该部分以“猫狗识别模型”为例,学习如何直接通过平台提供的开发环境调用GPU资源
一.学习准备
获取官方代码文件:https://platform.virtaicloud.com/gemini_web/workspace/space/n9tte8i2aspd/project/list
二.创建项目
1)进入趋动云用户工作台,在当前空间处选择注册时系统自动生成的空间(其他空间无免费算力);
2)填写项目名称及项目描述;
3)添加镜像:选择含 TensorFlow 2.x 框架的官方镜像即可;
4)添加绑定数据集:选择公开数据集,DogsVsCats。
5)其余无需填写,点击右下角 创建 ,系统弹出 上传代码 的提示,单击 暂不上传,项目创建成功。如下图示:

三.准备代码
单击上传文件图标将获取的 DogsVsCats.py 文件上传至项目中。

四.初始化开发环境
-
单击右上角的 运行代码,进入 初始化开发环境 页
-
填写开发环境的初始化配置


五.调试代码
1)单击 开发环境实例 页右侧的 JupyterLab 工具
2)默认进入 /gemini/ 目录下,在右侧目录树中单击 code 文件夹,进入到 /gemini/code/ 目录下。


3)单击顶部 网页终端 按钮,进入终端界面。
4)在终端界面执行如下命令测试模型的识别能力。
python $GEMINI_RUN/DogsVsCats.py --num_epochs 5 --data_dir $GEMINI_DATA_IN1/DogsVsCats/ --train_dir $GEMINI_DATA_OUT
系统返回一系列信息,直到返回 test accuracy 信息,如下所示,表明该模型测试结束,其识别猫狗的能力为 0.500000,即几乎无识别能力。
5)单击 JupyterLab,切换回 JupyterLab 工具,分析 /gemini/code/ 路径下的模型代码。
经排查,发现代码中没有打乱数据集进行训练,导致模型没有训练成功。
6) 修改模型代码并保存。
-
双击
/gemini/code/路径下的DogsVsCats.py,开始编辑该文件。 -
删除该文件中第 44 行的注释符号 #。
- 按 “Crtl + S” 键,保存该文件。
-

7) 单击 网页终端 按钮,进入终端界面再次执行上述 4) 中的命令进行识别能力的测试。
系统返回的测试结果如下所示,显然已经能达到 80% 能识别出猫狗了。
2022-02-17 05:38:55.734254: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
test accuracy:0.845800
此时您可提交离线训练,对模型进行大规模的训练以达到更精准的识别能力,详情参见下一步。
六.提交离线训练
当您已经完成本次调优,可参考如下步骤保存代码并使用当前版本代码提交训练任务。
- 单击调试页面右上角的 提交训练任务。

