以用散点图来得到一个快速的印象,不过绘制150万个点有困难。我们用Awk取出 0.1%的样本(大概1500个点),并进行绘制:
$ awk -F'\t' 'NR%1000 == 500 {print $2, $5}' rev.tsv >temp
$ gnuplot
plot 'temp'
$结果见下图 3-1。看来在评分和ABV之间最多存在弱关联。

图3-1
Tukey的可视化箱线图(boxplot)能显示数据集的中位数、四分位数和其他属性。箱线图有时称为箱须图,因为从箱体两段延伸出的两条“晶须”(whiskers)的范围,通常是下四分位数和上四分位数之间范围的1.5倍。晶须之外的点是异常值。
下面这个简短的Python程序生成前面所述样本数据的箱线图。 temp 文件是前面的程序生成的,每行都包含了评分和ABV,中间用空格隔开,且不带表头。
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('temp', sep=' ', header=None)
plt.boxplot(df[0])
plt.show()得到图3-2所示的箱线图,显示评分的中位数是4,而一半的评分介于3.5和4.5这两个四分位数之间。晶须最多延伸到四分位数间距的 1.5 倍,另外在 1.5 和 1.0 处存在异常值。

图 3-2
也许通过与大众市场的美国啤酒相比,可以看看任意特定的啤酒或酒厂的表现如何。
$ awk -F'\t' '/Budweiser/ { s += $2; n++ }
END {print s/n, n }' rev.tsv
3.15159 3958
$ awk -F'\t' '/Coors/ { s += $2; n++ }
END {print s/n, n }' rev.tsv
3.1044 9291
$ awk -F'\t' '/Hill Farmstead/ { s += $2; n++ }
END {print s/n, n }' rev.tsv
4.29486 1555这表明在大规模生产的啤酒与小规模生产的精酿啤酒之间,存在明显的评分差距。
3.6 总结
探索性数据分析的目的是为了在对结果做出假设之前,去了解数据,寻找模式和异常。如 John Tukey所说:
一些数据,结合上对答案的渴望,并不能确保从给定的数据体中提取出合理的答案。
宁可要近似正确,而不要完全错误。
正确问题的近似答案(通常是模糊的)比错误问题的确切答案(总是能做成精确的)要好得多。
作为探索性数据分析的核心工具,Awk是非常值得学习的,因为你能用它来快速地统计、汇总、查找。当然Awk不能做所有的事,但和其他工具,特别是电子表格和绘图库,结合起来,就能非常好地对数据集所包含的内容有一个快速的了解。
其中的很大一部分在于识别异常和怪异。正如很久以前贝尔实验室的一位同事所说:“三分之一的数据是坏的”。尽管他可能为了达到修辞效果而有所夸大,但我们已经看到了很多这样的例子:数据集中很大一部分真是古怪且不可信的。如果你构建了一套用于查看数据的工具和技术,就能更容易找到需要清理(至少是谨慎对待)的地方。
(第三章完)