参考资料:NeurIPS 2021 | ViTAE: vision transformer中的归纳偏置探索 - 知乎
paper地址:https://openreview.net/pdf?id=_RnHyIeu5Y5
论文标题:ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias
code:
GitHub - Annbless/ViTAE: The official pytorch implementation of ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias
一、问题提出
Transformers have shown great potential in various computer vision tasks owing to their strong capability in modeling long-range dependency using the self-attention mechanism.
Transformers 由于具有较强的利用自注意机制建模长期依赖关系的能力,在各种计算机视觉任务中显示出巨大的潜力。
Unlike vision transformers, Convolution Neural Networks (CNNs) naturally equip with the intrinsic IBs of scale-invariance and locality and still serve as prevalent backbones in vision tasks.
与视觉转换器不同,卷积神经网络(cnn)具有固有的尺度不变性和局部性,仍然是视觉任务中普遍存在的backbones
Can we improve vision transformers by leveraging the good properties
of CNNs?
能否利用CNN的良好特性来改进vision transformers?
尺度不变性,多尺度特征来有效地表示不同尺度下的对象。有两种方法:
To construct multi-scale feature representation, the classical idea is using image pyramid, where features are hand-crafted or learned from a pyramid of images at different resolutions respectively. 为了构建多尺度特征表示,经典思想是使用图像金字塔,其中特征分别是手工制作或从不同分辨率的图像金字塔中学习。