2.在弹框中选择镜像和代码版本。
- 选择代码版本:单击 新建代码版本,并在右边框中填写代码版本名。
- 选择镜像:选择 直接使用当前工作镜像。


3.单击 确定,进入 提交任务 页面。
4.参考如下说明配置任务基本信息。


5.单击 确定。
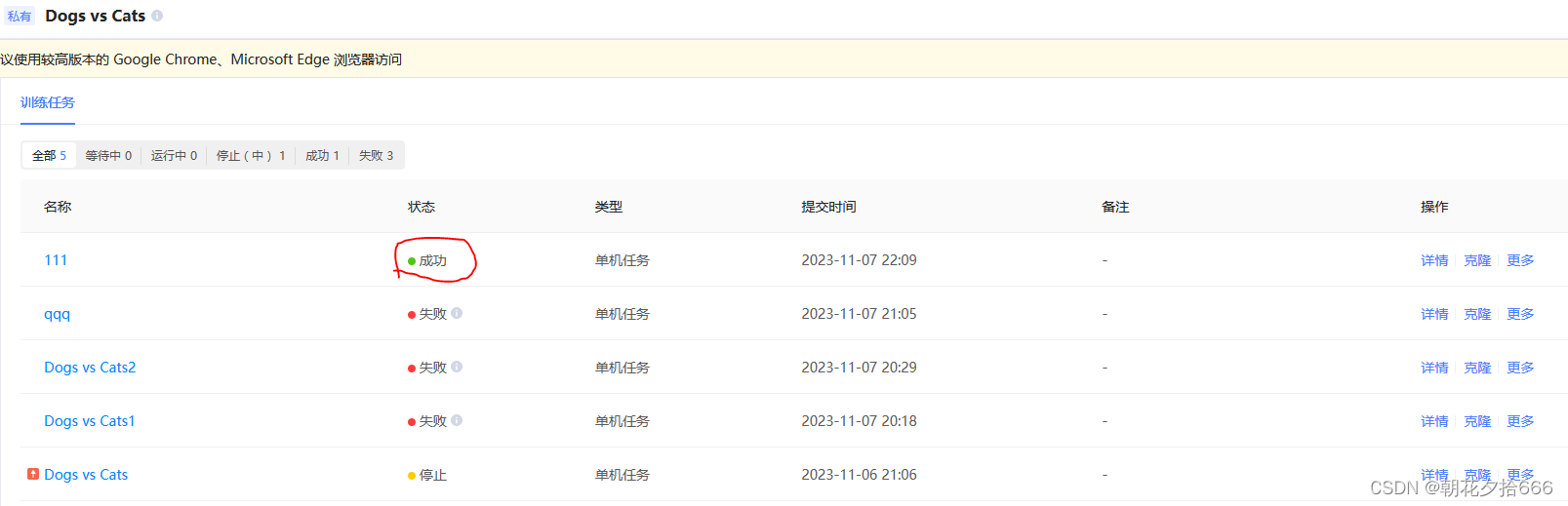
返回 训练任务 页面,在训练任务列表中查看该任务的状态,该任务大约 5 分钟即可训练完成。
- 任务状态显示为 成功 则表示训练任务成功结束。
- 任务状态为 失败,可将鼠标悬置于 失败 字样上,查看失败原因,详情可参考 FAQ。
后续操作
模型在经历了大规模数据的训练后,将具备相对精准的识别猫狗的能力,此时您可下载模型并将模型部署到应用中。
平台为您提供了结果集存储与下载的功能,您在代码中设置的输出,都将被存储在结果集中。
您可将结果集中的模型文件导出为模型。
1.在左侧导航栏中选择 结果,默认进入 任务结果 页面。
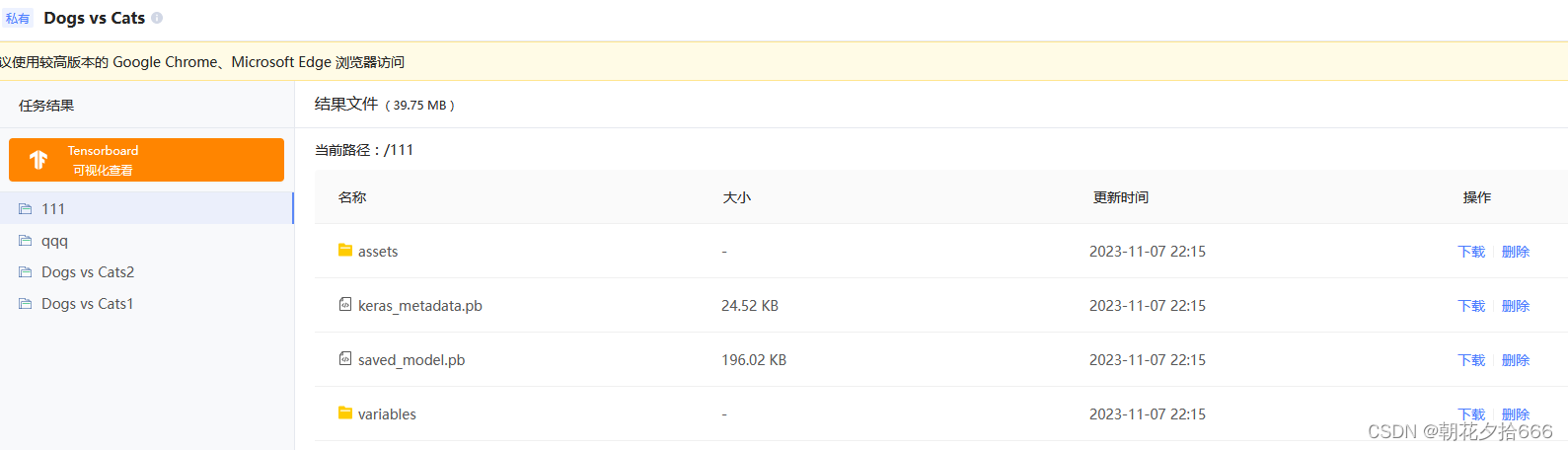 2.单击右上角的 导出模型 按钮,进入 导出模型 页面。
2.单击右上角的 导出模型 按钮,进入 导出模型 页面。


3.单击 创建,生成模型。
生成的模型将保存在平台中,您可将其公开性设置为 公开,并将其分享给其他成员使用或进一步完善模型。