sleep 30 #这是睡眠时间
awk的精确筛选:
$n{><==}:对比数值
$n-"字符串"代表第n个字段包含某个字符串
$n!-"字符串"代表第n个字段不包含某个字符串
$n=="字符串" 代表第n个字段为某个字符串
$n!="字符串"代表第n个字段不为某个字符串
$NF:最后一个字段
实验:

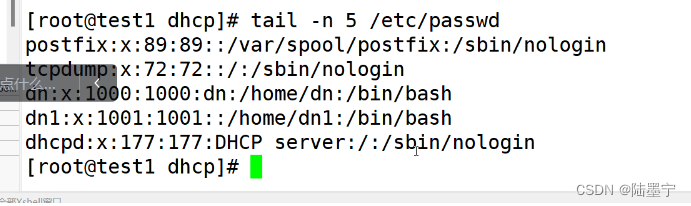
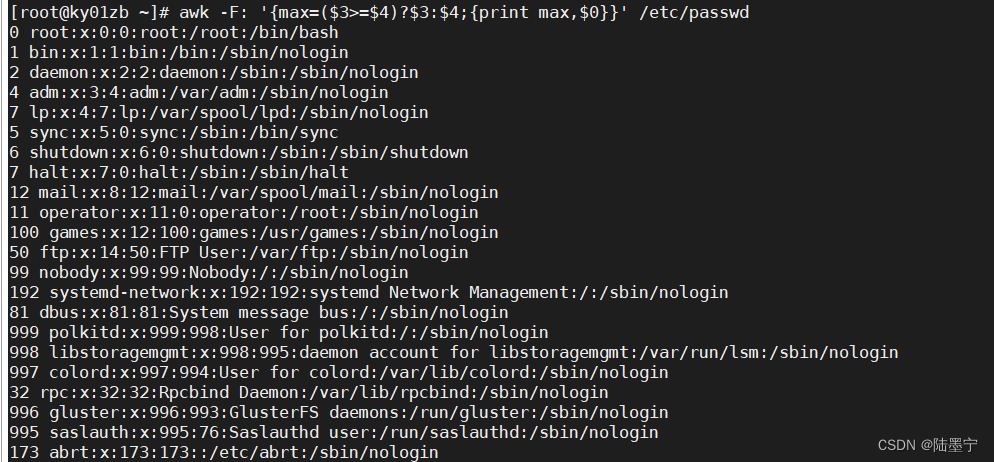
如图所示:如果第七列不包含nologin打印第五列
答案:

实验:
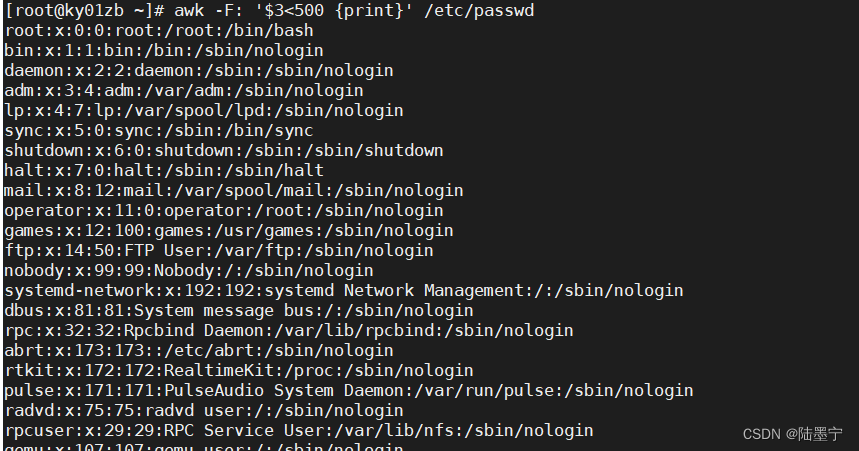
如图所示:如果第五列是home而且最后一列是bin/bash,条件满足就答应第一列与最后一列
答案:

实验:如果最后一列非/bin/bash,就全部打印

实验:大于小于等于举例:


