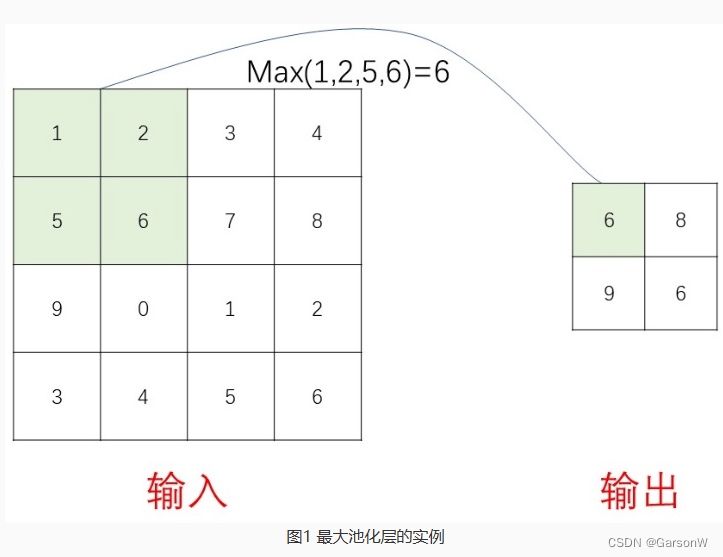
对于很多大型企业(如阿里巴巴)来说,经过多年的技术演进,系统工具和架构已经高度垂直化,服务器规模也达到了比较大的体量。当服务规模大于一定量(如10000台)时,小概率的硬件故障每天都会发生。这时如果需要人的干预,系统就无法可靠的伸缩。
为此每一层的系统都会面向失败做设计,对下游组件零信任,确保在故障发生时可以快速的发现和处理。但这些措施在故障发生时的有效性、故障恢复工具的真实容灾能力、处理问题人员的熟练度,沟通机制、容灾措施对上层的影响等问题,平时并没有太多的机会验证,往往都是在真实故障中暴露。
故障演练就是这个背景下诞生的,沉淀通用的故障场景,以可控成本在线上故障重放,以持续性的演练和回归方式的运营来暴露问题,不断验证和推动系统、工具、流程、人员能力的提升,从而提前发现并修复可避免的重大问题,或通过验证故障发现手段、故障修复能力来达到缩短故障修复时长的作用。
故障演练验证,是指基于混沌工程的故障演练实现对业务系统的验证。演练可以分为有损演练和无损演练,一般通过低频的有损演练发现业务架构问题、验证业务容灾能力,通过高频的无损演练实现对业务的监控发现/报警响应、组织应急等能力进行验证。
演练方案设计理论基础
技术型故障分析归纳,大致可以按照IaaS、PaaS、SaaS的层次进行归类。
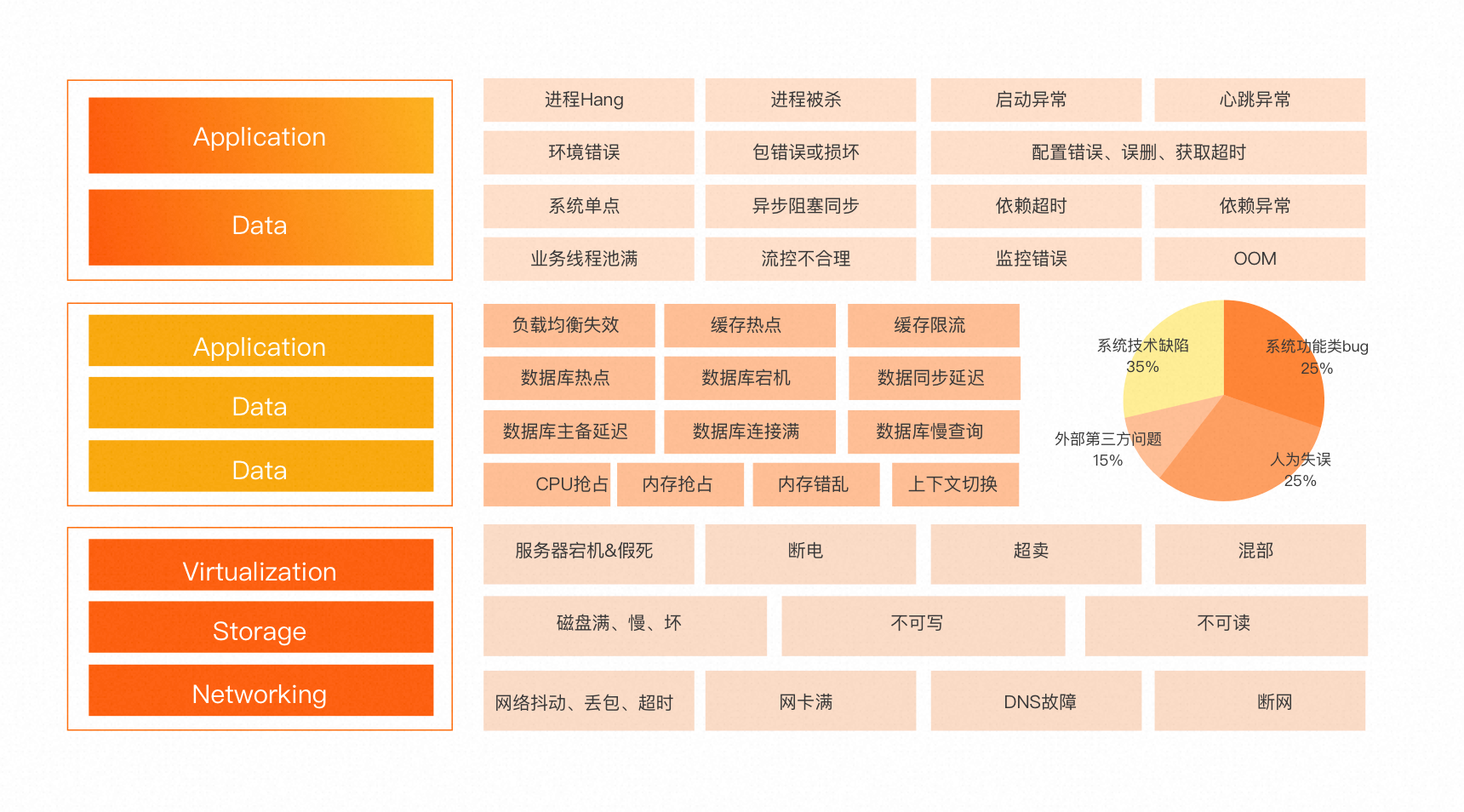
上面的分类是一个宏观视角,不是一个系统设计的视角。所以可以对故障模型再做一次升级,并得到一些推论&#x