In addition to the above inter-layer fusion way, another way is to aggregate multi-scale
context by using multiple convolutions with different receptive fields within a single layer, i.e. intra-layer fusion. 除了上述的层间融合方式外,另一种方法是在一层内使用不同感受野的多次卷积来聚合多尺度上下文,即层内融合
Either inter-layer fusion or intra-layer fusion empower CNNs an intrinsic IB in modeling scale-invariance. This paper introduces such an IB to vision transformers by following the intra-layer fusion idea and utilizing multiple convolutions with different dilation rates in the reduction cells to encode multi-scale context into each visual token.
无论是层间融合还是层内融合,都使cnn在建模尺度不变性时具有内在的IB。本文通过遵循层内融合思想,利用不同膨胀率的多卷积,将多尺度上下文编码到每个visual token中,将这种IB引入vision transformers。
二、Methodology
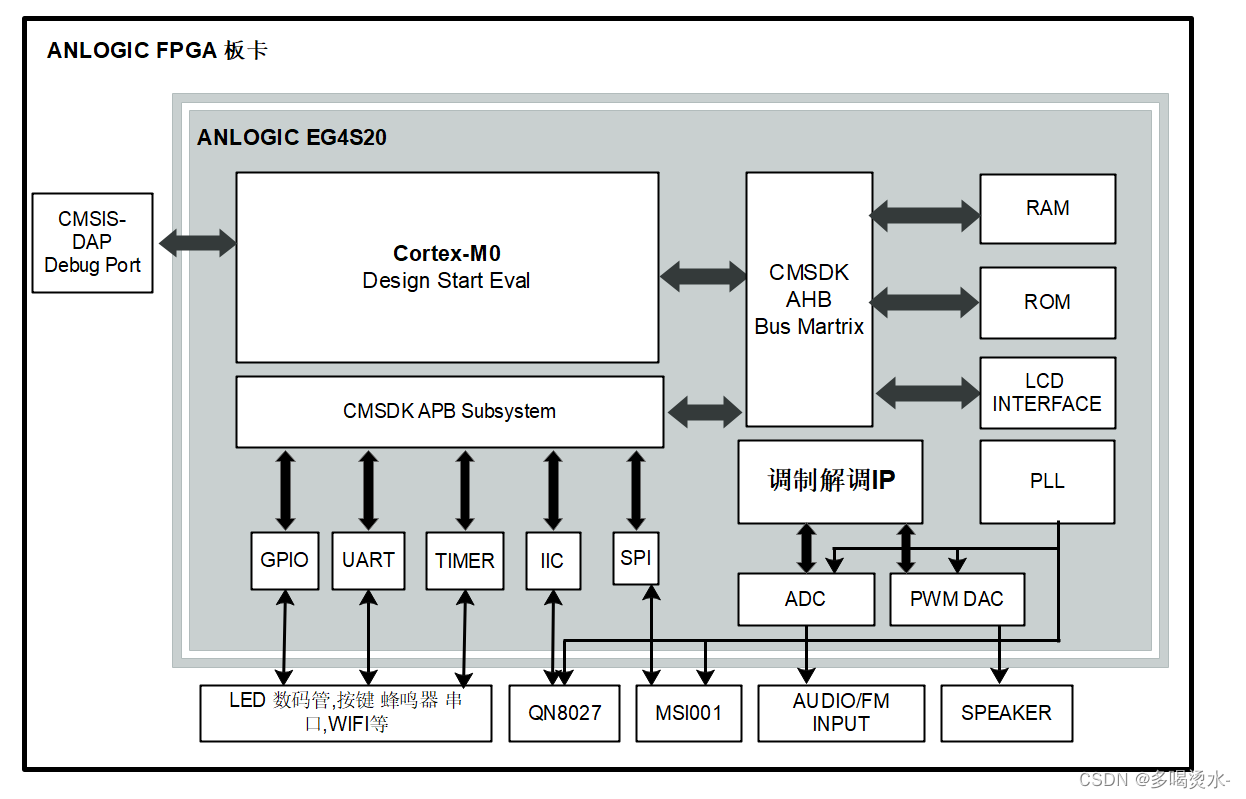
1、Overview architecture of ViTAE
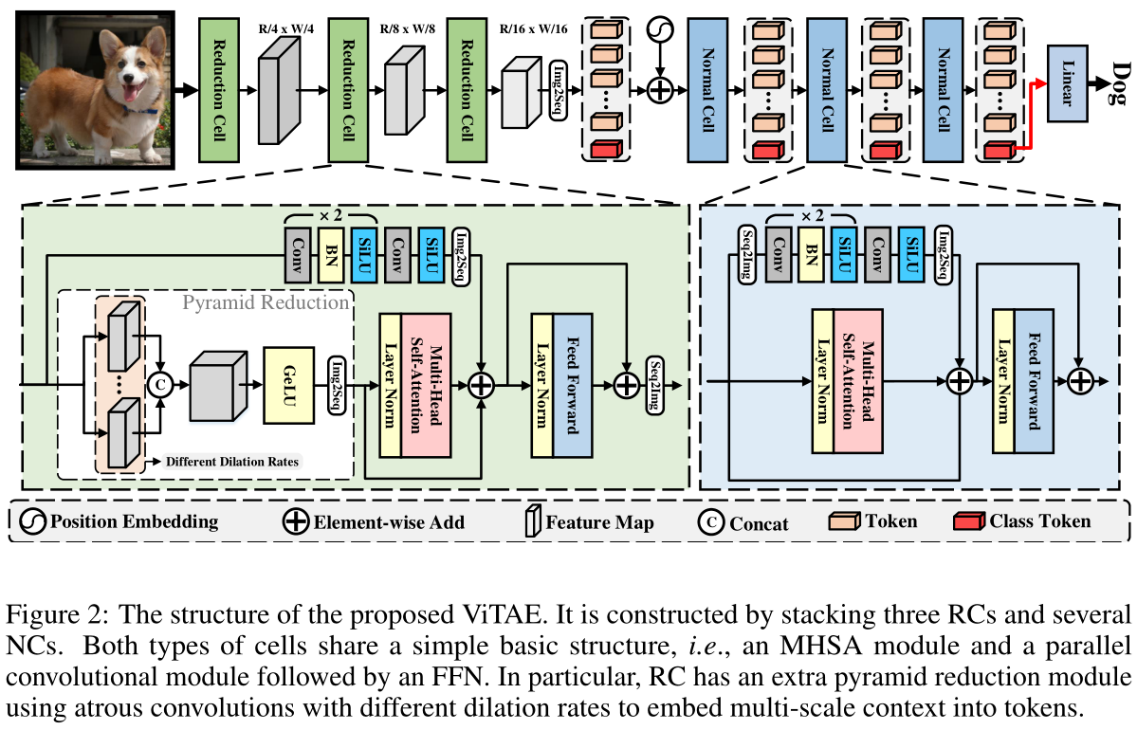
有两种结构(cell):RCs and NCs。RCs负责将多尺度上下文和局部信息embedding到token中,NCs用于进一步建模token中的局部和长期依赖关系。
输入图片(H,W,3),通过3个RCs对其分别进行4×, 2×, 2×的下采样,得到feature maps(H/16,W/16,D),实验中D=64。然后拉伸为H*W/256×D的2D向量,添加cls token,正弦(sinusoid )位置编码。然后将tokens输入NCs,保留token的长度。最后,使用来自最后一个NC的cls token获得预测概率。
2、Reduction cells(RCs)
RC有两个并行分支,分别负责建模局部性和长程依赖性,然后是一个FFN,用于特征转换。

