1. 数据目录
在Ubuntu下,MySQL的数据目录为/var/lib/mysql
1.1 数据库在文件系统中的表示
(1)创建数据库时,会在数据目录下创建一个与数据库名同名的子目录。(除了information_schema这个系统数据外)
(2)db.opt文件存储数据库的一些属性
MySQL 8.0 之后不再提供
1.2 表在文件系统中的表示
(1)表结构定义。表名.frm文件
(2)表数据
1.2.1 InnoDB
(1)系统表空间。只有一份,默认为数据目录下的ibdata1文件
(2)独立表空间;表名.ibd文件。
MySQL 8.0将ibd文件和frm文件合并,只有一个ibd文件,并且不再提供db.opt文件,其中的字符集、比较规则信息也放在ibd文件中。
存储到系统表空间中的表转移到独立表空间
ALTER TABLE 表名 TABLESPACE innodb_system
存储在独立表空间中的表转移到系统表空间
ALTER TABLE 表名 TABLESPACE innodb_file_per_table
1.2.2 MyISAM
表名.MYD、表名.MYI分别表示表的数据文件和索引文件
2. InnoDB的表空间
2.1 页面通用部分
每个页都包含了File Header和File Trailer
(1)FIL_PAGE_OFFSET表空间下描述页号,4字节,因此一个表空间最多 64TB,即 (2^32)*16KB
(2)FIL_PAGE_PREV 和 FIL_PAGE_NEXT 上/下页的页号,主要是数据页(INDEX 类型)使用。
(3)FIL_PAGE_TYPE据此区分页的类型
2.2 独立表空间结构
表空间划分为一个一个的区(每个 1 MB),每 256 个区组成一个组。
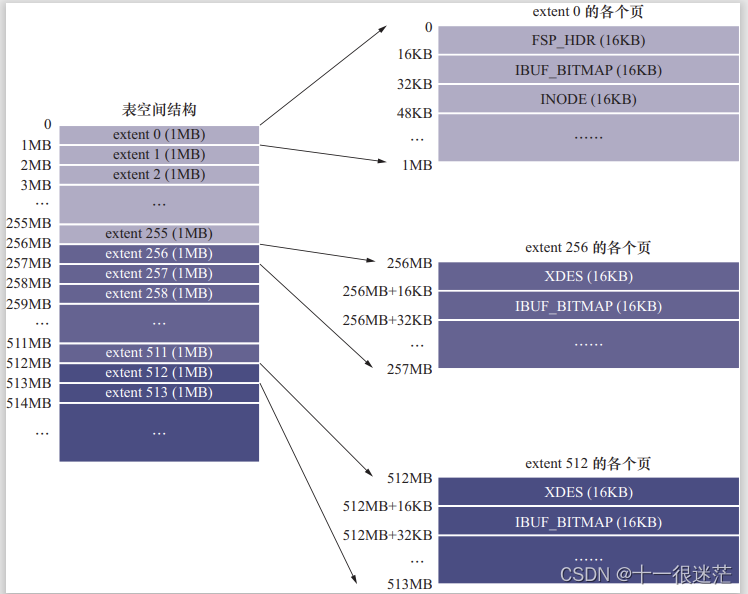
(1)第一个组最开始的 3 个页面的类型是固定的。
- FSP_HDR:整个表空间中只有一个 FSP_HDR 类型的页面;登记表空间的一些整体属性和本组索引的区。
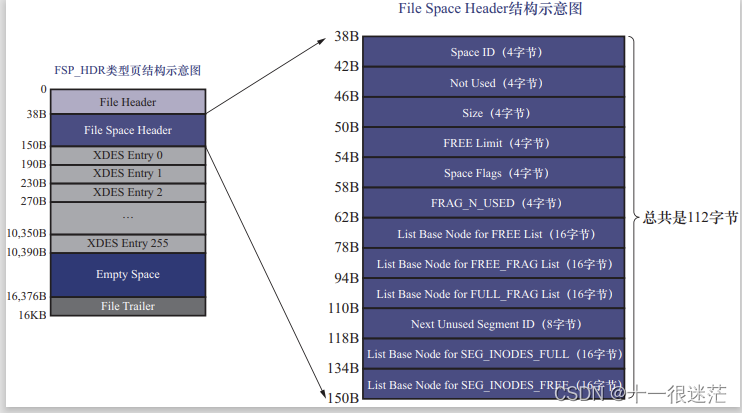
| File Space Header | 共 112 字节 | |
|---|---|---|
| Space ID | 4 | 表空间 ID |
| Not Used | 4 | 未使用,可忽略 |
| Size | 4 | 拥有的页面数 |
| FREE Limit | 4 | 尚未被初始化的最小页号,该字段表示页号之后的区都未被使用,且没有加入到 FREE 链表中 |
| Space Flags | 4 | 页面大小,是否为共享/临时表空间等属性 |
| FRAG_N_USED | 4 | FREE_FRAG 链表中已使用的页面数量 |
| List Base Node for FREE list | 16 | FREE 链表基节点 |
| List Base Node for FREE_FRAG list | 16 | FREE_FRAG 链表基节点 |
| List Base Node for FULL_FRAG list | 16 | FULL_FRAG 链表基节点 |
| Next Unused Segment ID | 8 | 当前表空间中下一个未使用的 Segment ID,递增 |
| List Base Node for SEG_INODES_FULL list | 16 | SEG_INODES_FULL 链表基节点 |
| List Base Node for SEG_INODES_FREE list | 16 | SEG_INODES_FREE 链表基节点 |
- INODE:存储 INODE Entry 数据结构
每个段对应的 INODE Entry 结构会存储到 INODE 页中。段特别多的情况下。会有多个 INODE 页,会组成链表。
SEG_INODES_FULL :在该链表中的 INODE 页没有空闲空间