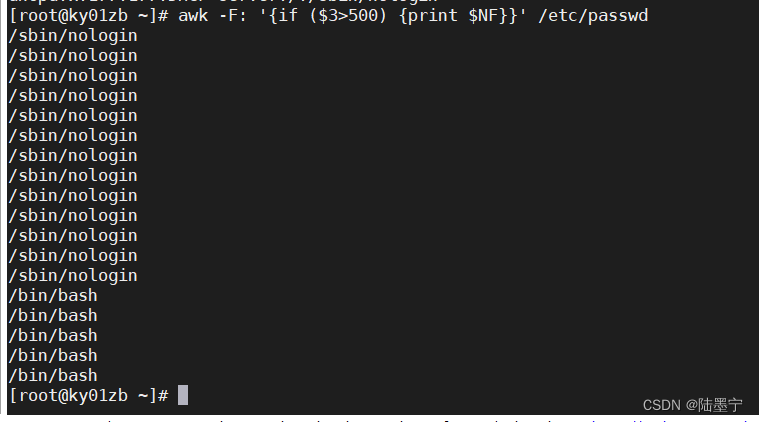
实验:加上if语句打印
awk的三元表达式:ps:这是一个面试题
-V赋值变量:

fs=:
-v
fs赋值给FS
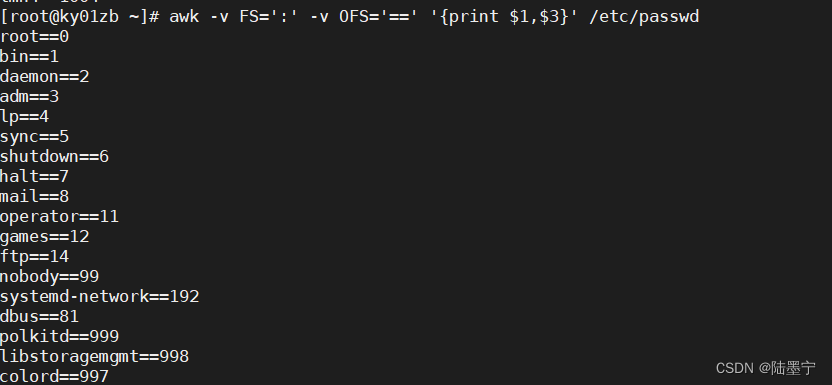
实验:awk -F: '{print $1,$3}' 中间的:改成==。两种方式

数组的定义:ps:这只能按照下标输出,无法直接全部输出

因此用for循环实现全部打印

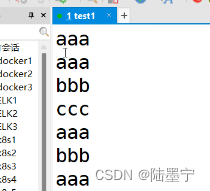
面试题:实验:用数组遍历进行去重以下文本内容


以下是awk必须掌握的知识点
awk的按行取列
awk -F:'{print $3}'
精确筛选
-v往参
数组去重
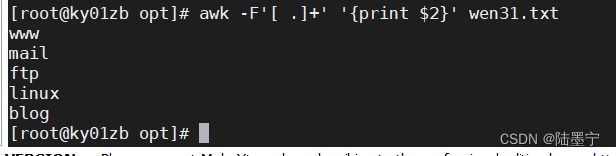
面试题:实验:将以下文本内容取第一列的单词内容,排查数字空格和.
面试题:实验:在 /var/log/messages 文件中的内容,取前两行,然后打印第一列和第四列

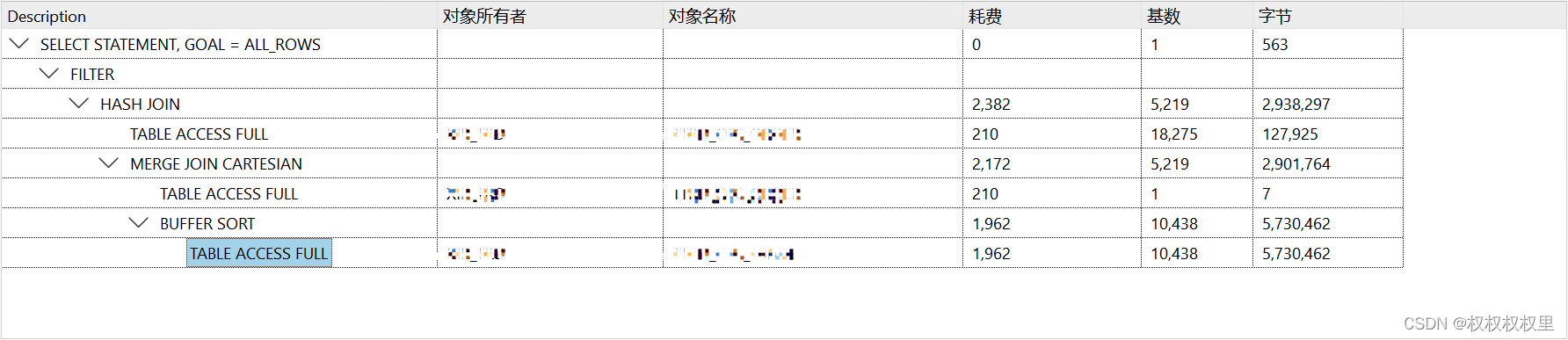
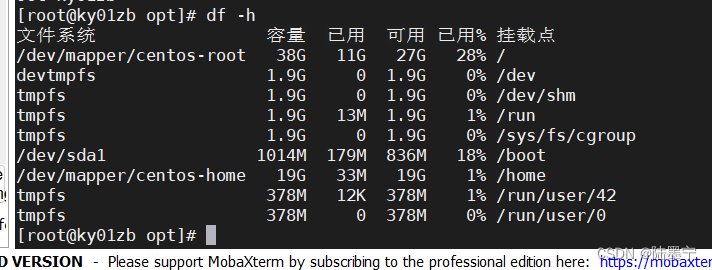
实验:df-h 统计磁盘的可用容量,且排除tmpfs,其他可用容量总和
答案:

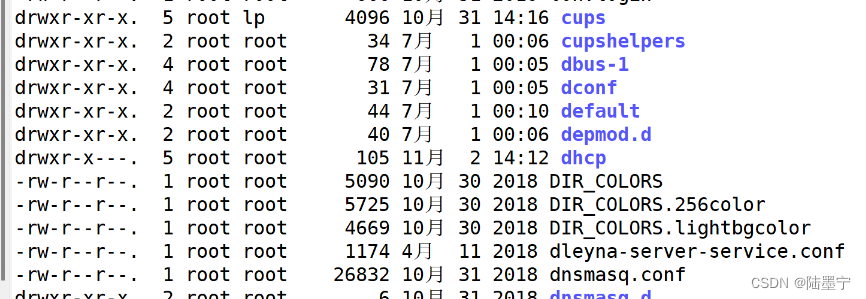
实验:ls -l /etc/取文件总和多少M
答案:

实验:top -b -n 1

监控CUP内存,如果CPU使用超过80%,则告警
free -h
监控内存,使用量超过总量的80%告警
df -h
监控硬盘,监控根目录,已用超快90%告警
然后三个脚本写成函数库,用定时任务调用,每天早上8点20分执行一次,
实例引用 题目一:简单的日志分割 awk '{print $1, $7, $9}' /var/log/messages
在这个命令中,我们使用单引号将awk命令的操作包含起来。 $1、$7和$9是awk的内置变量,分别表示每行日志文件中的第1、第7和第9个字段。 通过使用print命令,我们将这些字段分别打印出来,以空格分隔。 最后,我们指定日志文件的路径/var/log/messages,awk会自动对文件中的每行进行处理并输出结果。
只分割前两行内容的第一个和第四个字段 awk 'NR<=2{print $1, $4}' /var/log/messages
题目二:取小数点几位和取整数 result=$(awk 'BEGIN{printf "%.2f", 2.3312.542}') #取小数点2位 result=$(awk 'BEGIN{printf "%.F", 2.3312.542}') # 不取小数点,只取整数
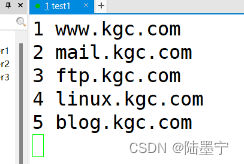
题目三:提取host.txt主机名后再放回host.txt文件 1 www.kgc.com 2 mail.kgc.com 3 ftp.kgc.com 4 linux.kgc.com 5 blog.kgc.com cat file.txt | awk -F '[ .]+' '{print $2}' >> host.txt
题目四:统计磁盘总共使用容量: df | tail -n +2 | grep -v tmpfs | awk '{sum+=$4} END{print "磁盘可用容量:"sum/1024/1024"G"}'
题目五:统计/etc下文件总大小 ls -l /etc | awk '/^-/{sum+=$5} END{print "文件总大小:"sum/1024"M"}'
题目六:CPU使用率 top -b -n 1 -b 告诉 top 以批处理模式运行,没有交互界面,这意味着它将输出结果到控制台一次,然后退出。 -n 1 指定 top 在退出之前应运行的迭代次数。在这种情况下,它只运行一次。 us 表示用户空间占用 CPU 百分比,sy 表示内核空间占用 CPU 百分比 [root@localhost network-scripts]# sum=$(top -b -n 1 | grep -w st |awk '{print $2+$4}') [root@localhost network-scripts]# echo $sum 3.1
题目七:统计内存: 监控硬盘: [root@localhost home]# df -h | grep -w centos-root | awk '{print $5}' | tr -d "%"
16% memory_used=$(free -m | grep "Mem:" |awk '{print $3 }')




![洛谷P2196 [NOIP1996 提高组] 挖地雷【动态规划思路分析】看完直接举一反三!](https://img-blog.csdnimg.cn/174bc9f250054bc39bcc6c0efe61dcde.png)

![[答疑]大老二和德州扑克-属性值没变,状态怎么变了](https://img-blog.csdnimg.cn/img_convert/88736e3ea903c37826e06f9a6c863d31.jpeg)