1)Pyramid Reduction Module, PRM
第一个RC的输入是图像x。在全局依赖项分支中,fi首先被输入到金字塔缩减模块(Pyramid Reduction Module, PRM)中来提取多尺度上下文:

第i个PRM模块,Convij表示第i个PRM模块中第j个卷积层,sij表示第i个PRM模块中第j个卷积层的膨胀率,使用跨步卷积来降低特征的空间维数(ri为步距),不同卷积得到的feature map通过在channel维度上进行concate,然后将fmsi由MHSA(Multiple head self-attention)模块处理,以建模长期依赖关系:
![]()
Img2Seq(·)是一个简单的reshape为1D序列的操作,
2)Parallel Convolutional Module (PCM)
使用并行卷积模块(PCM)将局部上下文embedd到token中,令牌与fgi融合:

平行卷积分支与跨步卷积的PRM具有相同的空间下采样比(保证能add)。
3)fusion
特征可以携带局部和多尺度上下文,这意味着RC通过设计获得了局部性IB和尺度不变性IB。
然后,融合的token被FFN处理,重新reshape为特征映射,并输入以下RC或NC,即:
![]()
Seq2Img(·)是将seqence reshape为feature maps的格式。
3、Normal cells(NCs)
NC除了缺少PRM外,具有与RC相似的结构。由于RC后的特征图空间尺寸相对较小(1/16 ×),在nc中不需要使用PRM.

首先将其与类标记tcls连接起来,然后将添加位置编码,上分支采用2D group卷积,下分支采用多头注意力机制,对最后一个NC生成的类令牌进行层归一化,并将其送入分类头,得到最终的分类结果。
4、model detail