SEG_INODES_FREE :有空闲空间
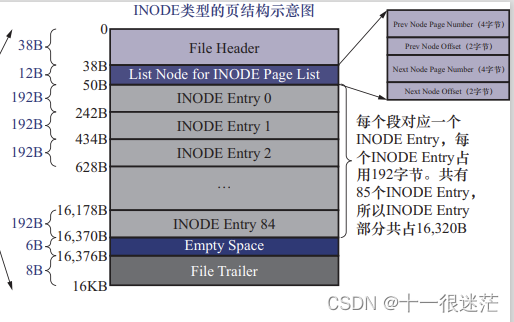
如果新建一个段时,SEG_INODES_FREE 链表为空,需要从表空间的 FREE_FRAG链表申请一个页面,并把页面的类型修改为 INODE。
(2)其余各组最开始的 2 个页面的类型是固定的。
XDES:登记本组 256 个区的属性。
2.2.1 段
一些零散页面以及一些完整区的集合
(1)为什么使用区?
一个区是连续的 64 页。在表中数据量很大时,为某个索引分配空间按照区为单位,这样就尽量让页面链表中相邻的页的物理位置也相邻。
(2)对 B+ 树的叶子节点和非叶子节点进行了区分。会生成一个叶子节点段和一个非叶子节点段(一个索引会生成两个段),段是以区为单位申请存储空间的
(3)以区为单位申请空间,对小表会造成浪费存储空间;提出了碎片区
碎片区只需于表空间,不属于任何段。
碎片区中的页可以用于不同的目的,可以属于不同段。
在刚开始向表中插入数据时,段是从碎片区的以页为单位分配存储空间的,当某个段已经占用了 32 个碎片区页面后,就会以区为单位来分配。(原先占用的碎片区的页面不会被复制到新申请的区中)
2.2.2 区
区可分为 4 种类型,这也是 4 种状态(State)
- FREE;空闲的区
- FREE_FRAG;有剩余空间页面的碎片区
- FULL_FRAG;没有剩余空间页面的碎片区
- FSEG;附属于某个段的区
前三种是独立的,直属于表空间
(1)为了方便管理区,设计每个区都对应一个 XDES Entry 的结构(40 字节)。
- Segment ID (8 字节);段的 ID,前提是分配给了某个段。
- List Node (12 字节);
指向 前/后一个 XDES Entry 的指针 (Page Number + Offset); - State(4 字节);
- Page State Bitmap(16 字节);每个区有 64 页,每页用 2 位表示,表明对应的页是否是空闲。
(2)之所以 XDES Entry 要组成链表,是因为可以把状态分别为 FREE、FREE_FRAG、FULL_FRAG 的区对应的 XDES Entry 结构连接成一个 FREE、FREE_FRAG、FULL_FRAG 链表。
段中数据较少时,首先查看表空间中是否有状态为 FREE_FRAG 的区,如果有,则从该区中取下一个零散页把数据插进去;否则到表空间中申请一个状态为 FREE 的区,把该区的状态变为 FREE_FRAG ,然后从该区中取出一个零散页把数据插入进去。
该区中没有空闲页面后,将其状态变成 FULL_FRAG。
(3)段中数据已经占满了 32 个零散的页后,申请完整的区。
根据段号来区分各个段,对每个段都建立 3 个链表
- FREE 链表;所有页面都是空闲的区
- NOT_FULL 链表;仍有空闲页面的区
- FULL 链表;已经没有空闲页面的区
(4)链表基节点
每个链表对应一个 List Base Node 结构(16字节)
- List Length;表明链表一共有多少个节点;
- First Node Page;该链表的头结点在表空间中的位置;
- Last Node Page;该链表的尾结点在表空间中的位置;
2.2.3 段的结构
为每个段定义一个 INODE Entry 结构。
- Segment ID;对应的段的编号;
- NOT_FULL_N_USED;在 NOT_FULL 链表中已经使用了多少个页面;
- 3 个 List Base Node;分别为 FREE、NOT_FULL 、FULL 链表基节点
- Magic Number
- Fragment Array Entry;共有 32 个,每个 Fragment Array Entry 结构对应一个零散的页面,这个结构一共 4 字节,表示一个零散页面的页号。
2.2.4 Segment Header
(1)索引会对应两个段,如何知道某个索引和某个段之间的对应关系?