在第一个RC中,默认卷积核大小为7 × 7,步幅为4,膨胀率为S1 =[1,2,3,4]。在接下来的两个rc中,卷积核大小为3 × 3, stride为2,膨胀率分别为S2 =[1,2,3]和S3 =[1,2]。由于标记的空间维度减小,因此不需要使用大内核和膨胀率。RCs和nc中的PCM都包含三个卷积层,核大小为3 × 3。
三、Experiments
1、Implementation details
ImageNet、224 × 224、AdamW、 cosine learning rate scheduler、batch size 512、initial learning rate 5e-4、8 V100 GPUs、PyTorch
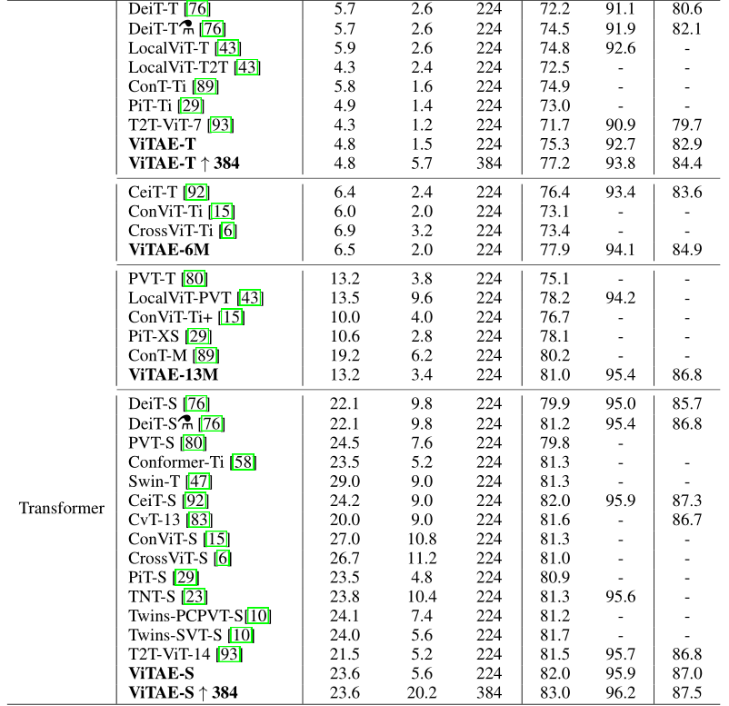
2、Comparison with the state-of-the-art
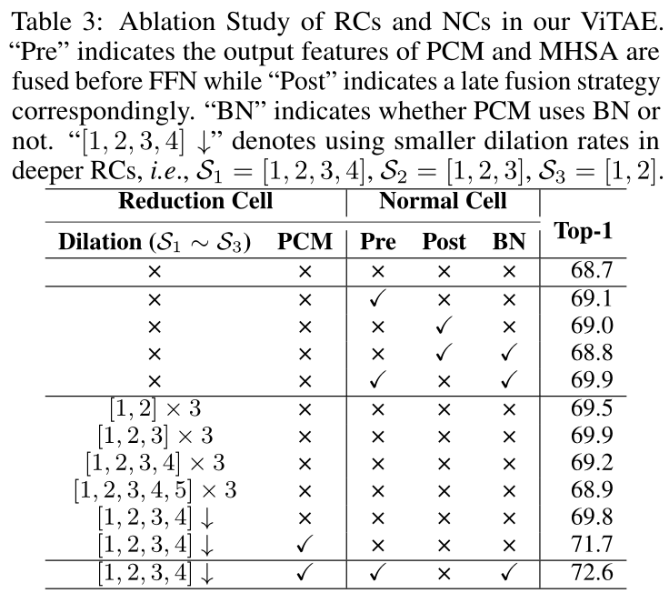
3、Ablation study
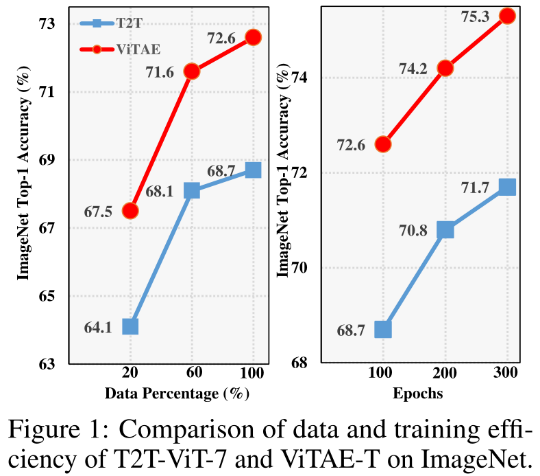
4、Data efficiency and training efficiency
(a)在完整的ImageNet训练集上使用20%、60%和100%的ImageNet训练集进行等效100个epoch的训练,例如,与使用100%的数据相比,我们在使用20%的数据进行训练时使用5次epoch;
(b)使用完整的ImageNet训练集分别训练100、200和300个epoch
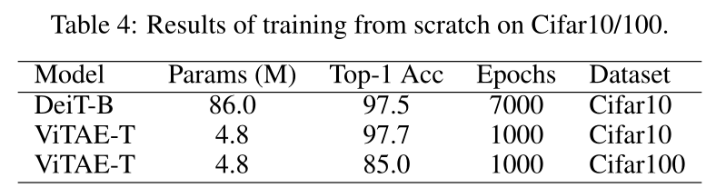
在较小的数据集Cifar10和Cifar100上从头开始训练ViTAE模型:
5、Generalization on downstream tasks

6、Visual inspection of ViTAE
Grad-CAM

Limitation
由于计算资源的限制,没有缩放ViTAE模型并在大型数据集上进行训练,例如ImageNet-21K和JFT-300M