在数据页的 Page Header 中,属性 PAGE_BTR_SEG_LEAF 和 PAGE_BTR_SEG_TOP 仅在 B+ 树的根页中定义,分别记录了叶子/非叶节点段的头部信息(Segment Header,其中包含表空间ID,页面号,偏移量);
2.3 系统表空间
整个 MySQL 进程只有一个系统表空间,其表空间 ID 为 0。

| 页号 | 页面类型 | 描述 |
|---|---|---|
| 3 | SYS | 存储 Change Buffer 的头部信息 |
| 4 | INDEX | 存储 Change Buffer 的根页面 |
| 5 | TRX_SYS | 事务相关信息 |
| 6 | SYS | 第一个回滚段信息 |
| 7 | SYS | 数据字典头部信息 |
extent 1 和 extent 2 这两个区,是作为 Doublewrite Buffer;
2.3.1 数据字典
由系统表来记录一些元数据(某个表中有多少列,该表有哪些索引等信息)。这些系统表被称为数据字典,都是以 B+ 树的形式保存在系统表空间的某些页面中。
以下四个为基本系统表
(1)SYS_TABLES;整个 InnoDB 存储引擎中所有表的信息
| 列名 | 描述 |
|---|---|
| NAME | 表名 |
| ID(TABLE_ID) | 表的 ID(每个表具有唯一的 ID) |
| N_COLS | 表中列的个数 |
| TYPE | 类型,记录文件格式、行格式、压缩等信息 |
| MIX_ID | 忽略 |
| MIX_LEN | 额外属性 |
| CLUSTER_ID | 忽略 |
| SPACE | 所属表空间的 ID |
以 NAME 列为主键的聚簇索引;
以 ID 列建立的二级索引;
(2)SYS_COLUMNS;所有列的信息。
| 列名 | 描述 |
|---|---|
| TABLE_ID | 该列所属表的 ID |
| POS | 表明是第几列 |
| NAME | 列名 |
| MTYPE | 列的数据类型(INT、CHAR等) |
| PRTYPE | 精确数据类型,修饰主数据类型的,例如是否允许 NULL 等 |
| LEN | 该列最多占用的字节数 |
| PREC | 精度,默认为 0 |
以 (TABLE_ID ,POS)列为主键的聚簇索引
(3)SYS_INDEXES;所有索引的信息。
| 列名 | 描述 |
|---|---|
| TABLE_ID | 该索引所属表的 ID |
| ID(INDEX_ID) | 索引 ID |
| NAME | 索引名 |
| N_FIELDS | 索引包含几列 |
| TYPE | 索引类型,例如聚簇索引、唯一二级索引、更改缓冲区的索引、全文索引、普通二级索引 |
| SPACE | 索引根页面所在的表空间 ID |
| PAGE_NO | 索引根页面所在的页面号 |
| MERGE_THRESHOLD | 指明 B+ 树发生合并时的比例(页面满发生分裂,数据太少发生合并) |
以 (TABLE_ID ,ID)列为主键的聚簇索引
(4)SYS_FIELDS;索引对应列的信息。
| 列名 | 描述 |
|---|---|
| INDEX_ID | 该列所属索引的 ID |
| POS | 该列在索引列中是第几列 |
| COL_NAME | 对应列的名称 |
以 (INDEX_ID,POS)列为主键的聚簇索引
(5)由页号为 7 的页面,记录了 Data Dictionary Header。记录上述 4 个表的聚簇索引和二级索引对应的 B+ 树根页面的位置。
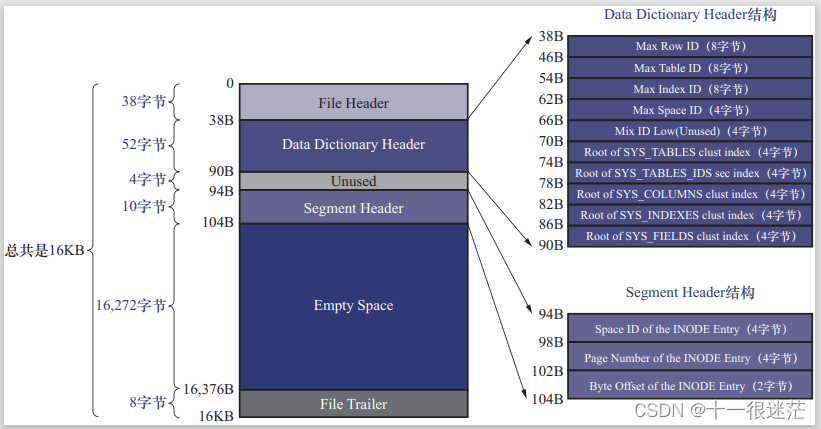
Max Row ID:隐藏主键的 ID 号,自增并且是全局共享的,即拥有 row_id 列的不同表之间的这个值也都是不同的。
Max Table ID:自增的表 ID 值。
之后记录了这些索引根页面的页号,对应上述 4 个表中的索引。
把数据字典信息当成一个段来分配存储空间,该段只有一个碎片页,即页号为 7 的页。
(6)information_schema 系统数据表
在存储引擎启动时读取这些 SYS 开头的系统表,然后填充到以 INNODB_SYS 开头的表中。
参考书籍
《MySQL 是怎样运行的》